


C++11其实主要就四方面内容,第一个是可变参数模板,第二个是右值引用,第三个是智能指针,第四个是内存模型(Memory Model)。
相对来说,这也是较难理解的几个特性,分别针对于泛型编程,内存优化,内存管理和并发编程。
并发编程是个非常大的模块,而在诸多内容底下有一个基本的概念,就是并发内存模型(Memory Model)。
那么,什么是内存模型?
早在之前介绍并发编程的文章中,我们就知道同步共享数据很重要。而同步可分为两种方式:原子操作和顺序约束。
原子操作是数据操作的最小单元,天生不可再分;顺序约束可以协调各个线程之间数据访问的先后顺序,避免数据竞争。
通常的同步方式会有两个问题,一是效率不够,二是死锁问题。导致效率不够是因为这些方式都是lock-based的。
当然,若非非常在意效率,完全可以使用这些同步方式,因其简单方便且不易出错。
若要追求更高的效率,需要学习lock-free(无锁)的同步方式。
内存模型,简单地说,是一种介于开发者和系统之间的并发约定,可以无锁地保证程序的执行逻辑与预期一致。
这里的系统包括编译器、处理器和缓存,各部分都想在自己的领域对程序进行优化,以提高性能,而这些优化会打乱源码中的执行顺序。尤其是在多线程上,这些优化会对共享数据造成巨大影响,导致程序的执行结果往往不遂人意。
内存模型,就是来解决这些优化所带来的问题。主要包含三个方面:
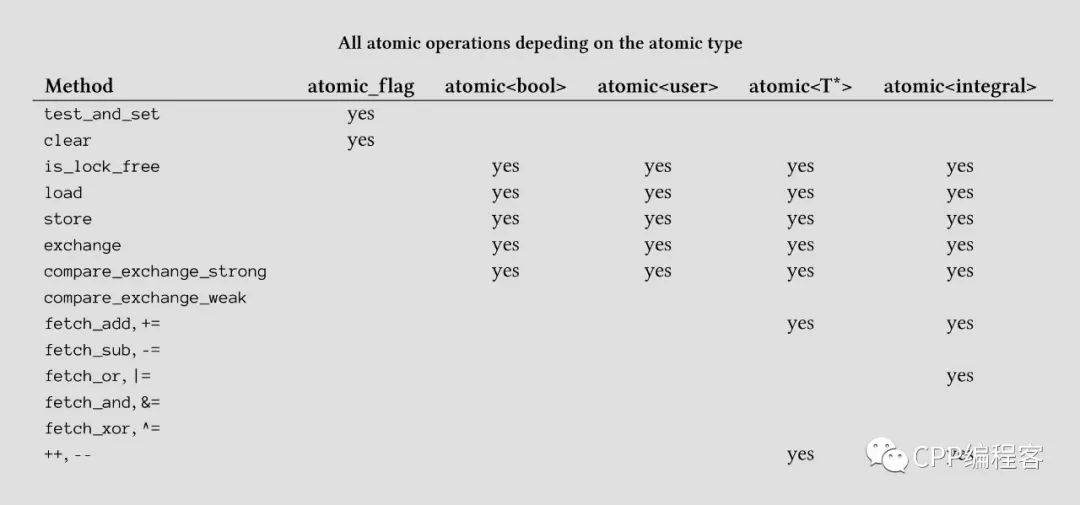
Atomic operations(原子操作)
Partial ordering of operations(局部执行顺序)
Visible effects of operations(操作可见性)
原子操作和局部执行顺序如前所述,「操作可见性」指的是不同线程之间操作共享变量是可见的。
原子数据的同步是由编译器来保证的,而非原子数据需要我们自己来规划顺序。
2
关系定义
这里有三种关系术语,
sequenced-before
happens-before
synchronizes-with
1#include <atomic>
2#include <thread>
3#include <iostream>
4
5class spin_lock
6{
7 std::atomic_flag flag = ATOMIC_FLAG_INIT;
8public:
9 void lock() { while(flag.test_and_set()); }
10
11 void unlock() { flag.clear(); }
12};
13
14spin_lock spin;
15int g_num = 0;
16void work()
17{
18 spin.lock();
19
20 g_num++;
21
22 spin.unlock();
23}
24
25int main()
26{
27 std::thread t1(work);
28 std::thread t2(work);
29 t1.join();
30 t2.join();
31
32 std::cout << g_num;
33
34 return 0;
35}
clear:清除操作,将值设为false。
test_and_set:将值设为true并返回之前的值。
1#include <atomic>
2#include <thread>
3#include <iostream>
4#include <vector>
5#include <algorithm>
6#include <iterator>
7
8std::atomic<bool> flag{false};
9std::vector<int> shared_values;
10void work()
11{
12 std::cout << "waiting" << std::endl;
13 while(!flag.load())
14 {
15 std::this_thread::sleep_for(std::chrono::milliseconds(5));
16 }
17
18 shared_values[1] = 2;
19 std::cout << "end of the work" << std::endl;
20}
21
22void set_value()
23{
24 shared_values = { 7, 8, 9 };
25 flag = true;
26 std::cout << "data prepared" << std::endl;
27}
28
29int main()
30{
31 std::thread t1(work);
32 std::thread t2(set_value);
33 t1.join();
34 t2.join();
35
36 std::copy(shared_values.begin(), shared_values.end(), std::ostream_iterator<int>(std::cout, " "));
37
38 return 0;
39}
是什么保证了上述原子操作能够在多线程环境下同步执行呢?
