


----追光逐电 光赢未来----
机器学习和深度学习算法流程

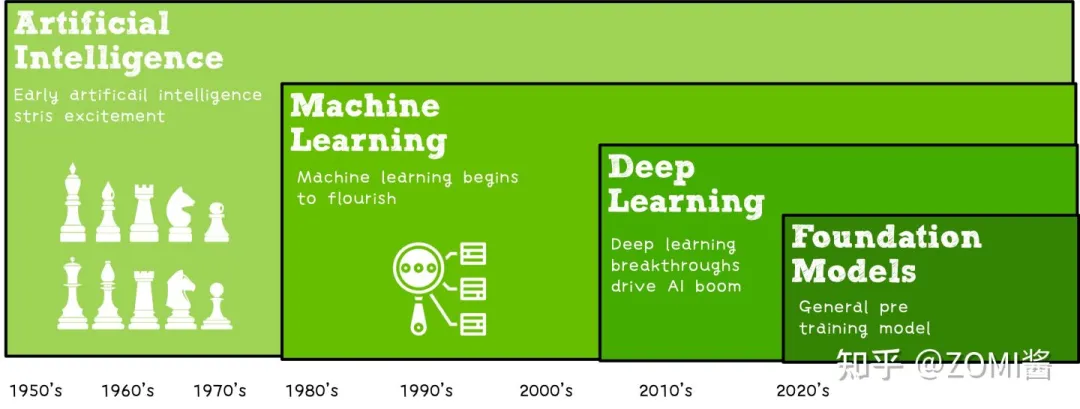
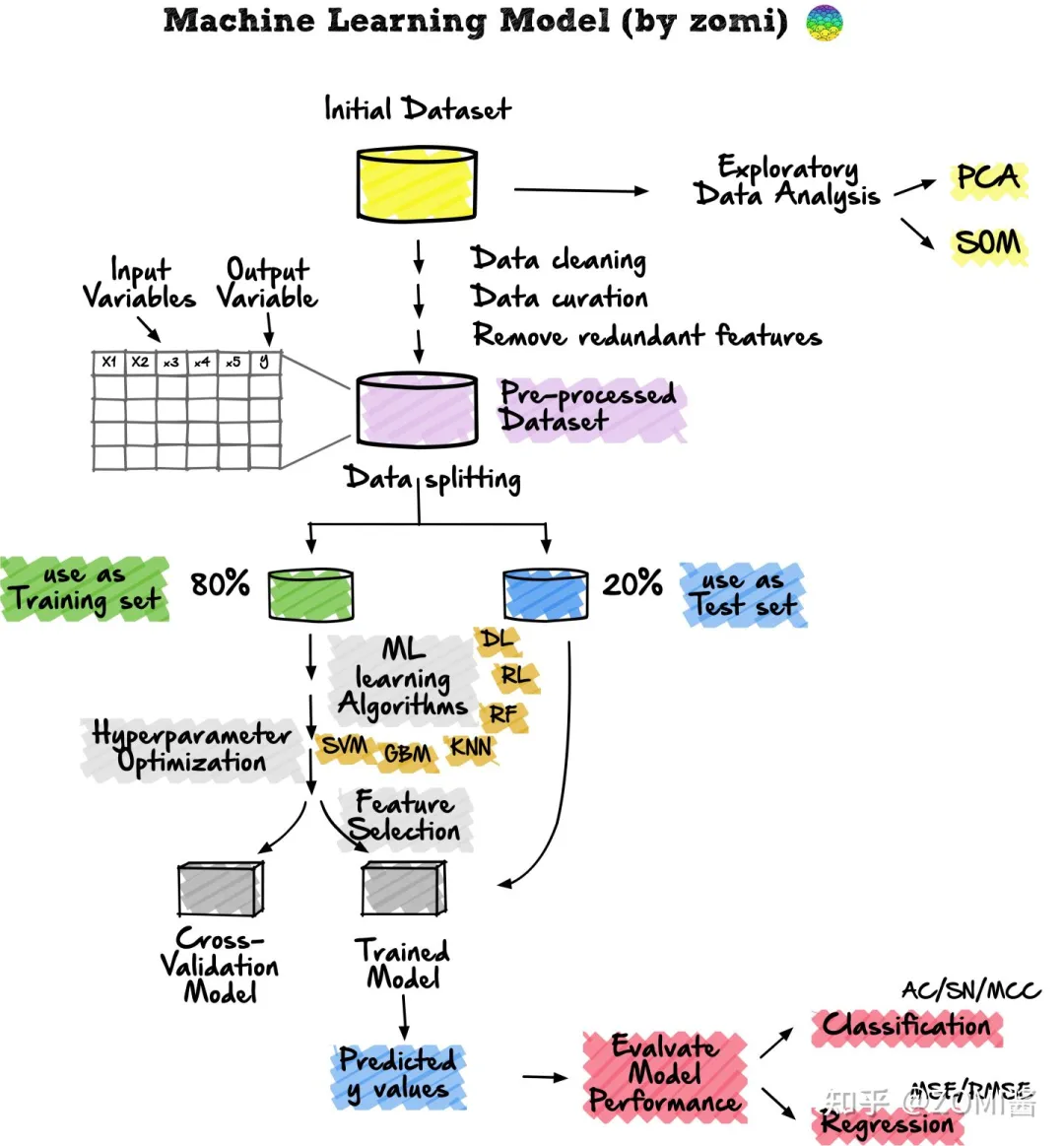
1、机器学习的算法流程
