

译者按:本文译自Brendan的博客。
想象一下,将 AI 的资源成本减半,这对地球和行业意味着什么 - 根据极端估计,到 2030 年,这种节省可以将美国的总用电量减少 10%以上 1。在英特尔,我们一直在创建一种新的分析工具,以帮助降低 AI 成本,称为 AI 火焰图:一种基于我的 CPU 火焰图显示 AI 加速器或 GPU 硬件配置文件以及完整软件堆栈的可视化工具。我们的第一个版本作为英特尔 Data Center GPU Max 系列(以前称为 Ponte Vecchio)的预览版提供给英特尔 Tiber AI Cloud 中的客户。下面是一个示例:
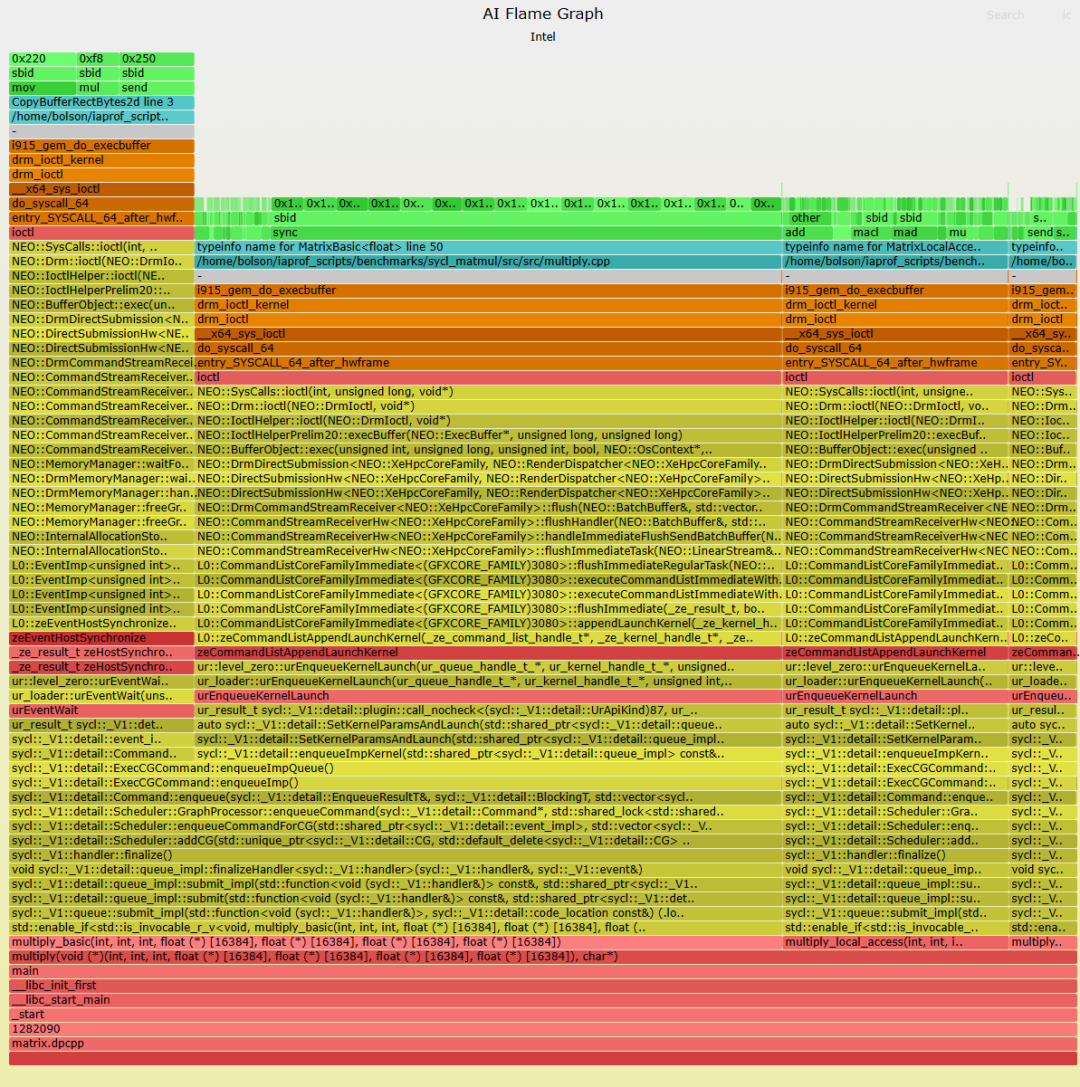
(点击进入交互式 SVG。绿色帧是在 AI 或 GPU 加速器上运行的实际指令,浅绿色显示这些函数的源代码,红色 (C)、黄色 (C++) 和橙色(内核)表示启动这些 AI/GPU 程序的 CPU 代码路径。灰色的 “-” 框只是帮助突出 CPU 和 AI/GPU 代码之间的边界。x 轴与成本成正比,因此您需要寻找最广泛的事物并找到减少它们的方法。
此火焰图显示了一个用于 SYCL(一种用于加速器的高级 C++ 语言)的简单程序,该程序测试矩阵乘法的三种实现,并使用相同的输入工作负载运行它们。火焰图由最慢的实现 multiply_basic() 主导,它不使用任何优化,消耗 72% 的 stall 样本,显示为最宽的塔。右侧是两个薄塔,分别用于 21% 的 multiply_local_access() 和用于 6% 的 multiply_local_access_and_tiling() (),它还添加了矩阵平铺。随着优化的添加,塔变得越来越小。
此火焰图分析器是基于 Intel EU stall profiling 的原型,用于硬件分析和 eBPF 用于软件插桩。它的设计简单且开销低,就像 CPU 性能分析器一样。您应该能够随时生成现有 AI 工作负载的火焰图,而无需重新启动任何内容或通过中介层启动其他代码。
