

分布式训练是破解超大模型训练时单机内存和速度限制的主要方法。随着训练的模型越来越大,分布式训练任务的集群规模也在不断扩大。GPU之间通信可以使用英伟达开发的NVLink进行高带宽互连,GPU卡间传输TB级别的数据变得可行。当单机多GPU不能满足需求时,多机分布式训练则需要通过InfiniBand互联实现较高的通信带宽来满足训练需求。InfiniBand是一种用于高性能计算的计算机网络通信标准,具有非常高的吞吐量和非常低的延迟,常被用于计算机之间和内部的数据互连。
随着从单机单卡(单GPU)到单机多卡,再转移到分布在多个机架和网络交换机上的多个节点,对应的分布式训练算法将变得更加复杂。分布式训练面临的难题是设备计算速度和节点通信速度不匹配的问题。一般来说,节点通过相对较低的带宽连接,在某些情况下它们的传输速度可能会比节点内传输速度差一个数量级,因此跨节点同步是个棘手的问题,对于分布式训练的通信效率优化至关重要。
除了从硬件上提升通信速度外,集群架构与通信算法也直接影响训练效率。本文将介绍两种典型的分布式训练架构:中心化架构与去中心化架构。其中,去中心化架构是当前分布式训练的主流架构;去中心化架构中的全归约算法是目前使用频率最高、用途最广的操作。
参数服务器(Parameter Server)是一种常见的分布式训练框架,它的核心思想在2010年分布式隐变量模型中被提出。
参数服务器的设计很直观,通过采用一个中心存储,也就是所谓的“参数服务器”存放参数,提供了在分布式训练中不同的节点之间同步模型参数的机制。每个节点仅需要保存它计算时所依赖的一部分参数,从而达到分布式并行训练的目的。
参数服务器框架主要包含两种类型的节点:服务器和工作节点。其中,服务器负责参数的存储和更新,而工作节点负责提供算力进行训练。图1是参数服务器的工作流程示意。
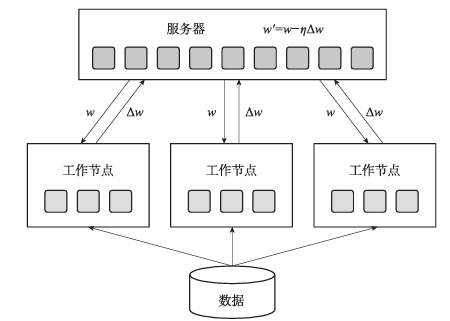
图1 参数服务器的工作流程示意
如图1所示,参数服务器训练的具体流程如下:
将模型参数分片,并存储在不同的服务器中。
将训练数据均匀分配给不同的工作节点。
工作节点:读取一批训练数据,从服务器中拉取最新的参数,计算梯度,并根据分片信息将结果上传至不同的服务器。
服务器:接收工作节点上传的梯度,根据优化算法聚合结果并更新参数。
参数服务器的扩展方式如下:
当训练数据过多,算力不足时,应该引入更多工作节点提高训练速度;
当模型参数过大,以至当前模型存储空间不足,或工作节点过多导致一个服务器成为瓶颈时,需要引入更多服务器。
参数服务器的结构虽然简单,但由于多个节点需要与中心参数服务器进行数据同步通信,因此服务器的带宽通常成为系统的瓶颈。虽然通过增加参数服务器的数量可以在一定程度上缓解,但无法从根本上解决瓶颈问题。
顾名思义,去中心化架构没有中心服务器,节点之间可以通过直接通信的方式进行协同训练。
具体而言,节点间的通信包括点对点通信(Point-to-pointCommunication)与集合通信(CollectiveCommunication)两种方式。
点对点通信采用单发单收的方式,原理简单,但通信效率相对较低,此处不再赘述。
集合通信采用多发多收的方式,多个节点协同工作,降低通信开销,提升通信效率。
去中心化架构比中心化架构拥有更好的扩展性,是当前分布式训练的主流架构。
为达到高效训练的目的,英伟达研发了NVIDIA集合通信库(NVIDIA Collective Communication Library,NCCL),实现了点对点通信与集合通信的原语。
NCCL并未实现全部的集合通信操作,它主要实现了加速GPU间通信从而加速分布式机器学习训练的操作子集,包括广播(Broadcast)、归约(Reduce)、聚集(Gather)、分散(Scatter)、归约分散(Reduce-Scatter)、全聚集(All-Gather)和全归约(All-Reduce)。
