
存储计算可以降低数据移动开销并充分利用设备内带宽,相比于特定计算加速,通用存储计算框架可以允许用户自定义卸载到存储设备的计算逻辑。然而大部分工作都关注于控制存储设备的接口和用户空间,但是缺乏对主机侧计算&存储资源的充分利用。IO栈是管理存储器的的基本组件,包括设备驱动、块接口层、文件系统,目前一些用户空间IO库(如SPDK)有效降低了延迟,但是io栈仍然不可或缺。这是因为1)大部分引用采用POSIX接口需要IO栈的兼容性;2)IO栈提供了包括page cache、文件系统等多种功能模块。而用户空间IO库只提供原始数据传输功能;3)IO栈可以使得不同用户、应用充分共享存储设备。
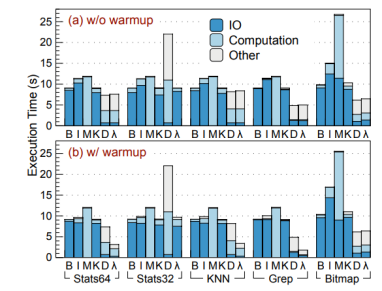
作者通过测试,发现不同特征的应用,对主机/设备具有不同的适应性。例如,在主机/设备侧分别运行Stat64和stat32。stat64在主机侧运行更快,stat32在设备侧运行更快。另外,一个应用的不同运行阶段,也具有不同的特征。例如使用warm page-cache策略运行stat64,发现无缓存时在设备上更快,缓存越多主机端越快。
eBPF是一种内核中的虚拟机,允许用户在不修改内核源码的情况下运行一段代码,其运行过程如下图所示。因为eBPF可以提供硬件无关的字节码格式,其可用于构建ISC运行时。然而,eBPF也存在一些问题:1)eBPF的静态校验器过于严格;2)缺乏指针访问和动态长度循环机制。因此,需要对eBPF进行扩展以更好的支持存储计算。

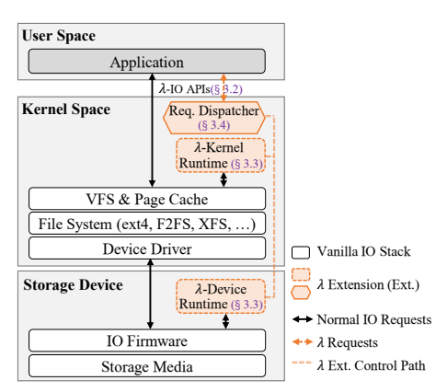
λ-IO通过扩展vanilla-IO框架,支持将计算动态卸载到内核/设备中进行计算。
它由三部分组成,如下图所示:
λ-IO API:用于提供扩展的应用编程接口
λ运行时:包括λ内核运行时和λ设备运行时,用于提供λ请求的计算接口
请求分发器:用于评估效率,将任务自动分发给设备/内核执行。
λ-API继承了vanilla IO的open/close/read/write接口,并扩展了λ_load/ λ _read/λ_write接口用于应用提交计算卸载请求。其中,λ函数是计算方法的实体,load_ λ用于将λ函数编译为eBPF代码;而open_λ/close_ λ:与vanilla中的定义保持一致,可以使用vanilla/ λ扩展函数。

pread_λ和pwrite_λ用于执行计算卸载,其中pread_λ表示以fd,offset,length表示的文件内容作为入参执行λ_id表示的λ函数,并将返回结果写到buf中。其执行步骤为:1)将文件数据作为输入数据加载到内存buffer中;2)为输出数据分配buffer空间;3)执行λ函数;4)将输出buffer的数据拷贝到用户分配的buffer中。pwrite_λ与pread_λ类似,但是其输入、输出参数相反。
λ运行时是执行load_ λ, pread_ λ, pwrite _λ的核心,它的实现具有两方面的关键挑战:1)计算:内核/设备的λ运行时都需要保存、执行计算函数;2)数据:λ运行时需要保存、访问文件数据和用户应用信息。
