

RAG(Retrieve Augment Generation,检索增强)是“驯服”大语言模型的主要手段之一。它允许大语言模型在从固定的数据库中抽取相关内容的基础上生成答案,从而限制随意发挥,提升答案的可靠性。
800+份重磅ChatGPT专业报告
生成(Generation)组件:通常是一个大型语言模型(LLM)。利用检索和增强阶段提供的信息作为上下文。生成符合用户需求的自然语言文本或回答。
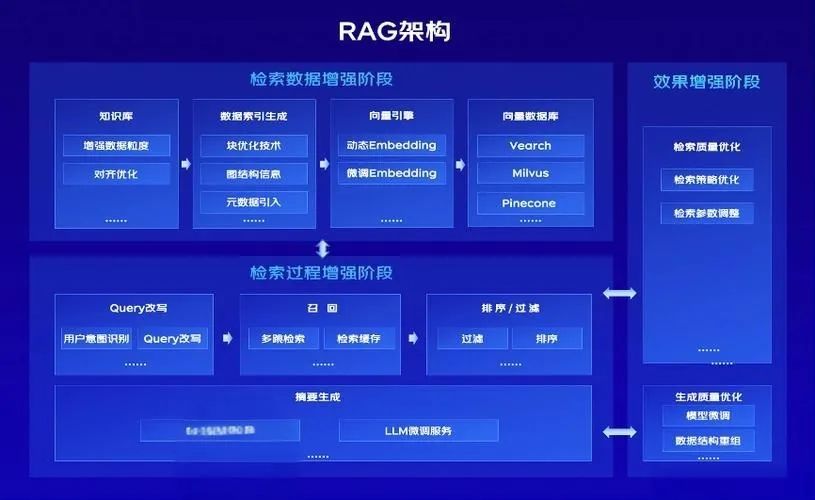
