随着X870E/X870主板的正式解禁上市,AMD宣布了多条重大消息,尤其是锐龙9000系列的延迟问题、架构优化。
AMD表示,部分媒体测试发现,双CCD配置锐龙9000系列的核心间延迟偏高,但他们测试的场景很罕见,对实际性能影响很小,但即便如此,AMD还是做了优化。
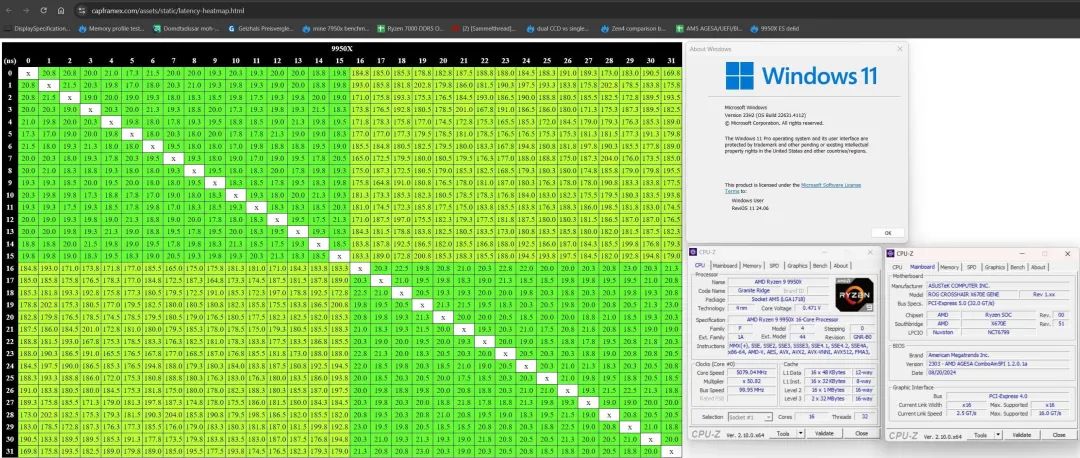
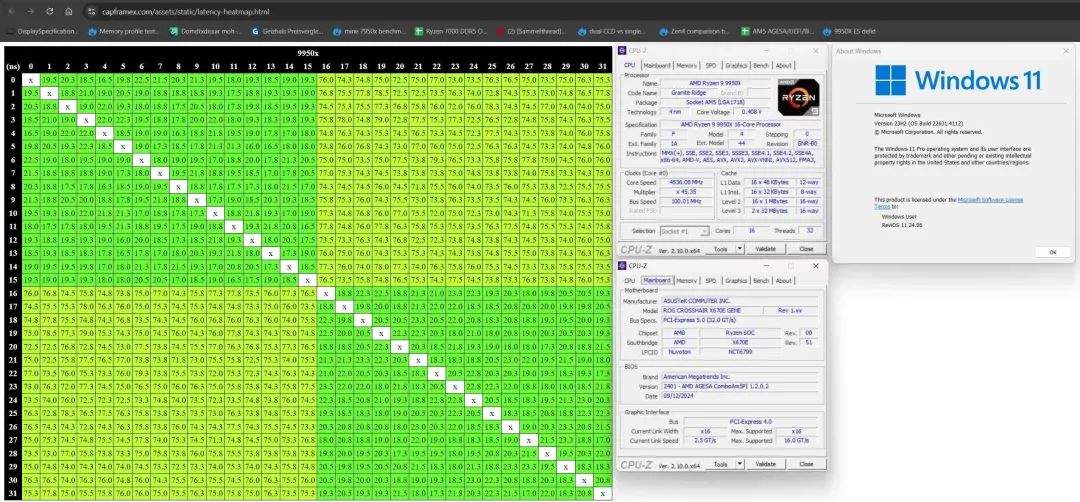
目前,AMD已经正式发布了AGESA PI 1.2.0.2版本的微代码,包括X870E/X870在内的全系AM5主板都可以刷新BIOS,降低核心间延迟。

