


随着ICCAD2024降下帷幕,2024年EDA领域四大会议ICCAD、DAC、DATE、ASP-DAC全部结束。
我们一起来回顾中国内地高校在2024年EDA领域的四大会议的整体表现。
大会论文
ICCAD:共收到1109篇投稿摘要,有802篇符合要求的文章进入了评审阶段,经过313位技术委员会成员的3096次审查,最终录用了195篇论文,录用率仅24.31%。所有录用论文分布在60个Session。10篇论文被提名为最佳论文,2篇论文最终获得了最佳论文;中国内地共入选81篇,4篇获论文最佳论文提名,2篇论文最终获得了最佳论文奖。
从第一作者所在机构来看,入选数量排名前六的高校都来自中国大陆。北京大学入选17篇位居第一;2023年入选7篇。香港中文大学以11篇排名第二;2023年入选10篇。复旦大学10篇列第三,2023年入选3篇。浙江大学8篇排第四。清华大学、上海交通大学各以6篇并列第五。
中国石油大学(北京)、西安电子科技大学、香港中文大学(深圳)、中科院微电子所首次有一作论文入选。
DAC:共接收1545篇,入选337篇,分布在29个Session。4篇论文获最佳论文提名,1篇论文最终获得了最佳论文。中国内地共入选149篇,2篇论文获最佳论文提名。
北京大学、香港中文大学以16篇并列第一,上海交通大学以14篇排第三,清华大学13篇排名第四,复旦大学、中科院计算所以12篇并列第五,华中科技大学以14篇排第七,北京航空航天大学9篇排名第八,湖南大学、香港科技大学、浙江大学以8篇并列第九。
2023年中国内地有10家机构是第一次有第一作者论文入选,包括北京工业大学、东方理工大学、兰州大学、闽南师范大学、齐鲁工业大学、西安电子科技大学、西南大学等7所高校以及上海AI实验室、中科院软件所等2个研究机构,加上蚂蚁集团。
DATE:在总共1314篇摘要提交中,996篇完整的研究论文最终进入了审查阶段。经过技术委员会405名成员的3956次审查,244篇论文(24.5%)最终被选中进行常规展示,60篇论文作为扩展摘要进行展示。中国内地共入选99篇。
ASP-DAC:共接收482篇,入选139篇,36个Session。中国内地共入选57篇。
最佳论文奖和最佳论文提名
首次获得ICCAD最佳论文奖
浙江大学和中国科学院微电子研究所包揽了前端和后端两个最佳论文奖。这也是中国内地机构第一次收获ICCAD最佳论文奖。北京大学、中国科学院计算技术研究所的论文获得最佳论文提名。

最佳前端论文:来自浙江大学的论文《An Agile Framework for Efficient LLM Accelerator Development and Model Inference》获得ICCAD2024最佳前端论文;一作陈律丞硕士生,指导老师:卓成教授、孙奇研究员(浙江大学集成电路学院)。
该研究工作提出了一项用于大语言模型(Large Language Model, LLM)高效推理和加速器开发的设计框架,其包含一个基于RISC-V架构的异构SoC和基于多保真度优化的敏捷设计空间探索方法,以提高LLM的推断效率。LLM在视觉和语言等各个领域都表现出了非凡的性能。然而,其推理依赖大量的存储、带宽和计算资源,导致相关加速器和SoC设计的工作量和时长大幅增加。
为解决上述挑战,该研究工作提出了一种新兴的二值化LLM阵列加速器,将其用于一个基于RISC-V架构、同时支持二进制和浮点运算的异构SoC中。本工作所提出的二值化LLM阵列加速器可将高位宽、高精度的数据按组转为低位宽、低精度的结果,依靠二进制运算实现对应运算操作,有效缓解了通过LLM推理剖析发现的矩阵/向量乘法运算耗时瓶颈。在框架中,本工作还提出了一种基于多保真度优化的敏捷设计空间探索方法,解决开发EDA工作流中因缺乏准确的后期数据而出现的过拟合问题,简化优化过程并提高建模质量。基于敏捷开发原则,该研究工作所提出的RISC-V框架由Chisel设计语言实现,具有可配置性和可扩展性,适应了LLM加速部署任务的动态需求。实验结果显示,该研究工作所提出的LLM加速框架与现有的各类计算设备相比,在LLaMA-7B、OPT等典型的大语言模型上均取得了可观的推理速度和能耗效率,在加速11.7倍的同时可将能耗效率提升2.19倍,并有效减少了相关SoC设计过程中的开销。