这不是第一个构建 AI 分析器甚至 AI 火焰图 的项目,但是,我见过的其他项目专注于跟踪 CPU 堆栈和时序加速器执行,但不分析加速器上运行的指令偏移量;或者通过昂贵的二进制插桩来分析它们。我想构建像 CPU 火焰图一样工作的 AI 火焰图:易于使用、成本可忽略不计、生产安全,并显示所有内容。开发人员的日常工具,大部分可视化都使用开发人员的语言:源代码函数。
这是英特尔过去一年的一个内部人工智能项目。英特尔已经在这一领域进行投资,为 Intel Data Center GPU Max 系列构建了 EU 停顿分析器功能,可提供硬件指令采样的近似值。我很幸运地邀请到了 Matthew (Ben) Olson 博士,他是一名英特尔人工智能工程师,也曾从事过 eBPF 性能工具 (processwatch) 和内存管理研究,他加入了我的团队,并完成了大部分开发工作。他的背景帮助我们克服了看似无法克服的困难。Brandon Kammerdiener 博士(巧合的是,他也是田纳西大学的另一位毕业生,与 Ben 一样)也加入了我们的行列,他也拥有 eBPF 和内存内部经验,一直在帮助我们承担越来越难的工作量。Gabriel Muñoz 今天刚刚加入,帮助发布。现在,我们的小团队已经证明这是可能的,我们将与英特尔的其他团队一起进一步发展。
几个月前,我们本可以使用英特尔 GTPin 构建一个更难使用且开销更高的版本,但要得到广泛采用,它需要最少的开销和易用性,以便开发人员可以毫不犹豫地每天使用它并将其添加到部署管道中。
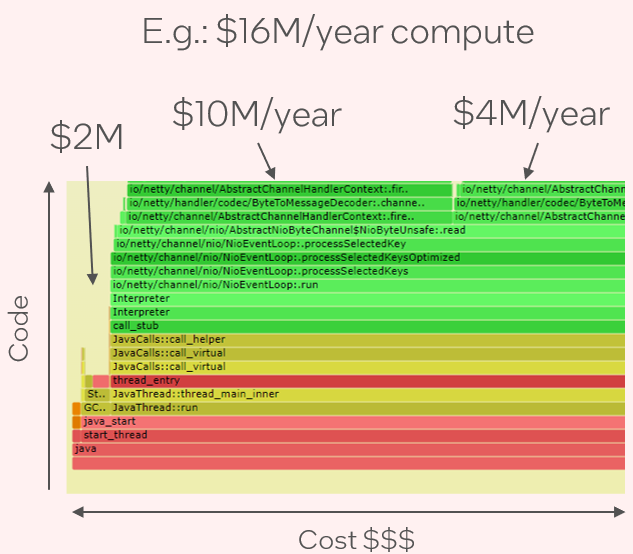
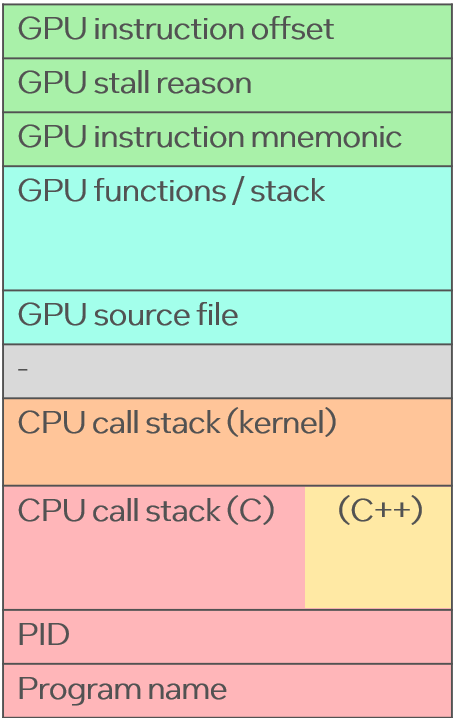
火焰图是我在 2011 年发明的一种可视化效果,用于显示采样的代码堆栈跟踪。它已成为 CPU 分析和分析的标准,可帮助开发人员快速找到性能改进并消除回归。CPU 火焰图显示了运行软件的“大图”,其中 x 轴与 CPU 成本成正比。右侧的示例图片总结了从计算成本到负责任的代码路径是多么容易。在火焰图之前,通过阅读数百页输出,可能需要数小时才能理解复杂的配置文件。现在只需几秒钟:您所要做的就是寻找最宽的矩形。