下面将从集合通信的基本操作入手,解释它们的含义,并讨论如何优化归约分散、全聚集和全归约的通信开销。
1.广播
广播操作用于将一个节点的数据复制到所有节点上。图2是一个三节点广播的示例。经过广播操作后,三个节点都获得了节点2的数据a。
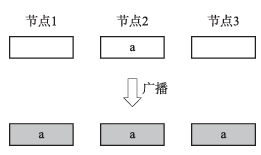
图2 广播操作示例
2.归约
归约操作用于将不同节点的部分数据用选定的算符(如求和、最大值、最小值等)收集并聚合成一个全局结果。图3是一个三节点进行求和的归约示例。经过归约操作后,得到三个节点求和后的结果a1+a2+a3并放置于节点2。
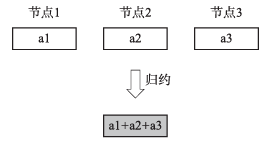
图3 归约操作示例
聚集操作用于将所有节点的数据收集到单个节点上,又称多对一操作(All-to-one)。它与归约的区别在于聚集仅将收集到的数据拼接在一起,而不做额外的算符聚合。
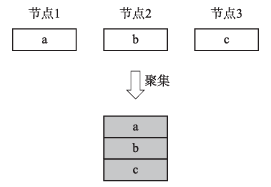
图4 聚集操作示例
图4是一个三节点进行聚集的示例。经过聚集操作后,三个节点的部分结果a、b、c被拼接后放置于节点2。
分散操作用于将一个节点的数据切分并分发到所有节点,又称一对多操作(One-to all)。图5是一个节点分散到三个节点的示例。经过分散操作,将节点2的结果切分为a、b、c三份,并依次放置于节点1、节点2和节点3上。
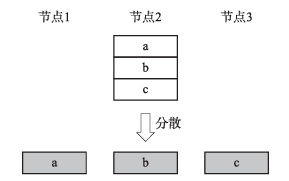
图5 分散操作示例
归约分散是先执行归约操作,然后再将归约后的部分结果分散放置于对应节点上。
前面介绍的参数服务器架构简单并易于使用,但它的主要问题在于随着GPU卡数的增加,服务器节点的通信量随之线性增长,服务器节点也会成为通信瓶颈。在给定通信带宽的情况下(不考虑延迟),训练所需通信时间会随着GPU数量的增加而线性增加。
为了解决此问题,环状通信算法被提出,每个节点仅与相邻节点通信。环状通信算法的优点在于数据传输的通信量是恒定的,不随GPU数量的增加而增加,通信时间仅受环中相邻节点之间最慢的链路带宽限制。
图6展示了环状归约分散的基本原理。
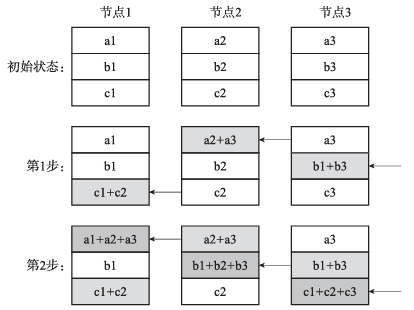
图6 环状归约分散的基本原理
全聚集操作将各节点的部分数据聚集在一起,并将完整的结果分发到各节点之上。全聚集的实现与归约分散的方式类似,也可以通过环状通信实现。图7展示了环状全聚集的执行过程。
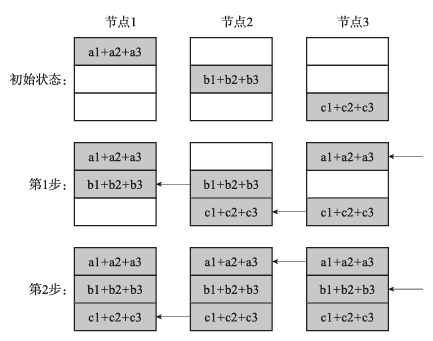
图7 环状全聚集操作示意
全归约操作与归约操作类似,区别在于全归约会将归约后的结果再分发给所有节点。图8是一个三节点全归约的示例。全归约算法将不同节点的数据聚合(此处以求和为例)成为一个单数组。
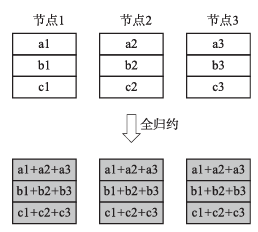
图8 全归约操作示意
在分布式机器学习训练中,全归约无疑是使用频率最高、用途最广的操作,它常用于从多个节点上梯度求和。因此,对于全归约的通信效率优化就非常重要。
全归约有许多不同的实现,最简单的实现是每个节点将自己的所有数据使用广播操作发给所有节点,但这样存在严重的带宽浪费问题。
于是,更高效的算法如环状全归约(Ring All-Reduce)和树状全归约(Tree All-Reduce)被提出,它们具有各自的优缺点和不同的应用场景。
环状全归约可由前文介绍的归约分散和全聚集操作组合实现。第一阶段的归约分散使得每个节点保存部分归约后的结果,第二阶段的全聚集可将每个节点的部分结果分散到所有节点上。整个过程如图6和图7所示,全归约的最终结果如图8所示,此处不再赘述。
