学习就是这样,永远前100页看的最多,后面300页种种原因看不下去。这次打破魔咒,把后面的看了。

大概就是这些东西
先总结一下文章,特征值和特征向量可以帮助我们找到矩阵里面不变的量。为了求n次方这样子的问题,我们通过对坐标系的变换,将原有的矩阵对角化,然后发现里面的逆矩阵不好求,后面又发现了正交矩阵的逆矩阵好求,就是自己的转置。但是不是什么矩阵都是有着一个好基底的(正交),然后就是使用了施密特的正交方法,把这个好基底表示出来,方便了最终的计算。
矩阵特征值-变化中不变的东西 之前都写过了,需要补充的一点是这个方向,方向是有两个方向的。
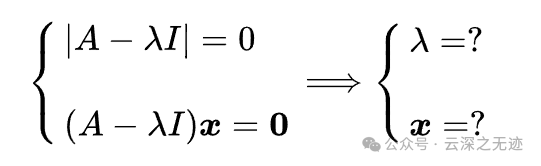
在计算的时候平平无奇,就是上面是解的行列式,下面是把上面求解的特征值带入下面的方程,解出解系。

然后其实还是上面的特征值构成的行列式,打开就是特征方程了
这么多的篇幅说这个就是因为,特征值和向量是后面的基础。特征向量并不唯一,特征向量乘上一个常数依然是特征向量。
一个特征向量唯一对应一个特征值,但特征值对应无数特征向量

这个很重要,不同的特征值构成的向量,进而组成的向量组线性无关
OK,开始新的篇章,对角化!矩阵的对角化:化繁为简的艺术
前些日子确实是学艺不精,现在重新写。其实对角化在目前来看现实的含义是简化计算:(核心原理就是换了一次基底)
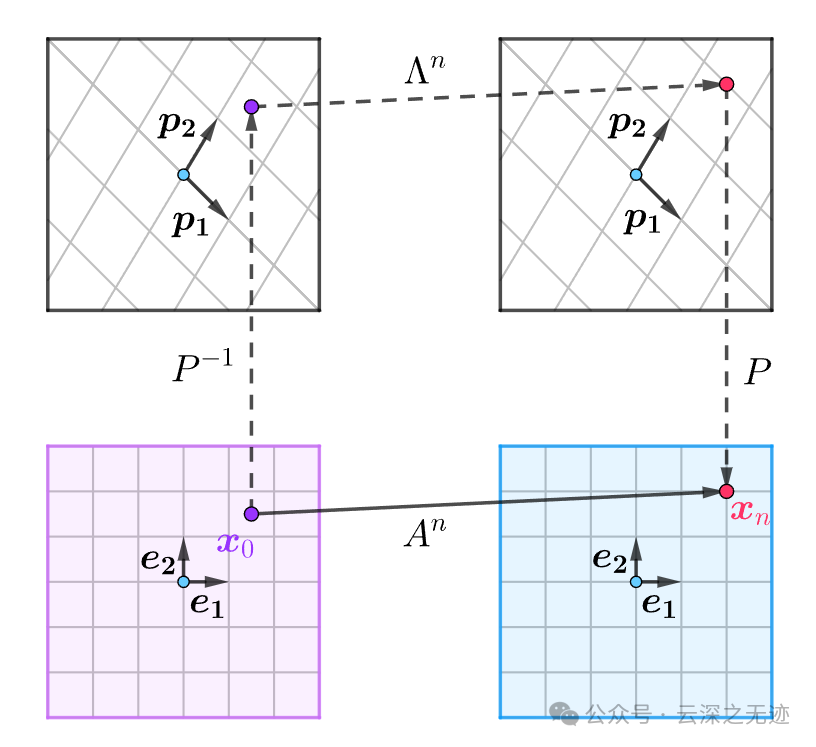
这个图很好的诠释了这一点
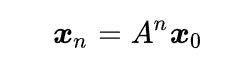
就是求指数
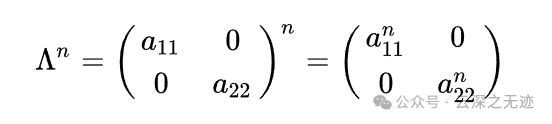
我们知道对角阵的n次方很好算
SO!如果能将A变换为某对角阵的话,那么难题就迎刃而解。
我们先给A矩阵求特征值和然后构建特征向量:

