有人说,20世纪是电的世纪,21世纪是光的世纪;知光解电,再小的个体都可以被赋能。追光逐电,光赢未来...欢迎来到今日光电!



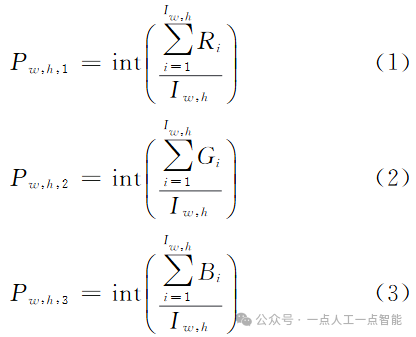
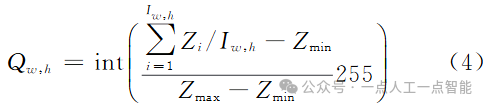
正射图像上的每个像素点代表了一定空间范围内的点云信息,如图 1所示。对于二维彩色图像,图像上各通道像素点代表给定区域内点云的平均红、绿、蓝像素。而三维深度图像上每个像素点代表给区域内点云的平均相对高度。二维图像包含三通道颜色信息,而三维图像能够反映表面深度信息。这2种正射图像采用相同的点云数据源,且成像范围一致,因此,生成的二维和三维图像具有完全重叠特性。
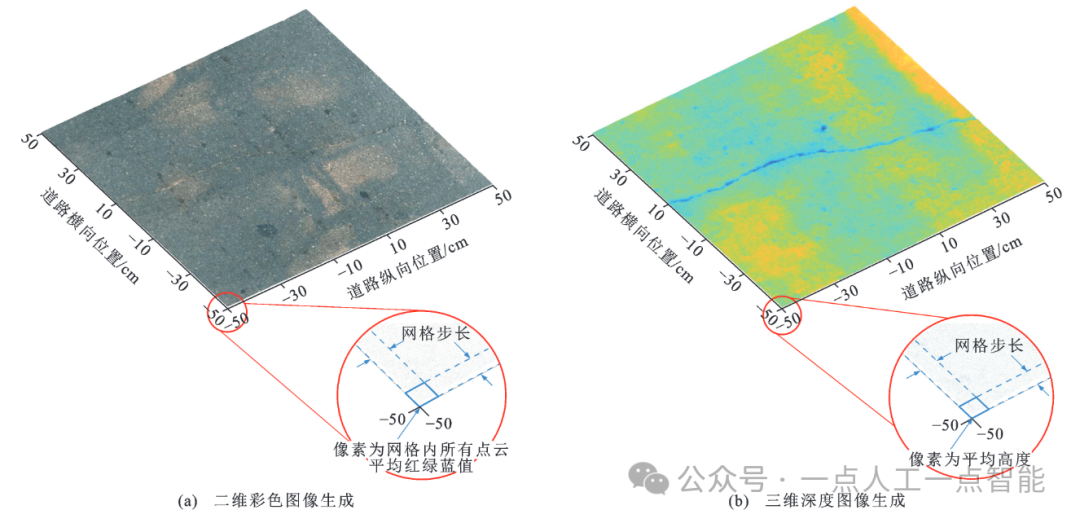
图1 路表点云栅格化
1.2 复杂场景路表破损图像数据特征
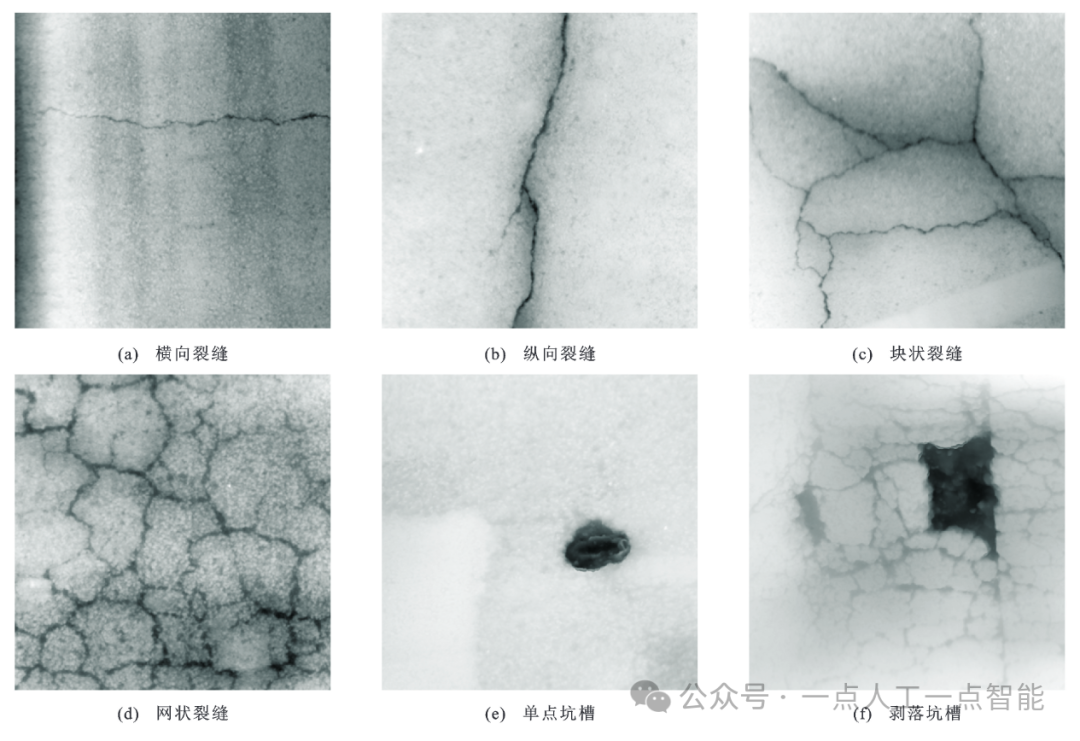