环状通信虽然优化了通信带宽,但随着GPU数量的增加,环形拓扑会导致通信延迟线性增加。具体而言,当数据量V比较大时,延迟项可以忽略,前文分析成立。当V相对较小,或者节点数p很大时,带宽将不再是瓶颈,影响训练速度的主要因素变成了延迟,此时环状全归约的方案存在改进的空间。
于是,NCCL提出了树状全归约算法优化通信延迟,用满带宽的同时将延迟降至对数级,也就是树状拓扑的深度级别。树状全归约的实现依赖于双二叉树(DoubleBinaryTree)拓扑,如图9所示,将网络中的节点构造两棵互补的二叉树,该网络拓扑具有如下性质:
根节点0和31仅有一个父节点和一个子节点。
其余每个节点都有两个父节点和两个子节点。
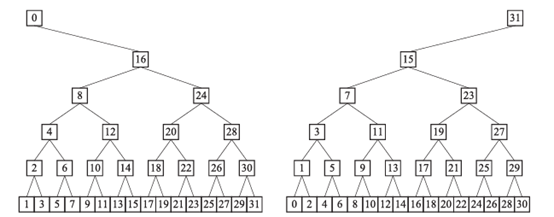
图9 两颗互补的二叉树
因此,当我们使用两棵树中的一棵处理一半的数据时,每个节点将最多接收和发送2倍的数据量,与环状全归约算法的实现相同。但这种连接方式可以将延迟由O(n)降至O(log(n))。
实验证明,当GPU数线性增加时,环状全归约算法的传输延迟也线性增加。但树状全归约算法的传输延迟呈对数级别增加,显著优于前者。
英伟达在24576块GPU上测试了两种算法的延迟,结果如图10所示。随着GPU数量的增加,环状通信算法的延迟呈线性增加,在24000块GPU的设定下,树状通信在延迟上可优化约180倍,此时树状通信的延迟显著优于环状通信。
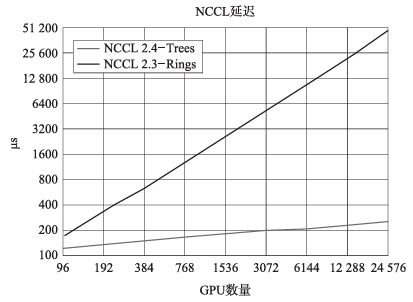
图10 环状通信和树状通信NCCL延迟对比
综上所述,选择合适的分布式训练架构与通信算法是实现大模型高效训练的关键。
作者简介:
苏之阳(博士),现任微软资深应用科学家,小冰前研发总监,专注于搜索排序算法和对话系统研发,曾主导了小冰智能评论和小冰框架等项目的架构设计和开发,在大语言模型的研发与应用方面具有丰富的经验。
王锦鹏(博士),致力于自然语言处理和推荐系统的研发,拥有在微软亚洲研究院等科技公司担任关键技术岗位的经验,参与了Office文档预训练、推荐大模型等多个重要项目的研发和优化工作。
姜迪(博士),拥有十余年工业界研发和管理经验,在雅虎、百度等知名互联网企业工作期间,为企业的多个关键业务研发了核心解决方案。
宋元峰(博士),曾就职于百度、腾讯等互联网公司,在人工智能产品开发领域拥有丰富的经验,研究涉及自然语言处理、数据挖掘与可视化等方向。
文章来源:IT阅读排行榜
本文摘编自《大语言模型:原理、应用与优化》,苏之阳、王锦鹏、姜迪、宋元峰 著,机械工业出版社出版,经出版方授权发布,转载请标明文章来源。
▼
延伸阅读

《大语言模型:原理、应用与优化》
苏之阳 等著
微软等大厂的4位博士撰写
为研究人员和开发者提供系统性参考
零基础理解大模型、构建大模型和使用大模型
内容简介:
这是一本从工程化角度讲解大语言模型的核心技术、构建方法与前沿应用的著作。首先从语言模型的原理和大模型的基础构件入手,详细梳理了大模型技术的发展脉络,深入探讨了大模型预训练与对齐的方法;然后阐明了大模型训练中的算法设计、数据处理和分布式训练的核心原理,展示了这一系统性工程的复杂性与实现路径。
除了基座模型的训练方案,本书还涵盖了大模型在各领域的落地应用方法,包括低参数量微调、知识融合、工具使用和自主智能体等,展示了大模型在提高生产力和创造性任务中的卓越性能和创新潜力。此外,书中进一步介绍了大模型优化的高级话题和前沿技术,如模型小型化、推理能力和多模态大模型等。最后,本书讨论了大模型的局限性与安全性问题,展望了未来的发展方向,为读者提供了全面的理解与前瞻性的视角。

本文来源:原创,图片来源:原创
责任编辑:王莹,部门领导:宁姗
发布人:白钰
