最近,一直采用激光雷达和高精地图实现 L4 的自动驾驶公司 Waymo 的一个内部研究团队,发布了一篇关于利用端到端多模态自动驾驶模型实现自动驾驶的新论文。
它采用类似于 ChatGPT 的大语言模型 Gemini LLM 作为算法核心,算法所有的输入和输出表示为普通文本,具有非常强大的通用性和泛化性,算法还具有可解释性。
引起了自动驾驶行业的轰动。所以,本文将初步总结和介绍Waymo 的端到端多模态自动驾驶模型EMMA相关信息:
希望能给大家带来一些智能驾驶和汽车发展的信息和思路。
目前智能驾驶行业算法的四种算法方案:
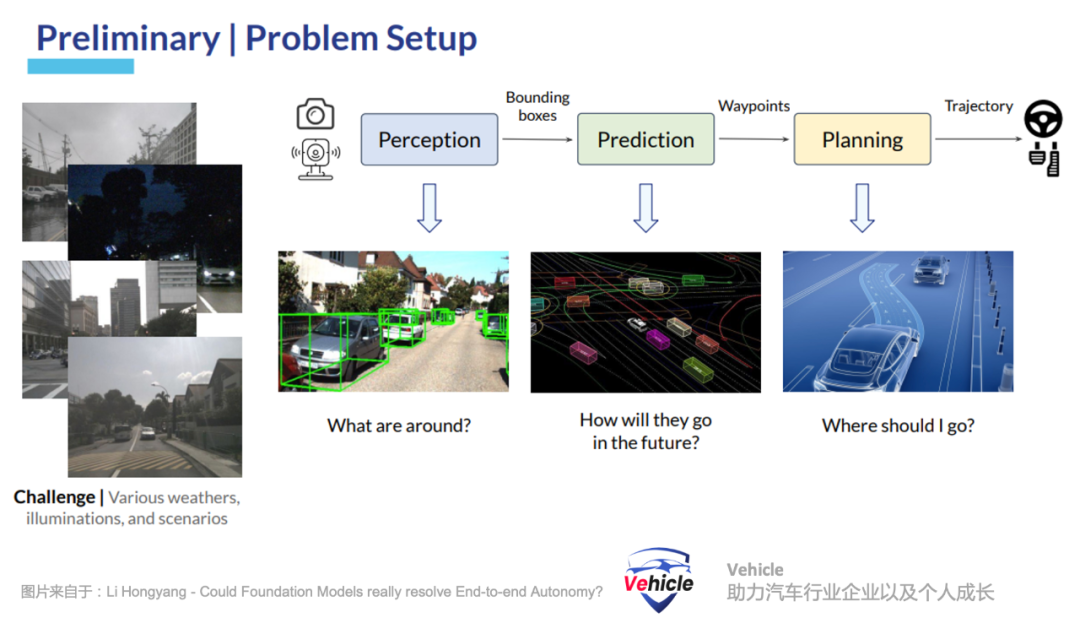
模块化自动驾驶算法
模块化的高阶智能驾驶系统采用,感知 、地图、预测和规划等不同的模块或者组件来实现。
这种设计便于单个模块或组件的调试和优化,但由于模块间的错误积累和模块间的通信有限,它在可扩展性方面面临挑战。特别需要指出的是,这些模块通常是基于目标场景预先定义的,所以,这些基于规则设计的模块间接口(例如感知和行为模块之间的接口)可能难以适应新环境。
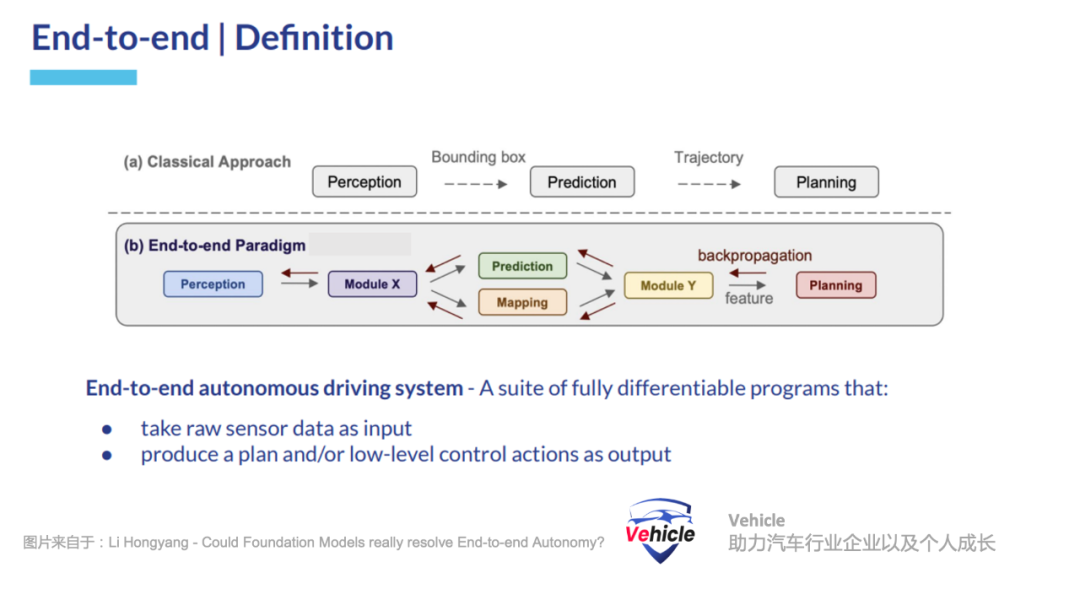
这种方案在现在的智能驾驶应用,能够实现针对性场景下高性能,高性价比,我们之前文章《被逼墙角的Mobileye,祭出 CAIS 大旗,挑战端到端大模型智能驾驶》中介绍的Mobileye是这方面的强者代表。特斯拉FSD V12,首先发起在智能驾驶方面采用端到端的自动驾驶算法,直接从传感器数据学习生成驾驶行为。