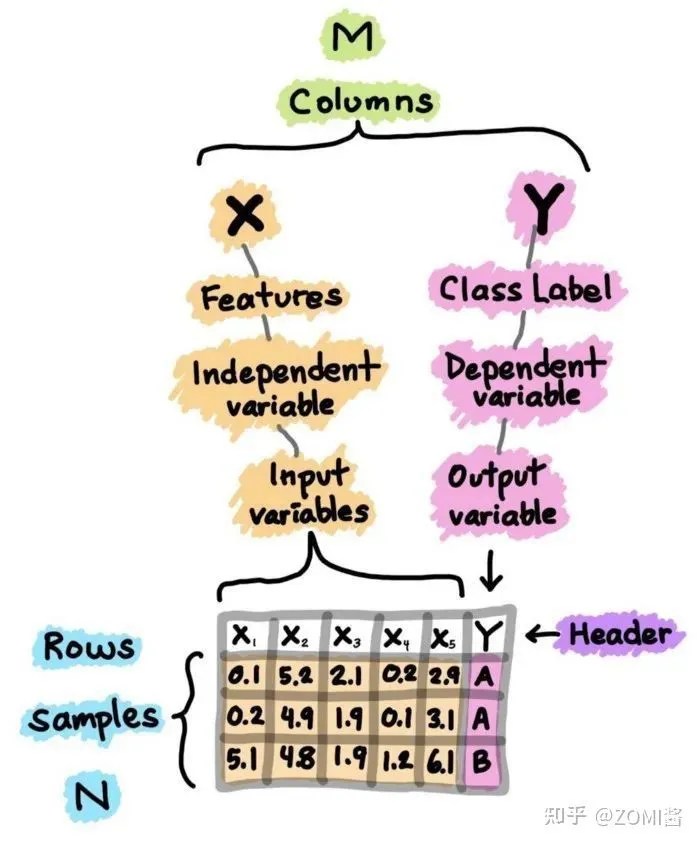
描述性统计:平均数、中位数、模式、标准差。
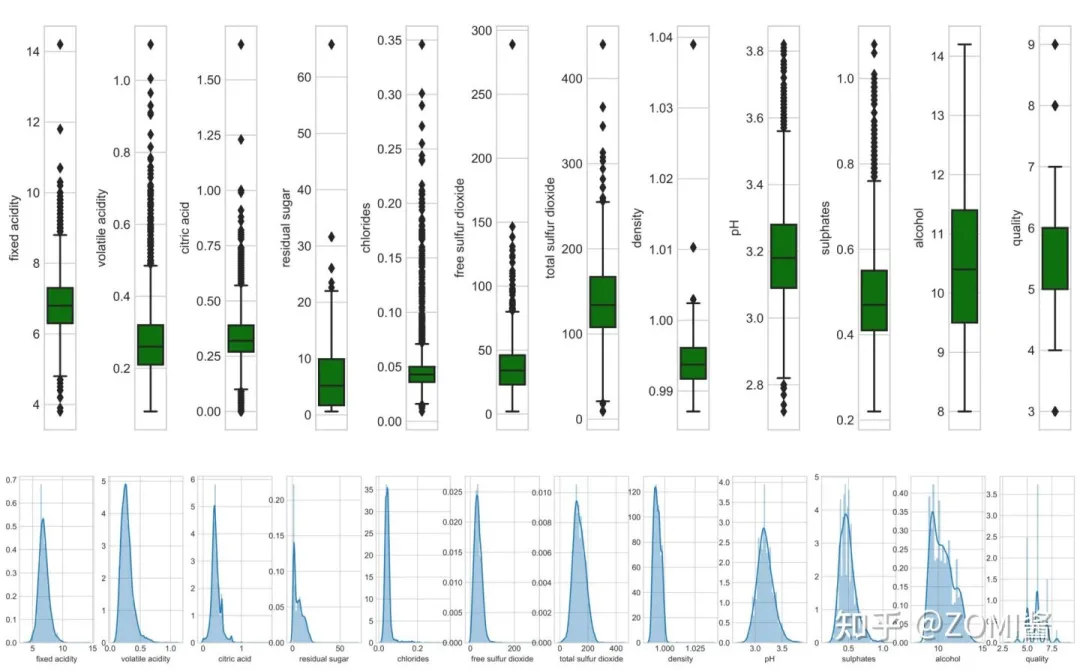
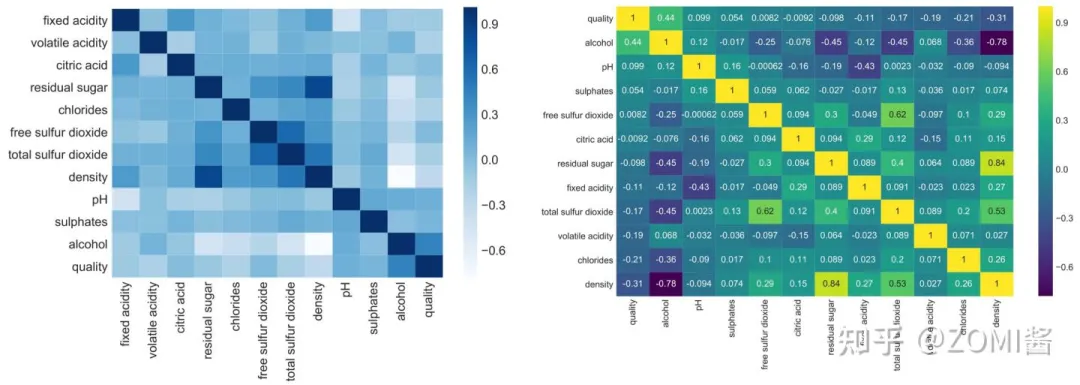
