

进行深度学习的训练向来不被认为是CPU的强项,但是以CPU研发见长的英特尔并不甘心屈服于这个定位,在过去的几年里,英特尔及其合作伙伴一直在探索用CPU来进行快速有效的深度学习开发的方法。代号KNL的Xeon Phi至强芯片是英特尔的努力尝试之一,同时在深度学习算法的改进上,英特尔也做了一些努力。
在美国旧金山举行的IDF16大会上,与英特尔联合宣布启动了KNL试用体验计划的浪潮集团副总裁、技术总监胡雷钧做了基于英特尔至强融合处理器KNL和FPGA上的深度学习的试用体验报告。报告介绍了高性能计算和深度学习发展的趋势、深度学习在高性能计算平台上的挑战和解决办法、大规模深度学习平台的系统设计、多核设备和机群系统的算法设计(包括KNL和FPGA各自的技术分析) 4部分的内容。下面我们从摩尔定律的演变开始,看企业在实践过程中,如何基于英特尔至强融合处理器KNL和FPGA,搭建最佳的深度学习算法。
摩尔定律的革命
1965年摩尔定律提出后,我们开始依次进入1965-2005年的单核CPU时代;2006至如今的多核CPU时代;2012至如今的多核英特尔MIC时代。
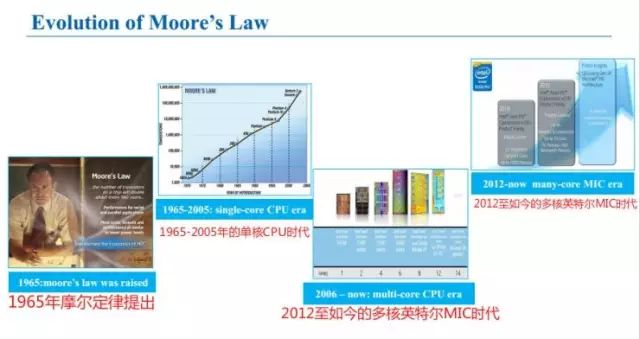
而现在,深度学习正在成为高性能计算的全新驱动力
高性能计算设备联手大数据提升深度学习的发展的同时,深度学习也在促进新的高性能计算模型的发展。归根结底,我们把深度学习现在的成功归功于三方面:
1)大量标签数据样本的出现:图片(10亿级)/语音(10万小时以上)。
2)好的算法,模型,软件的出现: 算法:DNN/CNN/RNN 软件:Caffe/TensorFlow/MXNet
3)高性能计算样本的激励:AlphaGo可视为典型例子。

不可避免地,深度学习在高性能计算上遇到了挑战
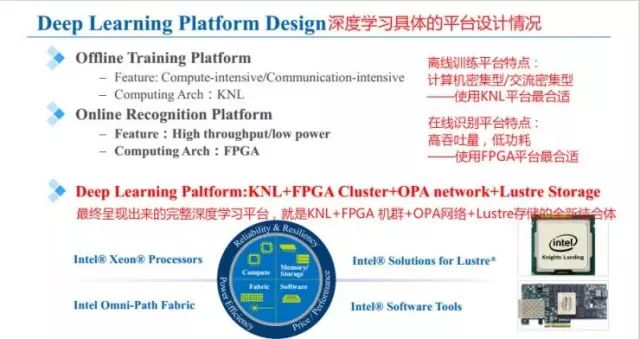
具体表现为两方面,其一,大规模深度学习平台的系统设计。比如离线训练要求的:高性能;在线识别要求的:低功耗。其二,多核设备和机群系统的算法设计问题。比如,多核设备异构细粒度并行算法;机群系统的分布式以及粗粒度并行算法。这些都是不容易解决的问题。

