随着大模型技术的快速更迭,企业内的落地场景逐渐丰富,智能数据分析则是重点关注和落地的场景之一。本次专家将会从数据分析的痛点与挑战、GenBI的落地路径、真实客户落地案例分享三方面进行展开。
分享嘉宾|于涛 亚马逊云科技解决方案架构师
内容已做精简,如需获取专家完整版视频实录和课件,请扫码领取。

01
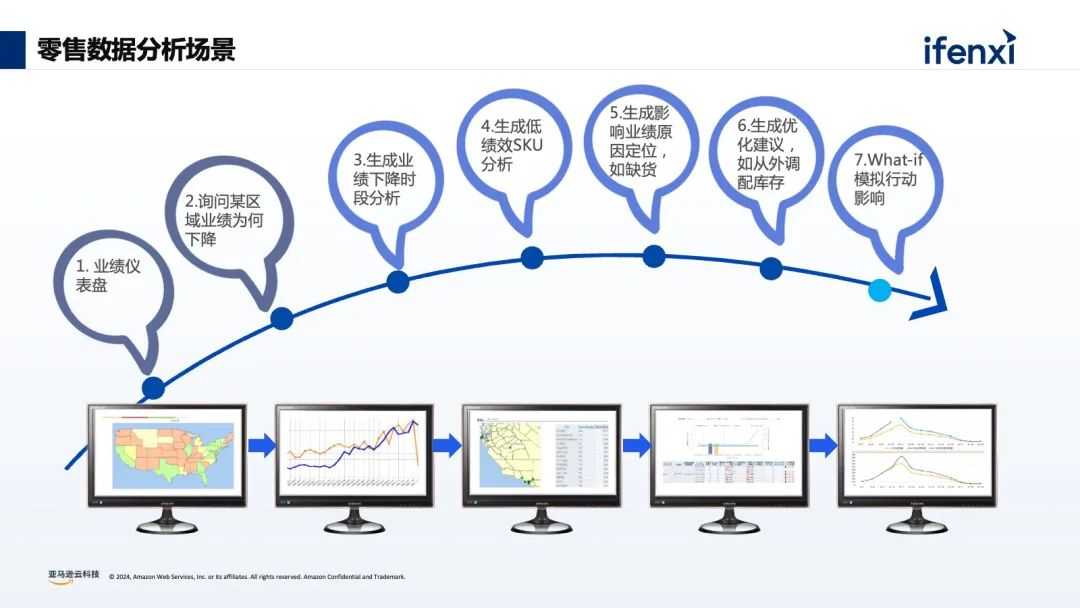
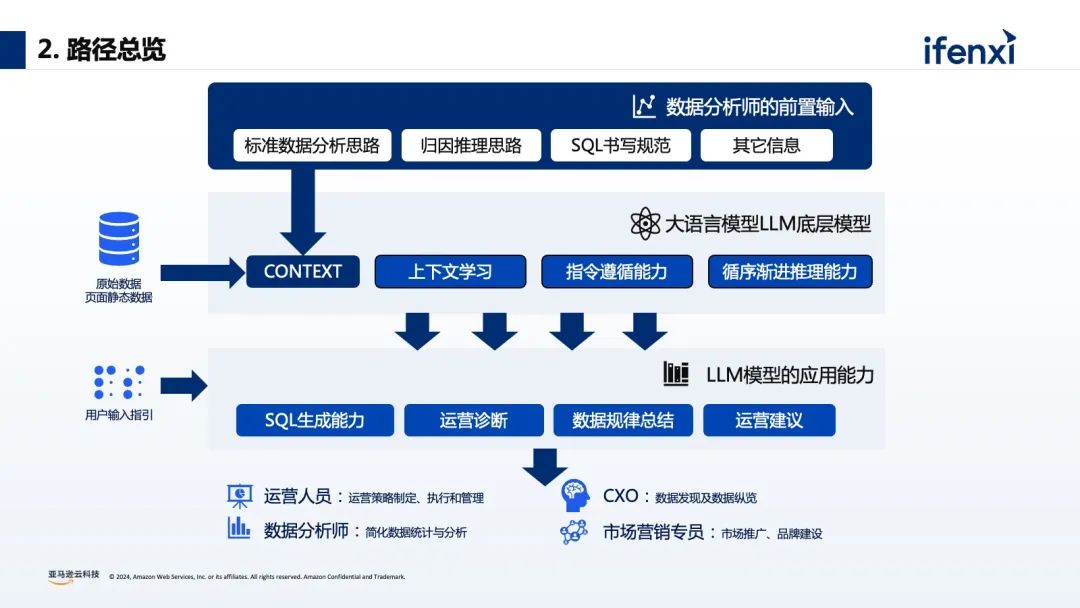
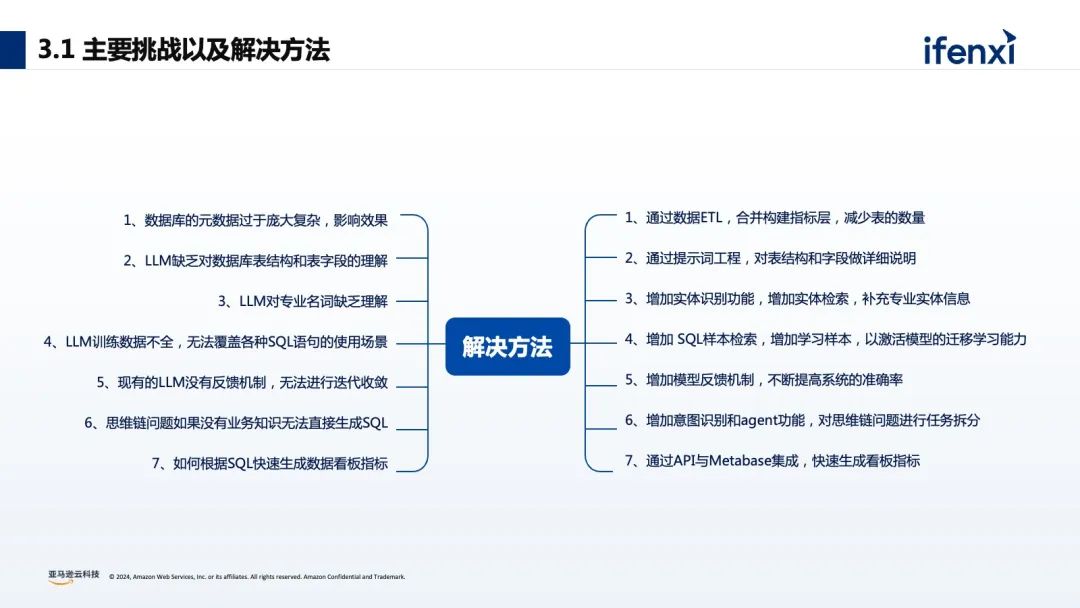
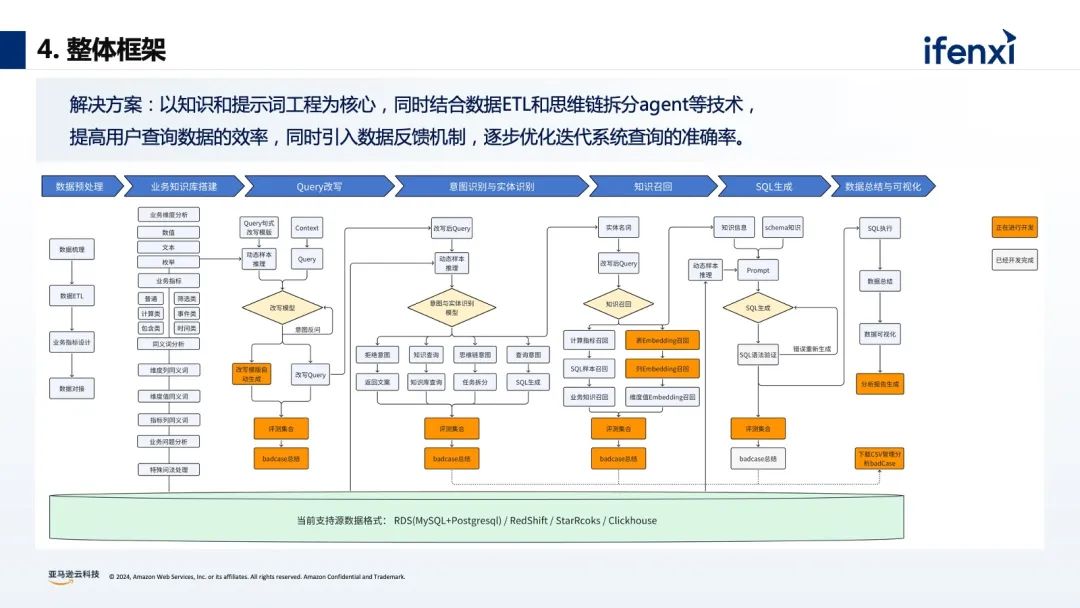
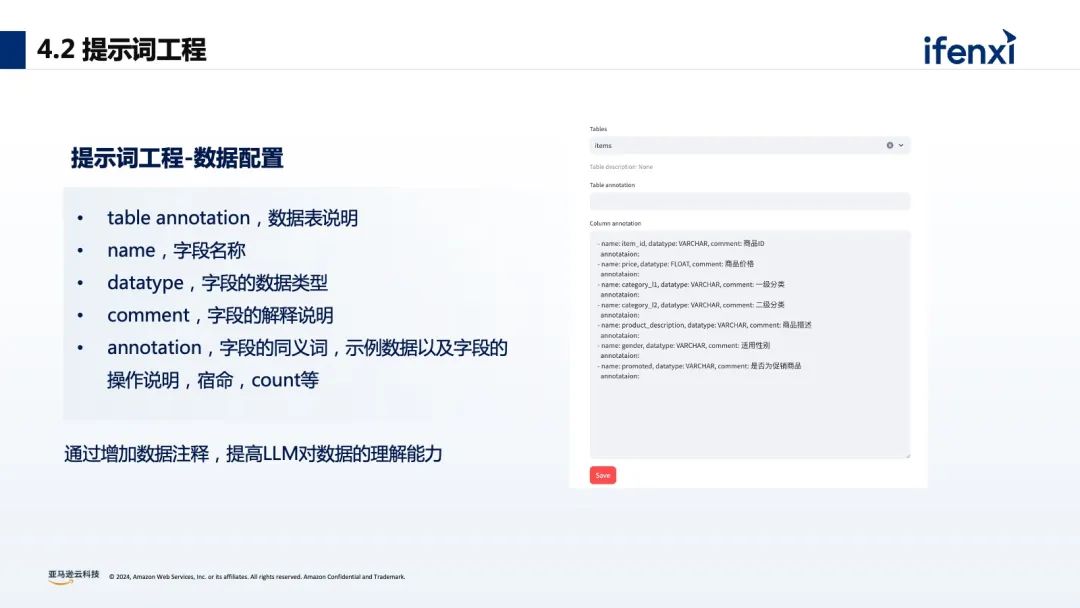
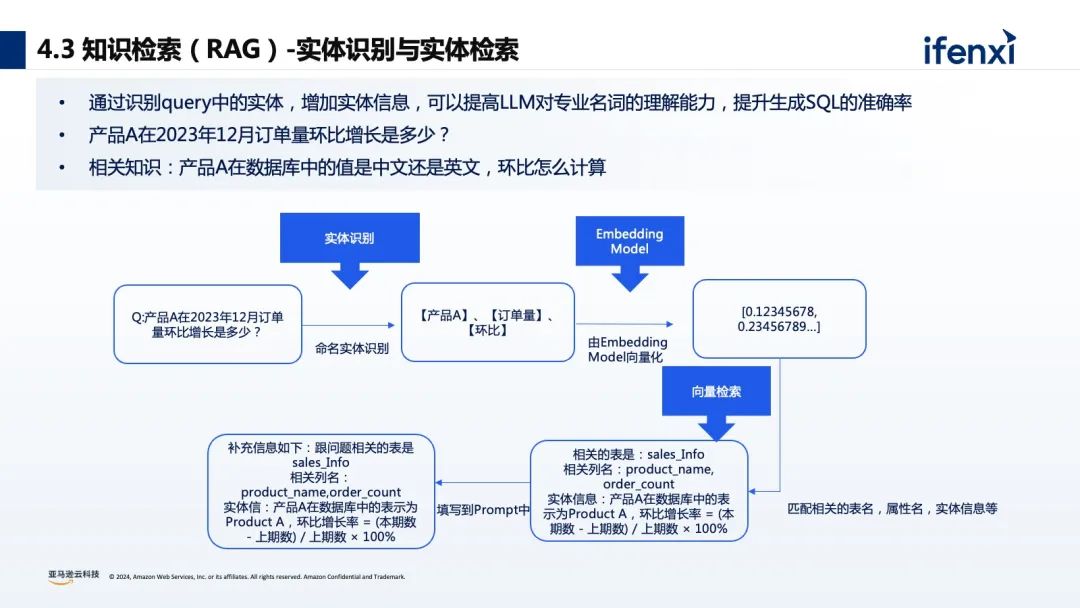
基于零售行业的数据分析场景,有7个典型的分析阶段,首先是业务仪表盘的呈现,基本上是每个企业都会做的智慧大屏或智慧报表,用来体现业务发展概况。接下来就是数据的洞察和挖掘阶段,也是每个企业最难做的部分。例如每个不同区域、不同行业的绩效分析,每个不同的 BU 、业务线下的 SKU 如何进行合理有效的定位及产品未来走向的分析等等。同时在这个基础上还可以增加行业化的建模,包括数据血缘、数据打通等等,利用外部的数据进行整合,或者通过 what-if 模拟情况进行分析和预测。传统的 BI 分析有非常多的问题和挑战,比如 BI 报表和仪表盘,虽然是可视化呈现,但本质反馈的是静态数据,缺少灵活性和归因。