其实在所有的原子操作函数中都有一个可选参数memory_order。比如atomic<bool>的load()和store()原型如下:
bool std::_Atomic_bool::load(std::memory_order _Order = std::memory_order_seq_cst) const noexcept
void std::_Atomic_bool::store(bool _Value, std::memory_order _Order = std::memory_order_seq_cst) noexcept
这里的可选参数默认为memory_order_seq_cst,所有的memory_order可选值为:
enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
};
这就是C++提供的如何实现顺序约束的方式,通过指定特定的memory_order,可以实现前面提及的sequence-before、happens-before、synchronizes-with关系。
顺序约束是我们和系统之间的一个约定,约定强度由强到弱可以分为三个层次:
Sequential consistency保证所有操作在线程之间都有一个全局的顺序,Acquire-release保证在不同线程间对于相同的原子变量的写和读的操作顺序,Relaxed仅保证原子的修改顺序。
为何要分层次呢?
其实顺序约束和系统优化之间是一种零和博弈,约束越强,系统所能够做的优化便越少。
因此每个层次拥有效率差异,层次越低,优化越多,效率也越高,不过掌握难度也越大。
所有的Memory order按照操作类型,又可分为三类:
Read(读):memory_order_acquire,memory_order_consume
Write(写):memory_order_release
Read-modify-Write(读-改-写):memory_order_acq_rel,memory_order_seq_cst
Relaxed未定义同步和顺序约束,所以要单独而论。
例如load()就是Read操作,store()就是Write()操作,compare_exchange_strong就是Read-modify-Write操作。
这意味着你不能将一个Read操作的顺序约束,写到store()上。例如,若将memory_order_acquire写到store()上,不会产生任何效果。
我们先来从默认的Sequential consistency开始,往往无需设置,便默认是memory_order_seq_cst,可以写一个简单的生产者-消费者函数:
1std::string sc_value;
2std::atomic<bool> ready{false};
3
4void consumer()
5{
6 while(!ready.load()) {}
7
8 std::cout << sc_value << std::endl;
9}
10
11void producer()
12{
13 sc_value = "produce values";
14 ready = true;
15}
16
17int main()
18{
19 std::thread t1(consumer);
20 std::thread t2(producer);
21 t1.join();
22 t2.join();
23
24 return 0;
25}
1class spin_lock
2{
3 std::atomic_flag flag = ATOMIC_FLAG_INIT;
4public:
5 spin_lock() {}
6
7 void lock() { while(flag.test_and_set(std::memory_order_acquire)); }
8
9 void unlock() { flag.clear(std::memory_order_release); }
10};
11
12spin_lock spin;
13void work()
14{
15 spin.lock();
16 // do something
17 spin.unlock();
18}
19
20int main()
21{
22 std::thread t1(work);
23 std::thread t2(work);
24 t1.join();
25 t2.join();
26
27 return 0;
28}
clear()中使用了release,test_and_set()中使用了acquire,acquire和release操作之间是synchronizes-with的关系。
它的行为和之前使用sequential consistency默认参数的自旋锁一样,不过要更加轻便高效。
test_and_set()操作其实是个Read-modify-Write操作,不过依旧可以使用acquire操作。release禁止了所有在它之前或之后的写操作乱序,acquire禁止了所有在它之前或之后的读操作乱序。
在两个不同的线程之间,共同访问同一个原子是flag,所添加的顺序约束就是为了保证flag的修改顺序。
我们再来看一个更清晰的例子:
1std::atomic<bool> x{false}, y{false};
2std::atomic<int> z{0};
3void write()
4{
5 // relaxed只保证修改顺序
6 x.store(true, std::memory_order_relaxed);
7
8 // release保证在它之前的所有写操作顺序一致
9 y.store(true, std::memory_order_release);
10}
11
12void read()
13{
14 // acquire保证在它之前和之后的读操作顺序一致
