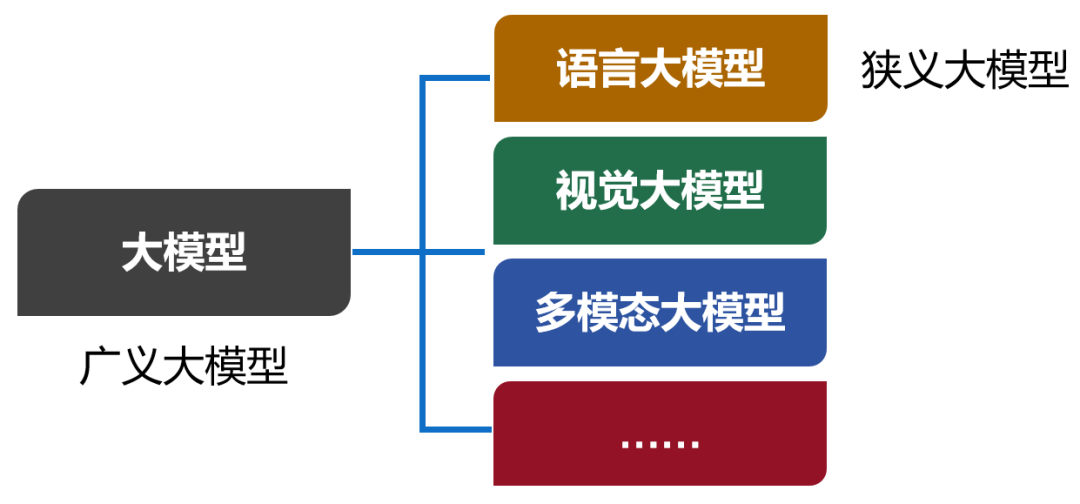
引言:网上关于大模型的文章也很多,但是都不太容易看懂。小枣君今天试着写一篇,争取做到通俗易懂。大模型,英文名叫Large Model,大型模型。早期的时候,也叫Foundation Model,基础模型。大模型是一个简称。完整的叫法,应该是“人工智能预训练大模型”。预训练,是一项技术,我们后面再解释。我们现在口头上常说的大模型,实际上特指大模型的其中一类,也是用得最多的一类——语言大模型(Large Language Model,也叫大语言模型,简称LLM)。除了语言大模型之外,还有视觉大模型、多模态大模型等。现在,包括所有类别在内的大模型合集,被称为广义的大模型。而语言大模型,被称为狭义的大模型。从本质来说,大模型,是包含超大规模参数(通常在十亿个以上)的神经网络模型。
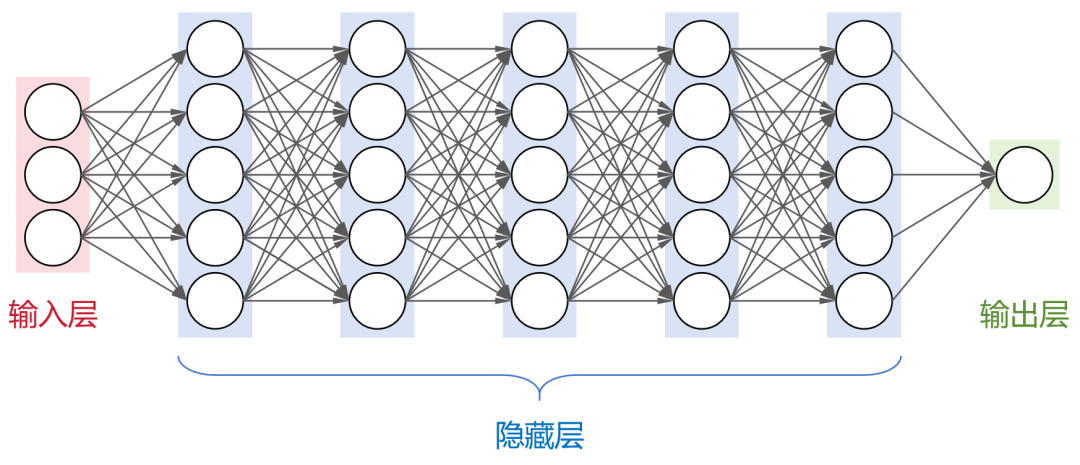
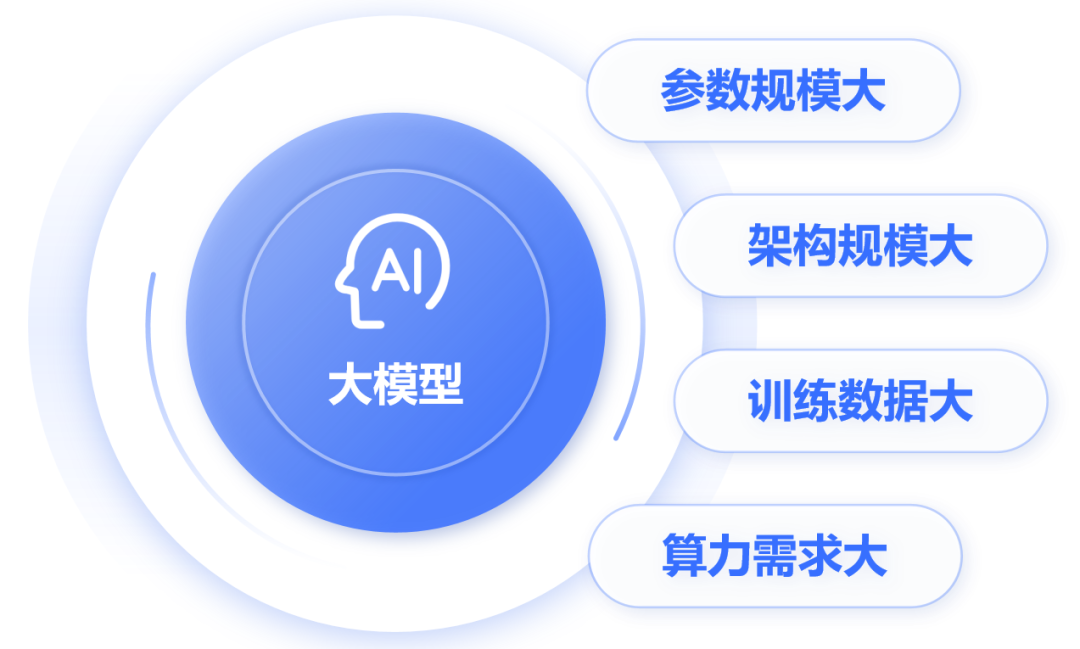
之前给大家科普人工智能(链接)的时候,小枣君介绍过,神经网络是人工智能领域目前最基础的计算模型。它通过模拟大脑中神经元的连接方式,能够从输入数据中学习并生成有用的输出。