AMD没有透露核心间延迟的具体改善幅度,而根据此前测试,有的从180纳秒降低到了75纳秒,幅度高达58%,有的从200纳秒降到了95纳秒,幅度也有52.5%。
 1.2.0.1
1.2.0.1
 1.2.0.2
1.2.0.2
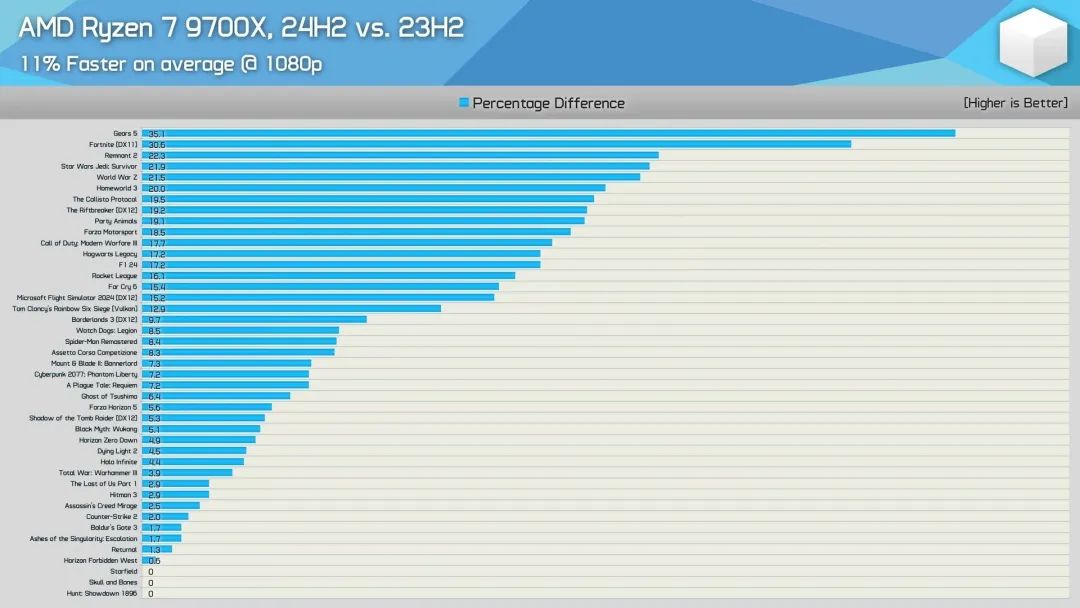
同时,AMD联合微软发布了KB5041587系统补丁,可以优化Zen架构的分支预测,显著提升性能。
该补丁之前只是可选项,现在已经正式加入Windows自动更新,支持Windows 11 23H2 Build 22631.4112及更新版本、24H2 Build 26100.1301及更新版本。