火焰图已在全球范围内得到采用。到目前为止,它们已成为 5 家初创公司的基础,已被 30 多种性能分析产品采用,并有 80 多次实施。
我第一次实现火焰图是在周三晚上下班后的几个小时。真正的努力是在那之后的十年中,我使用不同的分析器、运行时、库、内核、编译器和虚拟机管理程序来使火焰图在不同环境中正常工作,包括修复堆栈遍历和符号化。今年早些时候,我发布了关于最后一个缺失部分的文章:帮助发行版启用帧指针,以便跨标准系统库进行分析。
对于 AI 工作负载,类似的工作是必要的:修复堆栈和符号,并让分析适用于不同的硬件、内核驱动程序、用户模式驱动程序、框架、运行时、语言和模型。工作量也大得多,因为 AI 分析的成熟度低于 CPU 分析。
如果您不熟悉火焰图,那么值得一提的是内置的搜索功能。在前面的示例中,大多数 stall 样本是由 sbid:software scoreboard 依赖项引起的。由于这可能是一个唯一的搜索词,您可以在 “sbid” 上运行搜索(Ctrl-F,或单击“搜索”),它将以洋红色突出显示它:
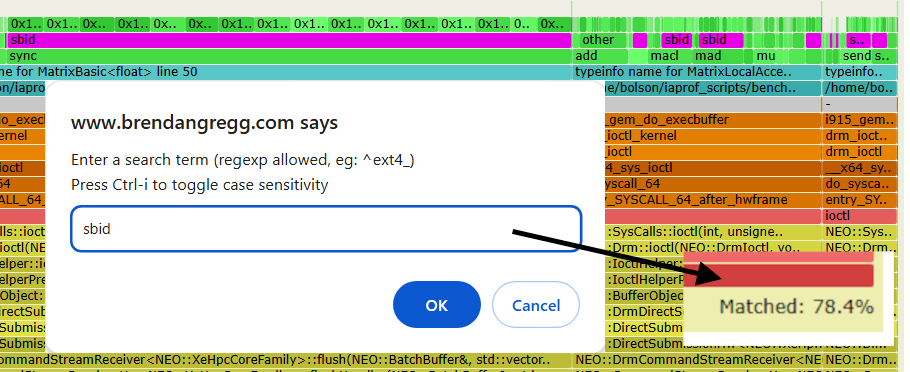
搜索还显示右下角包含 sbid 的堆栈样本总数:78.4%。您可以在火焰图中搜索任何术语:加速器指令、源路径、函数名称等,以快速计算存在该术语的堆栈百分比(不包括垂直重叠),从而帮助您确定性能工作的优先级。
请注意,样本是基于 EU stall 的,这意味着理论性能获胜可以将百分比降至零。这与 CPU 分析中通常使用的基于计时器的样本不同。停顿意味着您最好专注于痛苦,即代码中没有取得进展的部分,但您不会看到未停滞的指令对资源的使用情况。我也希望将来支持基于计时器的样本,这样我们就可以同时拥有这两种视图。
