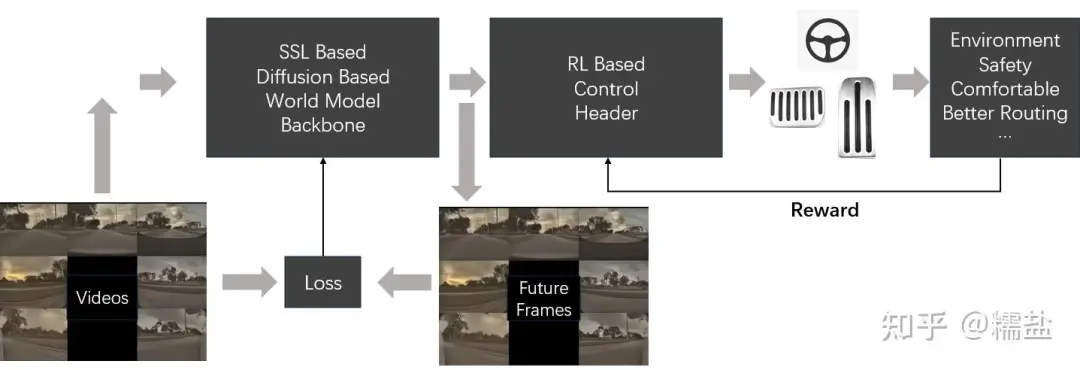
沉寂已久的无人出租车赛道,在2024年突然升温了。前脚百度旗下萝卜快跑,宣布无人驾驶单量突破800万单;后脚特斯拉就于北京时间10月11日上午,召开了以“We,Robot”为主题的发布会,公布了无人驾驶车型Cybercab和Robovan,就连低调了好几个月的滴滴也在悄悄扩编,大手笔加码Robotaxi。不止是滴滴、百度、特斯拉,作为Robotaxi的重磅选手,文远知行与小马智行,也分别在10月份先后启动美股IPO,极氪也在近日宣布,其与Waymo合作开发的无人驾驶出行汽车将大规模量产交付,无人
刘旷
2024-12-19 11:39
140浏览