早在4月份,Intel就宣布了新一代AI加速器Gaudi 3,现在它终于发布了,详细的规格参数也已出炉,竞争对手直指NVIDIA H100 GPU加速器,当然后者的Blackwell系列也要上量了。
数据显示,预计到2030年,全球半导体市场规模将达1万亿美元,AI是主要推动力,不过在2023年,只有10%的企业能够成功将其AIGC项目产品化。

Intel现有的Gaudi 2诞生于2022年5月,并于2023年7月正式引入中国,拥有极高的深度学习性能、效率,以及极高的性价比。
它采用台积电7nm工艺制造,集成24个可编程的Tenor张量核心(TPC)、48MB SRAM缓存、21个10万兆内部互连以太网接口(ROCEv2 RDMA)、96GB HBM2E高带宽内存(总带宽2.4TB/s)、多媒体引擎等,支持PCIe 4.0 x16,最高功耗800W,可满足大规模语言模型、生成式AI模型的强算力需求。

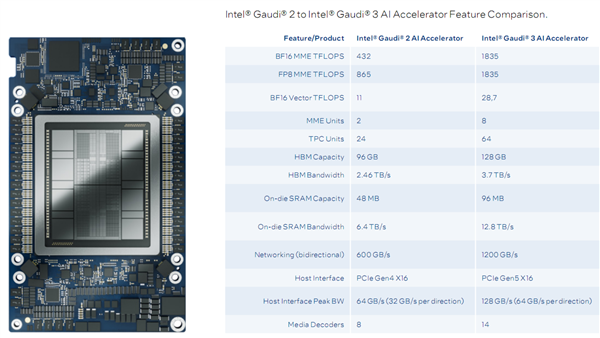
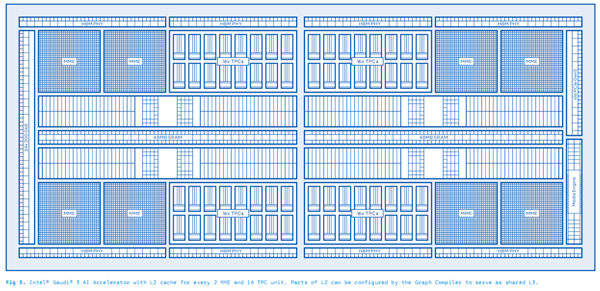
Gaudi 3的规格提升幅度堪称跨越式的,制造工艺从台积电7nm来到台积电5nm,MME(矩阵乘法引擎)从2个增加到8个,虽然每个MME内部的TPC(张量处理核心)从12个减少到8个,但是总数从24个大幅增加到了64个,另外媒体解码器差从8个增至14个。
内置SRAM缓存容量翻番至96MB,带宽翻倍至12.8TB/s。
核心性能方面,MME BF16/FP8都是1835 TFlops(每秒1.835亿亿次),矢量BF16则是28.8 TFlops(每秒28.8万亿次),分别提升了3.2倍、1.1倍、1.6倍。
HBM2E高带宽内存容量从96GB增加到128GB(八颗),带宽也顺应增加来到惊人的3.7TB/s。
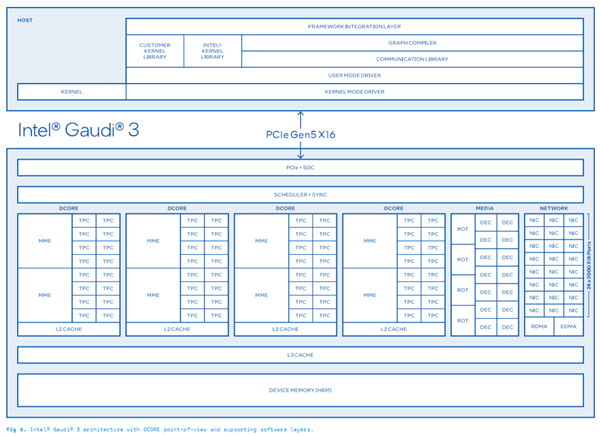
24个200Gb RDMA网络接口,双向网络互连带宽1.2TB/s,主机接口峰值双向带宽128GB/s,系统总线升级为PCIe 5.0 x16。
按照官方说法,Gaudi 3对比NVIDIA H100,LLM大模型推理性能领先50%、训练时间快40%,性价比则是对手的2倍。
开发方面,无缝兼容PyTorch框架、Hugging Face Transformer和扩散模型。
Gaudi 3还可大幅缩短70亿和130亿参数Llama2模型、1750亿参数GPT-3模型的训练时间。
在Llama 70亿/700亿参数、Falcon 1800亿参数大型语言模型上,Gaudi 3的推理吞吐量和能效也都非常出色。
Gaudi 3还提供开放的、基于社区的软件,以及行业标准以太网网络,可以灵活地从单个节点扩展到拥有数千个节点的集群、超级集群和超大集群,支持大规模的推理、微调和训练。