这是一个全连接神经网络(每层神经元与下一层的所有神经元都有连接),包括1个输入层,N个隐藏层,1个输出层。大名鼎鼎的卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆网络(LSTM)以及transformer架构,都属于神经网络模型。目前,业界大部分的大模型,都采用了transformer架构。刚才提到,大模型包含了超大规模参数。实际上,大模型的“大”,不仅是参数规模大,还包括:架构规模大、训练数据大、算力需求大。以OpenAI公司的GPT-3为例。这个大模型的隐藏层一共有96层,每层的神经元数量达到2048个。整个架构的规模就很大(我可画不出来),神经元节点数量很多。大模型的参数数量和神经元节点数有一定的关系。简单来说,神经元节点数越多,参数也就越多。例如,GPT-3的参数数量,大约是1750亿。同样以GPT-3为例,采用了45TB的文本数据进行训练。即便是清洗之后,也有570GB。具体来说,包括CC数据集(4千亿词)+WebText2(190亿词)+BookCorpus(670亿词)+维基百科(30亿词),绝对堪称海量。这个大家应该都听说过,训练大模型,需要大量的GPU算卡资源。而且,每次训练,都需要很长的时间。根据公开的数据显示,训练GPT-3大约需要3640PFLOP·天(PetaFLOP·Days)。如果采用512张英伟达的A100 GPU(单卡算力195 TFLOPS),大约需要1个月的时间。训练过程中,有时候还会出现中断,实际时间会更长。
