


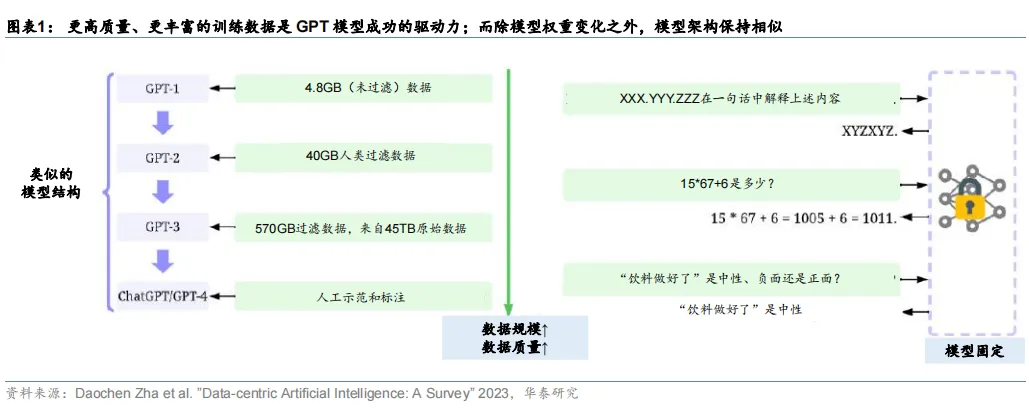
人工智能发展的突破得益于高质量数据的发展。例如,大型语言模型的最新进展依赖于更高质量、更丰富的训练数据集:与 GPT-2 相比,GPT-3 对模型架构只进行了微小的修改,但花费精力收集更大的高质量数据集进行训练。ChatGPT 与 GPT-3 的模型架构类似,并使用 RLHF(来自人工反馈过程的强化学习)来生成用于微调的高质量标记数据。
800+份重磅ChatGPT专业报告
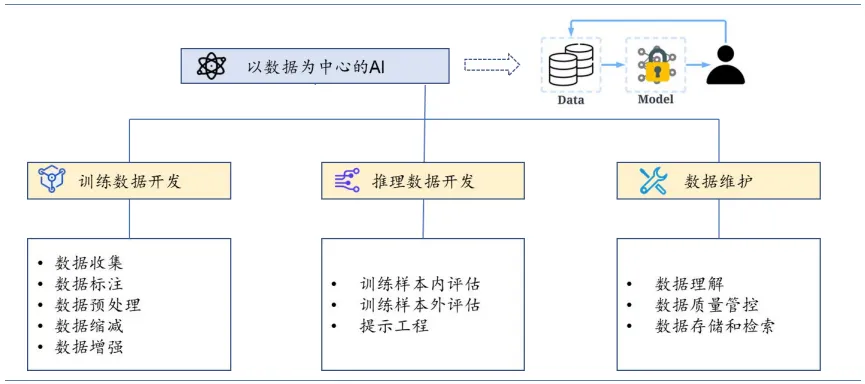
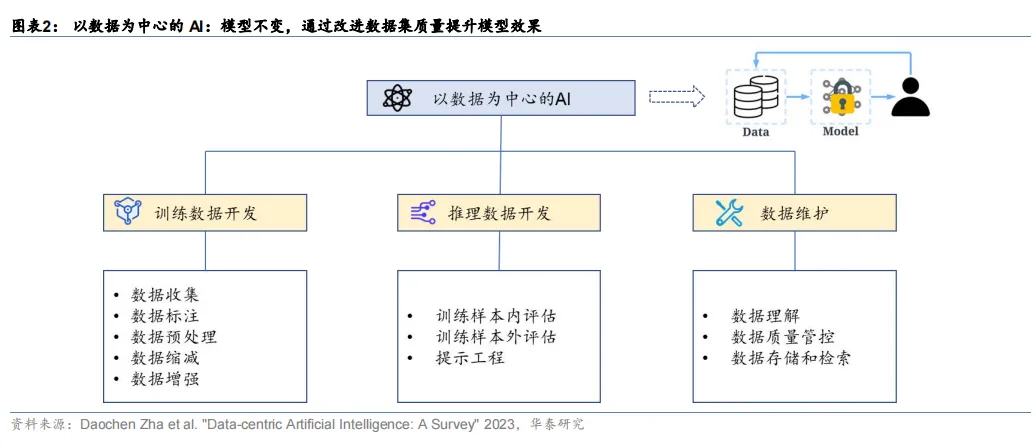
基于此,人工智能领域的权威学者吴承恩发起了“以数据为中心的 AI”运动,即在模型相对固定的前提下,通过提升数据的质量和数量来提升整个模型的训练效果。
提升数据集质量的方法主要有:添加数据标记、清洗和转换数据、数据缩减、增加数据多样性、持续监测和维护数据等。因此,未来数据成本在大模型开发中的成本占比或将提升,主要包括数据采集,清洗,标注等成本。
AI 大模型需要高质量、大规模、多样性的数据集。
1)高质量:高质量数据集能够提高模型精度与可解释性,并且减少收敛到最优解的时间,即减少训练时长。
2)大规模:OpenAI 在《Scaling Laws for Neural Language Models》中提出 LLM 模型所遵循的“伸缩法则”(scaling law),即独立增加训练数据量、模型参数规模或者延长模型训练时间,预训练模型的效果会越来越好。
3)丰富性:数据丰富性能够提高模型泛化能力,过于单一的数据会非常容易让模型过于拟合训练数据。
数据集如何产生出来?