p1,p2就是上面计算出来的特征向量
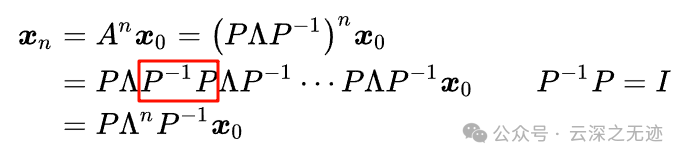
我们使用这样的变换就算了出来n次方,当然了不可否认的是,上面的转折很生硬,也没有推导过程,但那是教科书的问题。这里只是说了方法。
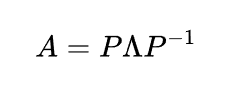
这个是就是对角化
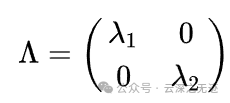
中间的是A矩阵的特征值构成的对角阵
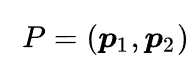
P是特征向量的列向量构成的矩阵

事实上是使用的这个例子来引入的n次方的计算的
最终市区的人口变成了最初郊区的人口比例,而郊区的人口变成了最初市区的人口比例,于是原先的市区在越来越多的郊区人的改造下慢慢变成郊区,而原先的郊区也会在越来越多的市区人的改造下慢慢变成市区,再接着发展又是一轮新的循环,新的市区又会再变回新的郊区,新的郊区又会再变回新的市区,如此往复,阴极而生阳,阳极而生阴,阴阳相生,生生不息。

其实我们上面就是完成了一个叫对角化的过程
方阵的对角化,有些资料里也称为方阵的特征值分解(Eigen Decomposition)。实对称阵(对称阵必然是方阵)必定可对角化
那既然这么好,这个方法有什么弊端吗?
就是出现了这个P的逆矩阵,很不好求

这里就给出了一个逆矩阵的求法,很复杂
正交矩阵其实是在这样的背景下出现的,这样看一环一环的,就合理不少,

就是互相垂直的两个向量,然后长度是1,就是标准的正交基底
省去很长的过程,给结果:

就是说,转换了矛盾,逆矩阵换到了直接转置的矩阵上面
实向量空间上两组标准正交基之间的过渡矩阵一定是正交矩阵,复向量空间上两组标准正交基之间的过渡矩阵一定是酉矩阵。
也是坐标系旋转了,标准正交基就是一组旋转的自然基
等等!这么好的东西怎么算啊?施密特正交化!是不是这样说下来就觉得线性代数也不是那么抽象,更像是偷懒的艺术。不装逼了,写完这段睡觉了。
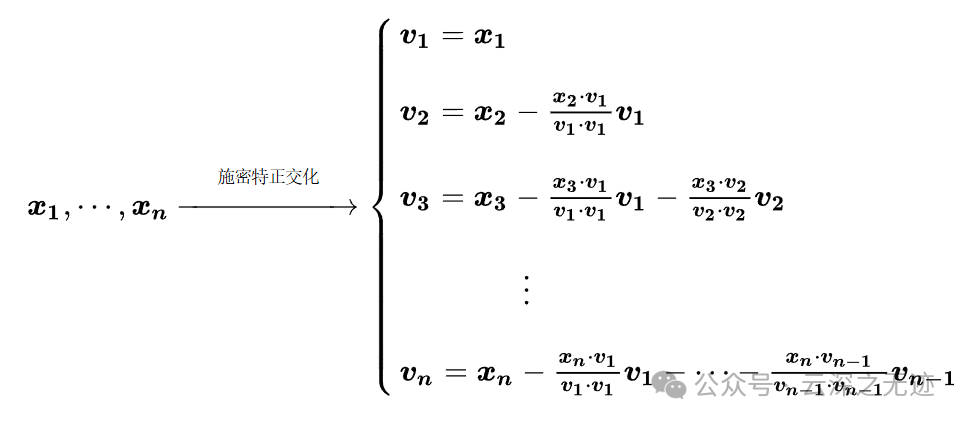
其实一般来说施密特正交化说的是这个公式
正交化可以得到正交矩阵,正交矩阵的逆就是转置
正交矩阵的逆矩阵很容易算出,所以如果对角化中用到的P可构造为正交矩阵,即有:
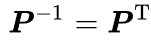
那么就可以大大降低对角化的求解难度:
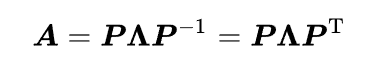
因为正交矩阵的列向量组为标准正交基,所以构造正交矩阵最关键的就是要找到正交基,
