


----追光逐电 光赢未来----
一、在anaconda中创建虚拟环境yolov5,python版本不低于3.8即可。
conda create -n yolo5 python==3.9
二、激活环境,下载pytorch框架(以cpu版本为例),pytorch版本不低于1.8即可。
activate yolov5
pip3 install torch torchvision torchaudio
三、下载源代码
可以采用git或者pycharm终端来下载代码,并安装相关的库。
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
四、YoLov5代码解析:
if __name__ == '__main__':"""weights:训练的权重source:测试数据,可以是图片/视频路径,也可以是'0'(电脑自带摄像头),也可以是rtsp等视频流output:网络预测之后的图片/视频的保存路径img-size:网络输入图片大小conf-thres:置信度阈值iou-thres:做nms的iou阈值device:设置设备view-img:是否展示预测之后的图片/视频,默认Falsesave-txt:是否将预测的框坐标以txt文件形式保存,默认Falseclasses:设置只保留某一部分类别,形如0或者0 2 3agnostic-nms:进行nms是否也去除不同类别之间的框,默认Falseaugment:推理的时候进行多尺度,翻转等操作(TTA)推理update:如果为True,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息,默认为False"""parser = argparse.ArgumentParser()parser.add_argument('--weights', nargs='+', type=str, default='', help='model.pt path(s)')parser.add_argument('--source', type=str, default='inference/images', help='source') # file/folder, 0 for webcamparser.add_argument('--output', type=str, default='inference/output', help='output folder') # output folderparser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')parser.add_argument('--conf-thres', type=float, default=0.65, help='object confidence threshold')parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')parser.add_argument('--view-img', action='store_true', help='display results')parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')parser.add_argument('--augment', action='store_true', help='augmented inference')parser.add_argument('--update', action='store_true', help='update all models')opt = parser.parse_args()print(opt)with torch.no_grad():if opt.update: # update all models (to fix SourceChangeWarning)for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']:detect()# 去除pt文件中的优化器等信息strip_optimizer(opt.weights)else:detect()
vimpo argparseimport osimport platformimport shutilimport timefrom pathlib import Pathimport cv2import torchimport torch.backends.cudnn as cudnnfrom numpy import randomfrom models.experimental import attempt_loadfrom utils.datasets import LoadStreams, LoadImagesfrom utils.general import (check_img_size, non_max_suppression, apply_classifier, scale_coords, xyxy2xywh, plot_one_box, strip_optimizer)from utils.torch_utils import select_device, load_classifier, time_synchronizeddef detect(save_img=False):# 获取输出文件夹,输入源,权重,参数等参数out, source, weights, view_img, save_txt, imgsz = \opt.output, opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_sizewebcam = source == '0' or source.startswith('rtsp') or source.startswith('http') or source.endswith('.txt')# Initialize# 获取设备device = select_device(opt.device)# 移除之前的输出文件夹if