最佳后端论文:来自中国科学院微电子研究所的论文《A Neural-Ordinary-Differential-Equations Based Generic Approach for Process Modeling in DTCO: A Case Study in Chemical-Mechanical Planarization and Copper Plating》获得ICCAD2024最佳后端论文;这是中国内场机构第一次获得此荣誉;博士生钱跃是第一作者,陈岚研究员是通讯作者。
该研究工作中首次将神经微分方程(Neural ODE)引入工艺建模。
经典半物理模型的较低过拟合风险主要源于其对真实工艺过程的有效模拟。该研究工作基于此,利用常微分方程(ODE)描述芯片形貌在工艺过程中的演变,并通过解初值问题进行模型推断。这种统一的数学表达和推断过程确保了方法的广泛适用性。其次,该研究工作在构建常微分方程时,突破了传统的专家知识模式,认识到基于硅数据的模型校正不仅可以调整待定参数,还能通过机器学习直接构建模型内部的经验关系或核心方程。因此,该研究工作将神经网络整合进常微分方程中,替代原半物理模型中的先验知识部分。最后,为了高效解决这一类异构模型的训练问题,该研究工作利用神经微分方程中的伴随敏感度分析法,采用伴随状态(Adjoint State)将梯度计算转化为常微分方程的初值问题。这一方案不仅减少了内存占用,还实现了与初值问题求解算法的解耦。
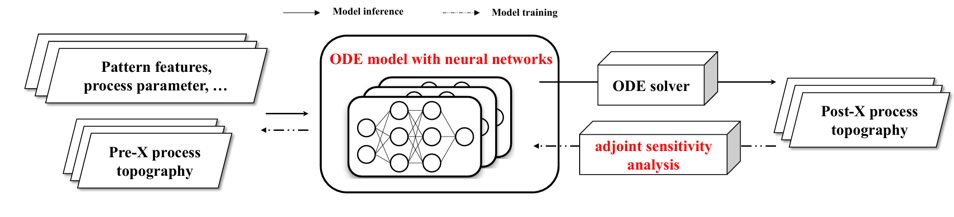 基于神经常微分方程的通用工艺建模方法
基于神经常微分方程的通用工艺建模方法
基于这一通用建模策略,该研究工作搭建了后道化学机械平坦化(CMP)和铜电镀(ECP)模型。
该研究工作提出的基于神经常微分方程的通用工艺建模方法具有多项优势,包括提升模型预测精度、实现自动化部署以及适用于复杂机理的工艺建模等。该方法在 CMP 和 Cu ECP 上的成功应用,进一步表明其在其他工艺中的应用潜力,进而推动 DTCO 工艺建模领域的进一步发展。
DAC最佳论文提名
上海科技大学、张江实验室共同发表的《LLM-HD: Layout Language Model for Hotspot Detection with GDS Semantic Encoding利用大语言模型对芯片版图进行编码及光刻热点检测》,为提升OPC 任务效率,减少OPC在版图缺陷(又称热点)层面修正产生的工作量,该篇论文开展了基于无损多层级版图语意编码和版图语言模型的热点检测研究。论文中,团队提出了全新的“语言模型+高性能GPU”的版图热点检测范式。该范式直接对二进制GDS版图文件进行无损多层级语义表征并使用定制化设计的自然语言模型进行训练和检测。通过将语言模型适配到版图光刻热点检测任务,所提出的方法在金属层和通孔层版图测试集上的表现均显著优于当前最先进的方法。该论文为大语言模型应用到集成电路制造、量测奠定了理论和工程基础。2023级博士生邬一闻和2022级硕士生陈禹阳是论文共同第一作者,虞晶怡教授和耿浩教授为通讯作者。
东南大学王翕副教授团队的论文“ChatCPU: An Agile CPU Design and Verification Platform with LLM”荣获本届DAC的最佳论文奖提名,并受邀在DAC大会上进行展示宣讲,这也是东南大学首次荣获DAC最佳论文提名。
DATE D-Track最佳论文奖
上海交通大学的《FusionArch: A Fusion-Based Accelerator for Point-Based Point Cloud Neural Networks》。该研究针对点云神经网络关键路径中各阶段存在的串行执行、冗余计算、冗余访存三大挑战,提出了一套面向点云神经网络全流程的、基于融合的算法-架构协同设计方案,有效消除了冗余性,改善了并行度,解耦了阶段间的数据依赖关系,消除了执行中潜在的负载不均衡问题。本研究的算法对比基线模型取得了最高2.02%的精度提升,同时对比团队去年在DATE会议获得最佳论文奖的工作PRADA,该论文的协同设计方案取得了平均2.4倍的性能加速。博士生刘学渊为论文第一作者,宋卓然为通讯作者。
DATE最佳论文提名
复旦大学《RVCE-FAL: A RISC-V Scalar-Vector Custom Extension for Faster FALCON Digital Signature》,一作Xinglong Yu,韩军教授为通讯作者。
浙江大学《A FeFET-based Time-Domain Associative Memory for Multi-bit Similarity Computation》,一作黄庆荣博士生,尹勋钊研究员为通讯作者。
ASP十年回顾最具影响力论文奖
清华大学2014年发表的论文《自训练:面向基于忆阻器神经网络加速器的混合信号训练加速Training itself: Mixed-signal training acceleration for memristor-based neural network》;清华大学2013级硕士李伯勋为该论文第一作者,汪玉为论文通讯作者,论文其他合作作者包括2012级博士汪彧之,美国杜克大学教授陈怡然以及清华大学杨华中教授。

