硬件世界10月11日美国旧金山现场报道:
在Advancing AI 2024大会上,AMD正式发布了新款GPU加速卡“Instinct MI325X”。
它在大获成功的MI300X基础上再进一步,主要是增强了HBM内存部分。


【硬件规格、性能篇】


MI325X配备了多达256GB HBM3E内存,相比于MI300X又增加了64GB,还是八颗,但单颗容量从24GB增至32GB。
同时,带宽从5.3TB/s来到了6TB/s,同样增加了大约13%,Infinity Fabric总线的带宽则还是896GB/s。
性能方面倒是没啥变化,还是FP16 1.3 PFlops(每秒1300万亿次)、FP8 2.6 PFlops。
很自然的,核心规格也是原封不动:5nm XCD模块搭配6nm IOD模块,3.5D封装,1530亿个晶体管,304个计算单元。
不过,AMD透露MI325X的功耗达到了1000W,相比MI320X增加了750W。


MI325X也支持八块并行组成一个平台,这就有多达2TB HBM3E、48TB/s带宽,总的性能高达FP16 10.4 PFlops(每秒1.04亿亿次)、FP8 20.8 PFlops(每秒2.08亿亿次)。
这个规模对比NVIDIA H200 HGX,分别有80%、30%、30%的优势。

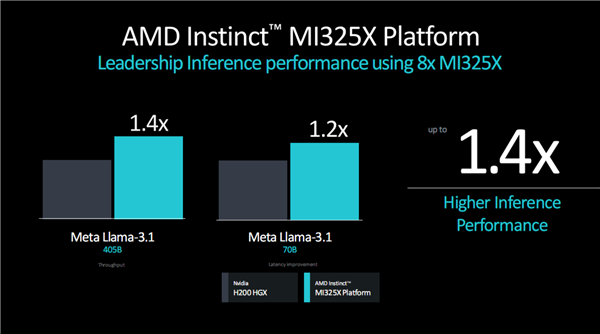

对比NVIDIA H200,无论单卡还是八卡平台,不同大模型推理的性能都可以领先20-40%。
训练性能方面,单卡可领先H200 10%,八卡平台则是持平。

MI325X加速卡和平台将在四季度内投产,而合作伙伴的整机系统、基础架构解决方案,将从明年第一季度起连续推出。
【生态伙伴、软件篇】


GPU加速器这样的产品要想成功,不但要有强大的硬件规格与性能,甚至更重要的还有两点,一是生态合作,二是软件支持。
生态方面,AMD Instinct系列的“朋友圈”不断壮大,领先的OEM整机厂商、云服务厂商、AI方案厂商都选择了AMD,那些我们熟悉的行业巨头名字都在这份越来越长的名单中。
尤其是微软、OpenAI、Meta,都在部署越来越多的Instinct平台。

软件方面,AMD ROCm开发平台是一套完整的AI软件堆栈,硬件之上,运行时、编译器、开发工具、库、AI框架、AI模型与算法一应俱全。
AMD ROCm的进化速度也在加快,新特性新功能不断加入进来,不但已经支持全部重要的AI框架与模型,还在不断优化对生成式AI的支持,包括新的算法、新的库等等,对开发者也越来越友好。
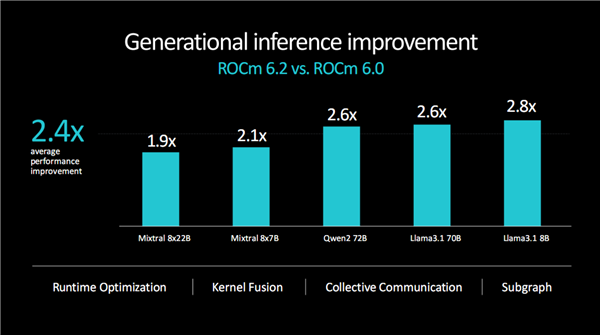
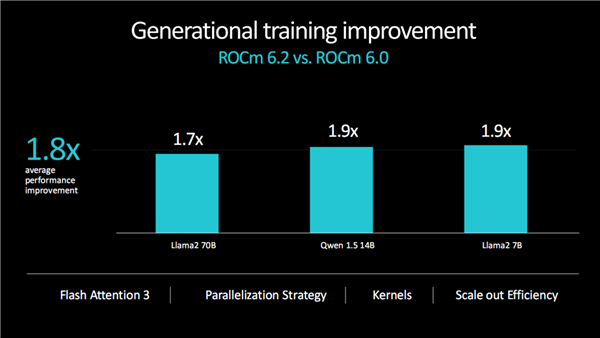
ROCm开发平台的性能也在不断优化提升,最新的6.2版本对比6.0版本,不同大模型的训练性能提升了1.7-1.9倍,平均约1.8倍;推理性能更是提升了1.9-2.8倍,平均约2.4倍。
这些都是无需升级硬件,完全靠软件优化得来的,可以说是“白捡”。

同时,AMD与开发者社区一直保持着良好、深度的合作,也是最大的贡献者之一,尤其是在PyTorch机器学习库、Triton编程语言和编译器上提供了及时、全面的支持。
AMD一直坚持开放开源的原则,不但自己的诸多技术对外公开,还全力支持着开源社区,不断壮大开源的力量。


以MI300X为例,上机无需任何调试适配,就能支持超过100万个生成式AI模型,尤其是第一时间支持Llama 3.1/3.2等领先大模型的最新版本。
良好的支持当然不仅仅是能用,更是好用,比如Llama 3 405B大模型上,MIX300X的延迟相比NVIDIA H100有着1.2倍的领先。