数据可视化:热力图(辨别特征内部相关性)、箱形图(可视化群体差异)、散点图(可视化特征之间的相关性)、主成分分析(可视化数据集中呈现的聚类分布)等。
数据整形:对数据进行透视、分组、过滤等。
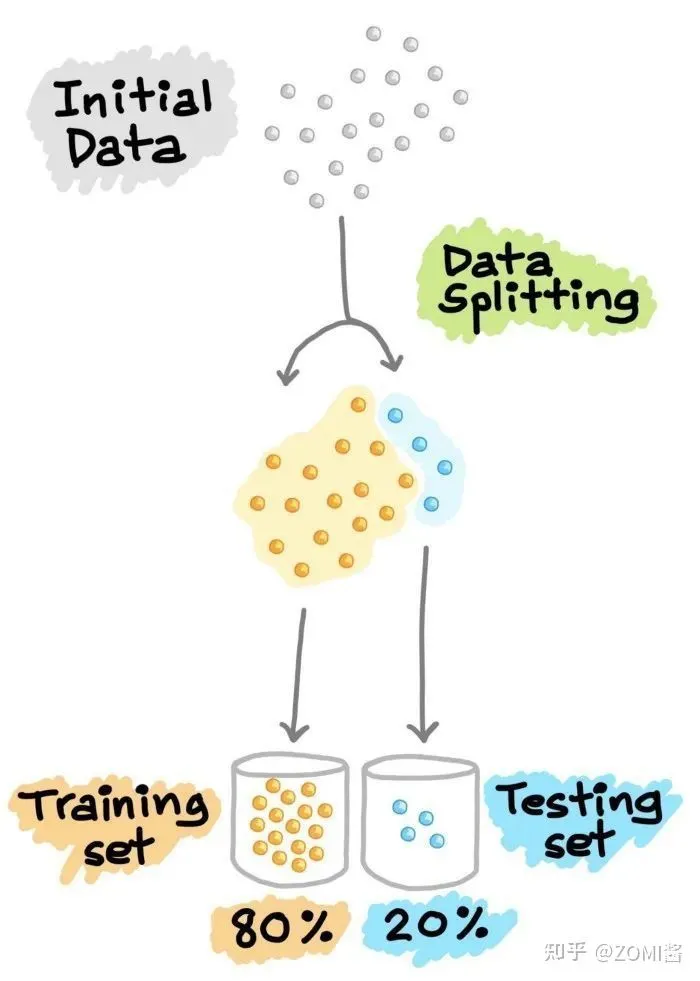