而对于数据的应用,则需要 IT 团队和业务团队紧密地配合,比如在进行数据集成的时候,数据运维工程师会通过 ETL 工具进行数据抓取,数据分析师会通过数仓、数据湖的工具进行数据血缘关系的建立,以及建立整个公司的数据网格,业务端也需要基于 SQL 生成后的结果进行最后的归因分析和统计。所以对企业而言,面临着如何快速进行数据清洗和数据分析?如何编写企业周报/日报?如何在尽可能少的人手实现业务洞察和决策?对于员工而言,每个人的专业水平参差不齐,如何在不了解 SQL 的情况下进行数据分析?如何在没有专业能力的前提下进行数据解读?不少企业尝试在数据平台中,加入大模型能力,实现自然语言的问数和数据的编辑处理。没有大模型能力之前,大部分企业会使用 BI 工具进行数据的可视化和数据分析,往往需要通过数据分析师来生成相应的 SQL 语句,实现内容的查找、归因、可视化仪表盘的建立。有了大模型能力后,不再要求数据需求人员会写 SQL ,现在可以利用生成式 AI 能力进行对话式的 BI 分析。比如举三个数据分析常见的例子:“上个月的浏览量有多少?”“同比/环比增长是多少?”“浏览量上升或者下降的原因是什么?”按照传统的 BI 分析方式,这三个问题就需要用到一些复杂的 SQL 才能实现,对于数据分析人员有一定的要求。如何实现对话式的大模型数据分析呢?关于建设路径中,最重要的是准备好原始的数据和原始的信息,这部分和最后的查询结果息息相关。从上图中可以看到,在最上层需要数据分析师进行前置的输入,包括标准数据分析思路、归因推理思路、 SQL 书写规范等等,能更好的衔接每家企业的技术基础和分析要求。再是大语言模型,它的底层的能力随着国内外各种模型的加速迭代,模型的参数逐渐更高和模型回答的结果逐渐更好,大模型的选择和模型的适配必须要考虑因地适宜。最后再通过用户的输入,实现自然语言的方式进行 SQL 的生成、运营诊断、数据规律总结、运营建议。