该方法消除了模块之间信号接口的需求,并允许从原始传感器输入联合优化驾驶目标。这种端到端算法是专门针对驾驶这种特定的任务,它需要收集大量的道路驾驶数据来训练全新的模型。这也就是当前特斯拉以及国内一众智能驾驶公司的方法,数据,算力为王,大家都在卖力重复造自己的轮子,希望有朝一日自己轮子能够成为米其林或者马牌轮胎,独步天下。但是,长尾理论一直存在,大家一直在 push 寻找这个长尾到底有多长。我们之前文章《智能驾驶技术演进与未来挑战:从目标物识别到大模型上车》分享了将现有智能驾驶系统的能力与多模特语言模型进行整合和增强的案例,它就是借用大语言模型对世界理解的能力去解读道路图片信息来增强端到端算法能力,弥补长尾。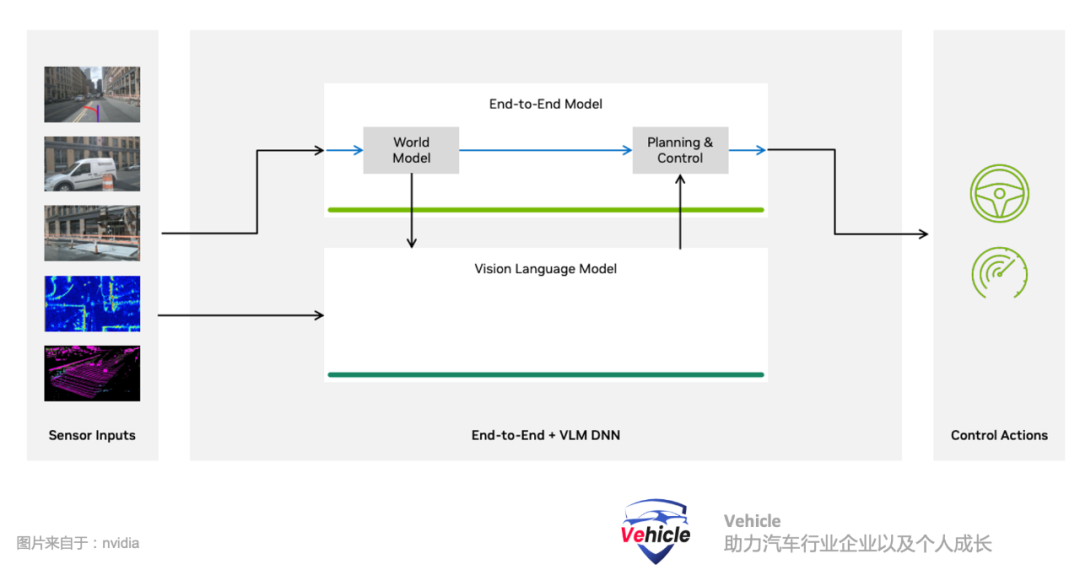
业内理想汽车最新的自动驾驶就是采用此类方案E2E大模型+LVM图像语言模型。本文介绍的 Waymo 端到端多模态自动驾驶模型EMMA是另外一种方法,当然它目前只是学术论文,没有进行工程化。它采用多模态大型语言模型为自动驾驶中的人工智能提供了一个有前景的新范式,采用专门针对驾驶调整过的通用基础大语言模型,作为智能驾驶算法的核心算法或者组件。大语言模型在两个关键领域表现出色,所以采用它不需要重新训练一个模型:- 他们是基于人类在互联网上积累的文字信息训练而成,所以可以理解为三体中的“智子”他把人类丰富的“世界知识”全部折叠进入它算法内,它的知识量远远超过我们常见驾驶日志中所包含的内容。
- 它们通过链式思维推理等技术展示了卓越的推理能力 ,这些能力在专用驾驶系统中并不具备。
