


在自然语言处理领域,大型语言模型(LLM)如GPT-3、BERT等已经取得了显著的进展,它们能够生成连贯、自然的文本,回答问题,并执行其他复杂的语言任务。然而,这些模型存在一些固有的局限性,如“模型幻觉问题”、“时效性问题”和“数据安全问题”。为了克服这些限制,检索增强生成(RAG)技术应运而生。
计算机行业深度:从技术路径,纵观国产大模型逆袭之路
大模型的局限性
| 大模型现存问题 | 大型语言模型的局限性 |
|---|---|
| 问题1.1 | 模型幻觉问题:生成内容可能不准确或不一致 |
| 问题1.2 | 时效性问题:生成的内容不具有当前时效性 |
| 问题1.3 | 数据安全问题:可能存在敏感信息泄露风险 |
在自然语言处理领域,幻觉(Hallucination)被定义为生成的内容与提供的源内容无关或不忠实,具体而言,是一种虚假的感知,但在表面上却似乎是真实的。在一般语境中,幻觉是一个心理学术语,指的是一种特定类型的感知。在自然语言处理或大型语言模型的语境下,这种感知即为一种虚假的、不符合实际的信息。
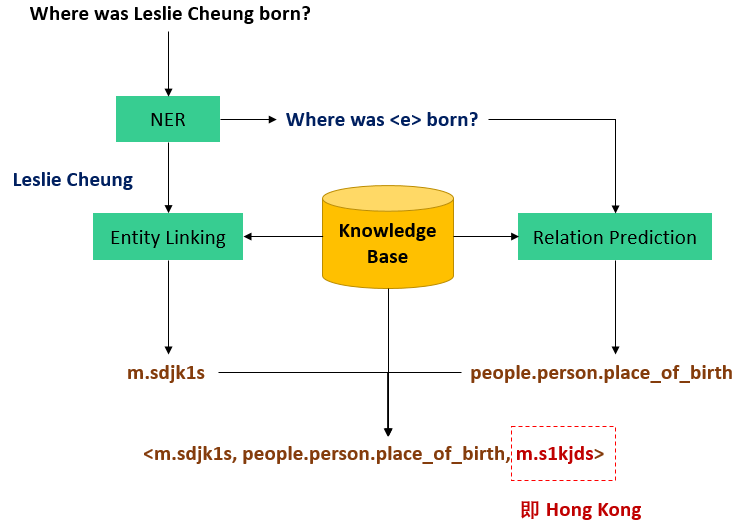
知识库问答(Knowledge Base Question Answering,KBQA)
RAG介绍
RAG技术通过检索外部知识库,避免了幻觉问题的困扰。相较于单纯依赖大型语言模型对海量文本数据的学习,RAG允许模型在生成文本时从事实丰富的外部知识库中检索相关信息。
RAG技术的时效性优势使其在处理实效性较强的问题时更为可靠。通过与外部知识库的连接,RAG确保了模型可以获取最新的信息,及时适应当前的事件和知识。
与传统的知识库问答(KBQA)相比,RAG技术在知识检索方面更加灵活,不仅能够从结构化的知识库中检索信息,还能够应对非结构化的自然语言文本。
| RAG优点 | 描述 |
|---|---|
| 优点1.1 | 提高准确性和相关性 |
| 优点1.2 | 改善时效性,使模型适应当前事件和知识 |
| 优点1.3 | 降低生成错误风险,依赖检索系统提供的准确信息 |
RAG被构建为一个应用于大型语言模型的框架,其目标是通过结合大模型的生成能力和外部知识库的检索机制,提升自然语言处理任务的效果。 RAG并非旨在取代已有的知识库问答(KBQA)系统,而是作为一种补充,利用检索机制强调实时性和准确性,从而弥补大型语言模型固有的局限性。
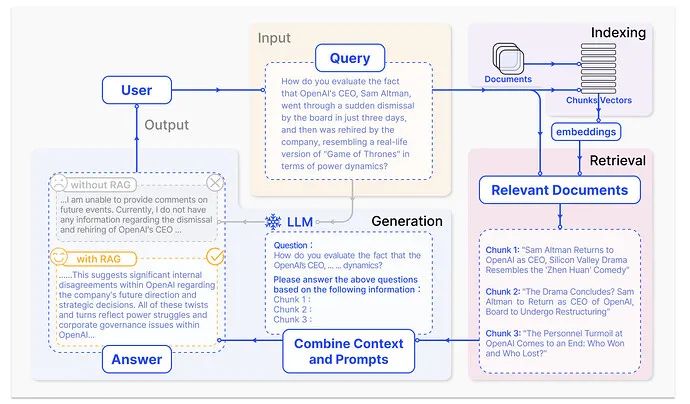
RAG和SFT对比
| 微调模型 | RAG | |
|---|---|---|
| 优点 | 针对特定任务调整预训练模型。优点是可针对特定任务优化; | 结合检索系统和生成模型。优点是能利用最新信息,提高答案质量,具有更好的可解释性和适应性: |
| 缺点 | 但缺点是更新成本高,对新信息适应性较差; | 是可能面临检索质量问题和曾加额外计算资源需求; |
| 特性 | RAG技术 | SFT模型微调 |