这就是整体的构建结构和路径。从数据分析实践的角度来看,通过自然语言的方式,可以很轻松的实现 SQL 查询语句的生成,但随着企业数据越来越多,企业数据表关联的信息越来越多,很难通过一句简单的自然语句实现较好的查询效果。在实际经验中我们总结发现,利用大模型的推理能力和通用的知识理解,辅以外部的知识体系(RAG)和执行规则来达到比较好的生成效果。对于元数据过于庞大复杂:可以通过数据 ETL 的清洗,把多表拼接成单表来减少表的数量,进一步提升效果。大模型缺少数据库表结构和表字段的理解:可以通过提示词工程,对表结构和字段的含义做详细说明。大模型对专业名词缺乏理解:比如苹果是指 iPhone 还是 Apple ,可以添加实体识别功能,增加实体的检索,来补充对应的知识。关于大模型训练语料不全:可以在大模型中加入 SQL 样本检索,增加学习样本,来激活模型的迁移学习能力。大模型没有反馈机制:可以在使用中加入反馈的机制,通过点赞、点踩的方式来提高系统生成的准确率。针对思维链问题,如果没有业务知识无法直接生成 SQL :可以在大模型中加入意图识别,或者 Agent 功能,实现对思维链问题进行任务拆分,通过设置不同的步骤,帮助大模型进行理解。如何根据 SQL 快速生成数据看板指标:可以通过 API 与 Metabase 集成,生成对应的 SQL 之后,就可以快速生成看板指标。最后再看下整体的框架,分为数据预处理、业务知识库搭建、Query 改写、意图识别与实体识别、知识召回、 SQL 生成、数据总结和可视化 7 个环节。关于数据 ETL 处理层,我们会对数据的表格进行清洗,构建指标层,这能很好的提高 SQL 的生成效率。