图2 不同类型与严重程度的三维破损图像

图3 不同环境噪声下的二维破损图像

面向路表破损分割的轻量化编码-解码网络
2.1 轻量化卷积运算
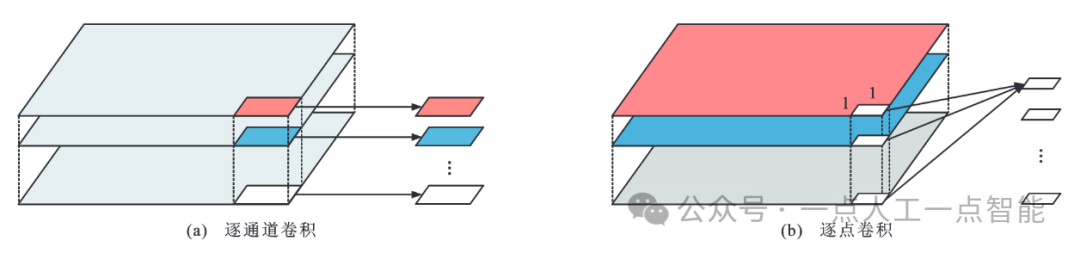
图4 深度可分离卷积运算
2.2 面向路表破损分割的轻量化编码-解码框架
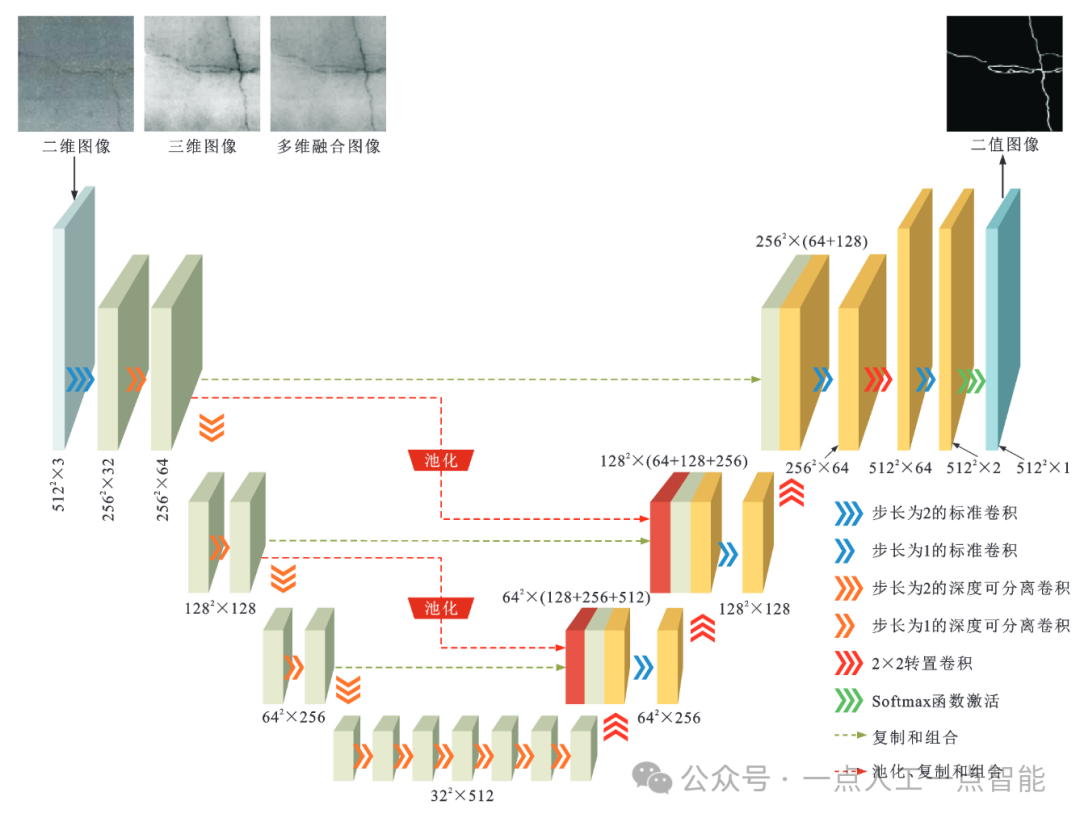
图5 轻量化编码-解码网络框架
2.3 考虑像素类别均衡的网络训练