据悉,这一补丁除了优化Zen5,也能给Zen4、Zen3带来一定的改善。
根据实测,锐龙7 9700X游戏性能平均提升约11%,部分游戏相当夸张,比如《战争机器5》提升多达35.1%,《堡垒之夜》提升30.6%,《遗迹2》提升22.3%,《星球大战绝地武士:幸存者》提升21.9%,《世界大战3》提升21.5%,《家园3》提升20.0%。
同时,锐龙7 7700X可平均提升10%,其中《战争机器5》高达32.6%。
至于该补丁是否会下放给Windows 10,暂时不详。
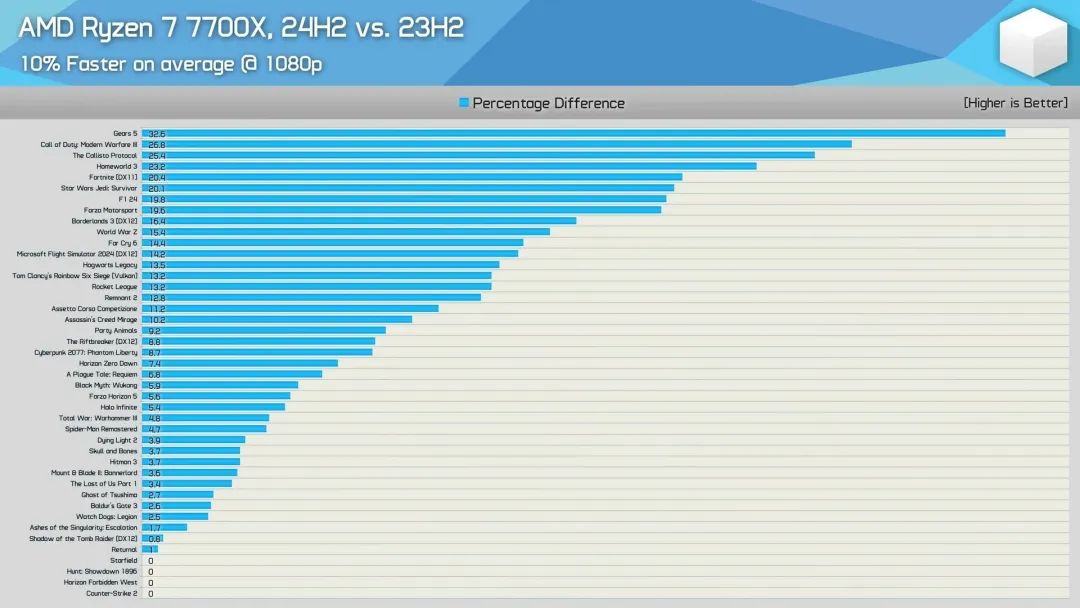
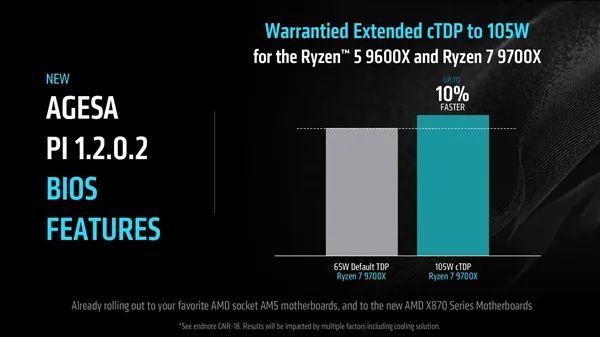
AGESA PI 1.2.0.2版微代码还正式解锁了锐龙5 9600X、锐龙7 9700X的热设计功耗限制,从原本的65W开放到105W,官方预计最多可带来10%的性能提升。
它同样支持所有的AM5主板,包括新的X870E/X870。
AMD确认,X870E/X870主板上只需打开EXPO,就可以一键达成DDR5-8000的超高内存频率,尤其适合X870E。

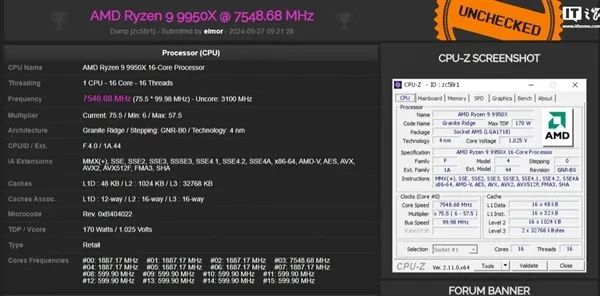
华硕ROG团队宣布,将一颗锐龙9 9950X超频到了惊人的7548.65MHz,并且打破了五项世界纪录。
主板是新发布的ROG CROSSHAIR X870E HERO,液氮自然也是少不了的,温度低至零下189度,最终在16核心全开的情况下达到了这一成就,只是关闭了多线程。
这也是锐龙处理器迄今为止的最高频率,比之前又提高了100MHz——上个记录也是锐龙9 9950X创造的。


如此高频下,GeekBench 3多核得分170646,7-Zip得分321970,CineBench R20多核得分23550,CineBench R23多核得分60798,HWBOT x265 4K得分77.57,都是世界第一。
除了极限超频,X870主板普遍也针对日常操作做了大量支持,尤其是新的AI超频,即便是小白也能轻松释放全部潜力。