在最近的一次 golang 会议上,我要求 200+ 的观众举手,如果他们使用的是 CPU 火焰图。几乎每个人都举起了手。我知道有些公司将火焰图作为开发人员用来理解和调整其代码的日常工具,从而降低计算成本。这将成为 AI 开发人员的日常工具。
我的雇主也会将其用于评估分析,寻找需要调整的领域以击败竞争对手,以及更好地了解工作负载性能以帮助设计。
考虑 CPU 指令分析:当程序和符号表都位于文件系统中并且采用标准化文件格式(如 ELF)时,这很容易,就像本机编译代码 (C) 一样。对于符合 JIT 的代码(如 Java),CPU 分析变得很困难,因为指令和符号是动态生成的,并放置在主内存(进程堆)中,而没有遵循通用标准。对于此类 JITted 代码,我们使用特定于运行时的方法和代理来检索堆信息的快照,每个运行时的快照都不同。
AI 工作负载也具有不同的运行时(以及框架、语言、用户模式驱动程序、编译器等),其中任何运行时都可能需要特殊的修改才能使其 CPU 堆栈和符号正常工作。这些 CPU 堆栈在 AI 火焰图中显示为红色、橙色和黄色帧。一些 AI 工作负载很容易让这些帧正常工作,而一些 (如 PyTorch) 则需要更多的工作。

但真正的挑战是对实际的 GPU 和 AI 加速器程序(显示为浅绿色帧)进行指令分析,并将它们与下面的 CPU 堆栈正确关联。这些 GPU 和 AI 程序不仅可能不存在于文件系统中,甚至可能不存在于主内存中!甚至对于正在运行的程序也是如此。一旦执行开始,它们就可以从主内存中释放出来,并且只存在于特殊的加速器内存中,超出了 OS 分析器和调试器的直接范围。或者触手可及,但只能通过高开销的特定于硬件的调试器接口。
这些程序也没有 /proc 表示形式(我一直在建议构建一个等效的程序),因此甚至无法直接判断哪些程序正在运行,哪些程序未运行,以及所有其他 /proc 详细信息。忘记指令分析,即使 ps(1) 和所有其他处理工具都不起作用。