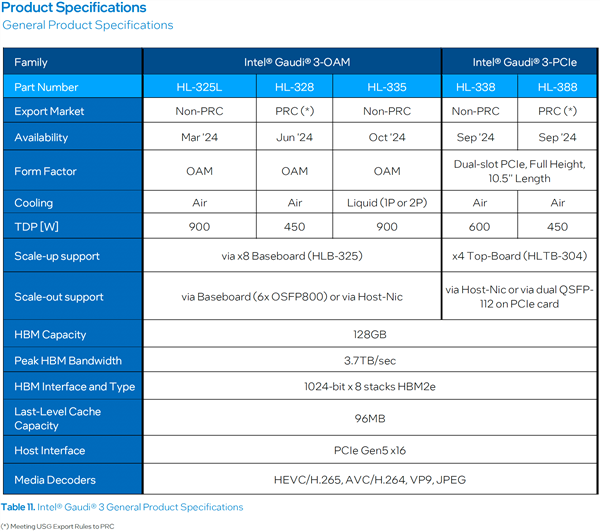
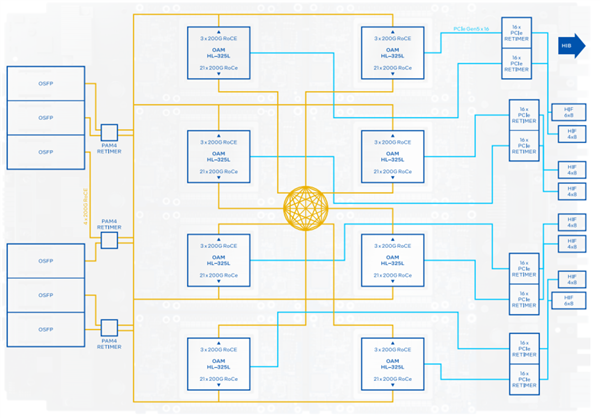
Gaudi 3加速器提供三种部署形态,一是OAM 2.0标准夹层卡,被动散热峰值功耗900W,液冷散热峰值功耗1200W,支持48个112Gb PAM4SerDes网络链接。

二是HLB-325通用基板,支持八颗Gaudi 3,具体功耗未披露。

三是HL-338扩展卡,PCIe 5.0 x16接口,被动散热峰值功耗600W,还可以四卡互连。

目前,Intel Gaudi加速器的行业客户及合作伙伴有NAVER、博世(Bosch)、IBM、Ola/Krutrim、NielsenIQ、Seekr、IFF、CtrlS Group、Bharti Airtel、Landing AI、Roboflow、Infosys,等等。
Intel此前已宣布,IBM将会在其云服务中部署Gaudi 3加速器。
另有消息称,Gaudi 3加速器也有中国特供版,其中OAM模组、PCIe模组的峰值功耗都限制至450W,算力自然也会大打折扣,但暂无更进一步说法。