


关注、星标公众号,直达精彩内容
最近部门时刻准备删库跑路的小兄弟调试CAN通讯的时候,遇到个MCU死机的问题,而负责这块代码的哥们已经跑路好几年了,而这个设备也已经用了好几年了,也没有反馈过什么问题。但是在他那里测试MCU 100%会死机,进入hardfault,一时间CPU都被干烧了,祖传的代码这么不靠谱吗....
最终问题定位在kfifo这部分出了问题,而kfifo是linux kernal里面非常经典的一段代码,应该不至于吧,对此进行了分析验证。
释义摘自:https://blog.csdn.net/linyt/article/details/53355355 讲解的很详细,如有侵权,联系删除~
kfifo是内核里面的一个First In First Out数据结构,它采用环形循环队列的数据结构来实现,提供一个无边界的字节流服务,并且使用并行无锁编程技术,即当它用于只有一个入队线程和一个出队线程的场情时,两个线程可以并发操作,而不需要任何加锁行为,就可以保证kfifo的线程安全。
kfifo代码既然肩负着这么多特性,那我们先一敝它的代码:
struct kfifo {
unsigned char *buffer; /* the buffer holding the data */
unsigned int size; /* the size of the allocated buffer */
unsigned int in; /* data is added at offset (in % size) */
unsigned int out; /* data is extracted from off. (out % size) */
spinlock_t *lock; /* protects concurrent modifications */
};
这是kfifo的数据结构,kfifo主要提供了两个操作,__kfifo_put(入队操作)和__kfifo_get(出队操作)。 它的各个数据成员如下:
buffer: 用于存放数据的缓存
size: buffer空间的大小,在初化时,将它向上扩展成2的幂
lock: 如果使用不能保证任何时间最多只有一个读线程和写线程,需要使用该lock实施同步。
in, out: 和buffer一起构成一个循环队列。 in指向buffer中队头,而且out指向buffer中的队尾,它的结构如示图如下:
+--------------------------------------------------------------+
| |<----------data---------->| |
+--------------------------------------------------------------+
^ ^ ^
| | |
out in size
当然,内核开发者使用了一种更好的技术处理了in, out和buffer的关系,我们将在下面进行详细分析。
kfifo提供如下对外功能规格:
kfifo_alloc 分配kfifo内存和初始化工作
struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, spinlock_t *lock)
{
unsigned char *buffer;
struct kfifo *ret;
/*
* round up to the next power of 2, since our 'let the indices
* wrap' tachnique works only in this case.
*/
if (size & (size - 1)) {
BUG_ON(size > 0x80000000);
size = roundup_pow_of_two(size);
}
buffer = kmalloc(size, gfp_mask);
if (!buffer)
return ERR_PTR(-ENOMEM);
ret = kfifo_init(buffer, size, gfp_mask, lock);
if (IS_ERR(ret))
kfree(buffer);
return ret;
}
这里值得一提的是,kfifo->size的值总是在调用者传进来的size参数的基础上向2的幂扩展,这是内核一贯的做法。这样的好处不言而喻——对kfifo->size取模运算可以转化为与运算,如下:
kfifo->in % kfifo->size
可以转化为
kfifo->in & (kfifo->size – 1)
在kfifo_alloc函数中,使用size & (size – 1)来判断size 是否为2幂,如果条件为真,则表示size不是2的幂,然后调用roundup_pow_of_two将之向上扩展为2的幂。
这都是常用的技巧,只不过大家没有将它们结合起来使用而已,下面要分析的__kfifo_put和__kfifo_get则是将kfifo->size的特点发挥到了极致。
__kfifo_put和__kfifo_get巧妙的入队和出队
_kfifo_put是入队操作,它先将数据放入buffer里面,最后才修改in参数;__kfifo_get是出队操作,它先将数据从buffer中移走,最后才修改out。你会发现in和out两者各司其职。
下面是__kfifo_put和__kfifo_get的代码
unsigned int __kfifo_put(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->size - fifo->in + fifo->out);
/*
* Ensure that we sample the fifo->out index -before- we
* start putting bytes into the kfifo.
*/
smp_mb();
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l);
/*
* Ensure that we add the bytes to the kfifo -before-
* we update the fifo->in index.