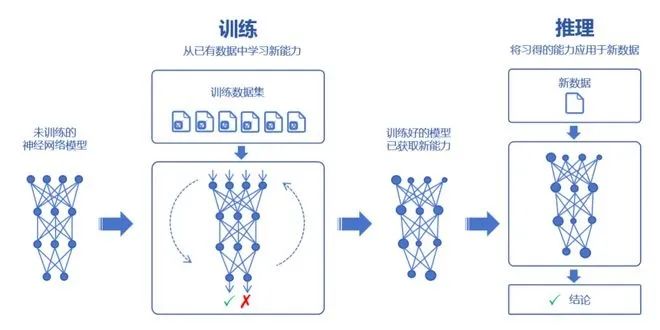
总而言之,大模型就是一个虚拟的庞然大物,架构复杂、参数庞大、依赖海量数据,且非常烧钱。相比之下,参数较少(百万级以下)、层数较浅的模型,是小模型。小模型具有轻量级、高效率、易于部署等优点,适用于数据量较小、计算资源有限的垂直领域场景。大家都知道,大模型可以通过对海量数据的学习,吸收数据里面的“知识”。然后,再对知识进行运用,例如回答问题、创造内容等。学习的过程,我们称之为训练。运用的过程,则称之为推理。
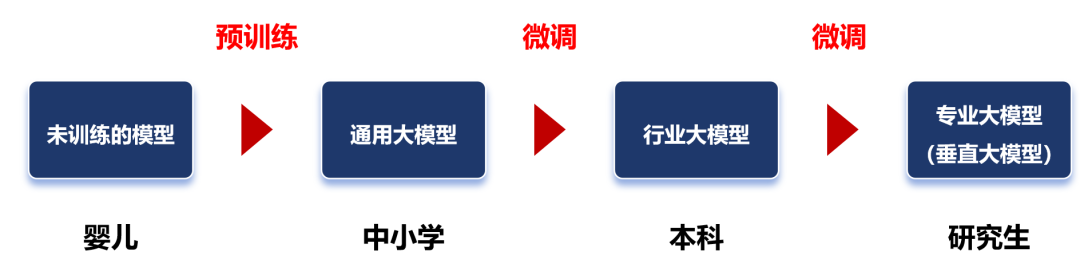
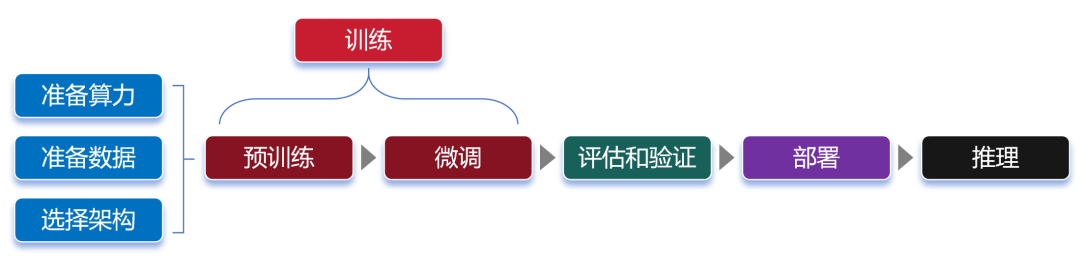
训练,又分为预训练(Pre-trained)和微调(Fine tuning)两个环节。在预训练时,我们首先要选择一个大模型框架,例如transformer。然后,通过“投喂”前面说的海量数据,让大模型学习到通用的特征表示。
那么,为什么大模型能够具有这么强大的学习能力?为什么说它的参数越多,学习能力就越强?