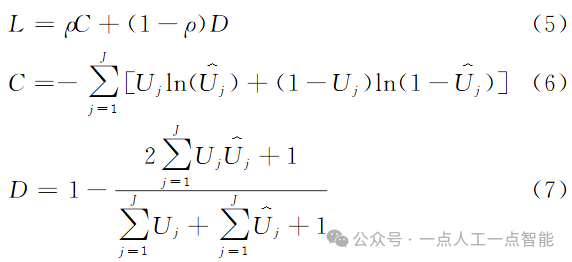
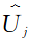 为第j个像素的概率预测值,∈[0, 1];J为像素总数。
为第j个像素的概率预测值,∈[0, 1];J为像素总数。 
多维图像融合优化
3.1 基于像素运算的多维特征融合
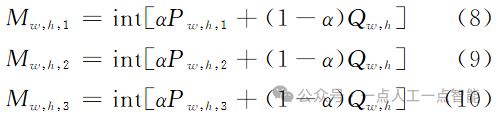

图6 基于像素运算的多维融合图像生成
3.2 基于通道重组的多维特征融合

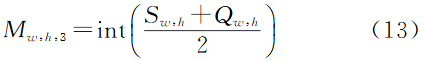
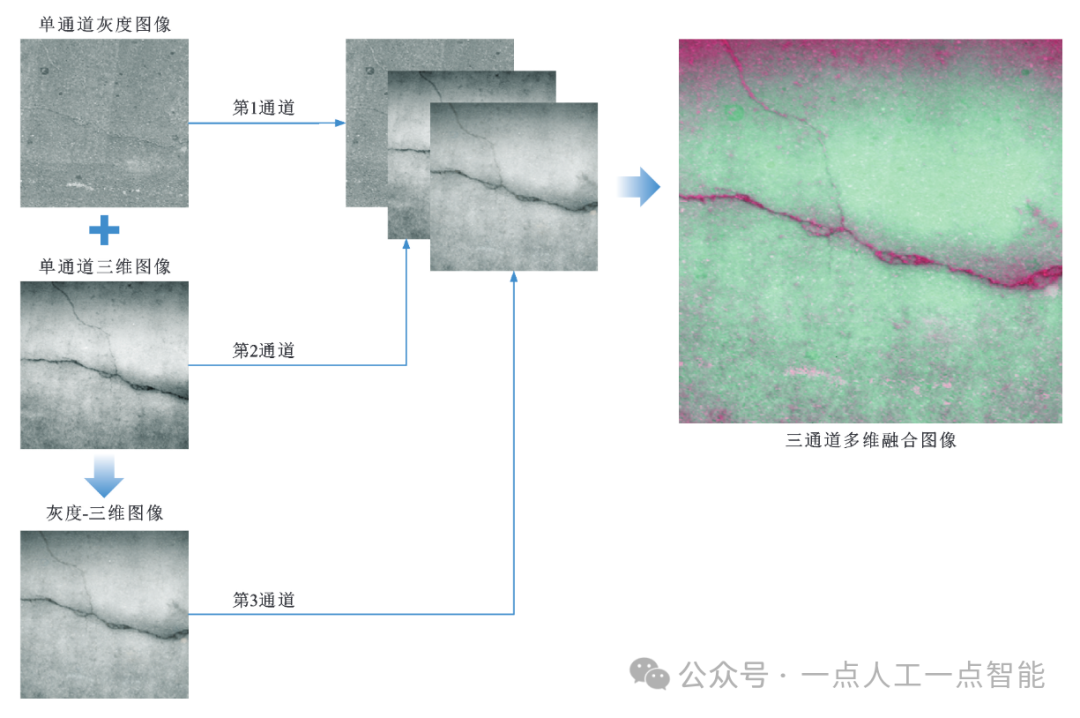
图7 基于通道重组的多维融合图像生成

试验结果分析
4.1 不同路表破损图像分割模型训练结果
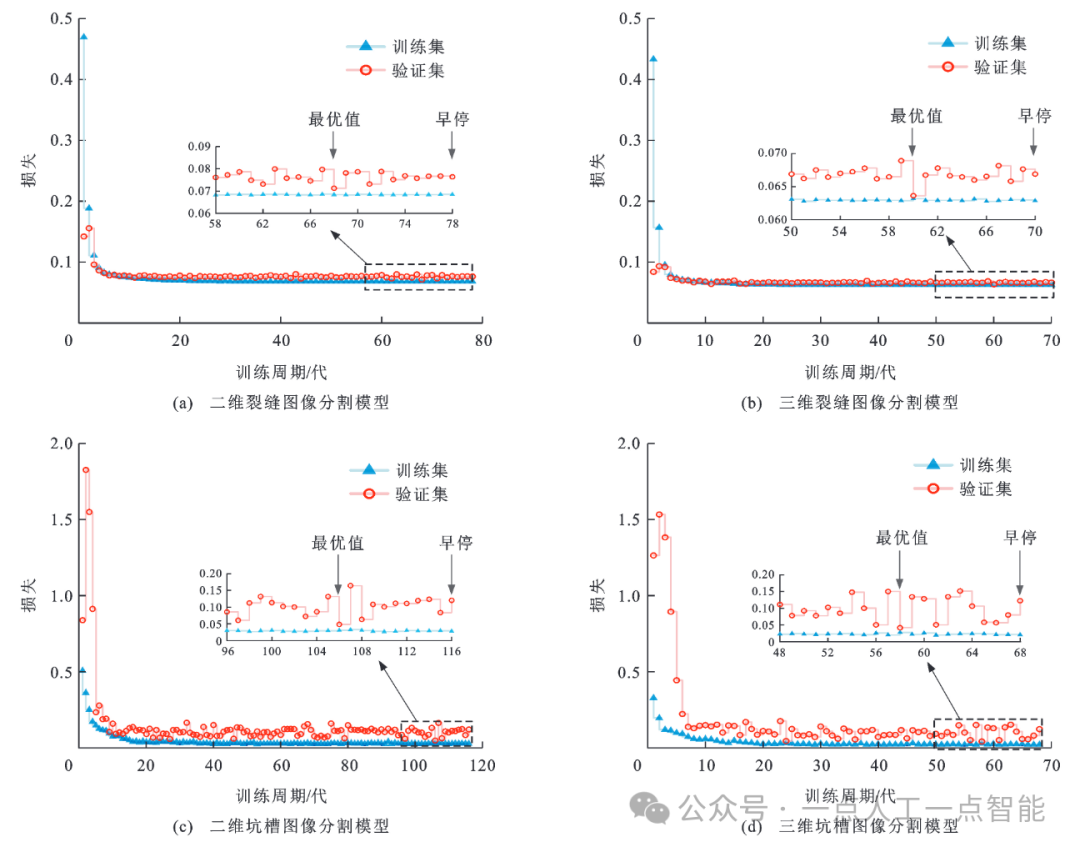
图8 不同PDU-net模型训练过程