*/
smp_wmb();
fifo->in += len;
return len;
}
奇怪吗?代码完全是线性结构,没有任何if-else分支来判断是否有足够的空间存放数据。内核在这里的代码非常简洁,没有一行多余的代码。
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
这个表达式计算当前写入的空间,换成人可理解的语言就是:
l = kfifo可写空间和预期写入空间的最小值
使用min宏来代if-else分支
__kfifo_get也应用了同样技巧,代码如下:
unsigned int __kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->in - fifo->out);
/*
* Ensure that we sample the fifo->in index -before- we
* start removing bytes from the kfifo.
*/
smp_rmb();
/* first get the data from fifo->out until the end of the buffer */
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + l, fifo->buffer, len - l);
/*
* Ensure that we remove the bytes from the kfifo -before-
* we update the fifo->out index.
*/
smp_mb();
fifo->out += len;
return len;
}
原来,kfifo每次入队或出队,kfifo->in或kfifo->out只是简单地kfifo->in/kfifo->out += len,并没有对kfifo->size 进行取模运算。因此kfifo->in和kfifo->out总是一直增大,直到unsigned in最大值时,又会绕回到0这一起始端。但始终满足:
kfifo->in - kfifo->out <= kfifo->size
即使kfifo->in回绕到了0的那一端,这个性质仍然是保持的。
对于给定的kfifo:
数据空间长度为:kfifo->in - kfifo->out
而剩余空间(可写入空间)长度为:kfifo->size - (kfifo->in - kfifo->out)
尽管kfifo->in和kfofo->out一直超过kfifo->size进行增长,但它对应在kfifo->buffer空间的下标却是如下:
kfifo->in % kfifo->size (i.e. kfifo->in & (kfifo->size - 1))
kfifo->out % kfifo->size (i.e. kfifo->out & (kfifo->size - 1))
往kfifo里面写一块数据时,数据空间、写入空间和kfifo->size的关系如果满足:
kfifo->in % size + len > size
那就要做写拆分了,见下图:
kfifo_put(写)空间开始地址
|
\_/
|XXXXXXXXXX
XXXXXXXX|
+--------------------------------------------------------------+
| |<----------data---------->| |
+--------------------------------------------------------------+
^ ^ ^
| | |
out%size in%size size
^
|
写空间结束地址
第一块当然是: [kfifo->in % kfifo->size, kfifo->size]
第二块当然是:[0, len - (kfifo->size - kfifo->in % kfifo->size)]
下面是代码,细细体味吧:
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l);
对于kfifo_get过程,也是类似的,请各位自行分析。
kfifo_get和kfifo_put无锁并发操作
计算机科学家已经证明,当只有一个读经程和一个写线程并发操作时,不需要任何额外的锁,就可以确保是线程安全的,也即kfifo使用了无锁编程技术,以提高kernel的并发。
kfifo使用in和out两个指针来描述写入和读取游标,对于写入操作,只更新in指针,而读取操作,只更新out指针,可谓井水不犯河水,示意图如下:
|<--写入-->|
+--------------------------------------------------------------+
| |<----------data----->| |
+--------------------------------------------------------------+
|<--读取-->|
^ ^ ^
| | |
out in size
为了避免读者看到写者预计写入,但实际没有写入数据的空间,写者必须保证以下的写入顺序:
往[kfifo->in, kfifo->in + len]空间写入数据
更新kfifo->in指针为 kfifo->in + len
在操作1完成时,读者是还没有看到写入的信息的,因为kfifo->in没有变化,认为读者还没有开始写操作,只有更新kfifo->in之后,读者才能看到。
那么如何保证1必须在2之前完成,秘密就是使用内存屏障:smp_mb(),smp_rmb(), smp_wmb(),来保证对方观察到的内存操作顺序。
上面已经详细介绍了kfifo的实现原理以及让人惊叹的代码简洁之道,接下来在MCU工程中实际去应用,看看效果如何。
直接上代码:
kfifo.h
#ifndef __KFIFO_H
#define __KFIFO_H
#include "stdint.h"
#include "stdlib.h"
#include "string.h"
#include "stdio.h"
#define MAX(a, b) (((a) > (b)) ? (a) : (b))
#define MIN(a, b) (((a) < (b)) ? (a) : (b))
#define is_power_of_2(x) ((x) != 0 && (((x) & ((x)-1)) == 0))
typedef struct {
unsigned char *buffer; /* the buffer holding the data*/
unsigned int size; /* the size of the allocated buffer*/
unsigned int in; /* data is added at offset (in % size)*/
unsigned int out; /* data is extracted from off. (out % size)*/
} kfifo;
/**
* @brief CAN Rx message structure definition
*/
#define CAN_FIFO_SIZE (2 * 1024)
typedef struct {
uint8_t FifoBuf1[CAN_FIFO_SIZE];
