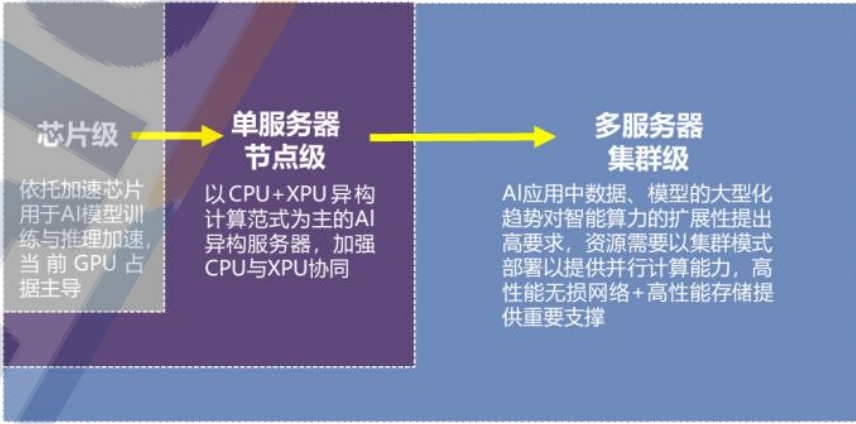
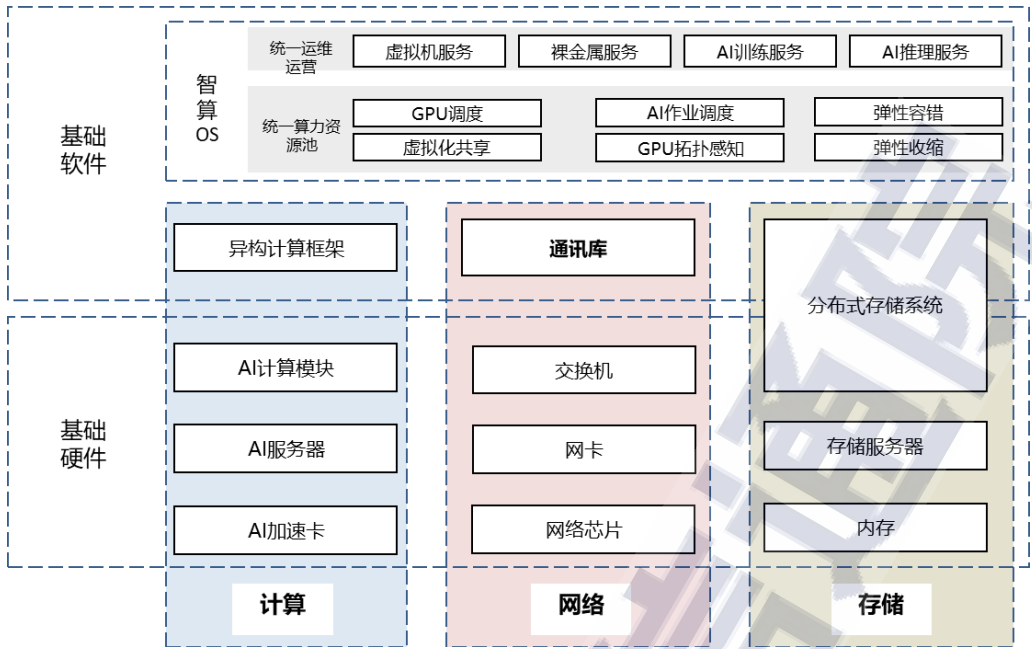
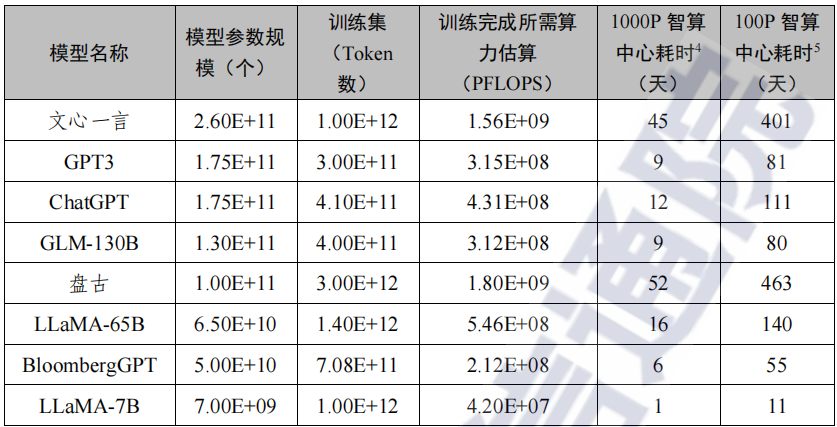
本文来自“智算基础设施发展研究报告(2024年)”。智算,即人工智能算力,是用于支撑加速人工智能算法模型训练与推理的算力,其部署层级分为芯片级、单服务器节点级、多服务器集群级。在芯片级,依托GPU、NPU、FPGA和ASIC等加速芯片用于AI模型训练与推理加速,当前GPU在国内市场中占据主导地位。华为、天数、海光、寒武纪等本土企业在该领域积极研发布局,如华为已经推出了昇腾系列全栈自主、性能优良的产品,能够实现对智能计算的良好支撑。在单服务器节点级,以“CPU+XPU”异构计算范式为主的Al异构服务器,加强CPU与XPU协同,主流服务器产品相对更丰富,浪潮、戴尔等传统服务器厂家基于英特尔CPU+英伟达GPU的组合推出了AI服务器产品,华为及生态伙伴基于其自主研发的AI芯片推出了国产系列AI服务器产品。在多服务器集群级,Al应用中数据、模型的大型化趋势对智能算力的扩展性提出高要求,资源需要以集群模式部署以提供并行计算能力,高性能无损网络+高性能存储为单服务器节点级和多服务器集群级的算力突破提供了重要支撑。智算基础设施,即人工智能算力基础设施,是基于人工智能专用算力芯片及加速芯片等组成异构计算架构,以智能计算设施为核心设施,以智能算力集群为核心载体,面向人工智能应用场景,提供所需算力服务、数据服务和算法服务的公共算力基础设施。智算基础设施需要统筹协同计算、网络、存储等核心技术。整体来看,智算基础设施的部署涉及计算、网络、存储三大维度的横向协同,也需要兼顾软件平台与硬件资源的纵向协同。各方主体积极推进布局智算基础设施。以提供公共普惠的智能算力服务为基本原则,地方政府(地方国投产投平台投资)、央国企(电信运营商投资)、AI云厂商(阿里云、华为云、百度智能云等投资)是我国智算基础设施的投建主体。从总体定位看,智算基础设施成为地方发展人工智能产业、发展产业数字化的重要创新载体,具有重要价值。从落地运营看,智算基础设施是加快AI产业化和产业AI化的重要战略支撑。智算中心与AI云,是当前智算基础设施的两种主要形态。智算中心一般由地方政府或电信运营商主导建设,定位于服务区域层面的产业创新与科研创新。据团队不完全统计,截止2024年7月底,纳入监测的智算中心(含已建和在建)已达87个。AI云一般由公有云计算厂商进行区域范围的建设布局,并提供统筹的调度运营,依托云计算模式,将AI部署能力开放给用户,为其不同场景所需要的AI算力、算法以及数据,提供规模化、高效率、低成本的支撑能力。目前,华为云、百度智能云、阿里云、腾讯云等厂商占据国内AI公有云市场份额近94%,平台效应凸显。大模型的参数规模与对算力的消耗成正比,参数规模越大,对算力的需求越大。