例如在真实的数仓或数据库中,会有非常多的订单表、订单库和订单信息,如果把对应的表进行 join ,来生成对应的产品数据统计表和产品订单表,就从 5 个表变成了 2 个表,就能减少不同表 join 的情况。对于前期的数据处理和数据准备是非常重要的一环。提示词工程也是非常重要的一个环节。对于大模型来说,它并不知道企业实际的数据是什么,也不知道表的信息是什么,所以需要提前把数据和字段进行定义和配置。通过识别 Query 中的实体,增加实体信息,可以提高大模型对专业名词的理解能力,提升生成 SQL 的准确率。以查询产品 A 在 2023 年 12 月份订单环比增长为例,首先会进行实体的识别,识别到【产品 A】【订单量】【环比】三个信息,此时触发下一个流程- embedding ,再进行一些向量检索就可以找到对应的表信息、列信息、实体信息等,最后拼接成对应对 prompt ,进行 SQL 语句生成,这就是背后的原理。通过增加样本,提高大模型推理能力和大模型对SQL任务生成的理解能力。以上图为例,最右侧匹配到【 0.67688006 0.10631783】对应的信息是“产品 B 今年 1 月北美的环比增长?”,它其实已经有预置的 slack 的条件语句或 SQL 语句,如果其他的运营人员在问相似问题的时候,大模型其实会检索对应的一些样本实现生成,这样也会提高 SQL 生成的准确度。在知识库检索的时候,针对生成的 badcase,可以在前端或在应用里面加入点赞和点踩的反馈机制。通过点赞的方式把 goodcase 的权重拉高,通过点踩的方式把 badcase 记录对应的表里,帮助数据分析师来进行后续的迭代和优化,所以在生成式 BI 的项目里面,并不是一次性的项目,需要按照飞轮的方式进行快速的迭代。