上述的挑战之一,大规模深度学习平台的系统设计问题,具体分为两种:
离线训练平台特点:计算机密集型/交流密集型——使用KNL平台最合适。
在线识别平台特点:高吞吐量,低功耗——使用FPGA平台最合适。
最终呈现出来的完整深度学习平台,就是KNL+FPGA 机群+OPA网络+Lustre存储 (由Linux和Clusters演化而来, 可以看做一个解决海量存储问题而设计的全新文件系统)的全新结合体。
上述的挑战之二,多核设备和机群系统的算法设计问题
在我们的浪潮—Intel中国并行计算实验室里,KNL/FPGA技术研究;HPC/深度学习应用;第一代 Xeon Phi Book三个方向的探索正如火如荼地进行着。
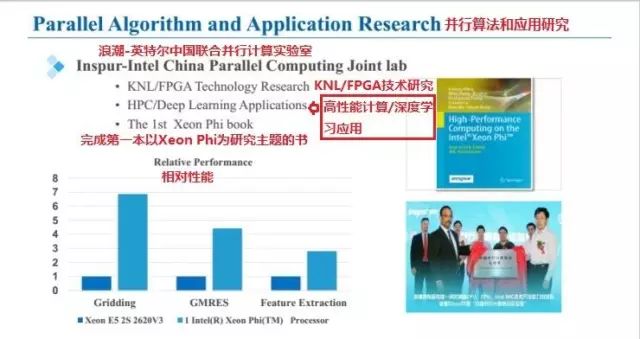
下面详细介绍具体应用实践中(SKA【平方公里阵列望远镜】的数据处理软件Gridding、大规模线性方程组求解器GMRES和开源深度学习并行计算框架Caffe-MPI的KNL版本)的高性能计算平台和其算法表现。
先谈谈KNL技术本身
它是英特尔第二代MIC架构,基于X86 架构的多核计算:拥有最多72核,总计288线程。目前有3个产品模型:包括处理器;协处理器;KNL-F。支持大规模记忆和高速宽带:DDR4:384 GB,90+GB/s。MCDRAM: 16GB, 500GB/s。

KNL技术的优势:高性能、高应用可适性、高可扩展性、可编程。

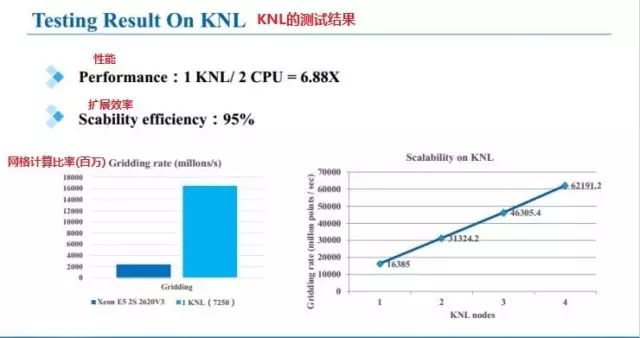
关于KNL测试结果
性能:1KNL/2 CPU=6.88X 。(叠加)扩展效率:95%
以浪潮全球首发基于KNL平台的深度学习计算框架Caffe-MPI举例
Caffe有许多用户,在中国非常流行。在数据规模很大的情况下,一个节点通常需要很长的时间去训练。这就要求,Caffe的前馈计算,权重计算,网络更新可在并行机群环境中处理。

来自伯克利大学的原始版本的Caffe语言在处理的数据规模太大时需要的时间太长了,并且默认情况下并不支持多节点、并行文件系统。因此不是很擅长超大规模的深度学习运算。不过由于Caffe是开源的,因此理论上任何人都能对其进行自己需要的改进。Caffe的多种功能事实上都有很好的被改进以支持集群并行计算的潜力。而浪潮集团在原版Caffe的基础上加以改进,开发出了第一代支持在KNL上进行丛集并行计算的Caffe版本。支持英特尔的Luster存储器、OPA网络和KNL丛集。