根据OpenAI公司《适用于神经语言模型的尺度定律(Scaling Laws for Neural Language Models )》论文观点显示,训练阶段算力需求与模型参数数量、训练数据集规模等有关,且为两者乘积的6倍:训练阶段算力需求=6×模型参数数量×训练集规模。推进基础预训练大模型(千亿级以上参数)需要大规模智算集群支撑。随着模型参数量从千亿迈向万亿,模型能力更加泛化,大模型对底层算力的诉求进一步升级,万卡集群成为这一轮大模型基建军备竞赛的标配,万卡集群将有助于压缩大模型训练时间,实现模型能力的快速迭代。万卡集群是指由一万张及以上的加速卡(如GPU、NPU、TPU或其他专用AI加速芯片)组成的高性能计算系统,用以训练基础大模型。美国一直在引领万卡集群建设进程,诸如Google、Meta、微软、亚马逊、特斯拉等科技巨头,正利用超万卡集群推动其在基座大模型、智能算法研发,以及生态服务等方面的技术创新。如Google推出超级计算机A3Virtual Machines,拥有26,000块Nvidia H100 GPU;Meta在2022年推出拥有16,000块Nvidia A100的Al研究超级集群Al Research Super Cluster,2024年初又公布了2个24576块NvidiaH100集群,支持下一代生成式Al模型的训练。国内大型AI企业、头部互联网厂商、电信运营商等均在万卡集群的建设和使用过程中不断推动技术革新。字节跳动、阿里巴巴、百度为代表的互联网公司在积极推进万卡集群的建设。其中,字节跳动搭建了一个12288卡Ampere架构训练集群,研发MegaScale生产系统用于训练大语言模型。大型AI研发企业基于万卡集群加速模型研发,如科大讯飞2023年建设成首个支持大模型训练的万卡集群算力平台“飞星一号”。目前,中国移动已投产呼和浩特万卡智算中心,共部署了近2500台智算服务器,单体算力规模可达6.7EFLOPS,同时正在规划建设2个超万卡国产算力集群。此外,中国电信于今年3月宣布,天翼云上海临港国产万卡算力池正式启用。随着AI大模型的应用落地,推理智算需求正迎来爆发。随着Llama等开源框架的广泛应用,将加速大模型在各行业各领域落地生成式AI应用,行业模型的推理算力需求也将快速增长。据中信建设证券数据显示,2024年-2027年全球大模型推理的峰值算力需求量的年复合增长率为113%,远高于训练的78%。另据IDC调研数据显示,2026年云端训练需求与云端推理需求比由2022年的58.5%-41.5%变为37.8%-62.2%。此外,英伟达和英特尔今年都在公开场合多次强调了AI推理的重要性和巨大潜力,且英伟达2024财年Q4财报直接显示其数据中心40%的收入来自推理。可见,随着基础通用大模型市场趋于饱和,训练增长曲线逐渐放缓,大模型技术逐步进入融合赋能落地阶段,推理应用的智算需求可能比预期中的发展速度要更快。大模型推理应用对智算基建的低成本性、实时性、稳定性提出更高要求。随着人工智能大模型逐步进入广泛投产模式,推理应用阶段对于单位算力的性价比、成本高度敏感。以Sora为例,据相关机构测算,基于扩散(diffusion-based)模型生产1530万到3810万分钟的视频后,在推理上花费的计算量将超过训练环节。