// uint8_t FifoBuf2[CAN_FIFO_SIZE];
uint8_t FpStep;
} CAN_STA_TYPE;
/* USER CODE BEGIN Prototypes */
typedef struct {
uint32_t StdId;
uint32_t ExtId;
uint32_t IDE;
uint32_t RTR;
uint32_t DLC;
uint8_t Data[8];
uint32_t Timestamp;
uint32_t FilterMatchIndex;
} MyCanRxMsgTypeDef;
extern kfifo gFifoReg1;
extern kfifo gFifoReg2;
void kfifo_init(kfifo *fifo, unsigned char *buffer, unsigned int size);
unsigned int kfifo_put(kfifo *fifo, unsigned char *buffer, unsigned int len);
unsigned int kfifo_get(kfifo *fifo, unsigned char *buffer, unsigned int len);
unsigned int can_fifo_get(kfifo *fifo, unsigned char *buffer, unsigned int len);
void kfifo_reset(kfifo *fifo);
unsigned int kfifo_len(kfifo *fifo);
#endif
kfifo.c
#include "kfifo.h"
kfifo gFifoReg1;
kfifo gFifoReg2;
/*
* kfifo初始化
*/
void kfifo_init(kfifo *fifo, unsigned char *buffer, unsigned int size)
{
if (!is_power_of_2(size))
{
return;
}
fifo->buffer = buffer;
fifo->size = size;
fifo->in = fifo->out = 0u;
memset(fifo->buffer, 0, size);
}
/*
* __kfifo_put - puts some data into the FIFO, no locking version
* @fifo: the fifo to be used.
* @buffer: the data to be added.
* @len: the length of the data to be added.
*
* This function copies at most 'len' bytes from the 'buffer' into
* the FIFO depending on the free space, and returns the number of
* bytes copied.
*
* Note that with only one concurrent reader and one concurrent
* writer, you don't need extra locking to use these functions.
*/
unsigned int kfifo_put(kfifo *fifo, unsigned char *buffer, unsigned int len)
{
unsigned int l = 0;
len = MIN(len, fifo->size - fifo->in + fifo->out);
/* first put the data starting from fifo->in to buffer end*/
l = MIN(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer*/
memcpy(fifo->buffer, buffer + l, len - l);
fifo->in += len;
return len;
}
/*
* __kfifo_get - gets some data from the FIFO, no locking version
* @fifo: the fifo to be used.
* @buffer: where the data must be copied.
* @len: the size of the destination buffer.
*
* This function copies at most 'len' bytes from the FIFO into the
* 'buffer' and returns the number of copied bytes.
*
* Note that with only one concurrent reader and one concurrent
* writer, you don't need extra locking to use these functions.
*/
unsigned int kfifo_get(kfifo *fifo, unsigned char *buffer, unsigned int len)
{
unsigned int l = 0;
len = MIN(len, fifo->in - fifo->out);
/* first get the data from fifo->out until the end of the buffer*/
l = MIN(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer*/
memcpy(buffer + l, fifo->buffer, len - l);
fifo->out += len;
return len;
}
unsigned int can_fifo_get(kfifo *fifo, unsigned char *buffer, unsigned int len)
{
//__disable_irq();
len = kfifo_get(fifo, buffer, len);
//__enable_irq();
return len;
}
/*
* __kfifo_reset - removes the entire FIFO contents, no locking version
* @fifo: the fifo to be emptied.
*/
void kfifo_reset(kfifo *fifo)
{
fifo->in = fifo->out = 0;
}
/*
* __kfifo_len - returns the number of bytes available in the FIFO, no locking version
* @fifo: the fifo to be used.
*/
unsigned int kfifo_len(kfifo *fifo)
{
return fifo->in - fifo->out;
}
因为是单线程读写,所以没有进行加锁操作。
回到问题背景所说的,之前用的时候一直没问题,现在测试100%把CPU干冒烟,为何会有如此大的差别?