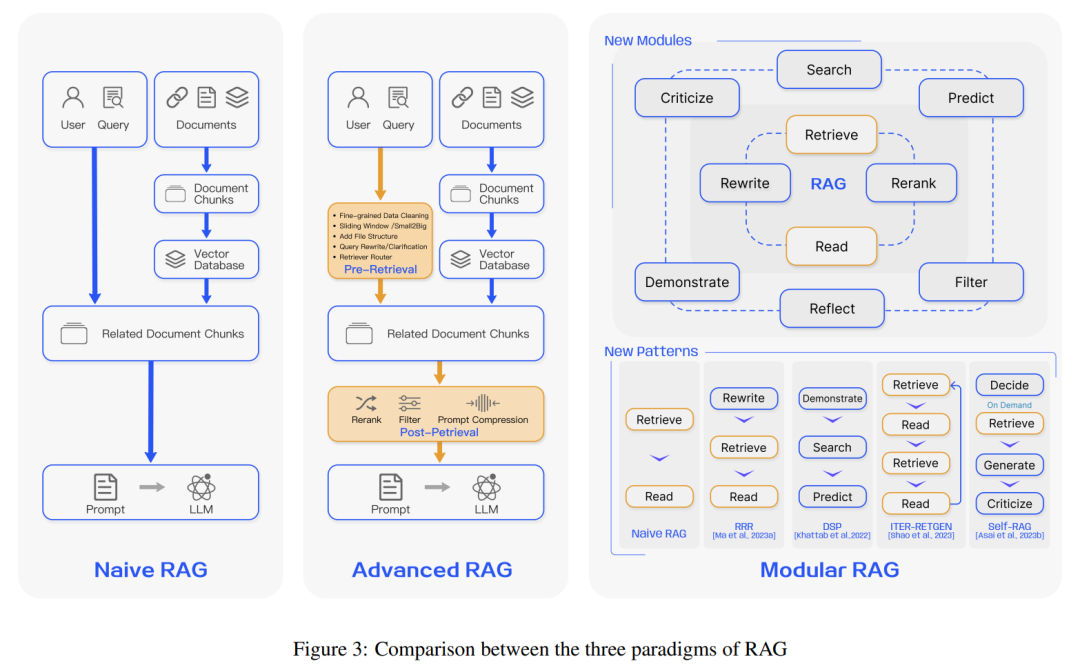
RAG系统的优势在于它结合了信息检索的准确性和自然语言生成的灵活性,能够提供更准确、相关和知情的回答,特别是在处理需要最新或专门知识的查询时。
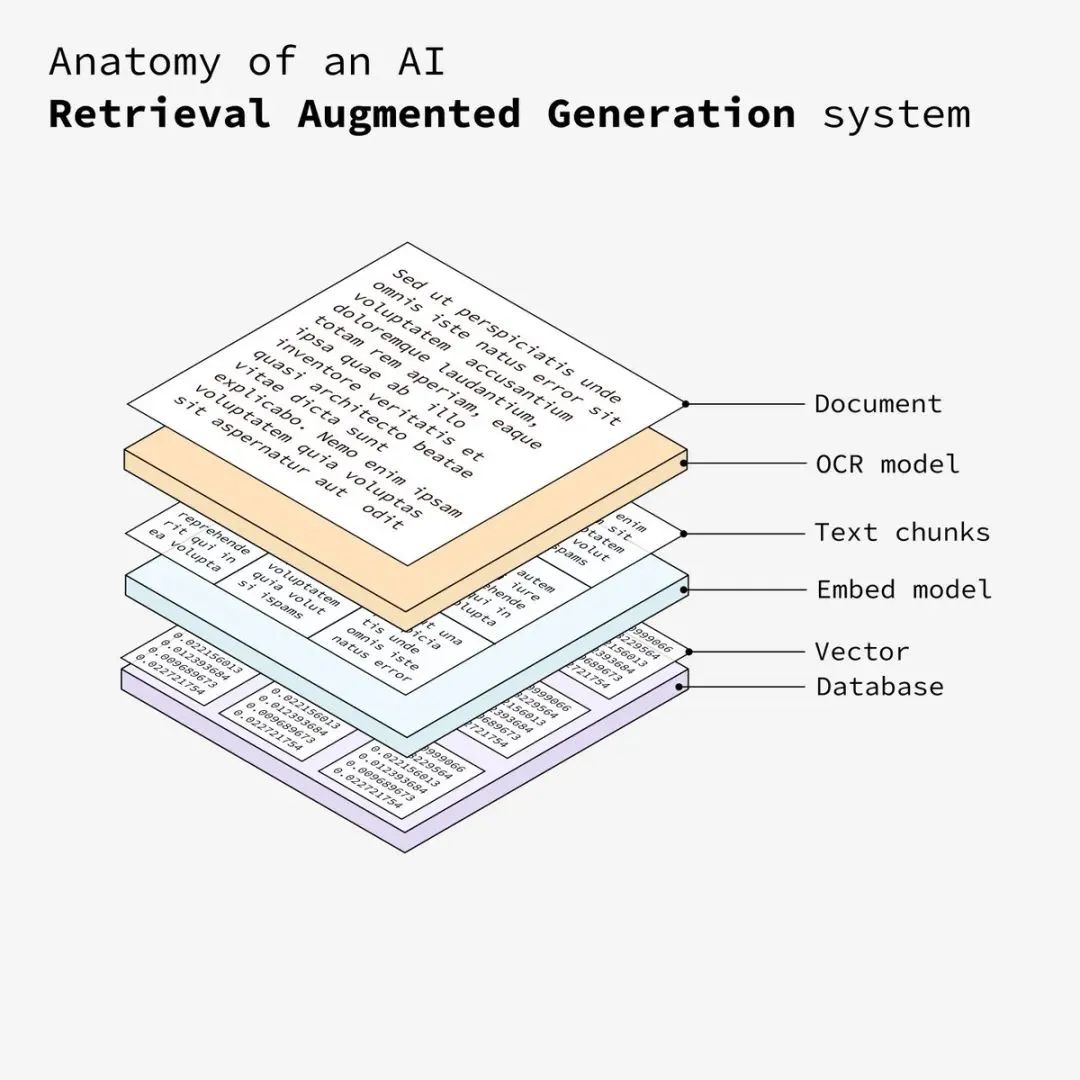
开发RAG系统的第一步是准备文档,这些文档将作为RAG系统的基础输入数据。

接下来,使用 OCR(光学字符识别)模型处理文档。如果需要,该模型可以从图像中提取文本。