4.2 二维、三维路表破损图像分割性能评价
4.2.1 路表破损图像分割性能定量评价
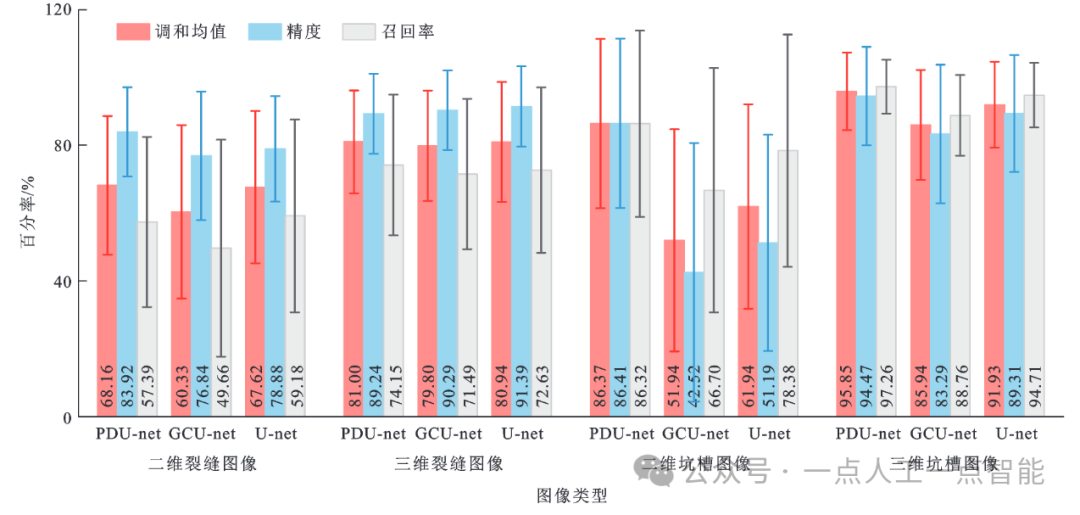
图9 路表破损图像分割定量评价
4.2.2 路表破损图像分割性能定性评价
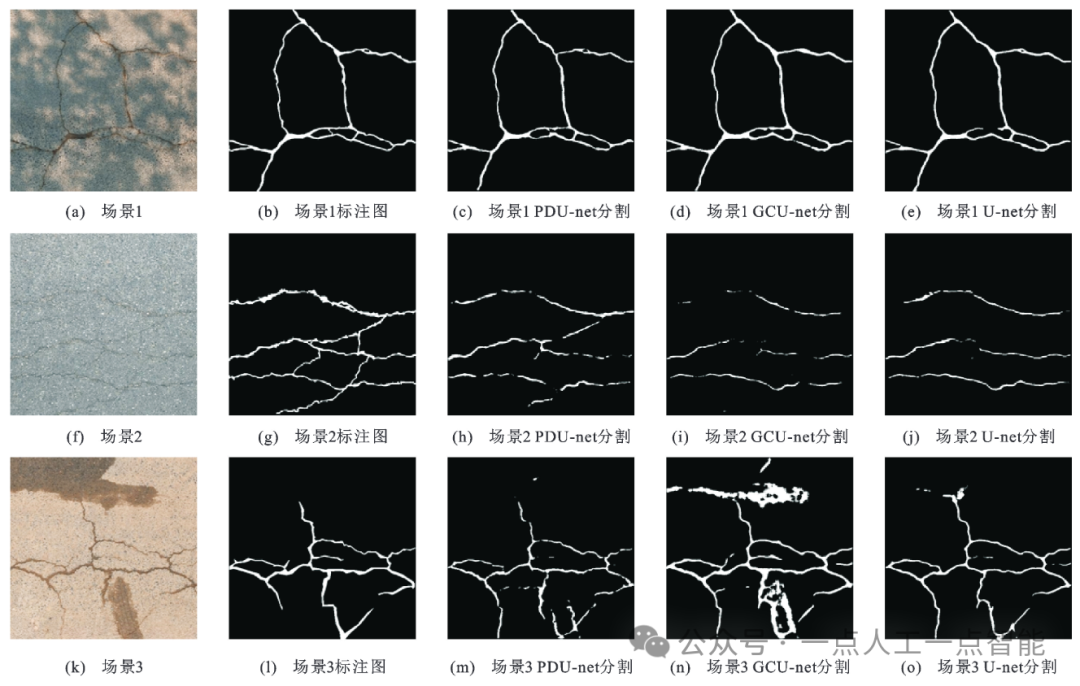
图10 二维裂缝图像分割可视化

图11 三维裂缝图像分割可视化

图12 二维坑槽图像分割可视化

图13 三维坑槽图像分割可视化