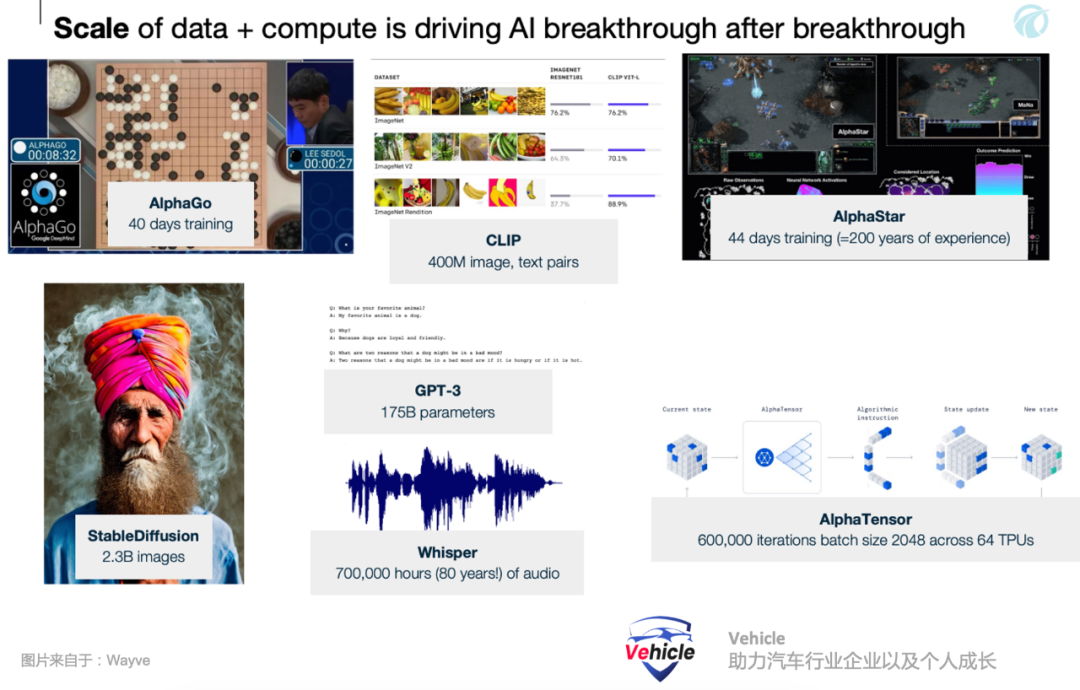
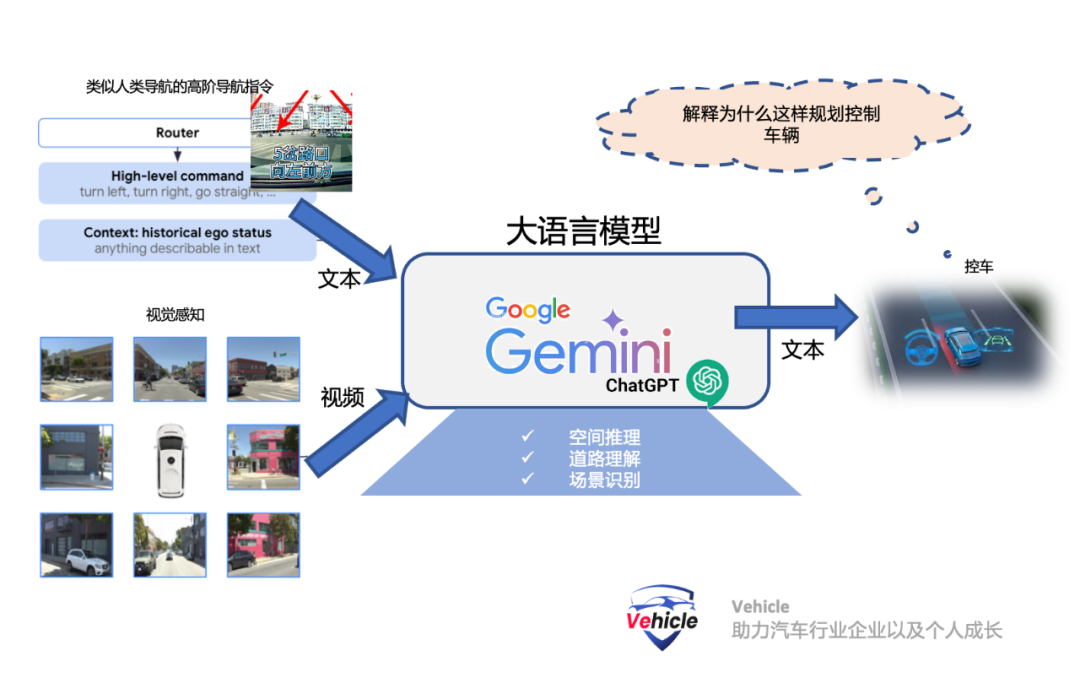
其实目前业内已经有两三家开始靠近这个方案,例如我们之前文章《探秘美国加州自动驾驶路试:豪横竞逐、勤奋探索与技术挑战》提到的采用Open AI大模型的 Ghost (今年已经倒闭)和 Wayve,但他们应该是部分采用这个思维。“端到端多模态自动驾驶模型”(EMMA)是怎么做的?“端到端多模态自动驾驶模型”(EMMA)是以谷歌的大语言模型 Gemini 框架为算法核心构建。Gemini 是一个基于文本的 LLM,类似于 Open AI的 ChatGPT,它使用大量通用文本语料库进行训练,从而获得世界和人类自然语言的知识。同时该算法针对大量有关道路和驾驶的文本以及许多其他通用知识进行训练和微调。此外,还添加了基于驾驶视频的“端到端”训练。EMMA的关键创新在于能够同时处理视觉输入(如摄像头图像)和非视觉输入(如基于文本的驾驶指令和历史上下文)。通过将驾驶任务重新表述为视觉问答(VQA)问题,这样,EMMA能够利用Gemini原有模型中编码的大量知识,同时赋予其处理各种驾驶任务的能力。- 多模态输入:EMMA接受摄像头图像(视觉数据)以及导航等文本输入,驾驶指令和历史上下文,使其能够理解并应对涉及视觉和非视觉信息的复杂驾驶场景。
- 视觉问答VQA方法:将驾驶任务重新表述为视觉问答问题,允许EMMA在文本指令的上下文中解读视觉数据。这有助于模型更好地理解驾驶中的动态和多样化的情况。