将提取的文本分解为更小、更易管理的部分。这种分块处理有助于提高后续处理和分析的效率。

然后每个文本块都会通过嵌入模型。该模型将块转换为向量,即捕获文本语义的数字表示。

将生成的向量存储在一个向量数据库中。上一步将文本转换为向量数据库需要存储到向量数据库中(例如PgVector),该数据库允许系统根据语义相似性有效地检索相关信息。
用户向系统输入问题,该问题将用于从矢量数据库中检索最相关的信息(其实就是从向量库中匹配相似的数据)。
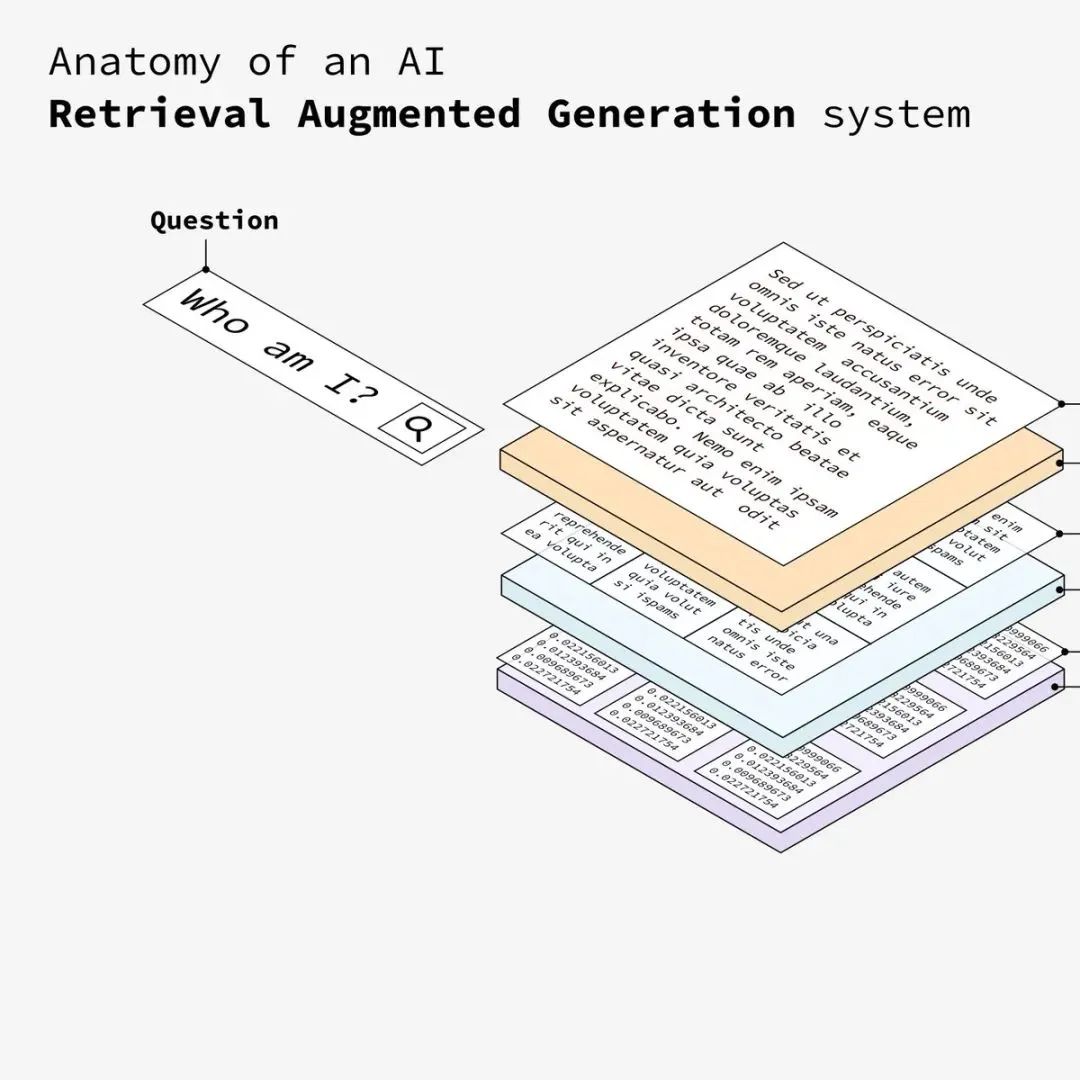