回顾了下测试环境,“跑路的工程师”调试的时候使用的上位机是自定义的数据发送间隔时间,对与kfifo来说,发个间隔时间较大,kfifo进出次数不会差太多,kfifo是“反应的过来”的,实际使用过的时候,上位机替换成了APP,数据发送间隔更大,所以没有出问题。
现在,“准备删库跑路的工程师”,用的是固定间隔的上位机,而且数据发送频率很高,接收使用的CAN中断接收,发送的时候是使用的任务轮询,任务运行周期是100ms,创建的buffer缓冲为2048字节,发送一会儿就会死机,100%复现,增大buffer,不过是死的时间晚了点,虽迟但到~~~
void can_nbbus_entry(void *parameter)
{
nbbus_can_init();
while (1)
{
nbbus_poll(&nbbus_can, NB_BUS_BATDIAG_ID);
rt_thread_mdelay(100);
}
}
于是对数据帧进行了分析,can接收到的原始数据帧是没问题的,前面没出问题的数据一直没问题,MCU崩溃的时候,CAN接收到的原始数据依然是没问题的,原始数据既然没问题,问题应该出在后面解析转发流程了,分析最终定位在数据帧出现了错位,CAN数据帧的数据出现了移位,导致can数据长度字节取了一个比较大的数,数据拷贝的时候出现了越界,擦出了内存中的一些数据,进入了hardfault
那么为什么CAN数据帧出现了错位呢,并且似乎出现在某一固定时刻?
can数据接收数据如下,can的结构体有36字节,每次kfifo_put传入的len为36字节,剩余空间与36字节进行比较
typedef struct
{
uint32_t StdId;
uint32_t ExtId;
uint32_t IDE;
uint32_t RTR;
uint32_t DLC;
uint8_t Data[8];
uint32_t Timestamp;
uint32_t FilterMatchIndex;
} MyCanRxMsgTypeDef;
void HAL_CAN_RxFifo1MsgPendingCallback(CAN_HandleTypeDef *hcan)
{
HAL_StatusTypeDef HAL_RetVal;
if (hcan == &hcan1)
{
HAL_RetVal = HAL_CAN_GetRxMessage(hcan, CAN_RX_FIFO1, (CAN_RxHeaderTypeDef *)&gCanRxMsg11, gCanRxMsg11.Data);
if ( HAL_OK == HAL_RetVal)
{
kfifo_put(&gFifoReg1, (uint8_t *)&gCanRxMsg11, sizeof(gCanRxMsg11));
__HAL_CAN_ENABLE_IT (hcan, CAN_IT_RX_FIFO1_MSG_PENDING);
}
}
}
接下来着重分析下数据是如何产生错乱的,前面说到定义了2048字节的buffer缓存空间,对存储空间结构分组如下:
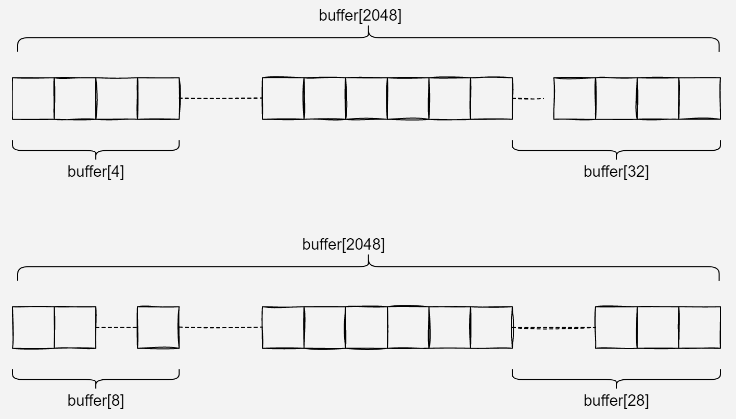
总共2048字节缓存空间,可以划分为36*56 = 2016 + 32 = 2048,也就意味着最后一帧数据32字节存储在尾端32字节空间,剩余4字节存储在队列头部4字节空间
那么一个循环之后,后面剩余2048-4=2044字节,可以划分为36*56 = 2016 + 28 = 2044字节,同理循环之后,最后一帧数据28字节存储在队列尾部28字节空间,8字节数据存储在队列头部8字节空间
如此循环往复,不再赘述.......