- 使用任务特定提示进行微调:EMMA通过使用驾驶日志和任务特定的提示进行微调,从而使其能够生成各种驾驶输出,如运动规划的未来轨迹、感知目标、道路图元素和场景语义等。
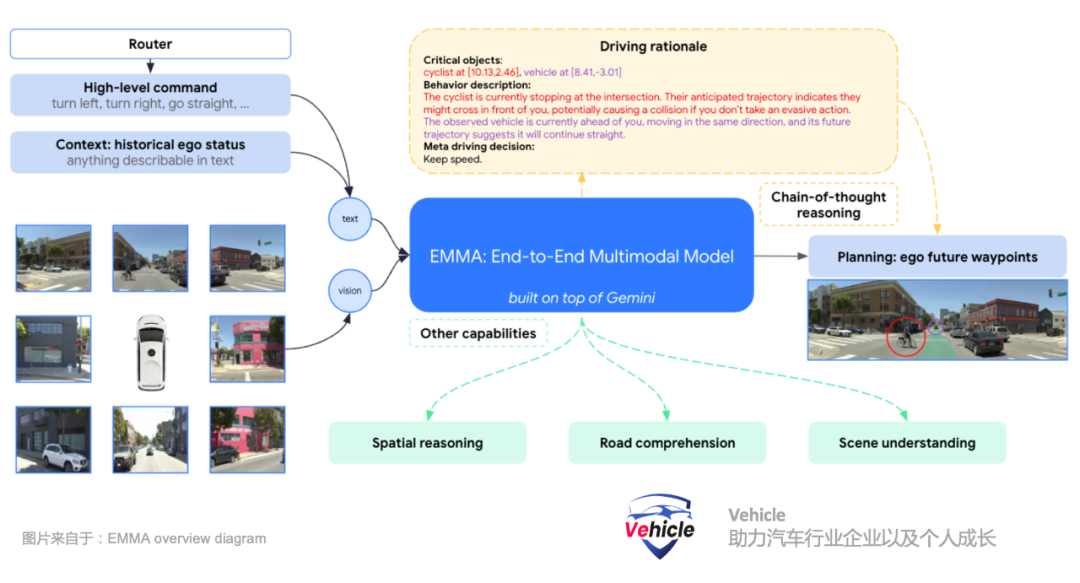
导航指令,类似于人类使用导航一样,系统接收来自于导航的high level高层次文本指令,例如前方100m左转,前方路口右转等等类似指令。自车的历史状态,表示为不同时间戳下的鸟瞰视图(BEV)空间中的一组路标坐标。所有的路标坐标都表示为普通文本,不使用专门的标记。方便扩展为包含更高阶的自车状态,如速度和加速度。摄像头视频感知。通过摄像头感知三维世界、识别周围的物体、道路图以及交通状况。Waymo 团队将EMMA构建为一个通用模型,能够通过训练混合处理多个驾驶任务。Waymo 团队使用视觉-语言框架将所有的输入和输出表示为普通文本,从而提供了将许多其他驾驶任务融入系统的灵活性。对原有大语言模型采用指令微调(instruction-tuning),将感知任务组织为三个主要类别:空间推理、道路图估计和场景理解。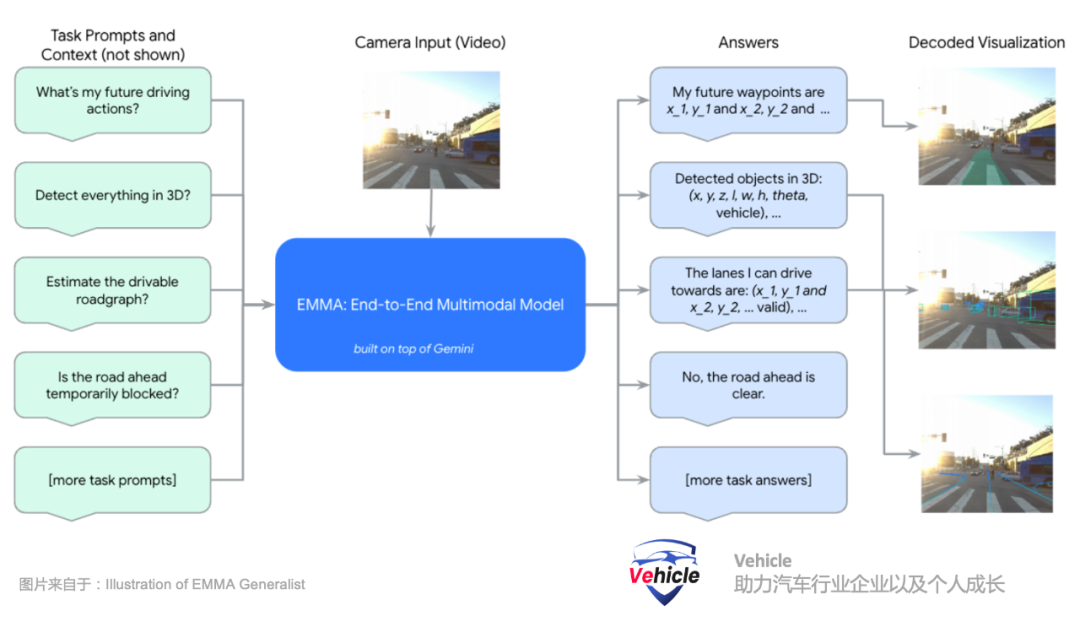
- 空间推理是理解、推理并得出关于物体及其在空间中的关系的能力。这使得自动驾驶系统能够解释并与其周围环境互动,从而实现安全导航。Waymo 团队巧妙的将空间推理结果的7维框((x, y, z)是车辆坐标系中的中心位置,l, w, h是边界框的长、宽和高,θ是航向角)转换为文本表示。