接下来需要将用户输入的问题转换成相同的向量纬度,只有转换成和文档相同的向量纬度,确保了问题和文本块都位于同一向量空间中,才能从向量数据库中匹配到相似的数据。
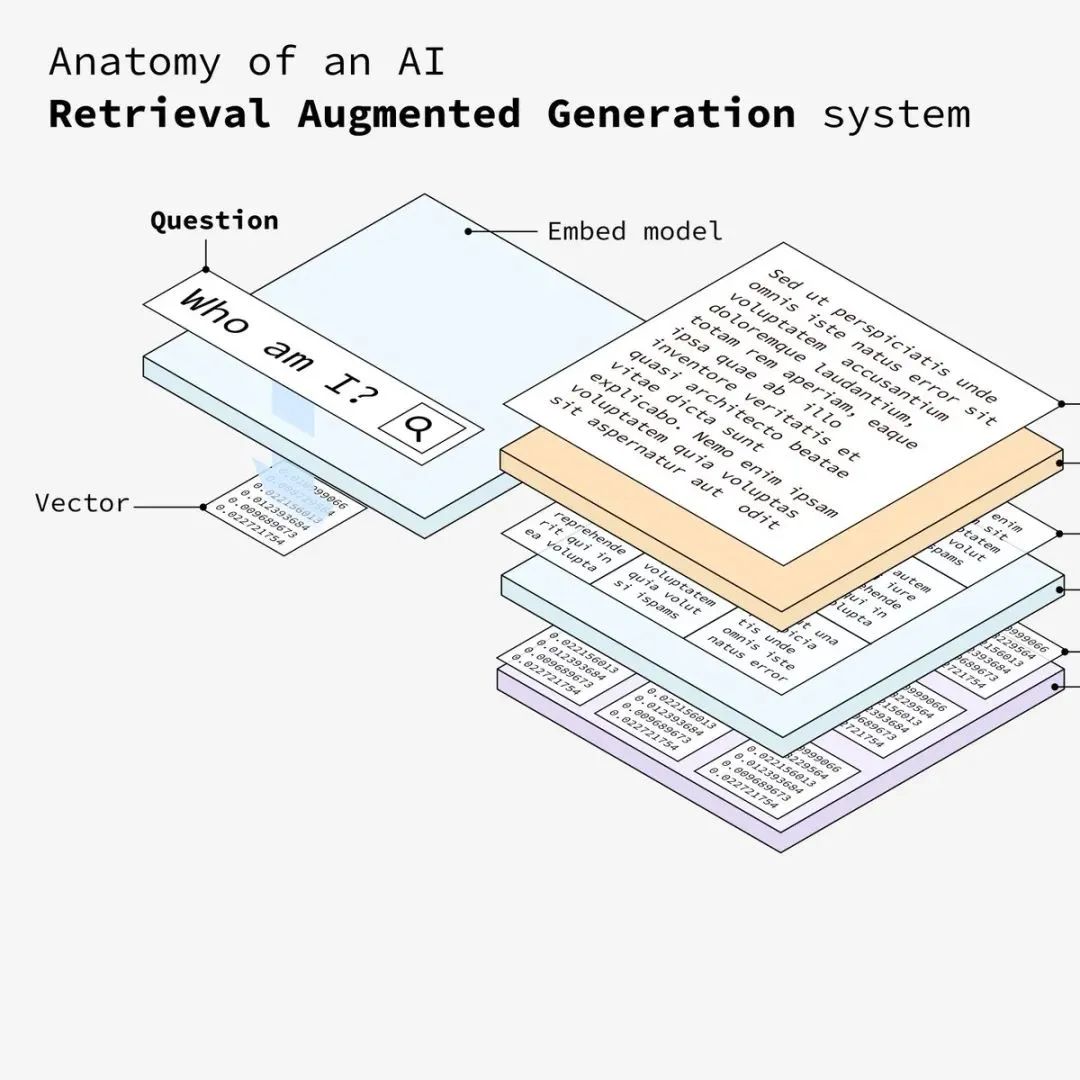
系统根据相似性将嵌入的问题与数据库中的向量进行匹配,并检索出最相似的文本块。同上,将嵌入后的问题在向量存储库中检索匹配相似的数据。
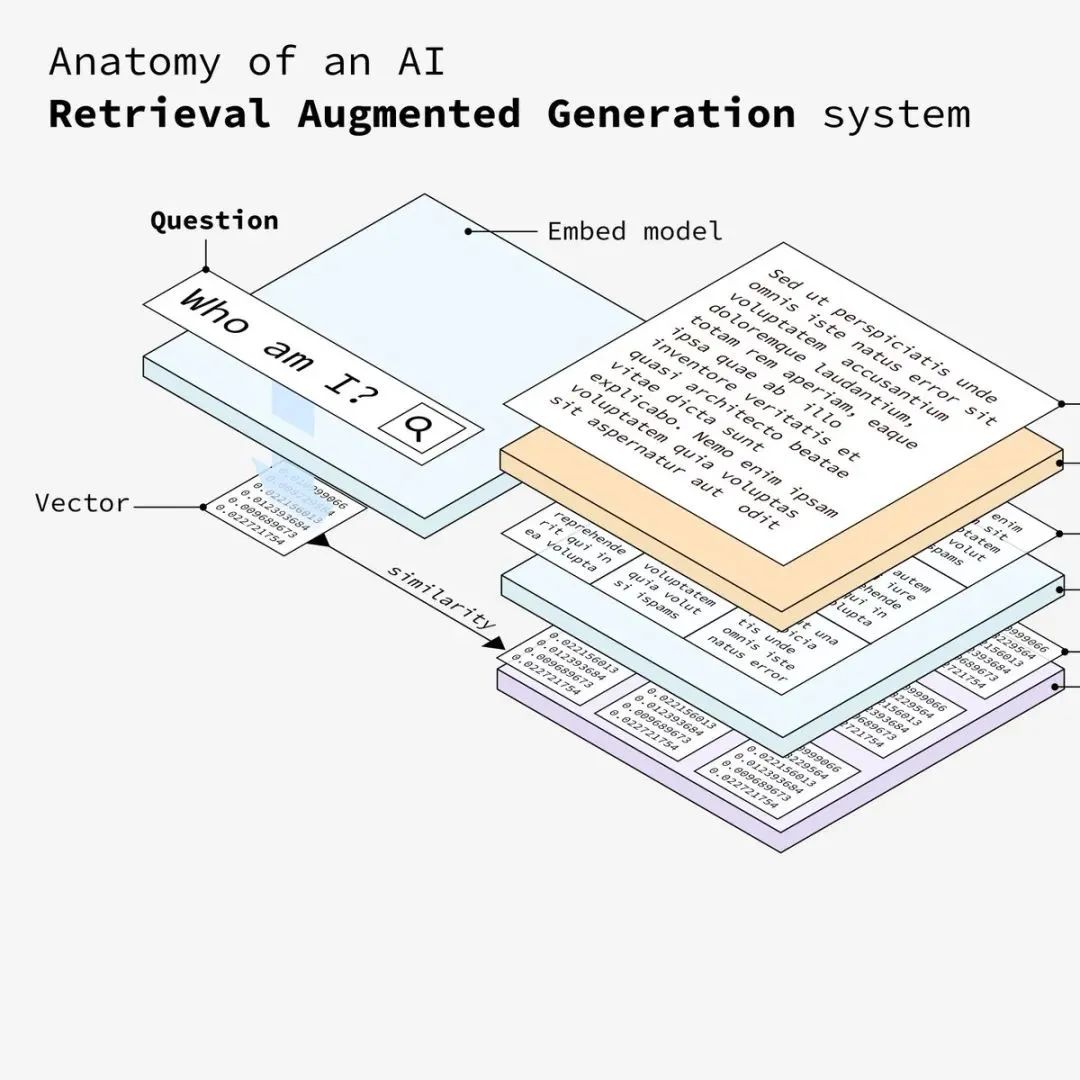
