中国企业出海面临多语言、跨时区等挑战。大模型技术带来了智能客服机器人的新一轮迭代。本文将介绍如何设计客服机器人产品,探讨基于大语言模型的智能客服实现方式,助力企业快速构建全渠道智能客服系统,重塑客户体验,驱动业务增长。
分享嘉宾|徐峰 亚马逊云科技资深解决方案架构师
内容已做精简,如需获取专家完整版视频实录和课件,请扫码领取。

01
首先看一下使用场景,今年中国企业有一个比较热的趋势,很多企业在国内增长遇到瓶颈以后,就会考虑出海。但是出海后会遇到很多问题,特别是c 端用户的企业,需要有客服团队提供客服支持,这就会面临多语言、跨时区、跨国家的一些问题。
第一,需要满足跨多个时区,多种语言的要求。但是用传统方式构建人工客服团队,对企业的初期运营成本有比较大的压力。第二,因为人工客服有工作时间,不可能一直在线,如果企业本身的业务是 7 × 24 小时运作,那么用户随时可能向客服团队提出咨询或希望做自助服务的查询。这些服务通过人工客服团队来响应的话,一定会有延迟。第三,需要人工客服团队持续学习和改进。因为企业的业务是多变的,所以很多业务需要通过人工培训掌握回答,同时还要通过一些手段来分析每位人工客服的回答是否准确,比较消耗精力。针对上述问题,智能客服文本机器人能很好解决出海企业的客户服务需求。第一是提升服务效率,因为是聊天机器人,可以 7 × 24 小时在线,用户可以随时跟机器人进行聊天、提出问题咨询,或者是完成自助服务查询。第二是降低运营成本,构建一个客服机器人,整体的部署成本是相对固定的。当用户群体足够大时,分摊的运营成本会逐渐变低。第三是提升满意度,当企业能够及时地回复用户,并提供准确的答案,用户自然会更加满意,且对服务或者产品的粘性会增加。第四是在数据驱动下能持续改进,因为是客服机器人,所以客服 AI 跟用户的对话记录都会被记录下来,方便后续做数据层面的优化。基于客服机器人的优势,产品经理要怎样设计一个客服机器人产品呢?
客服机器人的需求有很多,以下8 个是比较重要的需求:第一需要准确回答用户的问题,用户的问题能够准确的从知识库里面找到对应的答案,然后回复给用户。第二需要拒绝无关的问题,不希望用户把精力花在聊天上面,对于无法回答的问题,要让 AI 客服能够礼貌的进行拒绝。第三需要问题澄清功能,当用户手动输入问题时,问题描述不一定特别清晰,或者在多语言的环境下存在拼写错误,或者多语言混杂的描述,所以需要让 AI 能够在不明确用户问题的时候,提出反问将用户的问题进行澄清。第四需要支持多轮对话,模拟真人对话情景让 AI能够有多轮对话的能力。第五需要支持长期记忆,例如用户昨天问了一个问题,今天突然又想要进行追问,这时 AI 能够知道用户昨天问的问题,它的回答需要参考上下文来做精准的回答。第七需要外部API调用,因为客服机器人是在现有客服系统上做增强,需要调用内部系统做集成,可以通过API 调用的方式来实现。第八机器人交互需要提供API ,通过 API 的方式,用户可以和自有 APP 或者网站通过前端进行调用集成,也支持流式输出。接下来以普通用户在使用客服机器人的用户旅程为例,首先用户提出问题后,会显示出该用户的历史对话,接下来机器人可以给用户发送问候语及常见问题。如果用户提出的问题能在常见问题列表中找到,就可以直接点击该问题,AI 客服可以很快拿到已经预设好的答案进行回答。如果用户的问题不在常见问题列表中,会让用户手动输入问题,这时也是通过 AI 模型做意图识别或者实体识别。意图识别主要是对问题做分类,实体识别主要是识别问题中的专有名词及跟业务相关的名词,或者产品名称、地名等等,然后通过相似度算法,找到与用户当前输入问题比较相似的标准问题,从知识库中寻找答案去做问答,或者直接从问答对中找到答案。最后把答案回复给用户,用户可以选择点赞或者点踩。点赞说明用户接受这个答案,此时可以通过 AI 生成follow up的问题,用户可以选择这些问题,继续开始一个新的问答。或者用户对当前答案不满意也可以点踩,此时可以给用户转人工的渠道,直接对接人工客服。有了上述的产品设计,如何用大模型技术来实现客服机器人呢?
