


----追光逐电 光赢未来----
Blob分析法(BlobAnalysis)
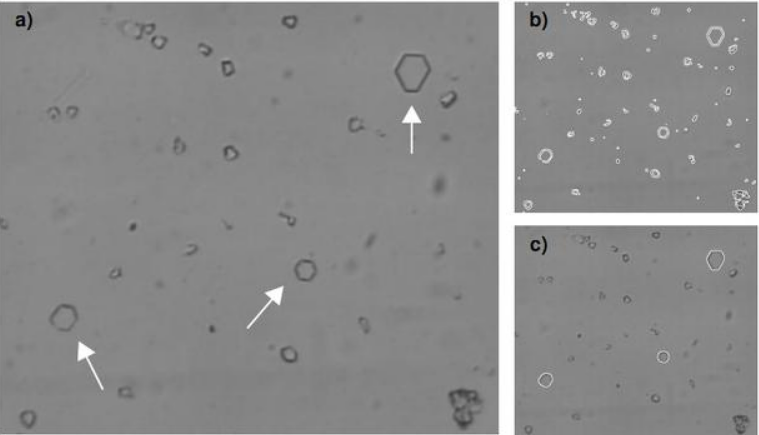
模板匹配法

深度学习法


总结来看,表示的选择会对机器学习算法的性能产生巨大的影响,监督学习训练的前馈网络可视为表示学习的一种形式。依此来看传统的算法如Blob分析和模板匹配都是手工设计其特征表示,而神经网络则是通过算法自动学习目标的合适特征表示,相比手工特征设计来说其更高效快捷,也无需太多的专业的特征设计知识,因此其能够识别不同场景中形状、大小、纹理等不一的目标,随着数据集的增大,检测的精度也会进一步提高。
综上,基于深度学习算法的优势,其在我司智慧物流领域也得到了较深的应用,例如视觉单件分离设备的包裹分割定位,3D视觉无序抓取工作栈的包裹轮廓识别、属性识别,3D视觉拆码垛工作栈的包裹识别引导等。对此,我司算法专家李博也表示:“AI的发展未来会在深度学习的基础上大放光彩,它将赋予机器多元感知、自主学习、自主分析、精准执行的能力”。
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