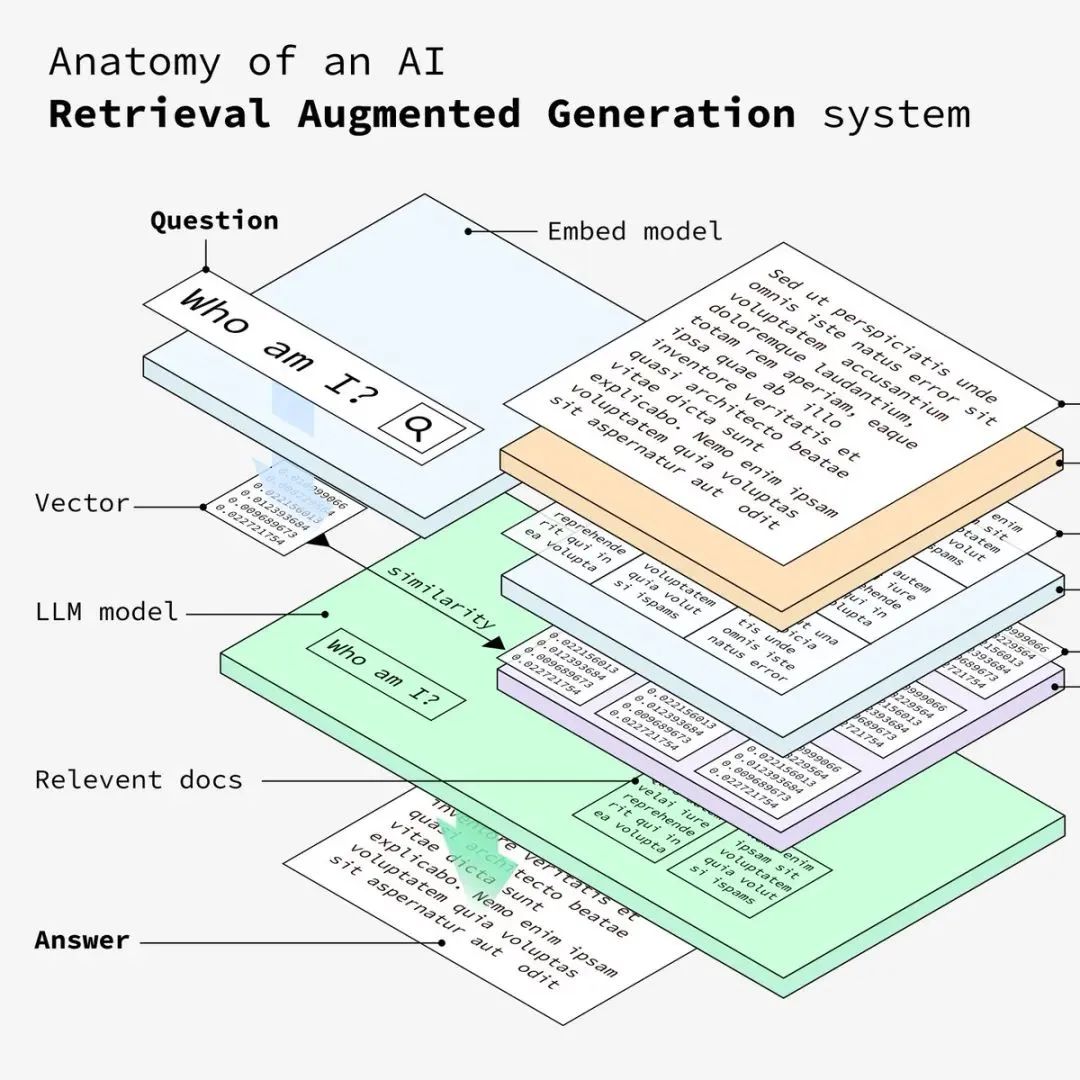
系统根据相似度得分检索最相关的文档。然后,LLM(大语言模型)处理这些相关信息,从向量库中匹配到相似的数据后,系统将交由LLM 处理相关信息以对用户的问题制定详细的答案。

最终,LLM将针对用户的问题,并结合向量库中匹配到的相似的数据分析,输出最终的语义化文本内容给用户
提高准确性:通过结合外部知识库的信息,RAG能够提供更准确和相关的答案。
增强可解释性:由于生成答案时参考了具体的上下文信息,因此答案的可解释性也得到了提升。
解决知识局限性:RAG弥补了大语言模型在专业领域知识理解和最新知识掌握方面的不足。
计算资源需求高:大规模的知识库检索和信息整合需要大量的计算资源。
实时性问题:对于需要快速响应的应用场景,RAG可能面临延迟的问题。
总之,RAG技术通过结合检索和生成两大关键技术,为自然语言处理领域带来了革命性的进步,并在多个应用场景中展现了卓越的潜力。随着技术的不断发展,RAG有望在未来发挥更大的作用。
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