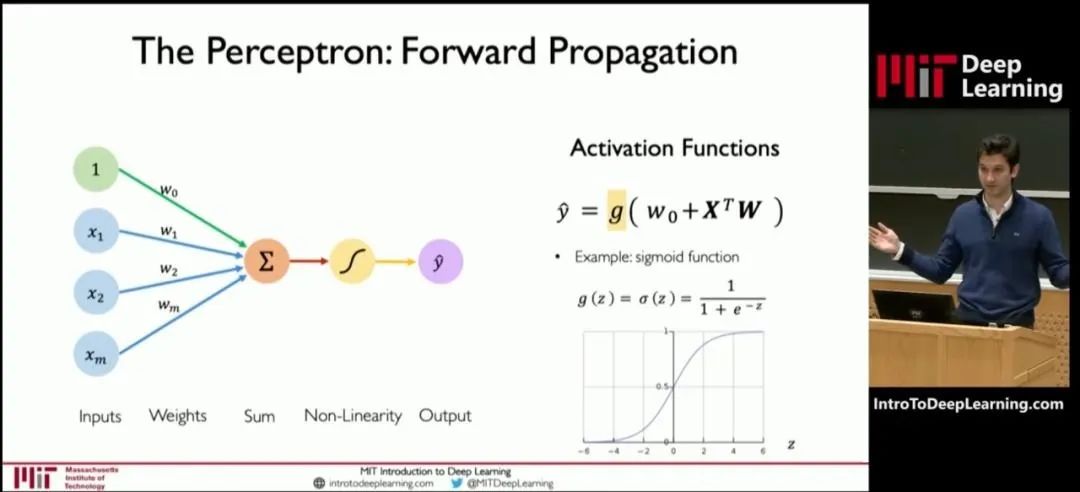
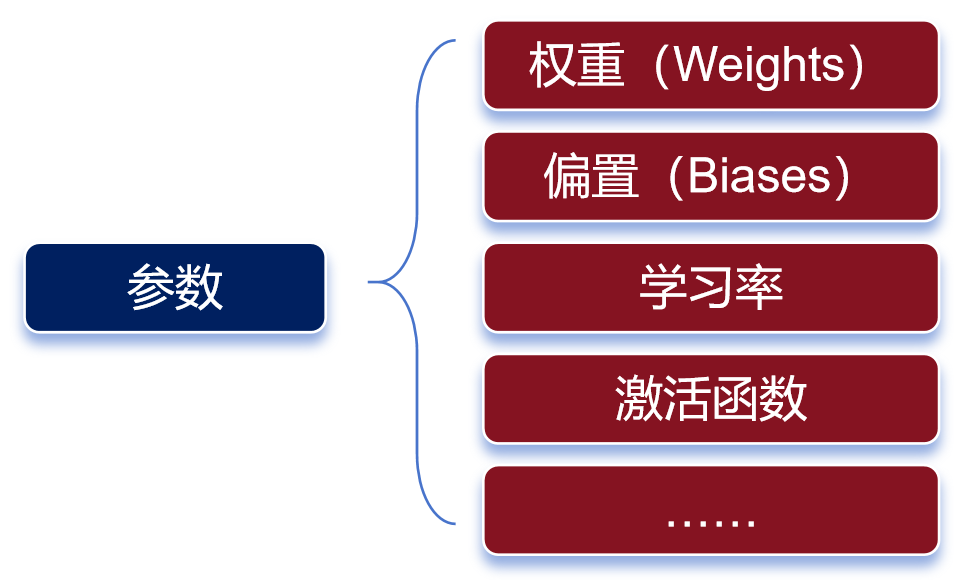
神经元的处理过程,其实就是一个函数计算过程。算式中,x是输入,y是输出。预训练,就是通过x和y,求解W。W是算式中的“权重(weights)”。权重决定了输入特征对模型输出的影响程度。通过反复训练来获得权重,这就是训练的意义。权重是最主要的参数类别之一。除了权重之外,还有另一个重要的参数类别——偏置(biases)。权重决定了输入信号对神经元的影响程度,而偏置则可以理解为神经元的“容忍度”,即神经元对输入信号的敏感程度。简单来说,预训练的过程,就是通过对数据的输入和输出,去反复“推算”最合理的权重和偏置(也就是参数)。训练完成后,这些参数会被保存,以便模型的后续使用或部署。参数越多,模型通常能够学习到更复杂的模式和特征,从而在各种任务上表现出更强的性能。我们通常会说大模型具有两个特征能力——涌现能力和泛化能力。当模型的训练数据和参数不断扩大,直到达到一定的临界规模后,会表现出一些未能预测的、更复杂的能力和特性。模型能够从原始训练数据中,自动学习并发现新的、更高层次的特征和模式。这种能力,被称为“涌现能力”。“涌现能力”,可以理解为大模型的脑子突然“开窍”了,不再仅仅是复述知识,而是能够理解知识,并且能够发散思维。泛化能力,是指大模型通过“投喂”海量数据,可以学习复杂的模式和特征,可以对未见过的数据做出准确的预测。简单来说,就像董宇辉一样,书读得多了,有些书虽然没读过,他也能瞎掰几句。参数规模越来越大,虽然能让大模型变得更强,但是也会带来更庞大的资源消耗,甚至可能增加“过拟合”的风险。过拟合,是指模型对训练数据学习得过于精确,以至于它开始捕捉并反映训练数据中的噪声和细节,而不是数据的总体趋势或规律。说白了,就是大模型变成了“书呆子”,只会死记硬背,不愿意融会贯通。预训练使用的数据,是海量的未标注数据(几十TB)。之所以使用未标注数据,是因为互联网上存在大量的此类数据,很容易获取。而标注数据(基本上靠人肉标注)需要消耗大量的时间和金钱,成本太高。预训练模型,可以通过无监督学习方法(如自编码器、生成对抗网络、掩码语言建模、对比学习等,大家可以另行了解),从未标注数据中,学习到数据的通用特征和表示。这些数据,也不是随便网上下载得来的。整个数据需要经过收集、清洗、脱敏和分类等过程。这样可以去除异常数据和错误数据,还能删除隐私数据,让数据更加标准化,有利于后面的训练过程。如果是个人和学术研究,可以通过一些官方论坛、开源数据库或者研究机构获取。如果是企业,既可以自行收集和处理,也可以直接通过外部渠道(市场上有专门的数据提供商)购买。预训练学习之后,我们就得到了一个通用大模型。这种模型一般不能直接拿来用,因为它在完成特定任务时往往表现不佳。微调,是给大模型提供特定领域的标注数据集,对预训练的模型参数进行微小的调整,让模型更好的完成特定任务。微调之后的大模型,可以称之为行业大模型。