os.path.exists(out):shutil.rmtree(out) # delete output folderos.makedirs(out) # make new output folder# 如果设备为gpu,使用Float16half = device.type != 'cpu' # half precision only supported on CUDA# Load model# 加载Float32模型,确保用户设定的输入图片分辨率能整除32(如不能则调整为能整除并返回)model = attempt_load(weights, map_location=device) # load FP32 modelimgsz = check_img_size(imgsz, s=model.stride.max()) # check img_size# 设置Float16if half:model.half() # to FP16# Second-stage classifier# 设置第二次分类,默认不使用classify = Falseif classify:modelc = load_classifier(name='resnet101', n=2) # initializemodelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']) # load weightsmodelc.to(device).eval()# Set Dataloader# 通过不同的输入源来设置不同的数据加载方式vid_path, vid_writer = None, Noneif webcam:view_img = Truecudnn.benchmark = True # set True to speed up constant image size inferencedataset = LoadStreams(source, img_size=imgsz)else:save_img = True# 如果检测视频的时候想显示出来,可以在这里加一行view_img = Trueview_img = Truedataset = LoadImages(source, img_size=imgsz)# Get names and colors# 获取类别名字names = model.module.names if hasattr(model, 'module') else model.names# 设置画框的颜色colors = [[random.randint(0, 255) for _ in range(3)] for _ in range(len(names))]# Run inferencet0 = time.time()# 进行一次前向推理,测试程序是否正常img = torch.zeros((1, 3, imgsz, imgsz), device=device) # init img_ = model(img.half() if half else img) if device.type != 'cpu' else None # run once"""path 图片/视频路径img 进行resize+pad之后的图片img0 原size图片cap 当读取图片时为None,读取视频时为视频源"""for path, img, im0s, vid_cap in dataset:img = torch.from_numpy(img).to(device)# 图片也设置为Float16img = img.half() if half else img.float() # uint8 to fp16/32img /= 255.0 # 0 - 255 to 0.0 - 1.0# 没有batch_size的话则在最前面添加一个轴if img.ndimension() == 3:img = img.unsqueeze(0)# Inferencet1 = time_synchronized()# print("preprocess_image:", t1 - t0)# t1 = time.time()"""前向传播 返回pred的shape是(1, num_boxes, 5+num_class)h,w为传入网络图片的长和宽,注意dataset在检测时使用了矩形推理,所以这里h不一定等于wnum_boxes = h/32 * w/32 + h/16 * w/16 + h/8 * w/8pred[..., 0:4]为预测框坐标预测框坐标为xywh(中心点+宽长)格式pred[..., 4]为objectness置信度pred[..., 5:-1]为分类结果"""pred = model(img, augment=opt.augment)[0]t1_ = time_synchronized()print('inference:', t1_ - t1)# Apply NMS# 进行NMS"""pred:前向传播的输出conf_thres:置信度阈值iou_thres:iou阈值classes:是否只保留特定的类别agnostic:进行nms是否也去除不同类别之间的框经过nms之后,预测框格式:xywh-->xyxy(左上角右下角)pred是一个列表list[torch.tensor],长度为batch_size每一个torch.tensor的shape为(num_boxes, 6),内容为box+conf+cls"""pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)t2 = time_synchronized()# t2 = time.time()# Apply Classifier# 添加二次分类,默认不使用if classify:pred = apply_classifier(pred, modelc, img, im0s)# Process detections# 对每一张图片作处理for i, det in enumerate(pred): # detections per image# 