当今,人工智能(AI)已成为推动各行各业创新与发展的核心驱动力。AI技术的核心,通常被分为两个紧密相连但又各具特色的过程:AI训练和AI推理。
在AI训练阶段,需要向AI‘投喂’海量的数据,随后AI对这些数据进行分析,提取其中的规律,最终构建出一个AI模型。例如,通过输入猫、鸟、马等动物图像数据,AI能够培养出识别这些动物形态的能力。
AI训练往往需要大量的数据,并需耗费较长的时间,才能完成一个完整的AI模型训练。这些模型往往模型庞大,如实时语言处理翻译模型、实时生成式语言模型等。
Rambus研究员兼杰出发明家Steven Woo博士表示:“AI训练是当前计算领域中最具挑战性和难度最高的任务之一,因为在这个阶段需要管理和处理的数据量极为庞大。如果训练过程能够越快完成,就意味着AI模型能够更早投入使用,从而帮助投资者尽早获得回报,并实现投资回报率的最大化。”
当AI训练完成并形成大模型后,便可以将其应用于实际场景中,并处理新的、大模型未曾接触过的案例进行推理,这一过程即AI的推理阶段。在AI训练阶段,数据是核心要素;而在AI推理阶段,性能则成为关键所在,尤其在推理速度和准确性方面,因为人们都希望大模型能够快速且准确地得出推理结果。
无论是AI训练阶段还是AI推理阶段,都需要具备极快的处理速度、强大的处理性能以及小巧的芯片尺寸。尤其在AI推理阶段,还需更短的延迟和更高的带宽,这些都对内存提出了更高的要求。
Steven Woo博士表示:“对于内存的需求一直在快速增长和变化,自2012年以来,这一趋势并未减缓。AI应用对内存带宽和容量的需求更是永无止境。”
以OpenAI的大预言模型ChatGPT为例,其参数量和规模在过去几年中大幅增长。如2022年11月发布的GPT-3使用了1750亿个参数,而今年5月发布的最新版本的GPT-4o则使用了超过1.5万亿个参数。这意味着大语言模型的规模在过去两年增长了超过400倍,但同期硬件内存的规模则仅增长了两倍。
Steven Woo博士表示:“为完成这些AI模型的任务,必须增加GPU和AI加速器的数量,才能满足对内存容量和带宽的需求。”
HBM(High Bandwidth Memory,高带宽内存)被认为是AI时代的理想内存。HBM的DRAM堆栈采用多层堆叠架构,这种设计为其带来了极高的内存带宽、大容量和高能效,同时具有极低的延迟和占用面积小等优势。从HBM第一代到第二代、2E、3E,每一代最明显的变化就是单个堆栈带宽的急剧增加,HBM3E单个设备的带宽已超过1.2TB/s。目前,HBM3已成为AI训练硬件中不可或缺的内存技术,而HBM3E也为最先进的AI加速芯片提供了所需的内存带宽。
在高带宽内存需求的推动下,内存行业一直致力于研发新一代的HBM内存,目前,正在开发中的HBM4就是由JEDEC制定标准的下一代技术。虽然HBM4仍在开发中,但可以肯定的是,其每个堆栈的带宽已超越前一代,HBM4的单个堆栈带宽或将达到1.6TB/s,最终的实际带宽可能会更高。
作为主要的内存控制器IP提供商,Rambus也认识到了HBM4对未来AI技术发展的重要性。近期,Rambus推出了业界首款HBM4控制器IP,旨在加速下一代AI工作负载。
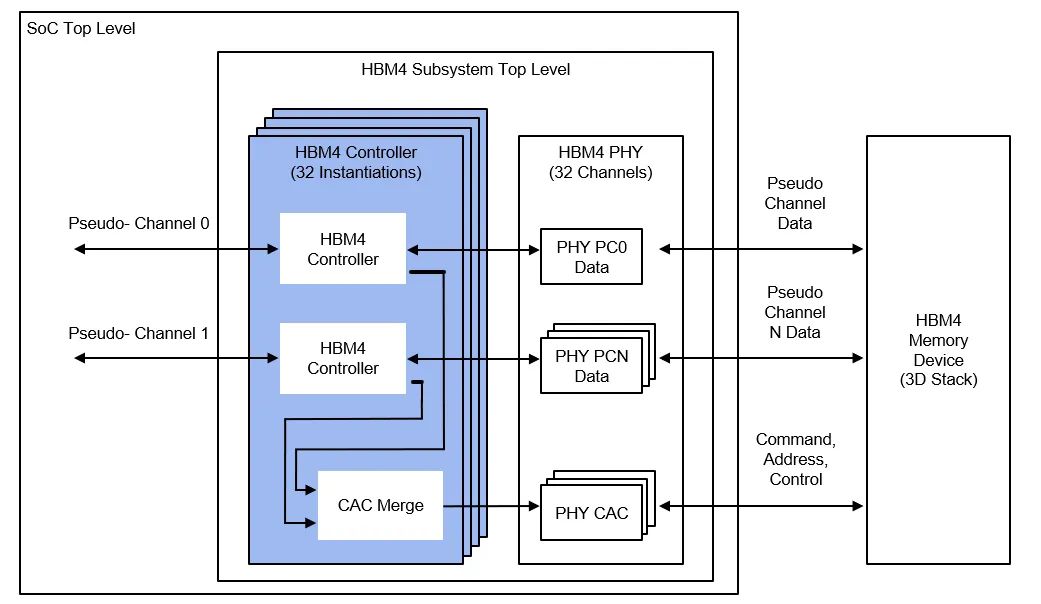
据Steven Woo博士介绍,Rambus的这款HBM4控制器IP提供了32个独立通道接口,总数据宽度可达2048位。基于这一数据宽度,当数据速率为6.4Gbps时,HBM4的总内存吞吐量将比HBM3高出两倍以上,达到1.64TB/s。此外,该HBM4内存控制器IP还是一个模块化、高度可配置的解决方案。
根据客户的不同应用场景,Rambus还提供定制化服务,包括尺寸、性能和功能等方面的定制。关键的可选功能包括ECC、RMW和错误清理等。Rambus还与第三方PHY供应商合作,确保客户在选择使用第三方PHY时,能在开发过程中一次流片成功。
Steven Woo博士表示:“Rambus此次发布的HBM4控制器IP表明我们正在支持下一代应用程序,这将使用户以及硬件和软件开发人员受益。”
Rambus大中华区总经理苏雷先生也表示:“我们推出的这款HBM4控制器IP基于Rambus多年来在HBM内存领域积累的丰富经验。我们在HBM市场的份额位居前列。Rambus始终着眼于未来,并致力于不断扩展内存的性能和容量。”
随着AI技术的蓬勃发展,即将迈入AI 2.0时代,这将进一步提升对内存技术带宽和容量的需求。对于内存厂商以及像Rambus这样的公司来说,这既是一个挑战也是一个机遇。Rambus此次发布的HBM4控制器IP正是未雨绸缪之举,专为AI 2.0而设计,满足AI新时代对更高带宽和更大容量的需求。
END