这是一次令人费解的经历,揭示了什么被认为是理所当然的,因为它在 CPU 领域已经存在了几十年:进程表。工艺工具。标准文件格式。文件系统中存在的程序。从主内存运行的程序。调试。Profiliers.核心转储。拆卸。单步。静态和动态检测。等。对于 GPU 和 AI 来说,这一切都远没有那么成熟。它有时会使工作变得令人兴奋,当你认为某件事是不可能的,然后找到或想办法时。
幸运的是,我们有一个良好的开端,因为有些事情确实存在。根据运行时和内核驱动程序,有一些调试接口,您可以在其中列出正在运行的加速器程序和其他统计数据,如 intel_gpu_top(1) 等工具使用的那样。您可以使用 intel_gpu_abrt(1) 终止 -9 个 GPU 工作负载。一些接口甚至可以为正在运行的加速器程序生成基本的 ELF 文件,您可以尝试在像 gdb(1) 这样的调试器中加载这些文件。并且支持对 GPU/AI 程序反汇编,如果您可以掌握二进制文件。在我看来,操作系统风格的 GPU/AI 调试大约有两年的历史了。总比零好,但还处于早期阶段,还有很多事情要做。至少十年。
我们已经向英特尔的其他 AI 开发人员展示了 AI 火焰图,常见的反应是有点困惑,想知道该怎么处理它。AI 开发人员会考虑他们的代码,但借助 AI 火焰图,他们现在可以第一次看到整个堆栈,包括硬件,以及他们通常不会考虑或不知道的许多层。它基本上看起来像一堆胡言乱语,他们的代码只是火焰图的一小部分。

这种反应类似于人们第一次使用 CPU 火焰图,它显示了开发人员和工程师通常不会处理的系统部分,例如运行时内部、系统库和内核内部。火焰图非常擅长突出显示最重要的十几个函数,因此学习这些函数在几个不同的代码库(通常是开源的)中的作用就成为一个问题。理解十几个这样的函数可能需要几个小时甚至几天 - 但如果这导致 10% 或 2 倍的成本收益,那么时间是值得的。下次用户查看火焰图时,他们开始说“我以前见过那个函数”,以此类推。您可以达到不到一分钟的时间理解 CPU 火焰图的大部分:查找最宽的塔,单击缩放,阅读帧,完成。
CPU 火焰图的成功让我深受鼓舞,它有 80 多个实现和无数的实际案例研究。有时我在 github 上浏览我关心的性能问题,然后点击页面,然后有一个 CPU 火焰图。他们无处不在。