该论文基于忆阻器的存算一体架构(Process-In-Memory, PIM)可以在存储阵列内完成计算,显著降低数据搬运的能量开销,高效实现神经网络算法。现有存算一体架构往往需要使用GPU对神经网络模型进行训练,再将训练后的模型部署在忆阻器器件中,训练成本高昂。针对这一问题,本文提出了一种直接在忆阻器阵列中实现神经网络训练的系统方案。通过设计一系列数模混合辅助运算结构和算法近似化方法,首次实现了基于忆阻器计算架构的神经网络自训练,有望将神经网络训练能效提高3至4个量级。
ASP最佳论文
浙江大学《SPIRAL: Signal-Power Integrity Co-Analysis for High-Speed Inter-Chiplet Serial Links Validation》;(面向高速芯粒串行通道验证的信号与电源完整性协同分析)获得ASP-DAC 2024最佳论文奖。芯粒集成芯片是解决集成电路发展困境、突破算力瓶颈的重要技术,其中芯粒间串行通道的信号与电源完整性是影响电路性能的重要的因素,需要对其进行仿真验证。传统的仿真工具在处理大规模芯粒串行通道分析时遇到了效率低、计算量大的问题。针对以上问题,论文提出了一种高效准确的面向芯粒间高速串行通道信号与电源完整性协同分析的框架。首先,设计神经网络模型对高度非线性的发送端行为进行建模;接着提取传播媒介及接收端的S参数并转化为时域的冲激响应;基于上述神经网络模型和冲激响应计算得到脉冲响应,再通过脉冲响应叠加的方式实现高效的信号与电源完整性分析。相较于仿真工具,论文提出的框架实现了0.82-1.85%的平均相对误差和18-44倍的加速分析。该项工作由实验室的卓成教授指导博士生董晓、孙凇昱和硕士生蒋杨帆等完成,论文其他合作作者包括匹兹堡大学胡京通教授以及集成电路学院高大为研究员。

大赛获奖
DAC-SDC竞赛:东南大学FPGA赛道三连冠。张萌教授带领SEUer团队和SEU AIC Lab团队分别获得了DAC-SDC竞赛FPGA赛道和GPU赛道的冠军。
2022年,东南大学SEUer团队将低功耗单目标检测做到极致、力压群雄首次夺取第一名;2023年,团队探索多目标检测的硬件性能极限,蝉联第一名;2024年,面对应用领域的改变、硬件平台的升级、测试指标的变化,SEUer团队(博士生张经纬,硕士生李响、崔泽楠、陈沪、唐卫江、刘嘉琦)实现了多目标检测的硬件性能极限,克服了车道线和人行道的像素级识别的挑战,第三次获得第一名。东南大学SEUer队成为FPGA赛道有史以来唯一的“三连冠”得主。
SEU AIC Lab团队设计了面向自动驾驶场景的多任务模型YoloOST,在硬件方面利用Cuda算子加速等技术,取得了精度与速度方面的平衡,最终获得第一名。
Contest@ISPD
本届竞赛由英伟达主办,题为“GPU和机器学习加速大规模全局布线(GPU/ML-Enhanced Large Scale Global Routing Contest)”,该奖项吸引了来自包括欧洲、北美、南美和亚洲等地的研究团队组成的52支队伍参加。其中中国内地有18支队队伍,中国香港有3支队伍,中国台湾有6支队伍,中国参与的机构包括北京大学、清华大学、复旦大学、东南大学、中山大学、中国技术大学、北京邮电大学、西安交通大学、南京师范大学、福州大学、华中科技大学、香港中文大学、台湾大学、台湾科技大学、台湾清华大学、、台湾阳明交通大学等。要提醒的是,中国内地参与高校都是获批集成电路科学与工程一级学科硕博点的高校。
竞赛背景:全局布线是VLSI设计过程的关键组成部分,对电路时序、功耗和整体布线能力有重大影响,全局布线的效率至关重要。
竞赛目标是激发学术研究,旨在开发专为工业级电路量身定制的GPU/ML增强型全局路由器。
值得注意的是,当代VLSI电路通常包含数千万个单元,这与过去通常处理不超过100万个单元的场景的全球布线竞争有很大不同。由于当前路由器的局限性,通常采用分层或基于分区的方法来管理大型电路,尽管存在牺牲一定程度的最优性的风险。开发一种能够处理数千万个单元电路的可扩展全局路由器非常重要,因为它可以在早期设计阶段(如平面规划和布局)为优化提供重要信息。本次竞赛旨在大幅减少这些扩展的工业级电路的全球路由运行时间,利用GPU的计算能力和机器学习技术的潜力。同时,它努力提高路由结果的整体质量。