顺带一提,AMD近期还以6.65亿美元的价格,完成了对欧洲最大的私人AI实验室Silo AI的收购,获得了全面的端到端AI解决方案、约300名AI专家,势必会大大增强AMD在欧洲的AI业务实力,分析人士认为有望超越NVIDIA。
附MI325X官方精美图赏——







同时,AMD还宣布了全新的下一代Instinct MI350系列的首款产品“Instinct MI355X”,并披露了部分规格、性能数据。
MI355X将在2025年下半年上市,也就是还有差不多一年时间。
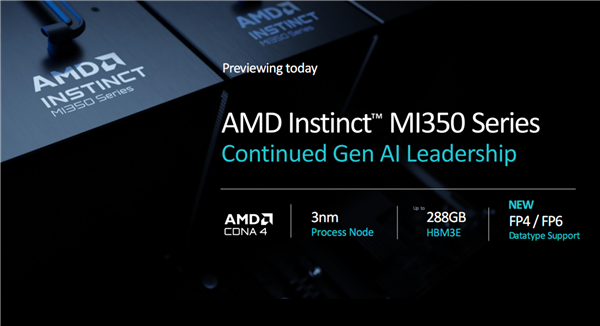
MI350系列将首次升级为台积电3nm工艺,首次采用CDNA 4架构,首次引入FP6、FP4浮点数据类型,搭配内存还是HBM3E但是容量高达288GB。
具体功耗没有披露,但是MI325X已经最高达1000W,AMD也透露MI355X会顺应行业趋势(NVIDIA B200 1000W、GB200 1700W),因此必然会显著超过1000W。
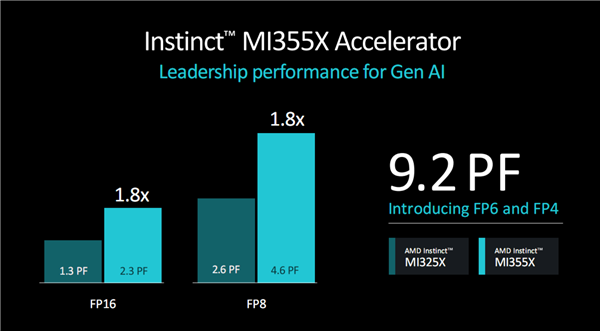
FP6、FP4都属于浮点数据格式,分别代表6位、4位精度,也就是只需6位、4位就能表达一个数字,相比于FP16、F8精度大大降低,但是数据处理量也大大减少,适合大模型的量化,特别是大语言模型和混合专家模型。
如果你不需要太高的精度,更想要速度,FP6、FP4就非常适合。
MI355X上的FP6、FP4浮点性能都是9.2 PFlops(每秒9200万亿次运算),同时还将FP16、FP8性能都提升了80%,分别达到2.3 PFlops、4.6 PFlops。
NVIDIA Blackwell GPU同样引入了FP6、FP4精度,但是性能更高,分别达20 PFlops、40 PFlops。

单卡多达288GB HBM3E内存确实是无可匹敌,同时带宽高达8TB/s。
对比MI325X分别多出1/8、1/3,而相比目前已上市的MI300X都增加了足足50%。
对比竞品,Blackwell B200也只有192GB HBM3E,但带宽同样做到了8TB/s。
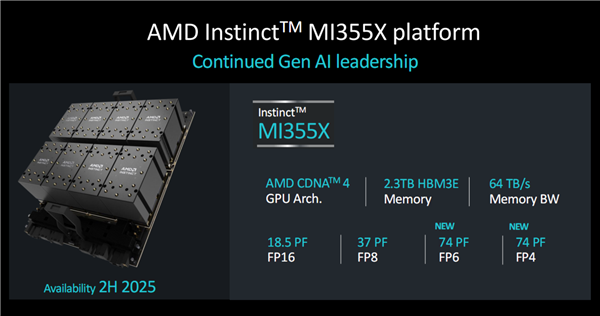
MI355X同样支持单平台八卡,这样就有总计2.3TB HBME内存、64TB/s带宽,性能更是高达FP16 18.5 PFlops、FP8 37 PFlops、FP6/FP4 74 PFlops。
它也将在明年下半年供货。
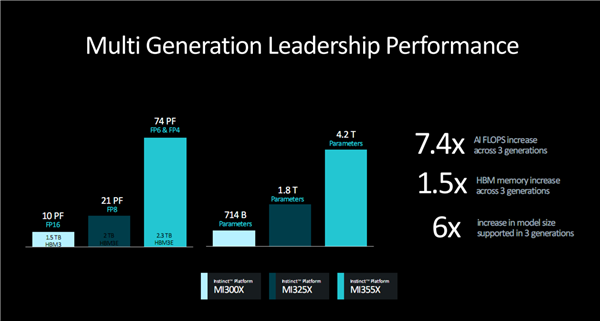
Instinct系列的性能进步幅度无疑是飞跃性的,一代一个新模样,跨代对比更是惊人。
MI355X对比MI300X,FP16性能达到了7.4倍之多,HBM容量也有1.5倍,所能处理的模型参数规模,也从7140亿增加到4.2万亿,足足6倍之多。

展望未来,2026年将推出再下一代的Instinct MI400系列,基于再下一代的CDNA架构(CDNA 5?),规格和性能必将再次迈上一个大大的台阶。