- 道路图估计侧重于识别关键的道路元素,以确保安全驾驶,包括语义元素(如车道标线、标志)和物理属性(如车道曲率)。这些道路元素集合构成了道路图。
- 场景理解任务测试模型对整个场景上下文的理解,这对于驾驶尤为重要。例如,由于施工、紧急情况或其他事件,道路可能暂时被堵塞。及时检测这些堵塞并安全绕行对于确保自动驾驶车辆的顺畅和安全运行至关重要;然而,场景中的多个线索必须结合起来才能确定是否存在堵塞。
所有的输入和输出都是文本信息,EMMA通过使用驾驶日志和任务特定的提示进行微调,从而使微调的 LLM 语言大模型能够生成各种驾驶输出运动规划和驾驶控制信号。- 自监督:唯一需要监督的是自车未来的位置,不需要专门的人工标签。
- 无需高清地图:除了来自导航系统(如Google Maps类似于我们用的高德和百度地图)的高层次导航信息外,不需要高清地图。
其实端到端大模型,最大的问题是可解释性,EMMA引入了链式思维提示(Chain-of-Thought Prompting),它可以增强多模态大型语言模型(MLLMs)的推理能力,并提高其可解释性。在EMMA中,Waymo团队通过要求模型在预测最终的未来轨迹路标Otrajectory 时阐明其决策理由(Orationale),将链式思维推理融入端到端规划轨迹生成中。Waymo 团队将驾驶推理结构化为四种粗到细的信息类型:- R1 - 场景描述:广泛描述驾驶场景,包括天气、时间、交通状况和道路条件。例如:“天气晴朗,白天。道路是四车道的未分隔街道,中间有行人道,街道两边停着车。”