如果输入源是webcam,则batch_size不为1,取出dataset中的一张图片if webcam: # batch_size >= 1p, s, im0 = path[i], '%g: ' % i, im0s[i].copy()else:p, s, im0 = path, '', im0s# 设置保存图片/视频的路径save_path = str(Path(out) / Path(p).name)# 设置保存框坐标txt文件的路径txt_path = str(Path(out) / Path(p).stem) + ('_%g' % dataset.frame if dataset.mode == 'video' else '')# 设置打印信息(图片长宽)s += '%gx%g ' % img.shape[2:] # print stringgn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwhif det is not None and len(det):# Rescale boxes from img_size to im0 size# 调整预测框的坐标:基于resize+pad的图片的坐标-->基于原size图片的坐标# 此时坐标格式为xyxydet[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()# Print results# 打印检测到的类别数量for c in det[:, -1].unique():n = (det[:, -1] == c).sum() # detections per classs += '%g %ss, ' % (n, names[int(c)]) # add to string# Write results# 保存预测结果for *xyxy, conf, cls in det:if save_txt: # Write to file# 将xyxy(左上角+右下角)格式转为xywh(中心点+宽长)格式,并除上w,h做归一化,转化为列表再保存xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywhwith open(txt_path + '.txt', 'a') as f:f.write(('%g ' * 5 + '\n') % (cls, *xywh)) # label format# 在原图上画框if save_img or view_img: # Add bbox to imagelabel = '%s %.2f' % (names[int(cls)], conf)plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)# Print time (inference + NMS)# 打印前向传播+nms时间print('%sDone. (%.3fs)' % (s, t2 - t1))# Stream results# 如果设置展示,则show图片/视频if view_img:cv2.imshow(p, im0)if cv2.waitKey(1) == ord('q'): # q to quitraise StopIteration# Save results (image with detections)# 设置保存图片/视频if save_img:if dataset.mode == 'images':cv2.imwrite(save_path, im0)else:if vid_path != save_path: # new videovid_path = save_pathif isinstance(vid_writer, cv2.VideoWriter):vid_writer.release() # release previous video writerfourcc = 'mp4v' # output video codecfps = vid_cap.get(cv2.CAP_PROP_FPS)w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*fourcc), fps, (w, h))vid_writer.write(im0)if save_txt or save_img:print('Results saved to %s' % Path(out))# 打开保存图片和txt的路径(好像只适用于MacOS系统)if platform == 'darwin' and not opt.update: # MacOSos.system('open ' + save_path)# 打印总时间print('Done. (%.3fs)' % (time.time() - t0))
来自csdn:
https://blog.csdn.net/Q1u1NG/article/details/108093525
yolov5代码:https://github.com/ultralytics/yolov5
五、注意事项
1.运行结果示例:
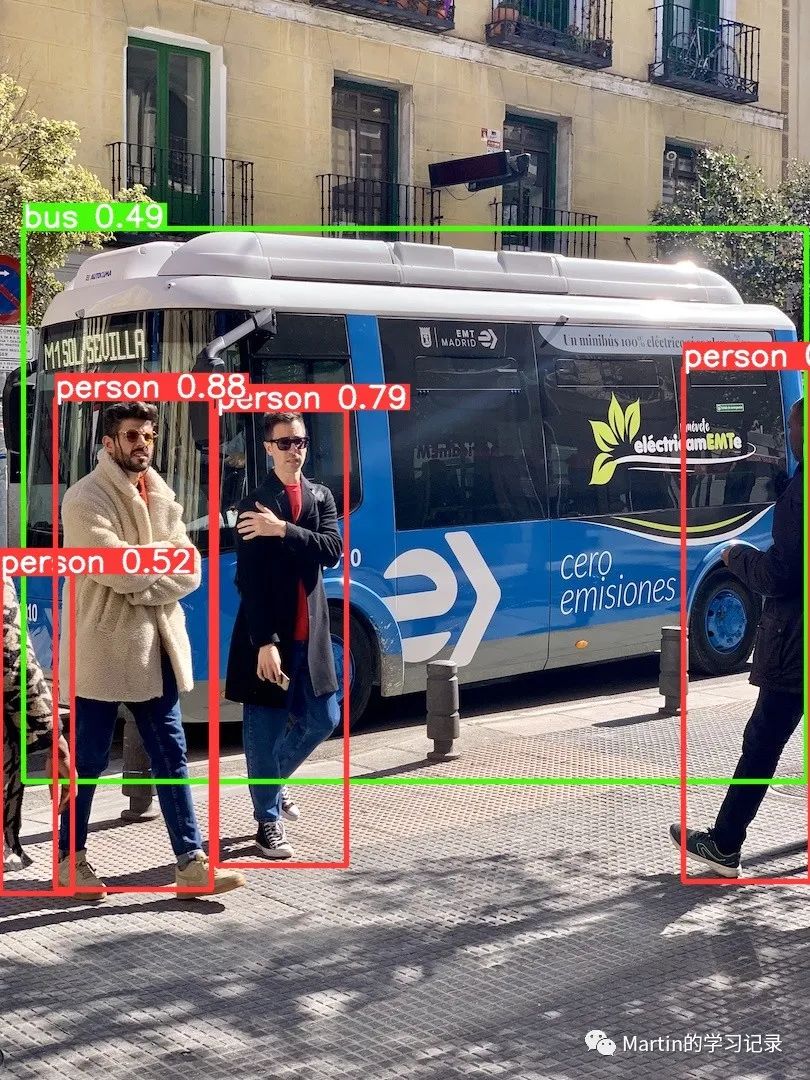
(注意:模型文件的下载需要魔法)
2.所有安装的库和框架需要安装在一个环境中;
3.如果遇到pip安装失败,用魔法和国内镜像源均失败的情况下,需要将anaconda更新到最新版本,建议卸载重新安装
4.安装anaconda后,需要检查一下电脑环境变量是否有:
D:\anaconda
D:\anaconda\Scripts\
D:\anaconda\Library\bin
D:\anaconda\Library\mingw-w64\bin
如果没有需要手动添加(一般情况下是没有)
参考:https://blog.csdn.net/qq_42310545/article/details/132280300
https://blog.csdn.net/ECHOSON/article/details/121939535
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