|---|---|---|
| 知识更新 | 实时更新检索库,适合动态数据,无需频繁重训 | 存储静态信息,更新知识需要重新训练 |
| 外部知识 | 高效利用外部资源,适合各类数据库 | 可对齐外部知识,但对动态数据源不够灵活 |
| 数据处理 | 数据处理需求低 | 需构建高质量数据集,数据限制可能影响性能 |
| 模型定制化 | 专注于信息检索和整合,定制化程度低 | 可定制行为,风格及领域知识 |
| 可解释性 | 答案可追溯,解释性高 | 解释性相对低 |
| 计算资源 | 需要支持检索的计算资源,维护外部数据源 | 需要训练数据集和微调资源 |
| 延迟要求 | 数据检索可能增加延迟 | 微调后的模型反应更快 |
| 减少幻觉 | 基于实际数据,幻觉减少 | 通过特定域训练可减少幻觉,但仍然有限 |
| 道德和隐私 | 处理外部文本数据时需要考虑隐私和道德问题 | 训练数据的敏感内容可能引发隐私问题 |
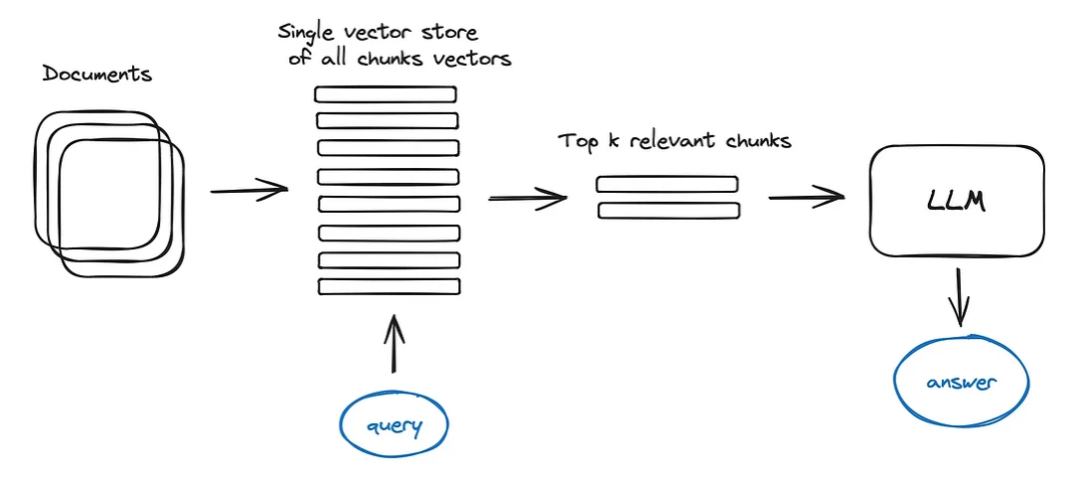
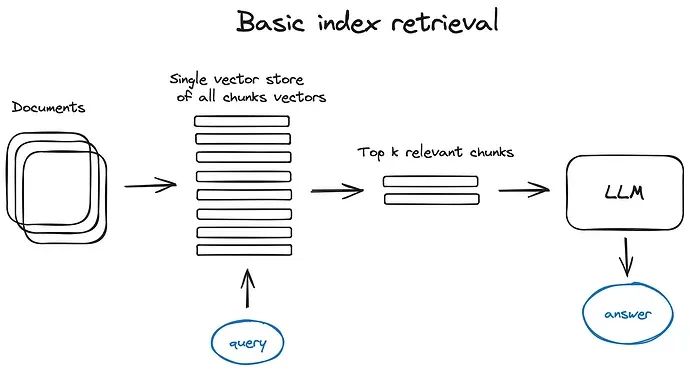
RAG实现流程
| RAG流程 | 描述 |
|---|---|
| 步骤1:问题理解 | 准确把握用户的意图 |
| 步骤2:知识检索 | 从知识库中相关的知识检索 |
| 步骤3:答案生成 | 将检索结果与问题 |
RAG每个步骤都面临一些挑战,这些挑战使得RAG的实现变得复杂而困难。在问题理解阶段,系统需要准确把握用户的意图。用户提问往往是短文本,而知识库中的信息可能是长文本。 将用户提问与知识库中的知识建立有效的关联是一个难点,特别是考虑到用户提问可能模糊,用词不规范,难以直接找到相关的知识。
| 技术类型 | 描述 |
|---|---|
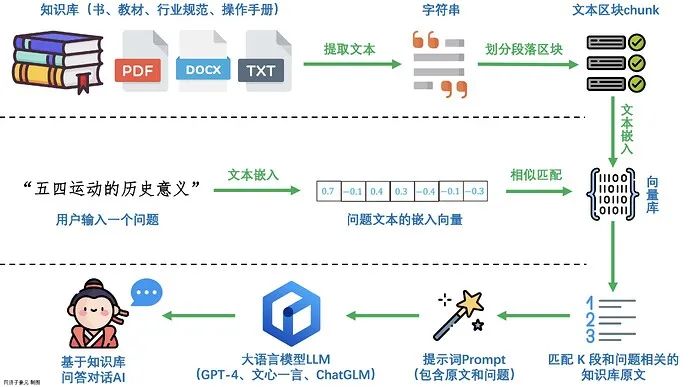
| Naive RAG | Naive RAG是RAG技术的最基本形式,也被称为经典RAG。包括索引、检索、生成三个基本步骤。索引阶段将文档库分割成短的Chunk,并构建向量索引。检索阶段根据问题和Chunks的相似度检索相关文档片段。生成阶段以检索到的上下文为条件,生成问题的回答。 |
| Advanced RAG | Advanced RAG在Naive RAG的基础上进行优化和增强。包含额外处理步骤,分别在数据索引、检索前和检索后进行。包括更精细的数据清洗、设计文档结构和添加元数据,以提升文本一致性、准确性和检索效率。在检索前使用问题的重写、路由和扩充等方式对齐问题和文档块之间的语义差异。在检索后通过重排序避免“Lost in the Middle”现象,或通过上下文筛选与压缩缩短窗口长度。 |
| Modular RAG | Modular RAG引入更多具体功能模块,例如查询搜索引擎、融合多个回答等。技术上融合了检索与微调、强化学习等。流程上对RAG模块进行设计和编排,出现多种不同RAG模式。提供更大灵活性,系统可以根据应用需求选择合适的功能模块组合。模块化RAG的引入使得系统更自由、灵活,适应不同场景和需求。 |