简单来说,就是借助该向量空间的一个基x1,x2,找到同一个向量空间的一个正交基v1,v2:
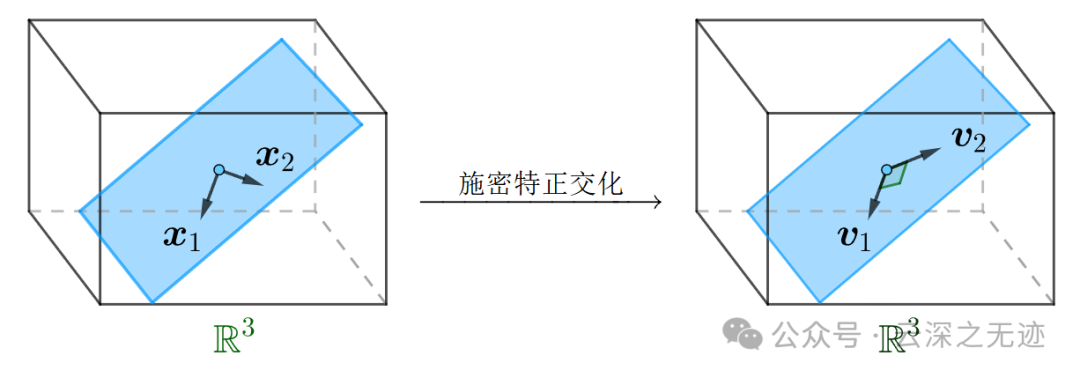
方法是固定住其中一个基,求出与之垂直的另一个基就行了,不过这只能保证正交基,还不是标准正交基.
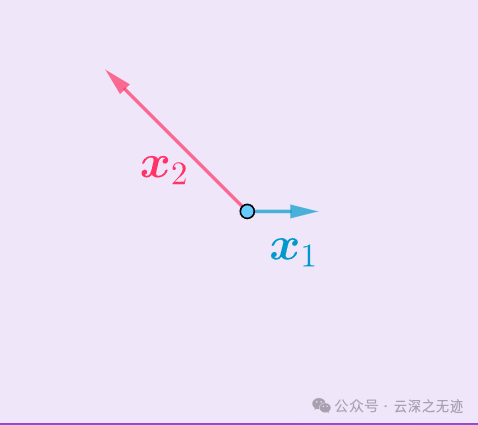
比如这个是一个平面,x1x2是一个🐔,很显然
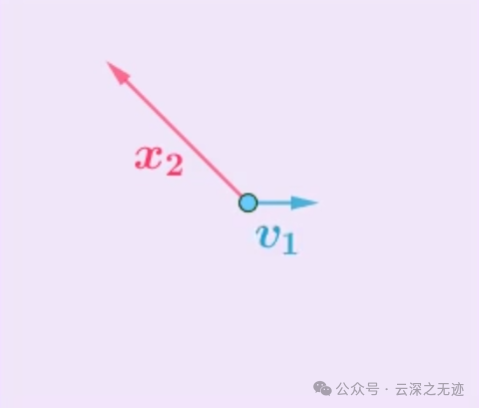
随便选一个,开始处理另外一个
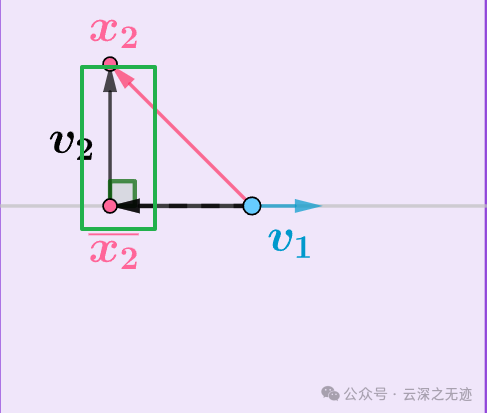
然后就是投影
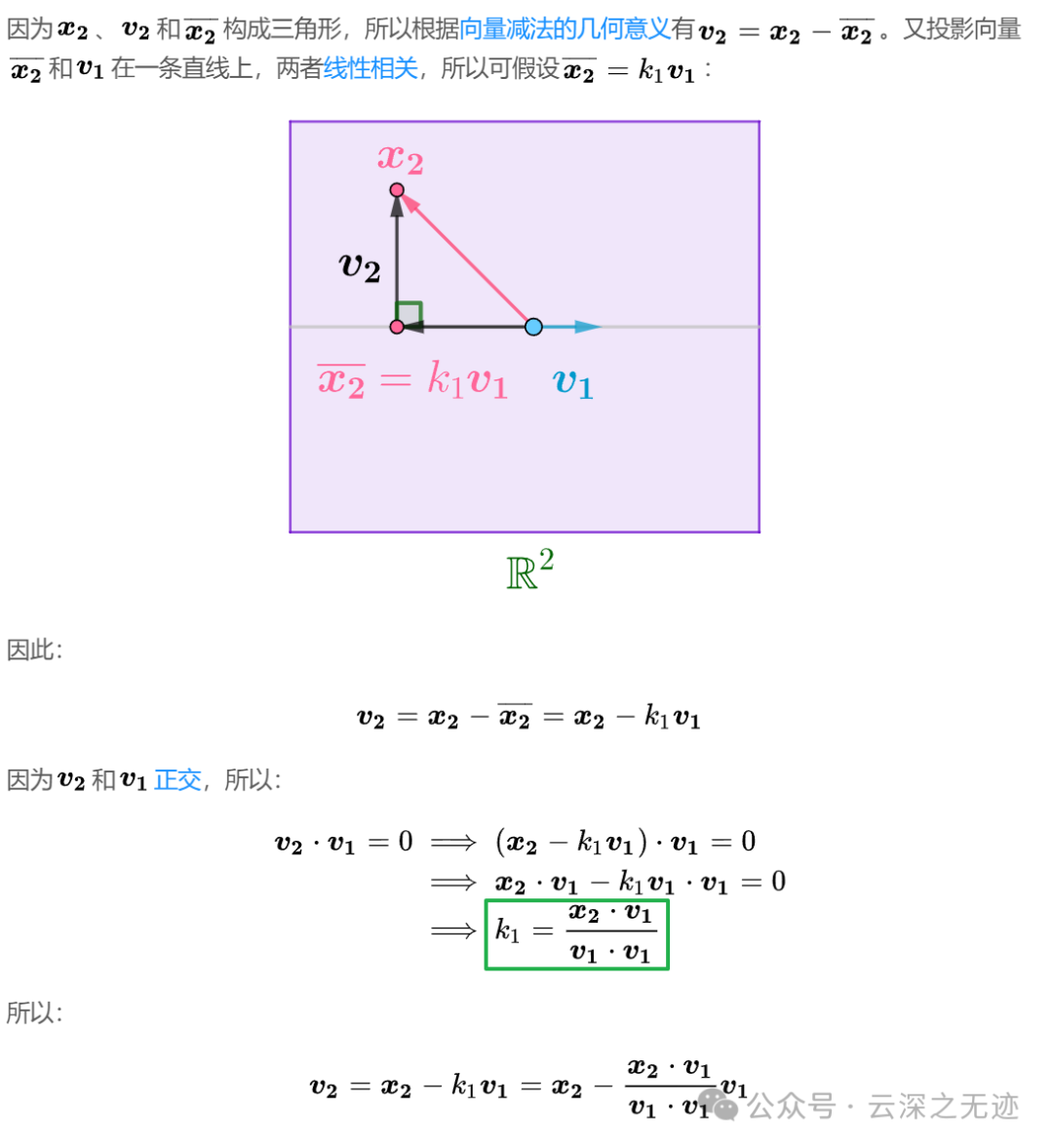
其实最抽象的k只是共线向量的一个比值而已
其实呢,你所谓的正交,只是一个和原来向量相关的投影罢了

乌萨奇宝宝来了!