接下来,锐龙9000X3D系列即将登场,而担当首发的将是大家最青睐的性阿訇,锐龙7 5800X3D/7800X3D的继承者,锐龙7 9800X3D。

根据MLID的最新曝料,锐龙7 9800X3D在官方资料中被列为2024年的产品,而更高端的锐龙9 9900X/9950X、更主流的锐龙5 9600X3D都不在此列,显然要明年再见了。
锐龙7 9800X3D的缓存总量仍然是104MB,包括6MB二级缓存、32MB原生三级缓存、64MB 3D缓存,这已经三代没变了。
不过,它的频率会显著提升频率,解决前两代最大的不足,同时有望基本解除对超频的限制,那就几乎不存在短板了,游戏、生产力可兼顾。
AMD在宣传材料中多次提及“最佳”(the best)、“精彩游戏终极处理器”(Ultimate Processor for Elite Gaming)等字样,看起来是极为自信啊。
另外,AMD还表示,锐龙9000X3D的最佳显卡搭档是RX 7000系列,完全没提RX 8000系列,显然得明年了。


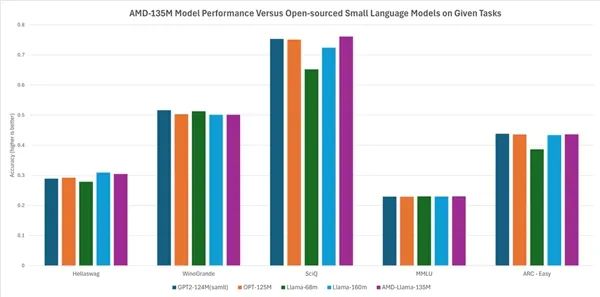
最后,AMD发布了自己的首个小语言模型(SLM),名为“AMD-135M”。
相比于越来越庞大的大语言模型(LLM),它体积小巧,更加灵活,更有针对性,非常适合私密性、专业性很强的企业部署。

AMD-135小模型隶属于Llama家族,有两个版本:
一是基础型“AMD-Llama-135M”,拥有多达6700亿个token,在八块Instinct MIM250 64GB加速器上训练了六天。
二是延伸型“AMD-Llama-135M-code”,额外增加了专门针对编程的200亿个token,同样硬件训练了四天。
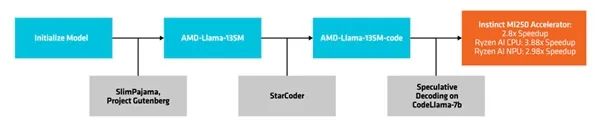
创建与部署流程
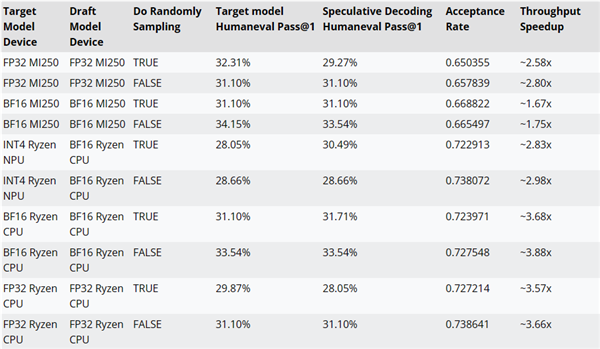
它使用了一种名为“推测解码”(speculative decoding)的方法,通过较小的草稿模型,在单次前向传播中生成多个候选token,然后发送给更大的、更精确的目标模型,进行验证或纠正。
这种方法可以同时生成多个token,不会影响性能,还可以降低内存占用,但因为数据交易更多,功耗也会增加。
AMD还使用AMD-Llama-135M-code作为CodeLlama-7b的草案模型,测试了推测解码使用与否的性能。
比如在MI250加速器上,性能可提升最多约2.8倍,锐龙AI CPU上可提升最多约3.88倍,锐龙AI NPU上可提升最多约2.98倍。

推测解码
AMD-135M小模型的训练代码、数据集等资源都已经开源,遵循Apache 2.0。
按照AMD的说法,它的性能与其他开源小模型基本相当或略有领先,比如Hellaswag、SciQ、ARC-Easy等任务超过Llama-68M、LLama-160M,Hellaswag、WinoGrande、SciQ、MMLU、ARC-Easy等任务则基本类似GTP2-124MN、OPT-125M。