训练集 & 测试集
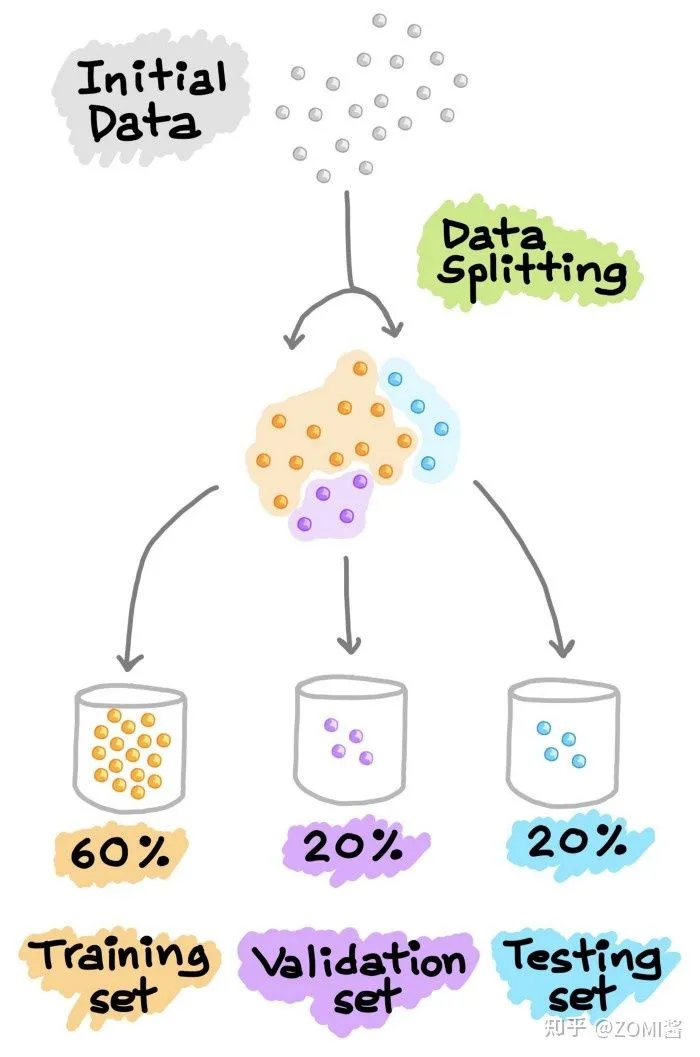
训练集 & 验证集 & 测试集
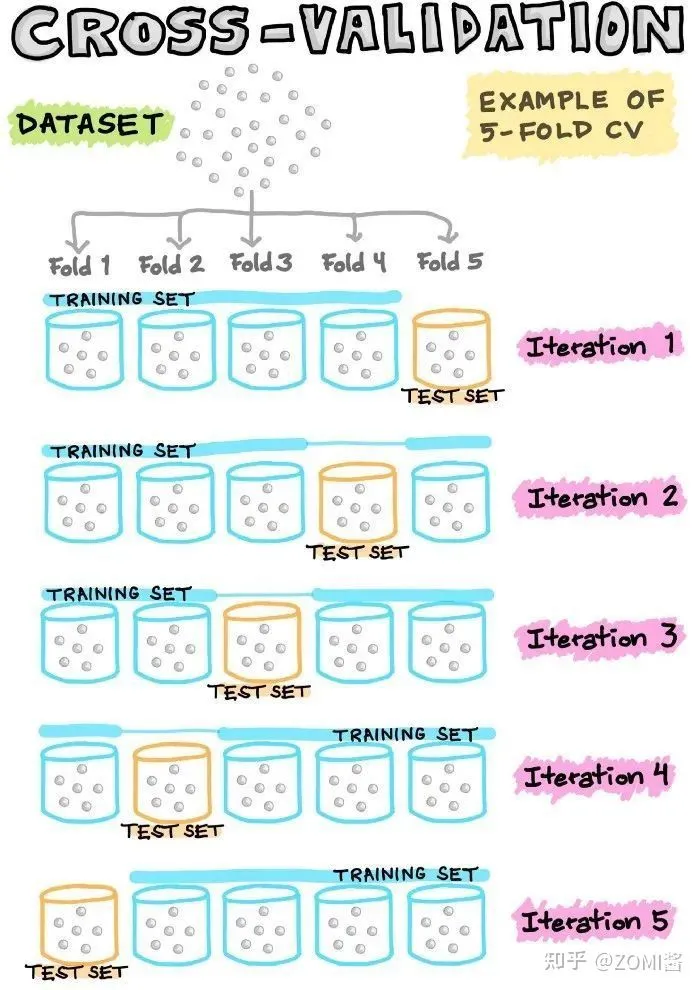