我希望 AI 开发人员也能够在不到一分钟的时间内理解 AI 火焰图,但首先,人们将花费一天或更长时间来浏览他们不知道涉及的代码库。发布 Found Wins 的案例研究也将帮助人们学习如何解释它们,也有助于解释其价值。
我们遇到的另一个常见反应是 AI 开发人员正在使用 PyTorch,最初我们不支持它,因为它意味着遍历 Python 堆栈,这并非易事。但之前的工作已经在那里完成(以支持 CPU 分析),经过大量修补,我们现在有了第一个 PyTorch AI 火焰图:
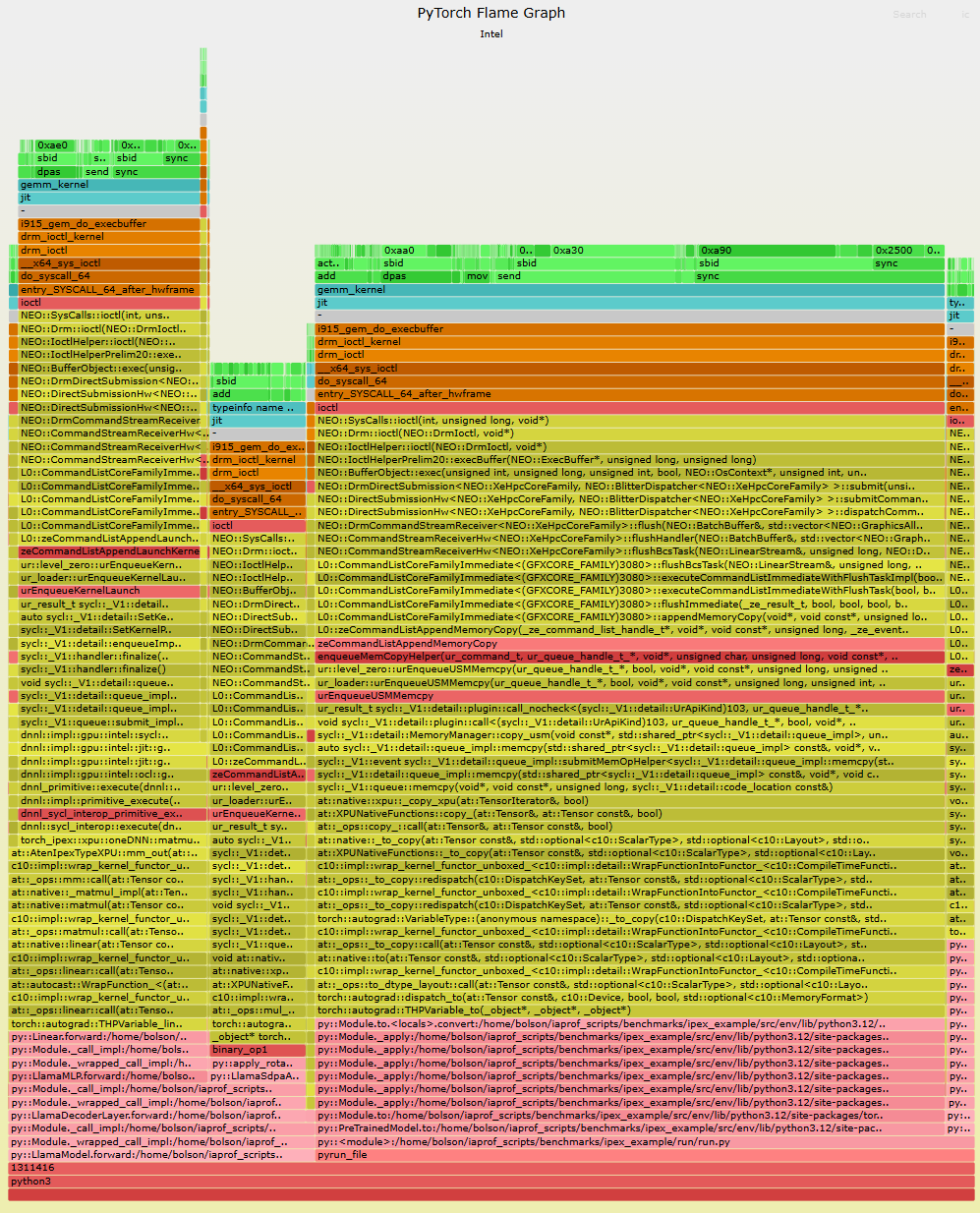
(点击进入交互式 SVG。PyTorch 函数位于底部,颜色为粉红色。此示例运行 oneDNN 内核,这些内核是 JIT 生成的,并且没有源路径,因此该层只读取“jit”。将所有其他层都包括进来真的很痛苦,但这是一个重要的里程碑。我们认为,如果我们能做到 PyTorch,我们就能做任何事情。
在此火焰图中,我们显示了使用 Intel Extensions for PyTorch (IPEX) 运行 Llama 2 7B 模型的 PyTorch。此火焰图显示了 GPU 内核执行的来源,一直追溯到以粉红色显示的 Python 源代码。大多数样本来自导致 aqua 中显示的 gemm_kernel(矩阵乘法)的堆栈,与前面的示例一样,由于软件记分板,该堆栈有许多停顿。
有两个指令(0xa30 和 0xa90),加起来占整个配置文件的 27%。我估计有人会问:我们不能点击说明,让它弹出一个带有完整源代码的反汇编视图吗?是的,这应该是可能的,但我还不能回答我们将如何提供这个服务。另一个我还无法回答的预期问题:既然现在有多个产品使用 CPU 火焰图(包括 Intel Granulate)提供 CPU 工作负载的 AI 自动调整,我们难道不能使用 AI 火焰图对 AI 工作负载进行 AI 自动调整吗?
