


----追光逐电 光赢未来----
我的博士课题是自监督学习(Self-supervised Learning)方法在计算机视觉表示学习领域的应用。作为一个新名词,自监督学习实际上与监督学习、非监督学习、半监督学习并没有本质上的鸿沟。
Ps: 我个人是不太喜欢科学界命名新技术的风格,给一些旧技术的新衍生冠以高大上的名字会让初学者对于这个领域感到很混乱,而事实上很多名词是交集或者子集的关系。我对于整个机器学习领域的技术分类迷茫了很久看了很多才慢慢理清楚,有机会给大家整理一个Node Map。当然,取名字是Hinton、Bengio这些大佬的事。。。万一哪天人家给RL改名叫Guess Learning/Try Learning >.<
01
样本特征在学习过程中至关重要。在简单的数据挖掘任务中,重要的数据特征是人工设计的。这些功能通常称为Hand-crafted features。在计算机视觉领域,这种类型的表示通常要求我们设计合适的函数以从图像或视频中提取所需的信息。但是,这些功能通常来自人类有关视觉任务中关键信息的经验,这导致手工制作的功能无法表示高级语义信息。例如,在早期工作中提出了各种视觉描述符,例如SIFT算子,HOG算子等等来表示有关对象边缘,纹理等的视觉信息。此外,由于设计函数的复杂度限制,这种类型的表示能力通常相对较低,并且提出新的hand-crafted features并非易事。
总而言之,hand-crafted features在早期视觉任务中取得了一些成功,但是随着问题的复杂性增加,它逐渐无法满足我们的需求。随着卷积神经网络的普及以及数据大小的指数增长,在完全监督的任务中,自动提取的表示形式逐渐取代了效率低下的hand-crafted features。在完全监督模型中,通过反向传播解决了以神经网络和监督损失函数为代表的全局优化问题。大量带注释的图像和视频数据集以及日益复杂的神经网络结构使诸如图像分类和对象检测之类的完全受监督的任务成为可能。之后,经过训练的模型的中间特征图通常包含与特定任务相关的语义有意义的信息,这些信息可以传递给类似的问题。
但是,手动数据注释是监督学习中必不可少的步骤,这是耗时,费力且有噪声的。与有监督的方法不同,无监督的方法不依赖于人类注释,并且通常集中在数据良好表示(例如平滑度,稀疏性和分解)的预设先验上。无监督方法的经典类型是聚类方法,例如高斯混合模型,它将数据集分解为多个高斯分布式子数据集。然而,非监督学习学习由于预设先验的一般性较差而不太值得信赖,在某些数据集(例如非高斯子数据集)上选择将数据拟合为高斯分布可能是完全错误的。
自我监督方法可以看作是一种具有监督形式的特殊形式的非监督学习方法,这里的监督是由自我监督任务而不是预设先验知识诱发的。与完全不受监督的设置相比,自监督学习使用数据集本身的信息来构造伪标签。在表示学习方面,自我监督学习具有取代完全监督学习的巨大潜力。人类学习的本质告诉我们,大型注释数据集可能不是必需的,我们可以自发地从未标记的数据集中学习。更为现实的设置是使用少量带注释的数据进行自学习。这称为Few-shot Learning。