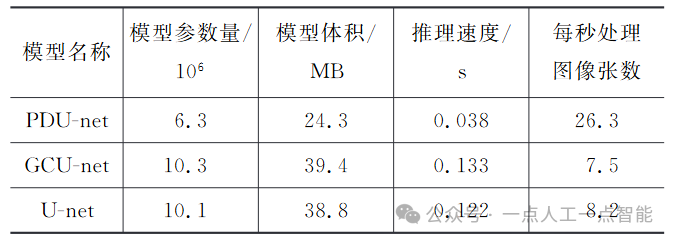
4.2.3 路表破损图像分割效率分析
表1 不同模型的计算效率
4.3 多维融合裂缝图像分割性能评价
4.3.1 基于像素运算的裂缝图像分割性能优化
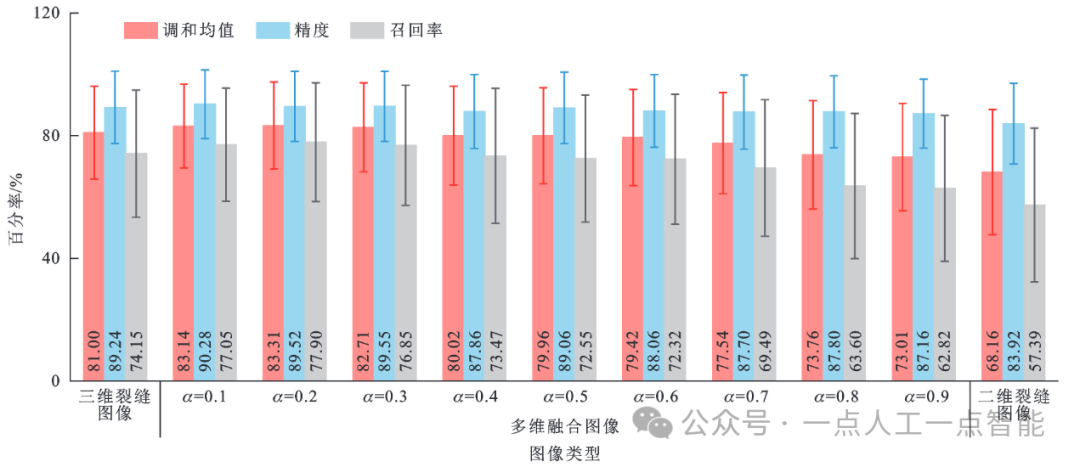
图14 像素运算多维融合图像分割性能定量评价
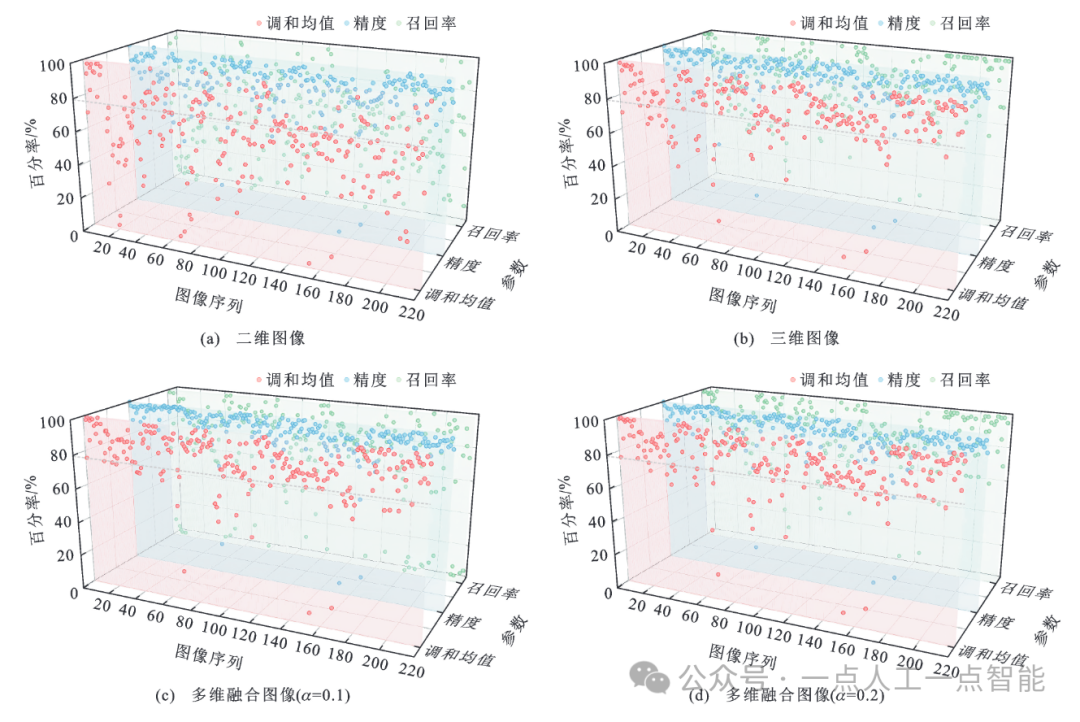