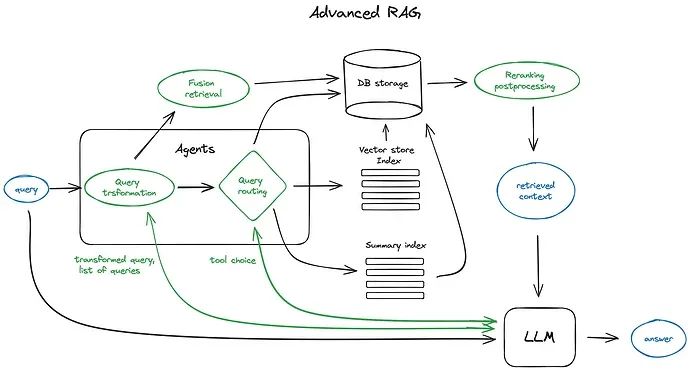
| 技术模块 | 描述 |
|---|---|
| 意图理解 | 意图理解模块负责准确把握用户提出的问题,确定用户的意图和主题。处理用户提问的模糊性和不规范性,为后续流程提供清晰的任务目标。 |
| 文档解析 | 文档解析模块用于处理来自不同来源的文档,包括PDF、PPT、Neo4j等格式。该模块负责将文档内容转化为可处理的结构化形式,为知识检索提供合适的输入。 |
| 文档索引 | 文档索引模块将解析后的文档分割成短的Chunk,并构建向量索引。或通过全文索引进行文本检索,使得系统能够更快速地找到与用户问题相关的文档片段。 |
| 向量嵌入 | 向量嵌入模块负责将文档索引中的内容映射为向量表示,以便后续的相似度计算。这有助于模型更好地理解文档之间的关系,提高知识检索的准确性。 |
| 知识检索 | 知识检索模块根据用户提问和向量嵌入计算的相似度检索或文本检索打分。这一步骤需要解决问题和文档之间的语义关联,确保检索的准确性。 |
| 重排序 | 重排序模块在知识检索后对文档库进行重排序,以避免“Lost in the Middle”现象,确保最相关的文档片段在前面。 |
| 大模型回答 | 大模型回答模块利用大型语言模型生成最终的回答。该模块结合检索到的上下文,以生成连贯、准确的文本回答。 |
| 其他功能模块 | 可根据具体应用需求引入其他功能模块,如查询搜索引擎、融合多个回答等。模块化设计使得系统更加灵活,能够根据不同场景选择合适的功能模块组合。 |
两个大模型介绍
《HotChips 2024大会技术合集(1)》
《HotChips 2024大会技术合集(2)》
《HotChips 2024大会技术合集(3)》
《HotChips 2024大会技术合集(4)》
《HotChips 2024大会技术合集(5)》
《HotChips 2024大会技术合集(6)》
《HotChips 2024大会技术合集(7)》
《HotChips 2024大会技术合集(8)》
机器人专题研究:产业发展概览(2024)
《算力网络:光网络技术合集(1)》
1、面向算力网络的新型全光网技术发展及关键器件探讨
2、面向算力网络的光网络智能化架构与技术白皮书
3、2023开放光网络系统验证测试规范
4、面向通感算一体化光网络的光纤传感技术白皮书
《算力网络:光网络技术合集(2)》
1、数据中心互联开放光传输系统设计
2、确定性光传输支撑广域长距算力互联
3、面向时隙光交换网络的纳秒级时间同步技术
4、数据中心光互联模块发展趋势及新技术研究
面向超万卡集群的新型智算技术白皮书
面向AI大模型的智算中心网络演进白皮书
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