在自监督学习中,如何自动获取伪标签至关重要。根据伪标签的不同类型,我将自我监督的表示学习方法分为4种类型:基于数据生成(恢复)的任务,基于数据变换的任务,基于多模态的任务,基于辅助信息的任务。这里简单介绍第一类任务。事实上,所有的非监督方法都可以视作第一类自监督任务,在我做文献调研的过程中,我越发的感觉到事实上非监督学习和自监督学习根本不存在界限。
所有的非监督学习方法,例如数据降维(PCA:在减少数据维度的同时最大化的保留原有数据的方差),数据拟合分类(GMM: 最大化高斯混合分布的似然), 本质上都是为了得到一个良好的数据表示并希望其能够生成(恢复)原始输入。这也正是目前很多的自监督学习方法赖以使用的监督信息。基本上所有的encoder-decoder模型都是以数据恢复为训练损失。
02
GAN的核心是通过Discriminator去缩小Generator distribution和real distribution之间的距离。GAN的学习过程不需要人为进行数据标注,其监督信号也即是优化目标就是使得上述对抗过程趋向平稳(Goodfellow 想出这个点子真的天才)。

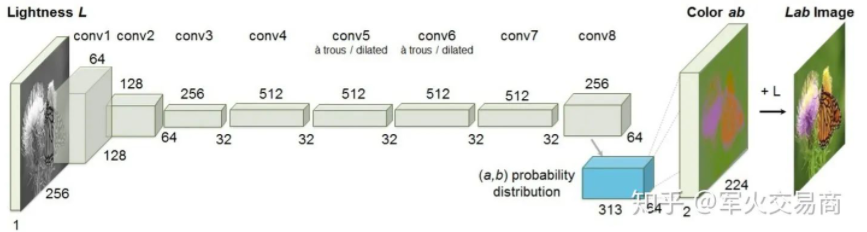
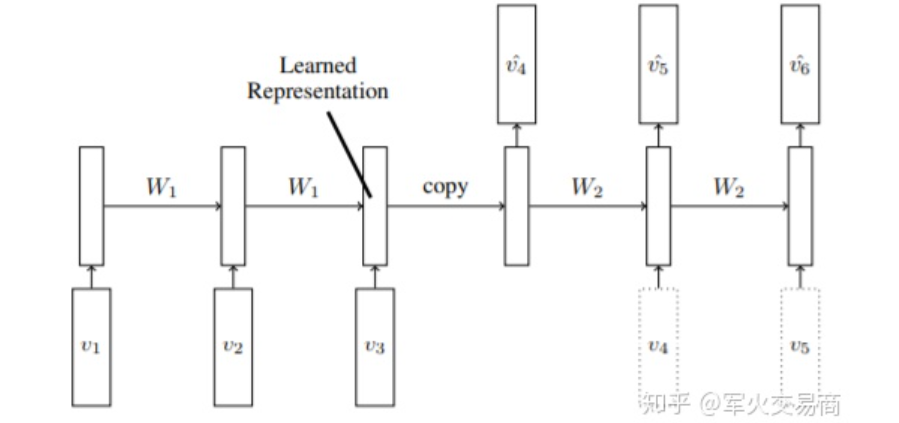
一般来说,视觉问题分成图片和视频两大类,图片数据可以认为具有i.i.d特性,而视频是由多个图片帧构成的,可以认为具有一定的Markov dependency,时序关系是他们之间最大的不同。比如最简单的思路,利用CNN提取单张图片特征可以做图片分类,再加入一个RNN或者LSTM去刻画Markov Dependency,便可以应用到视频上。
References
https://arxiv.org/abs/1603.08511
N. Srivastava, E. Mansimov, and R. Salakhutdinov, “Unsuper- vised Learning of Video Representations using LSTMs,” in ICML, 2015.
03
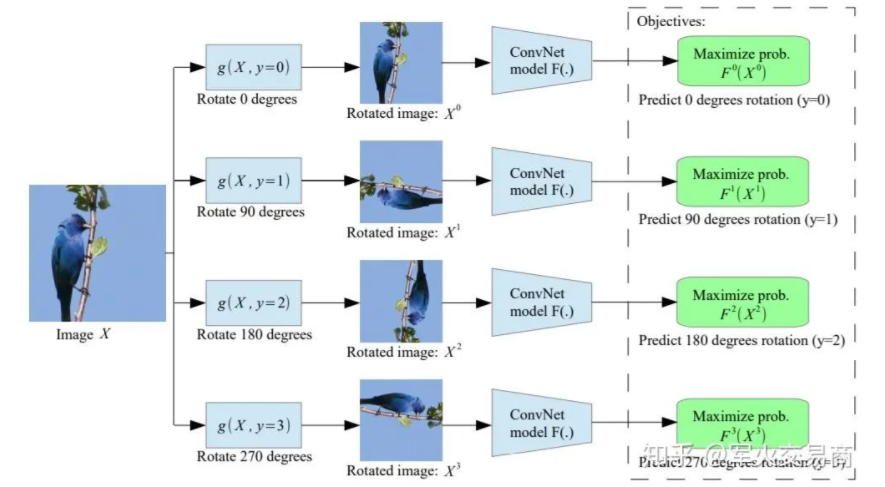
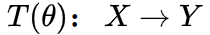 ,则自监督任务的目标是能够对生成的
,则自监督任务的目标是能够对生成的  。
。
参考地址:
https://zhuanlan.zhihu.com/p/125721565
https://zhuanlan.zhihu.com/p/129067097
https://zhuanlan.zhihu.com/p/136108863
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