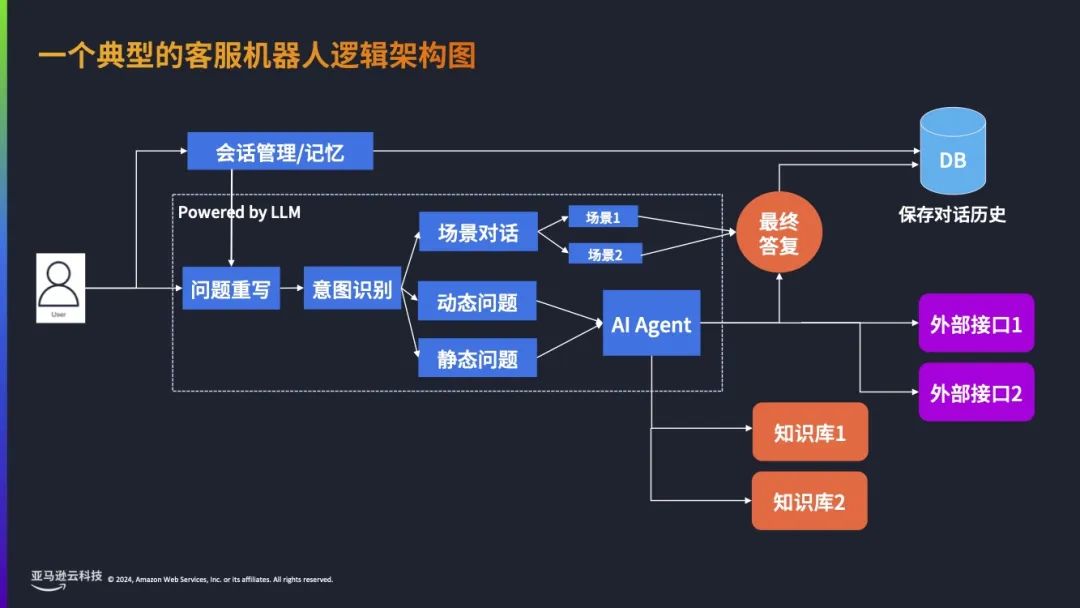
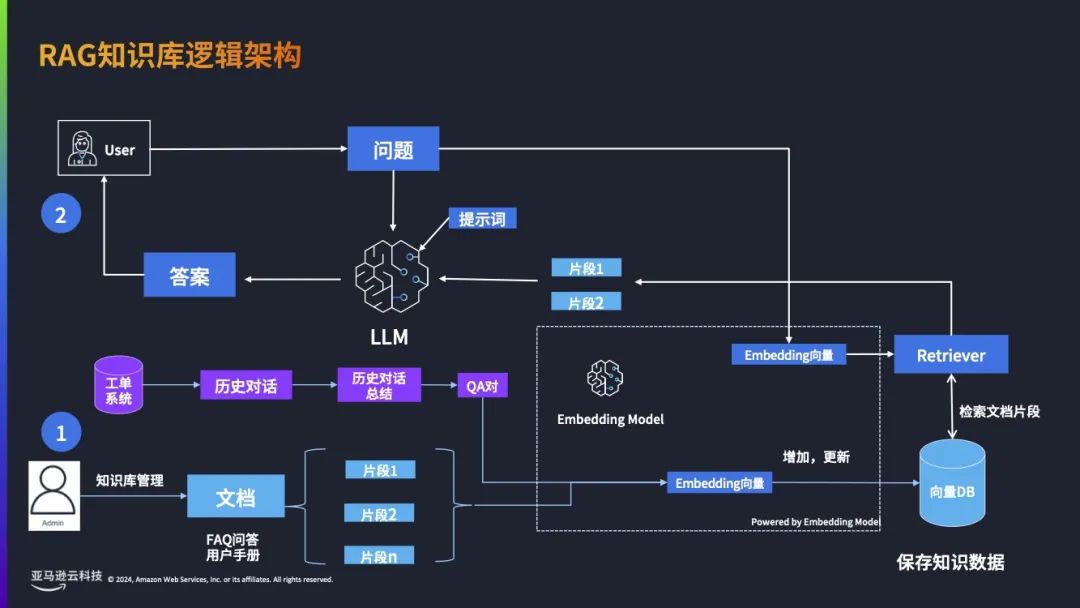
目前实现客服机器人主要有两种技术方案,一种是基于自然语言理解(NLU)和自然语言处理(NLP)的技术来做聊天机器人。亚马逊云科技有个服务叫 Amazon Lex,可以用这种方式构建客服机器人,也可以用 Rasa 开源的框架构建。第二种是基于大语言模型的技术,它有更强的能力,完全可以基于大语言模型来构建一套全新的客服机器人架构。如果是在海外地区使用,可以使用Amazon Bedrock上面先进的大语言模型或者embedding模型来做。因此会形成一个完整对客服机器人逻辑架构,如下图所示。先从左边看到用户提出问题后,首先会进到问题重写模块。此模块主要是为了满足用户开启多轮对话后,大模型可以根据当前提问结合对话历史把问题做改写。举个例子,比如前面问了“北京的天气怎么样?”,这时会返回北京天气的结果,接下来再问“上海呢”,这个问题单独看不能成为一个问题,但是结合上下文,其实能判断出用户想问的是“上海的天气怎么样?”,这时就可以通过问题重写,把“上海呢”重写成“上海天气怎么样?”,这就是问题重写模块的作用。接下来进入意图识别,举个例子,看病时会先进行预检,首先确定到底是什么类型的病,然后再到对应的科室去检查。意图识别也是一样,当企业的业务比较复杂的时候,可以通过意图识别快速把用户的问题分类到不同的业务模块。当然意图识别还有一个比较大的作用,是判断用户问题到底是静态问题还是动态问题,或者是类似于场景对话的问题。静态问题可以看成是FAQ问答,不同用户无论在什么时间问这个问题,他拿到的答案都是一样的。动态问题是不同的用户在不同时间去问,他拿到的答案是动态的,这个问题的答案是需要查询外部接口,或者是查询数据库来获取,我们把这类问题归为动态问题。场景对话主要是让AI 客服扮演一种角色,比如用户当前投诉 APP 的功能不好用,AI客服就会扮演一个安抚的角色,可以说比较委婉的话安抚客户的情绪,提供情绪价值。针对动态问题和静态问题,会把这些问题发送给 AI Agent 智能体,智能体可以选择不同的工具来回答用户的问题,这个工具可能是知识库、Web 接口等,具体调用哪个都是让 AI 做判断,判断以后调用相应接口拿到特定的结果返回,再把它转换成自然语言,回答给用户,这就是整个客服机器人完整的逻辑架构。我们把知识库拆开看的话,其实是检索增强生成的知识库。