让 AI 火焰图 处理某些工作负载很容易,但其他工作负载目前很困难,开销成本适中。它类似于 CPU 分析,其中某些工作负载和语言很容易分析,而其他工作负载和语言则需要修复各种问题。一些 AI 工作负载使用许多软件依赖项,这些依赖项需要各种调整和重新编译(例如,启用帧指针以便堆栈遍历正常工作),这使得设置非常耗时。PyTorch 特别困难,可能需要一周以上的操作系统工作才能为 AI 火焰图做好准备。我们将努力在各自的存储库中更改上游的这些调整,这涉及 Intel 内部和外部的团队,我预计这个过程至少需要一年时间。在此期间,AI 工作负载将逐渐变得更容易可视化为火焰图,并且开销也更低。
我想起了早期的 eBPF:你必须修补并重新编译内核、LLVM 和 Clang,如果你遇到错误,这可能需要几天时间。从那时起,所有 eBPF 依赖项补丁都被合并,默认设置也发生了变化,因此 eBPF“正常工作”。我们也会通过 AI Flame Graphs 实现这一目标,但目前仍处于早期阶段。
AI 火焰图 所需的更改实际上是关于改进一般调试,并且是 Fast by Friday 的要求:这是我们可以在 5 天或更短的时间内分析任何内容的根本原因。
AI 火焰图 将首先在 Intel Tiber AI Cloud 上作为 Intel Data Center GPU Max 系列的预览功能提供。如果您目前被部署到那里,您可以通过 Intel 服务渠道申请抢先体验。至于它是否或何时会支持其他硬件类型、出现在其他 Intel 产品中、正式发布、开源等,这些都涉及 Intel 的其他各个团队,他们需要先发布自己的公告,然后才能在这里讨论。
为 AI 数据中心寻找仅几分之一的性能改进,就可以在全球范围内节省电、水和钱。如果AI 火焰图像 CPU 火焰图一样成功,我预计超过 10% 的改进将是很常见的,最终会发现 50% 或更高的改进*。但在早期阶段,这并不容易,因为仍有许多软件组件需要调整和重新编译,并且 AI 火焰图中揭示了需要了解的软件层。
在未来的几年里,我想象其他人会构建自己的AI 火焰图,看起来和这个一样,甚至可能有初创公司在卖它们,但如果他们使用更难使用和开销更高的技术,我担心他们可能会让公司完全关闭AI 火焰图的想法,并阻止他们找到急需的胜利。这太重要了,不能做得不好。AI 火焰图应该易于使用,开销可以忽略不计,确保生产安全,并显示所有内容。英特尔已经证明这是可能的。
* 这是一篇个人博客文章,仅作个人预测,但不保证可能的性能改进。请随意对任何索赔持保留态度,并随时等待 Intel 关于这项技术的正式发布和公开发布。
1 根据 Arm 首席执行官 Rene Haas 估计的 20-25%,ArsTechnica 的 Kyle Orland 在《仔细研究 AI 的所谓能源灾难》中引用了这一估计。
感谢 Intel 的每一位员工,他们帮助我们实现了这一目标。Markus Flierl 推动了这个项目并将其作为重中之重,Greg Lavender 也表达了他的支持。特别感谢 Michael Cole、Matthew Roper、Luis Strano、Rodrigo Vivi、Joonas Lahtinen、Stanley Gambarin、Timothy Bauer、Brandon Yates、Maria Kraynyuk、Denis Samoylov、Krzysztof Raszknowski、Sanchit Jain、Po-Yu Chen、Felix Degrood、Piotr Rozenfeld、Andi Kleen 以及所有其他帮助我们解决问题的同事,并提前感谢将在未来几个月内帮助我们的其他人。
最后,我要感谢那些实际动手处理火焰图的公司和开发人员,他们收集它们,检查它们,找到性能优势,并应用它们。您正在帮助拯救地球。