- R2 - 关键物体:指那些可能影响自车驾驶行为的路面上的其他代理物体,我们要求模型识别其精确的3D/BEV坐标。例如:“行人位于[9.01, 3.22],车辆位于[11.58, 0.35]。”
- R3 - 关键物体的行为描述:描述已识别关键物体的当前状态和意图。例如:“行人目前站在人行道上,朝向道路,可能准备过马路。车辆目前在我前方,朝相同方向行驶,未来轨迹表明它将继续直行。”
- R4 - 元驾驶决策:包括12类高层次驾驶决策,总结基于前述观察的驾驶计划。例如:“我应该保持当前的低速。”
Waymo 团队强调,驾驶推理文本是通过自动化工具生成的,而没有任何额外的人工标签,从而确保了数据生成流程的可扩展性。Waymo 团队指出其当前模型每次只能处理有限数量的图像帧(最多4帧),搞自动驾驶的朋友肯定知道,当前牵扯安全的场景,甚至可能需要更多帧图片来确定场景。同时这限制了其捕捉驾驶任务所需的长期依赖关系的能力。有效的自动驾驶不仅需要实时决策,还需要在较长的时间范围内进行推理,能够预测并应对不断变化的场景。另外,目前,哪里有能跑如此多参数的大模型车载算力芯片,我们之前文章《高通的下一代智能汽车芯片 - 骁龙 Cockpit Elite 和 Ride Elite》介绍过高通下一代智能汽车芯片,最大能跑数十亿个参数的大型语言模型;最近小鹏AI日表示其新一代Turing芯片也最高可运行300亿 参数大模型,还不知道何时能上车。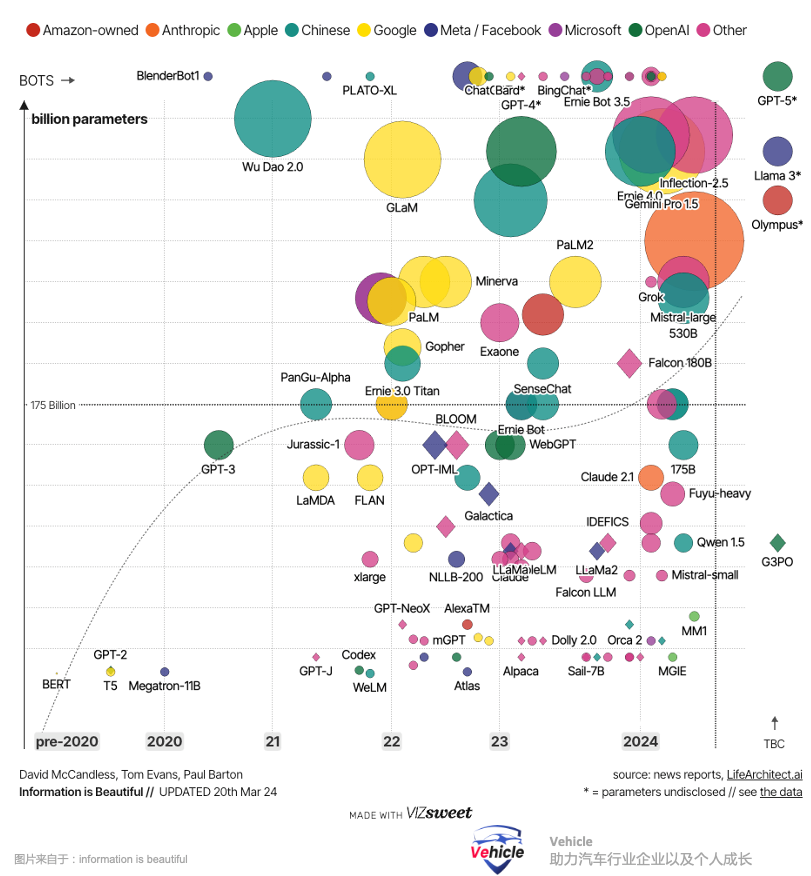
除此之外,随着算力的增大,整个计算系统从缓存到带宽再到热管理都需要跟上,这都需要当前车载算力平台能够跟上。