作者通过允许sBPF对BPF代码执行动态验证,使能指针、循环将eBPF扩展为sBPF。其中,指针访问的修改包括在JIT中增加指针地址检测代码,让sBPF可以在运行中检查指针,若指针未落在输入buffer中,则停止执行并返回错误码。另外,作者表示,所有循环都包括一个offset为负的跳转指令,因此sBPF使用了一个动态的后跳计数器,并限制后跳的执行次数,以避免死循环的发生。作者之后对其安全性进行了分析,并表示虽然增加了功能,但由于检验严格,并不会增加eBPF的安全性风险。
关于数据问题,主要是设备/内核的一致性访问问题。对于λ内核运行时,作者使用内核中通用的kernel_write和kernel_read访问文件,让内核管理页缓存和文件一致性,另外为了减少读写文件引起的大规模内存搬移,作者提出kernel_mmap进行内存映射解决这个问题。
对于设备运行时的文件一致性访问,作者提出,虽然由于设备对文件语义不可知,需要准确的物理地址,但是文件的IOCTL中由FIEMAP和FIBMAP用于提取元数据中的物理地址,可以解决设备的文件访问问题。而一致性问题包括内核-用户空间一致性和主机-设备一致性两方面,对于内核-用户空间一致性问题,由于采用的是标准syscall接口,内核可以管理一致性,而主机设备一致性问题则通过1)使用读写锁避免同时访问带来的一致性风险;2)在分发λ请求前,将请求数据文件相关的脏页刷入设备并清空缓存,可以解决其一致性问题。
请求分发器的目的是通过预测主机、设备对某个任务的执行时间,选择其中更快的那个进行分发,以达到更快、更高效的目的。为了评估执行时间,需要对执行时间进行建模。
为此,首先对相关变量进行符号表示如下表。
D | 存储器中内容大小 |
Bs | 存储介质-控制器传输带宽 |
Bd | 主机-设备传输带宽 |
Bh | 主机计算的等效带宽 |
α | 输入/输出长度比值 |
β | 设备/主机计算吞吐量比值 |
之后,对主机、设备端分别建模其执行时间,当不考虑缓存时,使用pread_λ在内核、设备端的执行时间如下公式所示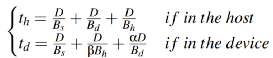 。当考虑缓存时,则其形式变为如下
。当考虑缓存时,则其形式变为如下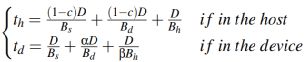 。而pwrite_λ的执行时间则为
。而pwrite_λ的执行时间则为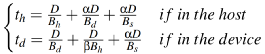 。
。
本文中在一个配备4核8线程的I7-7700@3.6GHz,16GB DDR4内存的电脑上运行内核为linux 5.10.21的Ubuntu20.04LTS操作系统进行测试。存储计算设备则采用Xilinx Zynq Ultrascale+ ZU17EG搭配2GB内存核64GBNand Flash。测试负载包括Stat64, Stat32, KNN, Grep, Bitmap。评估对比对象包括了1)Buffer IO(B):默认的vanilla IO;2)DirectIO(I):类似Buffer IO,但开启O_DIRECT;3)Mmap(M):将数据文件读入用户空间,避免内核数据拷贝;4)λ-IO kernel(K):使用内核计算的λ-IO;5)λ-IO device(D):使用设备计算的λ-IO;6)λ-IO(λ):启用请求分发的λ-IO。