15 while(!y.load(std::memory_order_acquire));
16
17 // relaxed只保证修改顺序
18 if(x.load(std::memory_order_relaxed))
19 ++z;
20}
21
22int main()
23{
24 std::thread t1(write);
25 std::thread t2(read);
26 t1.join();
27 t2.join();
28
29 assert(z.load() != 0);
30
31 return 0;
32}
1std::vector<int> shared_value;
2std::atomic<bool> produced{false};
3std::atomic<bool> consumed{false};
4
5void producer()
6{
7 shared_value = { 7, 8, 9 };
8
9 // A. realse happens-before B
10 produced.store(true, std::memory_order_release);
11}
12
13void delivery()
14{
15 // B. acquire,A synchronizes with B
16 while(!produced.load(std::memory_order_acquire));
17
18 // B. release happens-beforeC
19 consumed.store(true, std::memory_order_release);
20}
21
22void consumer()
23{
24 // C. acquire, B synchronizes with C
25 // therefore, A happens before C
26 while(!consumed.load(std::memory_order_acquire));
27
28 shared_value[1] = 2;
29}
30
31int main()
32{
33 std::thread t1(consumer);
34 std::thread t2(producer);
35 std::thread t3(delivery);
36 t1.join();
37 t2.join();
38 t3.join();
39
40 std::copy(shared_value.begin(), shared_value.end(), std::ostream_iterator<int>(std::cout, " "));
41
42 return 0;
43}
注释已经足够说明其中所以,便不细述。
看回先前的一个例子:
1std::atomic<bool> x{false}, y{false};
2std::atomic<int> z{0};
3void write()
4{
5 // relaxed只保证修改顺序
6 x.store(true, std::memory_order_relaxed);
7 y.store(true, std::memory_order_relaxed);
8}
9
10void read()
11{
12 // relaxed只保证修改顺序
13 while(!y.load(std::memory_order_relaxed));
14 if(x.load(std::memory_order_relaxed))
15 ++z;
16}
relaxed是最弱的内存模型,此处全使用relaxed,顺序将不再有保证。
也许在read()中看到的write()操作是先y后x,那么此时read()里面的if操作便无法满足,也就是说,++z不会被执行。
解决方法是结合fences来使用,只需添加两行代码:
1std::atomic<bool> x{false}, y{false};
2std::atomic<int> z{0};
3void write()
4{
5 // relaxed只保证修改顺序
6 x.store(true, std::memory_order_relaxed);
7
8 std::atomic_thread_fence(std::memory_order_release);
9
10 y.store(true, std::memory_order_relaxed);
11}
12
13void read()
14{
15 // relaxed只保证修改顺序
16 while(!y.load(std::memory_order_relaxed));
17
18 std::atomic_thread_fence(std::memory_order_acquire);
19
20 if(x.load(std::memory_order_relaxed))
21 ++z;
22}
std::atomic_thread_fence:同步线程之间的内存访问。
std::atomic_signal_fence:同步同一线程上的signal handler和code running。
我们主要学习第一个线程的fence,它会阻止特定的操作穿过栅栏,约束执行顺序。
有三种类型的fences,
Full fence:阻止两个任意操作乱序。memory_order_seq_cst或memory_order_acq_rel。
Acquire fence:阻止读操作乱序,memory_order_acquire。
Release fence:阻止写操作乱序,memory_order_release。
用图来表示为:

本篇内容挺复杂的,其实就包含三个方面:Atomic operations(原子操作)、Partial ordering of operations(局部执行顺序)和Visible effects of operations(操作可见性)。