图15 不同裂缝图像分割精度分布
4.3.2 基于通道重组的裂缝图像分割性能优化
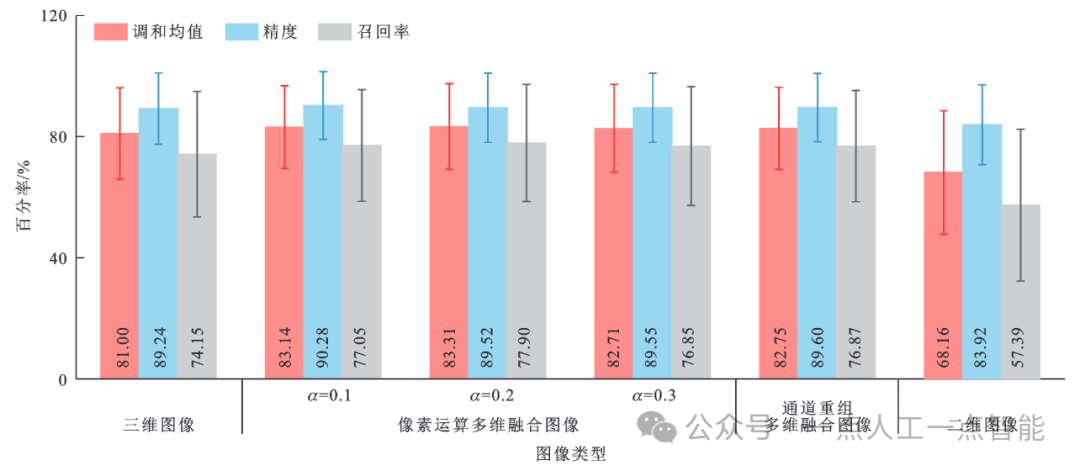
图16 通道重组多维融合图像分割性能定量评价
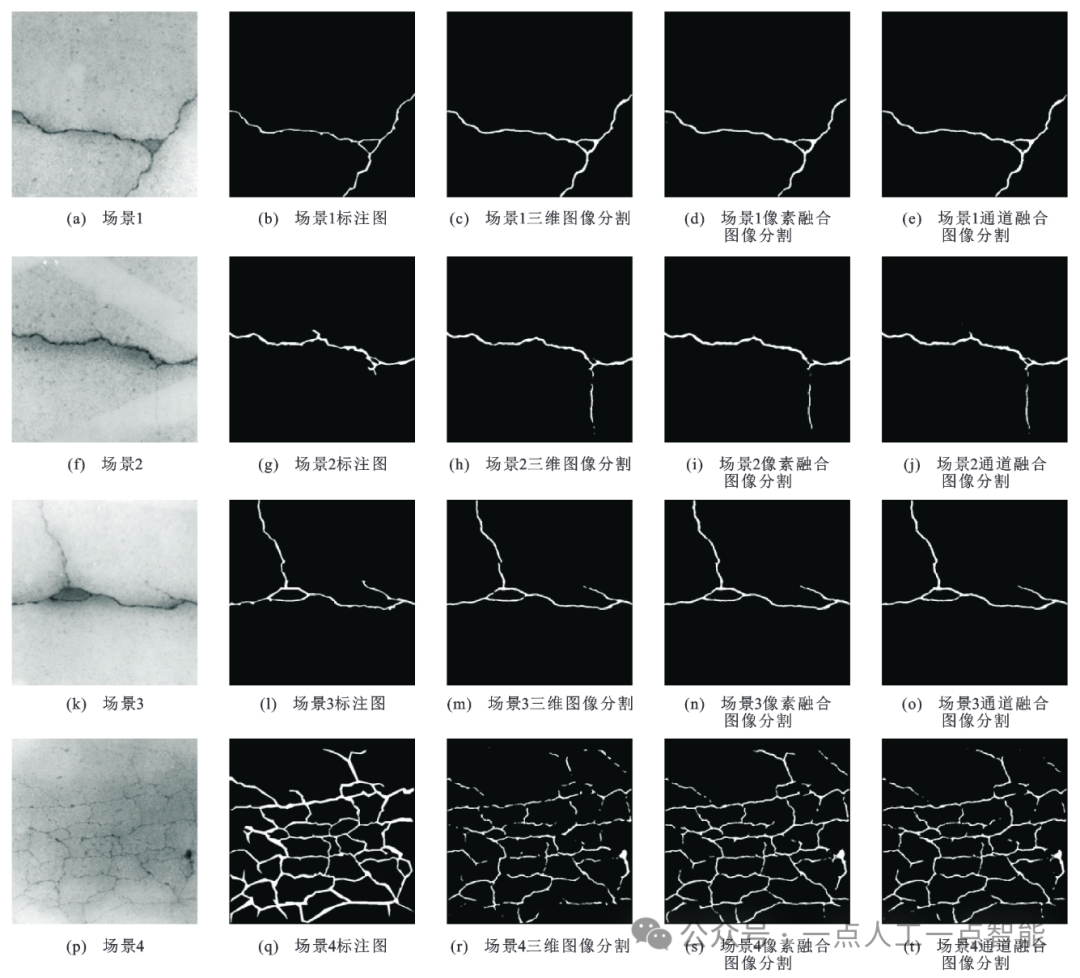
图17 多维融合裂缝图像分割可视化

结语
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