对单个应用的性能分析,作者将执行时间细分为三部分:IO/计算/其他。首先对比λ-IO Device(d)和Buffer IO(B)。可以发现,d相比B,Stats64, KNN, Grep, Bitmap分别提升23.24%, 10.82%, 87.13%, 60.15%。这是由于主机端IO时间占比超过92.04%。另外,由于设备仅有4核4线程,而主机发送请求为8线程,因此出现了请求排队现象。在stat32中d执行时间超过B 6.65倍 ,是由于64位eBPF对32位程序执行效率不高导致的。
之后作者对比了λ-Io Kernel(k)核vanilla-IO(B)之间的性能差异,并发现二者性能基本相同。λ-IO由于sBPF增加了运行时动态检验,带来了部分额外开销,但是又因为kernel_mmap避免了内存复制的开销,二者基本相互抵消。
最后作者对比了λ-IO不同模式之间的性能差异,并发现,引入请求分配器的λ-IO在每项测试中的性能都基本相当于k、d模式下更快的那一个,并且通过对比,可以发现请求分配器带来的额外开销约为4.98%。
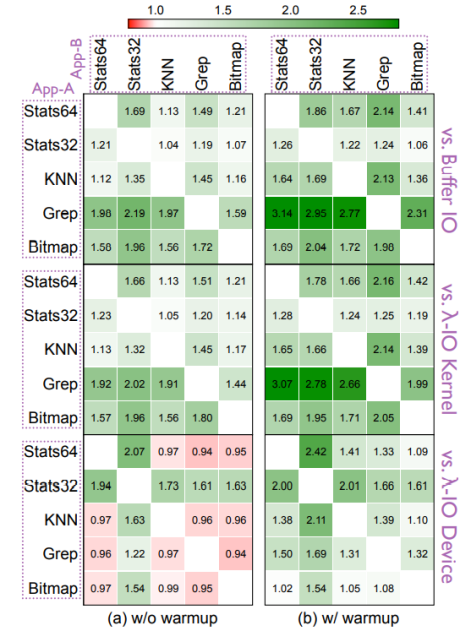
作者通过同时运行5种负载之二评估同时运行不同负载的性能差别。发现,当运行项包括stat32时,Stat32被分发到主机,另一个分发到设备运行,因此λ-IO性能提升2.19倍,其他情况下λ-IO也有1.98倍的整体性能提升。
敏感性分析
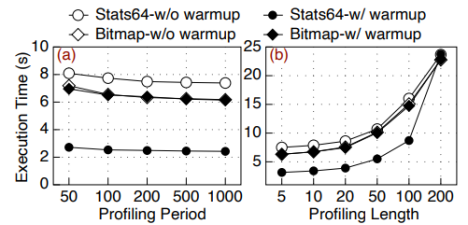
作者接着进行了敏感性分析。首先是数据集大小敏感性,作者使用stat64测试为例,发现在缓存>数据集大小时,由于避免了IO瓶颈,内核性能最佳,当缓存≈数据大小时,页缓存的影响变小,λ-IO性能更好,当数据>缓存大小时,λ-IO由于高效分发请求,比其他对照组快1.28-1.60倍不等。
接着是热启动敏感性,作者发现Buffer-IO在热启动下性能比冷启动更好一些,但是λ-IO性能仍是Buffer-IO的4.05倍。
之后作者分析了请求分发器的预测周期和预测长度的敏感性,发现,当预测周期超过200后,性能基本不发生改变,因此将默认预测周期设为200,而对于预测长度,可以看到随着预测长度增加,执行时间迅速增长,因此默认预测长度被设为5。
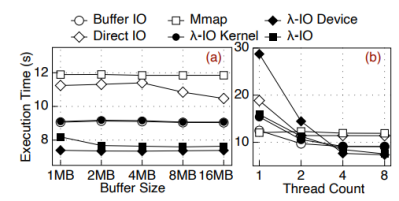
对于缓存大小和线程数量,可以看到大部分应用对缓存大小不敏感,且大部分应用随着线程数增长而增长,并在4线程时基本触顶。
通过对比运行时间,作者表示sBPF相比eBPF,循环检查对内核/设备增加不超过2.44%和10.09%的开销,加上指针检查,sBPF对内核/设备引入不超过16.96%和22.68%的额外开销。
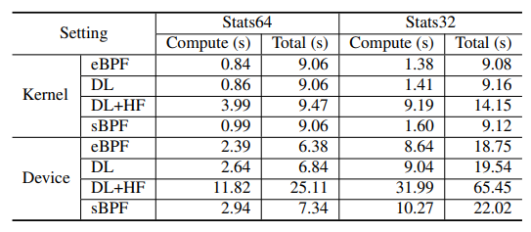
作者最后将spark SQL移植适配λ-IO,并测试了其在TPC-H负载下的真实性能表现。对比发现在buffer-IO模式下,IO占用了27.02%-60.41%的总时间,λ-IO Kernel与buffer-IO类似,λ-IO将任务分发至设备,提升最高81.55%的性能,暖启动后λ-IO比B/K/D分别提升2.15、2.16、1.51倍,在CPU密集型任务中Q20任务在D中执行时间比K少18.45%。

总结
在本文中提出了λ-IO,其扩展了Linux IO,使计算能够卸载到主机内核和设备。作者在真实的软硬件环境中实现并评估了λ-IO,其显示出显著的性能提升。
The End
致谢
感谢本次论文解读者,来自华东师范大学的硕士生黄奕阳,主要研究方向为存储压缩、存储计算。