例如,通过基于金融证券数据集的微调,可以得到一个金融证券大模型。如果再基于更细分的专业领域进行微调,就是专业大模型(也叫垂直大模型)。我们可以把通用大模型理解为中小学生,行业大模型是大学本科生,专业大模型是研究生。微调阶段,由于数据量远小于预训练阶段,所以对算力需求小很多。大家注意,对于大部分大模型厂商来说,他们一般只做预训练,不做微调。而对于行业客户来说,他们一般只做微调,不做预训练。“预训练+微调”这种分阶段的大模型训练方式,可以避免重复的投入,节省大量的计算资源,显著提升大模型的训练效率和效果。预训练和微调都完成之后,需要对这个大模型进行评估。通过采用实际数据或模拟场景对大模型进行评估验证,确认大模型的性能、稳定性和准确性等是否符合设计要求。等评估和验证也完成,大模型基本上算是打造成功了。接下来,我们可以部署这个大模型,将它用于推理任务。换句话说,这时候的大模型已经“定型”,参数不再变化,可以真正开始干活了。大模型的推理过程,就是我们使用它的过程。通过提问、提供提示词(Prompt),可以让大模型回答我们的问题,或者按要求进行内容生成。根据训练的数据类型和应用方向,我们通常会将大模型分为语言大模型(以文本数据进行训练)、音频大模型(以音频数据进行训练)、视觉大模型(以图像数据进行训练),以及多模态大模型(文本和图像都有)。语言大模型,擅长自然语言处理(NLP)领域,能够理解、生成和处理人类语言,常用于文本内容创作(生成文章、诗歌、代码)、文献分析、摘要汇总、机器翻译等场景。大家熟悉的ChatGPT,就属于此类模型。音频大模型,可以识别和生产语音内容,常用于语音助手、语音客服、智能家居语音控制等场景。视觉大模型,擅长计算机视觉(CV)领域,可以识别、生成甚至修复图像,常用于安防监控、自动驾驶、医学以及天文图像分析等场景。多模态大模型,结合了NLP和CV的能力,通过整合并处理来自不同模态的信息(文本、图像、音频和视频等),可以处理跨领域的任务,例如文生图,文生视频、跨媒体搜索(通过上传图,搜索和图有关的文字描述)等。
今年以来,多模态大模型的崛起势头非常明显,已经成为行业关注的焦点。
如果按照应用场景进行分类,那么类别就更多了,例如金融大模型、医疗大模型、法律大模型、教育大模型、代码大模型、能源大模型、政务大模型、通信大模型,等等。
例如金融大模型,可以用于风险管理、信用评估、交易监控、市场预测、合同审查、客户服务等。功能和作用很多很多,不再赘述。截至2024年3月25日,中国10亿参数规模以上的大模型数量已经超过100个,号称“百模大战”。这些大模型的应用领域、参数规模各有不同,但是,背后都是白花花的银子。根据行业估测的数据,训练一个大模型,成本可能在几百万美元到上亿美元之间。例如,GPT-3训练一次的成本,约为140万美元。Claude 3模型的训练费用,高达约1亿美元。如此多的企业推出大模型,实际上也是一种资源的浪费。而且,大模型也分为开源大模型和闭源大模型。