此外,推理的使用场景多在产业一线,对于底层算力的所处的位置、端应用服务是否能够快速连接等要求比较高,这就要求算力供给主体具备海量的可扩缩容的高性能算力,并且这些算力能够稳定交付。应对不同的推理场景,智算基建在加速卡选型方面有针对性的方案。针对大模型推理场景,智算基建需要选用训练卡支撑推理,或部署训推一体机方案,根据推理工作负载的需求,动态调整算力资源,通过“削峰填谷”的方式,来实现推理算力资源的高效利用,实现智算资源的错峰利用。针对实时性要求较高的小模型推理场景,智算基建也需要选用训练卡支撑推理。针对实时性要求较低的小模型推理场景,智算基建选用推理卡支撑推理。国内智算中心单体算力规模分为三个层次,与布局区域特点高度协同。目前智能算力主要分布和林格尔、贵阳、芜湖等国家算力枢纽节点,以及北京、上海、深圳等AI超一线城市,已布局不少单节点规模大于1000PFLOPS的大型算力中心,用于支撑通用基础大模型训练及高并发推理应用。人工智能发展基础较好的城市,布局300至1000PFLOPS规模的中型算力中心,可满足行业大模型对海量数据和复杂计算的需求。电信运营商智算基建跨区域调度能力较为突出。依托全国的智算布局体系,电信运营商自主研发算力调度平台,提供IaaS、PaaS、TaaS等多层次智算服务,全面推进智能算力一体化管控调度。中国移动打造“百川”算力并网平台,已接入社会算力近5EFLOPS,和自有算力形成优势互补,总共具备超10EFLOPS的算力供给能力,同时依托移动云算网大脑,支持东数西算、智算超算、数据快递等100多种算网业务,实现日均调度东西部资源上千万次。中国联通推出“星罗”先进算力调度平台,结合全国200+骨干云池及AI边缘一体机提供一键分发的“中训边推”服务,实现京津冀、大湾区、粤港澳等重点区域间毫秒级超低时延。中国电信推出算力互联互通平台“息壤”,单集群调度性能每秒超过2000+实例,打造通智超一体化智算加速平台“云骁”与一站式智算服务平台“慧聚”。地方层面多元异构算力互联互通调度平台持续涌现。安徽省算力统筹调度平台承担省级算力统筹调度平台职能,集通算、智算、超算、量算“四算合一”,围绕“管、排、调、营、测”五位一体,构建资源管理、交易服务、编排调度、监控运维4大能力中心,是算力使用省级财政补助政策的唯一指定承载平台,已与沪苏浙地区相关平台实现互联互通。2024 OCP全球峰会合集(Rack & Power篇)2024 OCP全球峰会合集(Networking篇)《2024 OCP全球峰会合集(Chiplets篇)》《2024 OCP全球峰会合集(Server篇)》《2024 OCP全球峰会合集(Security篇)》《2024 OCP全球峰会合集(Composable Memory Systems篇)》《2024 OCP全球峰会合集(HPC/NIC/OAI篇)》AR洞察与应用实践白皮书
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。