然后软件层面进行了模拟测试 测试代码如下:
CAN_STA_TYPE gCanStaReg = {0};
MyCanRxMsgTypeDef gCanTempMsg = {0};
MyCanRxMsgTypeDef gCanRxMsg20 = {0};
int main() {
uint16_t fifo_len = 0;
MyCanRxMsgTypeDef gCanRxMsg10 = {
0, 0x01B0AABF, 0x56, 0x78, 0x8, {1, 2, 3, 4, 5, 6, 7, 8}, 0x77, 0x44};
kfifo_init(&gFifoReg1, gCanStaReg.FifoBuf1, CAN_FIFO_SIZE);
int i = 0, j = 0;
while (1) {
i++;
if (i % 5 == 0) {
kfifo_put(&gFifoReg1, (uint8_t *)&gCanRxMsg10, sizeof(gCanRxMsg10));
}
j++;
if (j % 10 == 0) {
if ((fifo_len = kfifo_len(&gFifoReg1)) >= sizeof(gCanTempMsg)) {
can_fifo_get(&gFifoReg1, (uint8_t *)&gCanTempMsg, sizeof(gCanTempMsg));
printf("stdid = %04x\n", gCanTempMsg.StdId);
printf("exdid = %04x\n", gCanTempMsg.ExtId);
printf("ide = %04x\n", gCanTempMsg.IDE);
printf("rtr = %04x\n", gCanTempMsg.RTR);
printf("DLC = %04x\n", gCanTempMsg.DLC);
printf("data:\n");
for (int i = 0; i < 8; i++) {
printf("%02x ", gCanTempMsg.Data[i]);
}
printf("Timestamp = %04x\n", gCanTempMsg.Timestamp);
printf("FilterMatchIndex = %04x\n\n\n\n", gCanTempMsg.FilterMatchIndex);
}
printf("in_index = %d,out_index = %d,index_diff = %d\n", gFifoReg1.in,
gFifoReg1.out, gFifoReg1.in - gFifoReg1.out);
printf("-----arr----\n\n");
for (i = 0; i < 2048; i++) {
if (i % 36 == 0) {
printf("%d \n",i/36);
}
printf("%02x ", gFifoReg1.buffer[i]);
}
printf("\n\n");
if (gCanTempMsg.DLC > 8) {
printf("-----error----\n\n");
printf("in_index = %d,out_index = %d,index_diff = %d\n", gFifoReg1.in,
gFifoReg1.out, gFifoReg1.in - gFifoReg1.out);
return 0;
}
}
Sleep(10);
}
return 0;
}
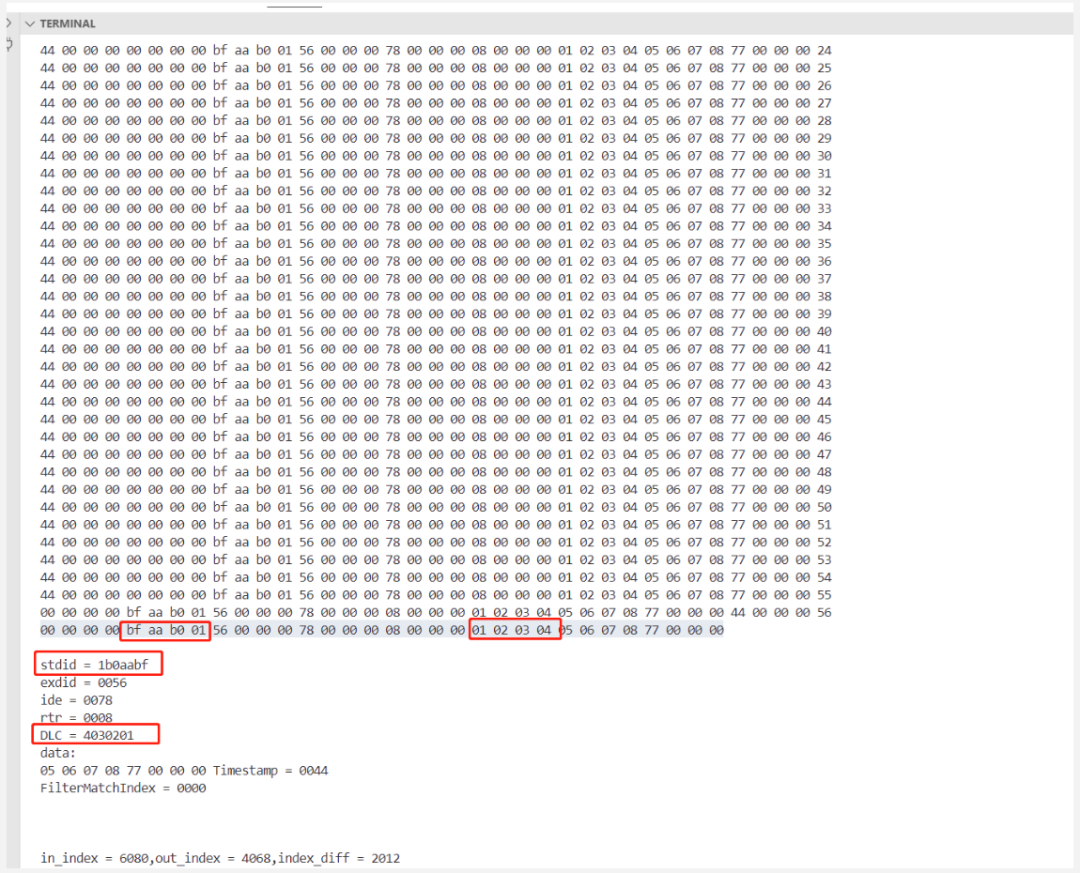
使用上面的测试代码复现了问题,出现了数据的错位,相差4个字节,本来应该是长度的字节,被数据区四字节给填充了,导致数据长度异常变大,数据copy过程中覆盖了部分ram空间,导致程序崩溃
出现上面问题的核心原因是数据放的速度远大于取得速度,导致数据存储扣圈出现错位,这种用法可能背离了kfifo原本的设计使用场景,导致出现问题。
这个方法最简单,只需要调整kfifo_get的调用周期即可,结合kfifo_put的调用周期,保持在不高于kfifo_put的调用周期应该都是可以的,实测改为了10ms取数据之后,不再出现数据异常,MCU进入hardfault的问题。
