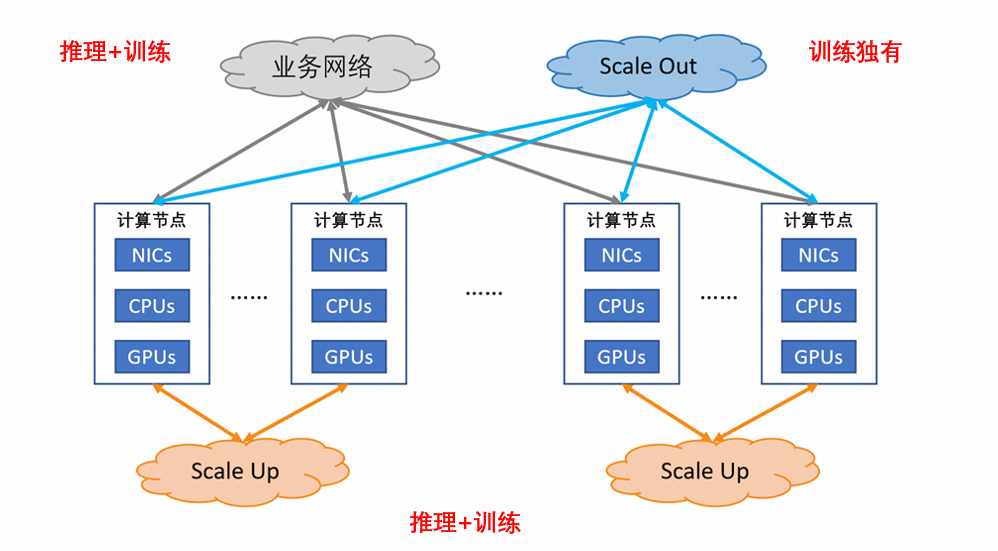
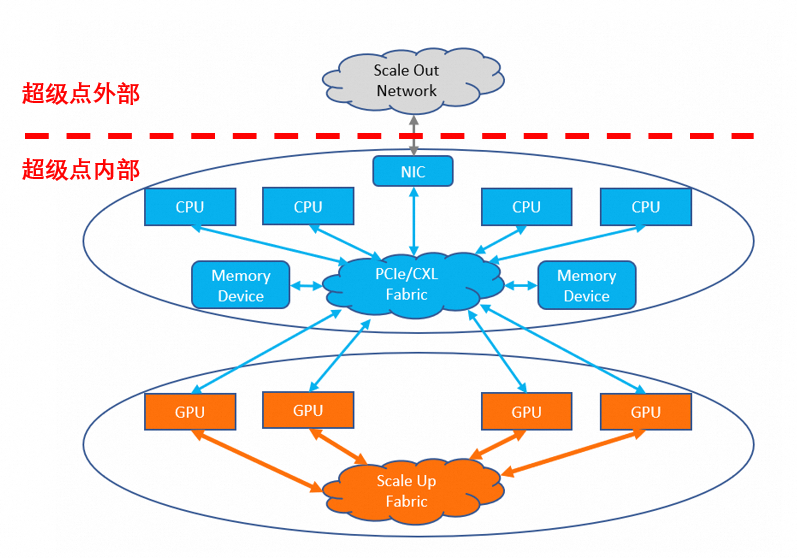
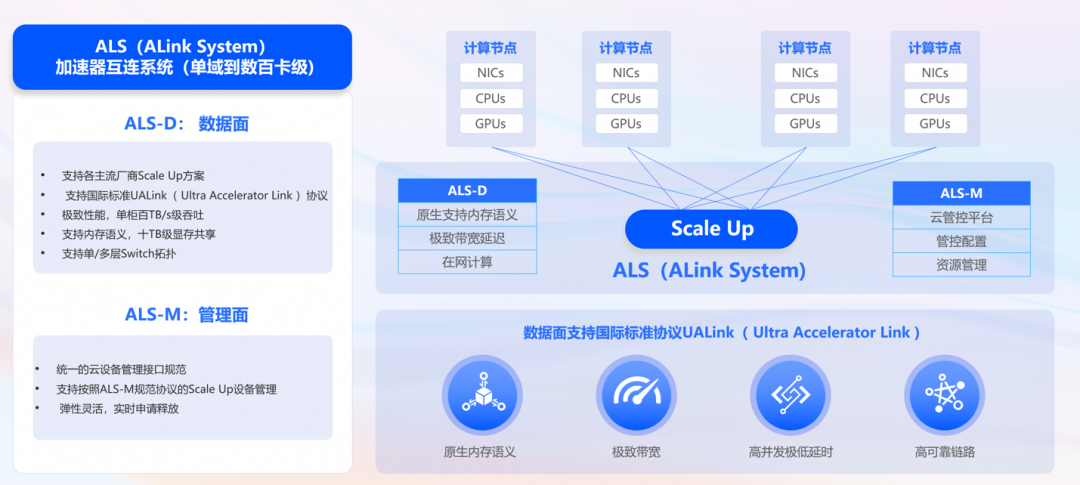
在GPU算力架构发展的历程和趋势中,我们意识到大模型的训练推理对显存容量以及带宽有不断增长的诉求,传统的GPU单机8卡方案已经不能满足业务发展的需要,更多卡组成超节点并具备大容量显存和低延的共享的解决方案才能满足大模型的需求。阿里云对行业技术方向进行评估后,于今年9月份发布了Alink Sytem开放生态和AI Infra 2.0服务器系统,其中底层互连协议部分兼容国际开放标准UALink协议。
一、SAE J1939协议概述SAE J1939协议是由美国汽车工程师协会(SAE,Society of Automotive Engineers)定义的一种用于重型车辆和工业设备中的通信协议,主要应用于车辆和设备之间的实时数据交换。J1939基于CAN(Controller Area Network)总线技术,使用29bit的扩展标识符和扩展数据帧,CAN通信速率为250Kbps,用于车载电子控制单元(ECU)之间的通信和控制。小北同学在之前也对J1939协议做过扫盲科普【科普系列】SAE J