同时,另外一个要命的问题是实时性,大模型用作ChatGPT对话,或者Midjourny画图延迟几秒完全没问题,不会影响到生命安全,但是对于汽车来讲毫秒必争,都是事关安全。总的来讲,当前大语言模型,需要通过蒸馏,来缩小参数,保证一定的准确性来实现。所以这个方法必须要优化模型,或者将其蒸馏成适合实时部署的更紧凑版本,同时确保不牺牲性能和安全。此外,当前这个模型可以直接预测驾驶信号,而无需依赖中间输出(如物体检测或道路图估计)。这种方法在实时验证和后期分析时带来了挑战。尽管Waymo 团队已经证明,模型可以生成如物体和道路图预测这样的可解释输出,并且驾驶决策可以通过思维链推理来解释,但这些输出与实际驾驶信号之间并不总是能够完全一致,也就是说这个可解释性目前有时候也会出错。最后,当前的模型主要依赖于预训练的多模态大语言模型(MLLMs),这些模型通常不包括LiDAR或雷达输入,汽车冗余多传感器方案部署是个大问题。- 强大算力的芯片,支持本地高达百亿,千亿参数的LLM大模型。
- 蒸馏优化后缩小参数可以部署上车的大模型,适合实时部署,同时确保不牺牲性能和安全,这个有点和小鹏汽车的云端大模型,车端小模型理论相吻合。
首先,Waymo 发布的端到端多模态自动驾驶模型 EMMA 给智能驾驶时代又添加了一颗定心丸,当前基于AI的人工智能,端到端方案理论上能够实现自动驾驶,接下来就是工程化落地。另外,通用人工智能会成为智能驾驶的发动机,智能汽车的划分,可以通过模型参数和算力来实现能力的分级,犹如燃油车时代,发动机排量决定车辆的等级和性能。