交叉验证
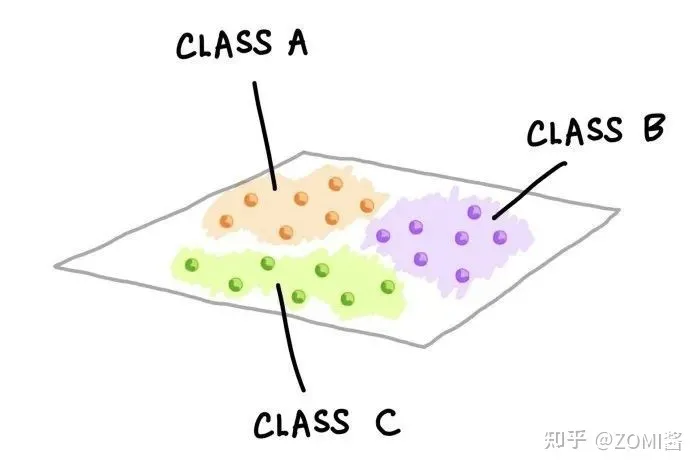
机器学习算法可以大致分为以下三种类型之一:
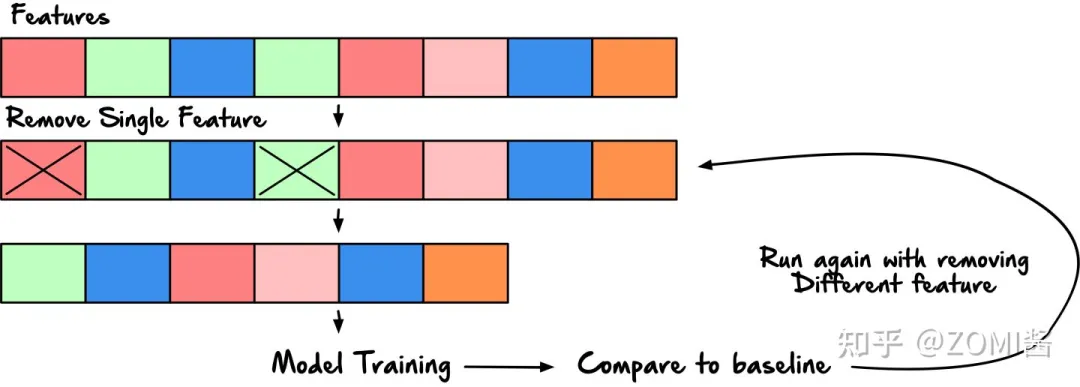
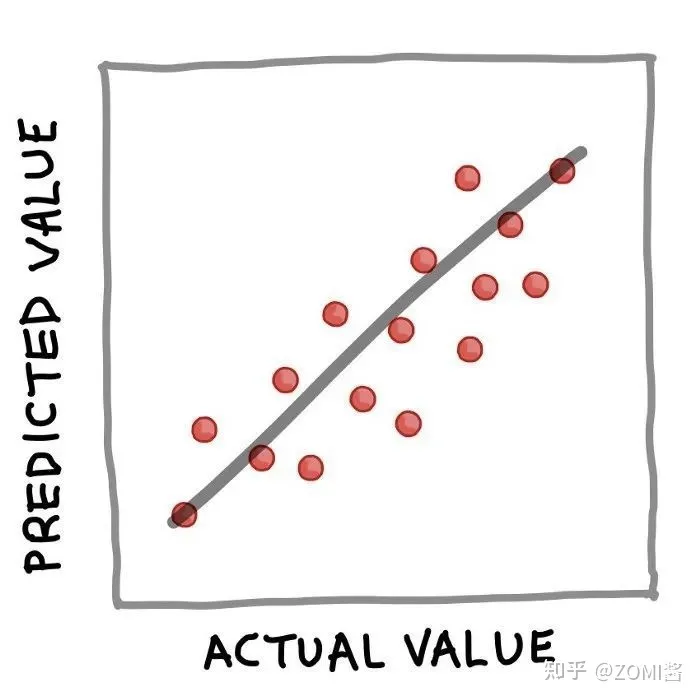