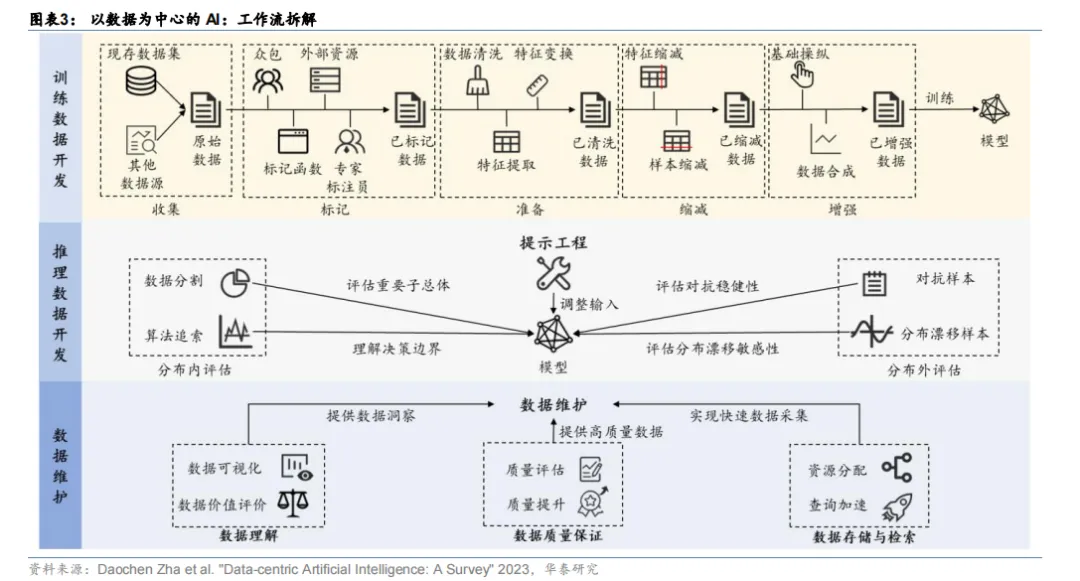
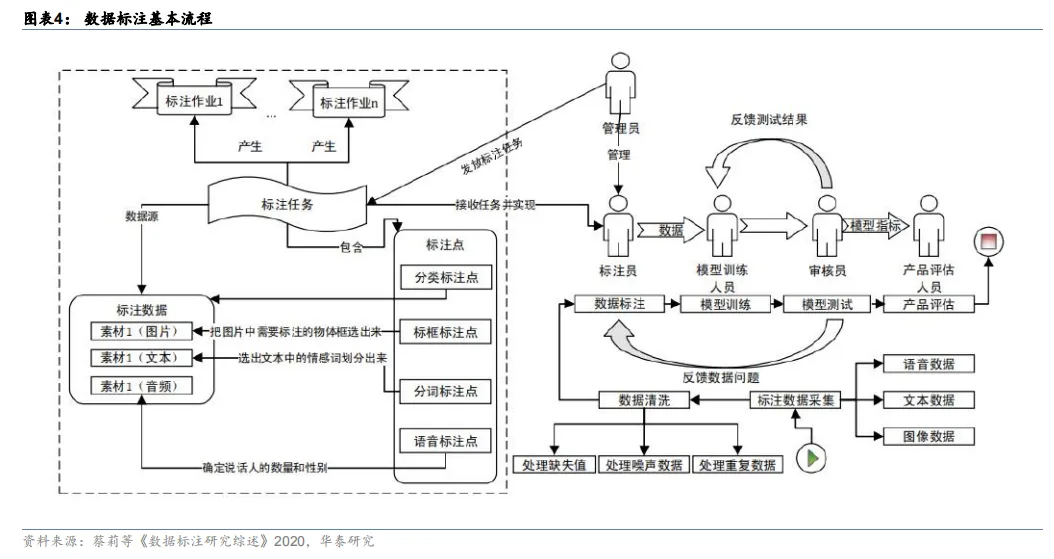
建立数据集的流程主要分为 1)数据采集;2)数据清洗:由于采集到的数据可能存在缺失值、噪声数据、重复数据等质量问题;3)数据标注:最重要的一个环节;4)模型训练:模型训练人员会利用标注好的数据训练出需要的算法模型;5)模型测试:审核员进行模型测试并将测试结果反馈给模型训练人员,而模型训练人员通过不断地调整参数,以便获得性能更好的算法模型;6)产品评估:产品评估人员使用并进行上线前的最后评估。
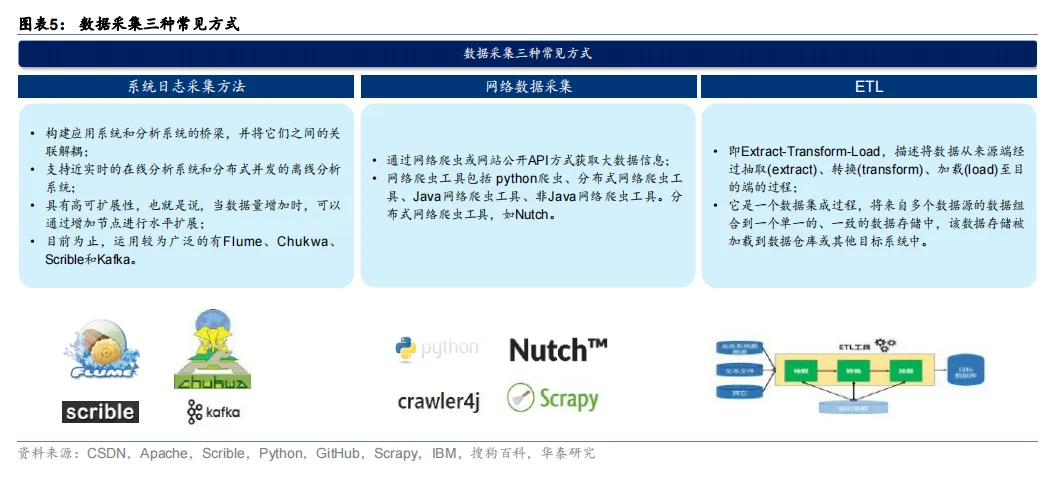
流程#1:数据采集。采集的对象包括视频、图片、音频和文本等多种类型和多种格式的数据。数据采集目前常用的有三种方式,分别为:1)系统日志采集方法;2)网络数据采集方法;3)ETL。
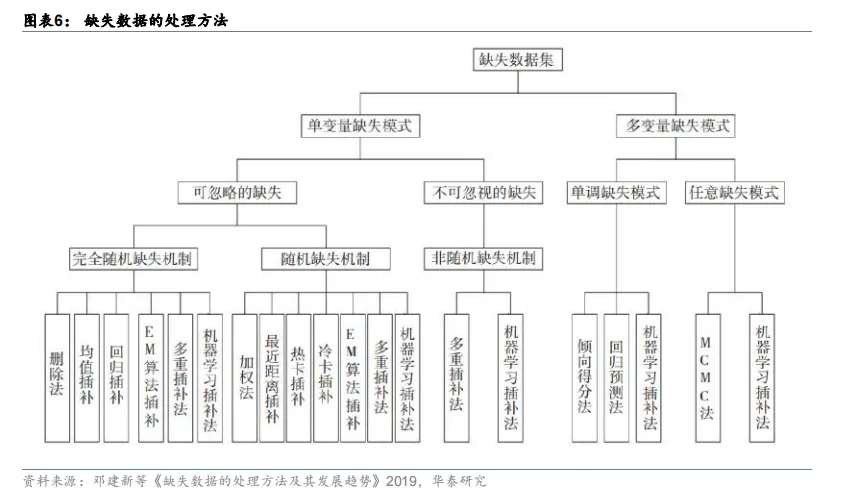
流程#2:数据清洗是提高数据质量的有效方法。由于采集到的数据可能存在缺失值、噪声数据、重复数据等质量问题,故需要执行数据清洗任务,数据清洗作为数据预处理中至关重要的环节,清洗后数据的质量很大程度上决定了 AI 算法的有效性。
流程#3:数据标注是流程中最重要的一个环节。管理员会根据不同的标注需求,将待标注的数据划分为不同的标注任务。每一个标注任务都有不同的规范和标注点要求,一个标注任务将会分配给多个标注员完成。

流程#4:最终通过产品评估环节的数据才算是真正过关。产品评估人员需要反复验证模型的标注效果,并对模型是否满足上线目标进行评估。

数据产业链包括生产、处理等环节。数据生产可以分为通用数据和行业数据:1)海外主要数据集的通用数据来自维基、书籍期刊、高质量论坛,国内相关公司包括文本领域的百度百科、中文在线、中国科传、知乎等,及视觉领域的视觉中国等。
2)数据是垂直行业企业的护城河之一,相关公司包括城市治理和 ToB 行业应用领域的中国电信、中国移动、中国联通,CV 领域的海康、大华等。数据处理环节,模型研发企业的外包需求强烈,利好卡位优质客户、技术赋能降低人力成本的数据服务企业,如 Appen、Telus International、Scale AI。
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