那么对于车企来讲,如果需要赢的智能汽车时代,可能需要扩大自己的野心,做一个足够大的集团覆盖汽车,机器人等人工智能落地的制造机器集团。可能必须要自研通用人工智能并利用 AI 赋能整个汽车和机器项目,提高汽车机器制造业的附加值。最终或许通用人工智能接管人类的重复性的脑力劳动,犹如现在机械取代人类的体力劳动。*未经准许严禁转载和摘录-参考资料:
EMMA: End-to-End Multimodal Model
for Autonomous Driving - waymo
Could Foundation Models really resolve
End-to-end Autonomy?
Hongyang Li
The Next Frontier in Embodied AI:
Autonomous Driving
CUED Guest Lecture – 25 April 2024
introduce autonomous vehicles - 英伟达
GAIA-1: A Generative World Model for Autonomous Driving - wayve
加入我们的知识星球可以下载公众号海量参考资料包含以上参考资料。
- 高通的下一代智能汽车芯片 - 骁龙 Cockpit Elite 和 Ride Elite
探秘美国加州自动驾驶路试:豪横竞逐、勤奋探索与技术挑战
智能汽车下半场,车路城融合发展 - 2024汽车百人会论坛车路城总结
AI 巨头 Nvidia 英伟达在汽车领域做什么?