行业里有能力做闭源大模型的企业,并不是很多。大部分的大模型,都是基于开源大模型框架和技术打造的,实际上是为了迎合资本市场的需求,或者为了蹭热度。行业里,目前仍有部分头部企业在死磕参数规模更大的超大模型(拥有数万亿到数千万亿个参数),例如OpenAI、xAI等。马斯克之前就在X平台宣布,xAI团队已经成功启动了世界上最强大的AI训练集群。该集群由10万块H100组成,主要用于Grok 2和Grok 3的训练和开发。对于大部分企业来说,万卡和万亿参数其实已经是个天花板了,再往上走的意愿不强烈,钱包也不允许。随着行业逐渐趋于理性,现在大家的关注焦点,逐渐从“打造大模型”,变成“使用大模型”。如何将大模型投入具体应用,如何吸引更多用户,如何通过大模型创造收入,成为各大厂商的头等任务。
大模型落地,就涉及到能力“入”端(下沉到终端)。所以,AI手机、AI PC、具身智能的概念越来越火,成为新的发展热点。以AI手机为例,像高通、联发科等芯片厂商,都推出了具有更强AI算力的手机芯片。而OPPO、vivo等手机厂商,也在手机里内置了大模型,并推出了很多原生AI应用。第三方AI应用的数量,就更不用说了。截止目前,根据行业数据显示,具有AI功能的APP数量已达到300多万款。2024年6月,AIGC类APP的月活跃用户规模达6170万,同比增长653%。大模型入端,也带来了轻量化的趋势。为了在资源受限的设备上运行,大模型将通过剪枝、量化、蒸馏等技术进行轻量化,保持性能的同时减少计算资源需求。大模型是一个好东西,能够帮我们做很多事情,节约时间,提升效率。但是,大模型也是一把双刃剑,会带来一些新的挑战。
首先,是影响失业率。大模型所掀起的AI人工智能浪潮,肯定会导致一些人类工作岗位被替代,进而导致失业率上升。其次,是版权问题。大模型基于已有数据进行学习。大模型生成的内容,尤其是用于文本、图像、音乐和视频创作,可能引发版权和知识产权问题。它虽然帮助了创作,但也“引用”了人类创作者的作品,界限难以区分。长此以往,可能打击人类的原生创作热情。第三,大模型可能引发算法偏见和不公平。也就是说,训练数据中存在的偏差,会导致大模型学习到这些偏差,从而在预测和生成内容时表现出不公平的行为。模型可能无意中强化社会上的刻板印象和偏见,例如性别、种族和宗教等方面的偏见。大模型生成的内容也可能被用于政治宣传和操纵,影响选举和公共舆论。第四,被用于犯罪。大模型可以生成逼真的文本、图像、语音和视频,这些内容可能被用于诈骗、诽谤、虚假信息传播等恶意用途。第五,能耗问题。大模型的训练和推理需要大量的计算资源,这不仅增加了成本,还带来了巨大的碳排放。很多企业为了服务于资本市场或跟风,盲目进行大模型训练,消耗了大量的资源,也导致了无意义的碳排放。总而言之,大模型在伦理、法律、社会和经济层面带来的威胁和挑战还是很多的,需要更多时间进行探索和解决。好啦,以上就是今天文章的全部内容,希望对大家有所帮助!对于人工智能这个领域,小枣君也是学习阶段。文章如果有错漏的地方,还请大家多多指正!谢谢!