关于意图识别,比如用户在提问的时候,大模型需要去识别对应的意图,并区分不同的意图是什么含义。比如拒绝意图,如果用户提出“帮我删除对应表里所有的数据”,这个操作对于整个系统和数据的安全是致命的打击,所以需要对于一些意图进行有效的判断。还有思维链的查询意图,需要调用多个 Agent ,进行任务拆分,比如说“ 5 月份的订单量为什么下降了?”可以拆分到用户维度、城市维度,最后将对应的内容进行综合的思考。03
德比软件主要是针对旅游业做营销系统的技术服务,他们在数据分析场景的痛点有三个。第一是面对业务决策人的数据分析及查询需求,可能在月初或月末时,对于需求的响应不够及时。第二是很难通过报表以外的地方,准确地查询到对应的订单、销售数据等等。第三是每个部门的数据结构不一样,不能很好的理解数据,通过执行 、Chat BI 或 GenBI 的项目也可以很好地进行数据规范和数据结构化的打通,实现跨平台或跨资产或跨产品的数据查询。这是在亚马逊云科技 ECS 容器化服务里面构建的一个应用,对于用户操作端的使用界面。右侧可以选择集成不同的大模型,底部的输入框可以进行提问。在亚马逊云科技与德比软件的合作案例中,实现了打通 AI 和 BI 平台数据隔离,可以更好的利用企业知识,快速地进行经验的赋能,通过自然语言进行对话分析,生成对应的结果,同时有效进行降本增效。🎁特别福利:亚马逊云科技 GenBI 支持开源,扫码获取开源项目文档。
负责亚马逊云科技云计算方案咨询和设计。目前主要专注在现代化应用改造和机器学习领域的技术研究和实践。加入 亚马逊云科技之前曾服务于大型运营商及 IT 解决方案供应商,积累了丰富的跨境电商/快消行业项目经验。
注:点击左下角“阅读原文”,领取专家完整版实录和分享课件。