上面提到数据取得慢了,出现了扣圈的情况,数据存储与读取出现了“内存错位”,那我们可以从空间剩余的情况考虑,假设剩余空间不足以放下一帧数据,等一等取数据的指针。
代码优化,增加忙判断,空间不足,认为是忙,但这种情况可能会导致一些数据帧的丢失,响应滞后,对于实时性特别高的场景可能不太适用,实际测试也不会出现数据内存错位。
boolean is_busy(kfifo *fifo, uint8_t len) {
if ((fifo->in - fifo->out) < len) {
return TRUE;
}
return FALSE;
}
int main() {
uint16_t fifo_len = 0;
MyCanRxMsgTypeDef gCanRxMsg10 = {
0, 0x01B0AABF, 0x56, 0x78, 0x8, {1, 2, 3, 4, 5, 6, 7, 8}, 0x77, 0x44};
kfifo_init(&gFifoReg1, gCanStaReg.FifoBuf1, CAN_FIFO_SIZE);
int i = 0, j = 0;
while (1) {
i++;
if ((i % 5 == 0) && is_busy(&gFifoReg1, sizeof(gCanRxMsg10))) {
kfifo_put(&gFifoReg1, (uint8_t *)&gCanRxMsg10, sizeof(gCanRxMsg10));
}
j++;
if (j % 10 == 0) {
if ((fifo_len = kfifo_len(&gFifoReg1)) >= sizeof(gCanTempMsg)) {
can_fifo_get(&gFifoReg1, (uint8_t *)&gCanTempMsg, sizeof(gCanTempMsg));
printf("stdid = %04x\n", gCanTempMsg.StdId);
printf("exdid = %04x\n", gCanTempMsg.ExtId);
printf("ide = %04x\n", gCanTempMsg.IDE);
printf("rtr = %04x\n", gCanTempMsg.RTR);
printf("DLC = %04x\n", gCanTempMsg.DLC);
printf("data:\n");
for (int i = 0; i < 8; i++) {
printf("%02x ", gCanTempMsg.Data[i]);
}
printf("Timestamp = %04x\n", gCanTempMsg.Timestamp);
printf("FilterMatchIndex = %04x\n\n\n\n", gCanTempMsg.FilterMatchIndex);
}
printf("in_index = %d,out_index = %d,index_diff = %d\n", gFifoReg1.in,
gFifoReg1.out, gFifoReg1.in - gFifoReg1.out);
// printf("-----arr----\n\n");
// for (i = 0; i < 2048; i++) {
// if (i % 36 == 0) {
// printf("%d \n",i/36);
// }
// printf("%02x ", gFifoReg1.buffer[i]);
// }
// printf("\n\n");
if (gCanTempMsg.DLC > 8) {
printf("-----error----\n\n");
printf("in_index = %d,out_index = %d,index_diff = %d\n", gFifoReg1.in,
gFifoReg1.out, gFifoReg1.in - gFifoReg1.out);
return 0;
}
}
Sleep(10);
}
return 0;
}
综上所述,为了保证数据的实时性要求,存储和读取的周期配合尤为重要,为最优解,实时性要求不高的,可以考虑增加忙判断的方式。
问题解决掉,删库跑路的小哥暂时不用跑了,又可以一块愉快的写代码了~
欢迎关注公众号“小飞哥玩嵌入式”,一起解锁更多的嵌入式开发技能。