首先客服管理员会收集企业内的各种文档,比如 FAQ 问答,或者是客服培训手册。把这些文档先进行分段,然后对每个分段调用embedding 模型,把文字转换成数字化的向量,存到向量数据库中。接下来用户开始提问,将问题也通过 embedding 模型转换成一个向量。向量和向量之间可以通过相似度算法进行检索,可以把用户当前问题对应的向量在向量数据库中做检索,检索出跟问题相关的片段,并把它返回出来,再结合知识库的提示词,就可以让大模型参考这个知识片段,同时参考用户的问题,最后生成答案返回给用户。这就是整个RAG知识库的业务流程。虽然整个客服机器人流程不是特别复杂,但也有很多技术细节,为了让企业能够快速地尝试智能客服机器人,或快速以客服知识文档来验证企业的内部数据,亚马逊云科技提供一下功能点的解决方案,提供以下8个功能点。
从方案优势的角度来看,首先是使用了先进的大语言模型,整体对话是非常拟人的。例如用户正在抱怨 APP上玩游戏又输了,当他给客服发消息后,客服能扮演一个安抚角色去安抚他的情绪。让用户不要感到太沮丧等等。其次是问题回答更精准,我们发现在客服系统里面的知识库需要做个性化回答。当形成了用户标签后,用户提问时会带上用户标签来缩小知识库的检索范围。当企业考虑构建大模型智能客服时,也会遇到一些问题,我们也给到了大家一些建议。例如不同国家的地域性差异是构建一套还是多套客服系统?这主要取决于运营的地理区域,如果是在欧洲,一般要考虑用户的隐私保护或者数据安全,为了保护这些信息,就要在欧洲单独放一套,如果是在东南亚,就要在新加坡部署一套。其次还要考虑不同国家的业务知识差异是否过大,如果不同国家的业务都差不多,那么维护一套知识库就可以。例如针对不同出海阶段,或者不同规模的出海企业,在智能客服建设路径上有什么差异?结合亚马逊云科技的经验,我们推荐在企业出海的初期,可以先尝试 SaaS 类型的智能客服产品,企业可以直接注册和使用。随着用户数据越来越多,在中期阶段,可以考虑基于亚马逊的服务自建工单系统。在后期阶段,主要是构建全渠道的智能客服,比如说APP、网站、邮件、电话等等,构建全渠道的智能客服系统,对大企业来说是必不可少的。⩓
亚马逊云科技泛娱乐及广告行业资深解决方案架构师,负责智能客服解决方案和生成式BI解决方案的研究、设计和构建。擅长大数据分析和GenAI等技术在云上的应用,目前主要专注于GenAI类解决方案的落地和推广。注:点击左下角“阅读原文”,领取专家完整版实录和分享课件。