浪潮集团将这个改进版的Caffe框架命名为Caffe架构,下图是关于Caffe-MPI在KNL上进行运算时的结构的一些解释。可以看到,其计算流程采用MPI主从模式,使用多个KNL处理器组成节点网络,主节点使用一个KNL,而从节点可以视需求由N个KNL构成,因为使用了专为HPC设计的Lustre文件系统,因此数据吞吐量并不会限制到计算和训练。OPA架构也保证了网络通信的顺畅。软件系统方面,支持Linux/Intel MKL和Mvapich2 。
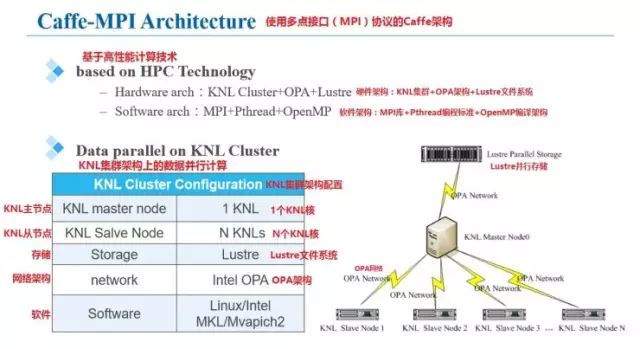
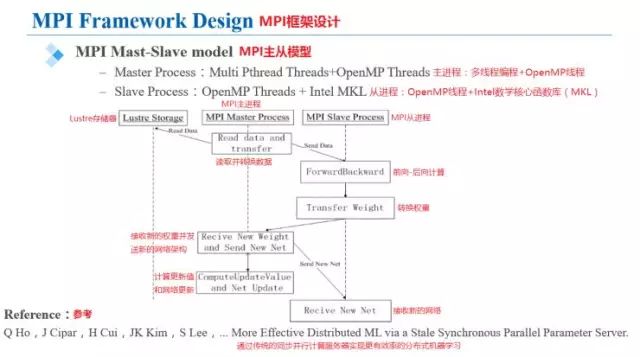
设计框架中的主节点为MPI单进程+多Pthread线程,从节点为MPI多进程,图中展示了整个网络训练的框图。
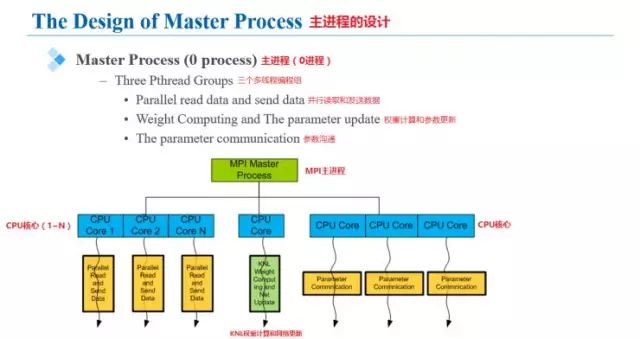
设计中对KNL的最多72个核心可以进行充分利用,主进程可以同时处理三个线程:并行读取和发送数据、权重计算和参数更新、网络间的参数沟通。下图中给出了图示。
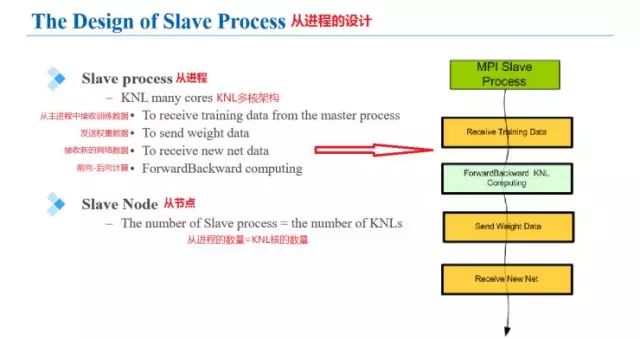
MPI结构中的从进程的主要处理流程是:从主进程中接收训练数据、发送权重数据、接收新的网络数据、进行前向、后向计算。从节点网络中每一个KNL核代表了一个MPI网络中的从节点。
下图中的信息表示,改进版的在KNL丛集上运行的Caffe-MPI架构对原版Caffe进行了多项优化。最终的效果表现是原版的3.78倍。增加KNL处理器的总数时的性能扩展效率高达94.5%。

而FPGA是另一项在深度学习领域极有潜力的硬件。我们知道FPGA的特点包括高性能、支持更多并行模式、高密度、易编程、适配OpenCL。

目前浪潮、Altera和科大讯飞在在线识别领域对FPGA的应用起到了很好的成效。结果表明,FPGA组成的系统在各项指标上都显著优于传统CPU组成的系统。

结论是
对于离线学习来说,基于KNL处理器搭建的MPI-Caffe架构可以很好的完成任务。而在线语音平台等在线认知项目则很适合使用FPGA来搭建系统。

————完————
<服务器基础知识全解(终极版)>,提供182页完整版付费下载。

获取方式:点击“阅读原文”即可查看详情,提供PPT可编辑版本和PDF阅读版本。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多精彩技术干货。