北京大学林亦波教授指导的本科生赵春源提出的高效GPU异构并行布线算法,通过异构并行计算提高芯片设计迭代的效率,在竞赛中斩获第一名。
第三名是复旦大学&福州大学&立芯科技联队metaRoute,队员包括复旦大学蔡志杰、魏民、邹鹏,福州大学陈忆鹭、吴昭怡,立芯软件的丁鸿志,指导老师是福州大学林智锋教授和复旦大学陈建利教授。
CADathlon@ICCAD
CADathlon要求代表队两人一组,在9小时内,运用自己的编码和分析技巧来解决6道集成电路与系统中电子设计自动化问题,涉及电路设计与分析(Circuit Design and Analysis Physical Design)、物理设计和设计可制造性(Physical Design & Design for Manufacturability)、逻辑与高级综合(Logic and High-Level Synthesis)、系统设计与分析(System Design and Analysis)、功能验证和测试(Functional Verification)、新兴技术(生物、安全、人工智能等)在EDA上的应用等多个方面的内容,需要参赛队伍综合运用EDA、计算机体系结构、及机器学习等各方面的知识解决问题。上述问题在以前的科学论文中有所描述。
北京大学(郭资政、麦景;指导老师:林亦波)获得第一名。

CAD Contest@ICCAD
CAD Contest竞赛作为EDA领域的年度盛事,是EDA领域影响范围最广、影响力最大的国际学术竞赛,一直受到国际学术界与工业界的广泛关注。
针对当前集成电路设计自动化所面临的亟需解决的问题,每年有三道不同的赛题,赛题均来自Synopsys、Cadence、Siemens EDA、Nvidia、IBM等全球著名EDA或半导体公司的真实业务场景,期望对目前集成电路工业界遇到的最困难的设计问题研发出更好的解决办法,竞赛的结果可以直接转化为工业界的解决方案,对集成电路计算机辅助设计领域的发展有很大的促进作用。


C赛题第一名 北京大学:杜宇凡、郭资政;指导老师:林亦波
C赛题第三名 东南大学:董雨晗、邓泽远、秦宇森、程旭、焦俊铭、张展华;指导老师:曹鹏
C赛题《Scalable Logic Gate Sizing Using ML Techniques and GPU Acceleration》是由亚利桑那州立大学和英伟达共同出题。
LLM4HWDesign Contest
2024年ICCAD新设立LLM for Hardware Design Contest。
大型语言模型(LLM)在生成高质量内容方面表现出了令人印象深刻的能力,引发了人们对其应用于硬件设计的兴趣。通过协助将人类指令翻译成硬件设计(例如硬件代码),LLM有可能简化硬件开发的劳动密集型过程。不幸的是,由于缺乏高质量、可公开访问的硬件代码数据集,用于硬件设计的LLM的开发受到了严重阻碍。具体而言,缺乏足够的数据集阻碍了LLM的有效微调,而LLM是为其配备硬件领域知识并减少其在预训练期间对硬件特定数据的有限暴露的关键方法。因此,这种短缺严重阻碍了LLM辅助硬件代码生成的进展。
LLM4HW Design竞赛旨在为硬件代码生成构建大规模、高质量的Verilog代码生成数据集。在基于LLM的硬件代码生成中引发一场类似ImageNet的革命。为了实现这一目标,LLM4HWDesign竞赛鼓励参与者收集数据样本,并开发创新的数据清理和标记技术,以有效提高硬件代码生成数据集的规模和质量,为推进LLM辅助硬件设计工作流程建立关键基础设施。
第二名:山东大学SDUAES队(Yuchen Zhang、Yicheng Liu、Jinheng Wang、Ruibo Xu、Yiyang Shi;指导老师:贾振格)

ACM ICCAD Student Research Contest
浙江大学赵亮老师指导的本科生刘毅泽获得ACM ICCAD Student Research Competition本科生组第一名,将代表EDA领域参加ACM全球总决赛!这是浙江大学本科生第二次获得第一名。