性能指标
2、深度学习算法流程
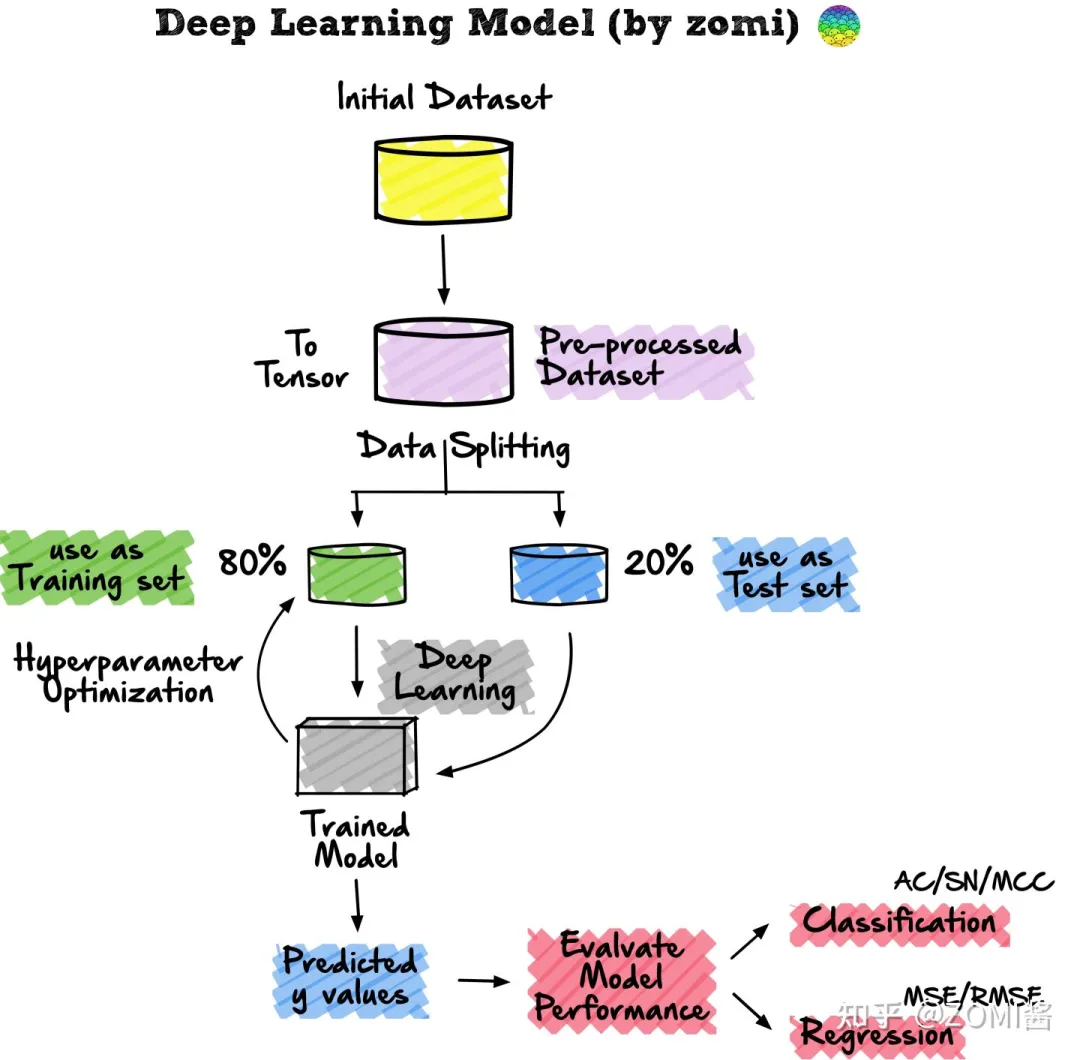
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


