中国电信宣布,天翼云自研的国内首个单集群万卡国产化全功能预训练云服务平台,已经正式发布上线,基于华为昇腾芯片,并完成了万卡规模Llama3.1-405B大模型训练。
Llama3.1-405B作为4000亿参数规模的大模型,在息壤训推服务平台的支持下,经过多轮优化,MFU(算力利用率)达到国内领先水平。
另外,700亿参数大模型Llama2-70B在万卡规模下完成训练,MFU也处于业界领先水平。

据悉,天翼云的这套平台具备万卡纳管和并行训练能力,基于HPFS PB级并行文件系统、CTCCL RDMA高速卡间互联技术、Gang策略与拓扑感知的智算容器调度,以及慧聚自研分布式训练框架TeleFormers和平台,实现万卡资源纳管、万卡规模并行训练。
其中,天翼云自研了AI框架Teleformers,对算子、通信、数据处理进行优化,还有并行策略的自适应调整,显著提升了大模型训练的训练效率。
在目前业内最大参数规模开源单体稠密模型Llama3.1-405B大模型训练测试中,性能表现达到国际同等水平。
算子优化方面,针对昇腾芯片的特性,在网络结构层面对诸多高频算子进行了定制化改造,构建了高性能算子集。
比如matmul算子,利用昇腾芯片的计算亲和性,将算子输入padding到特定的维度,大幅提升执行效率,从而明显缩短了训练时间。
数据处理和流水线方面,通过设置合理的数据分片策略和HPFS条带化优化,结合数据预取与数据下沉技术,大幅提升数据流的处理效率和稳定性;对预处理后的数据集进行了二次分片并提供就近缓存能力,减少GPU空闲时间。
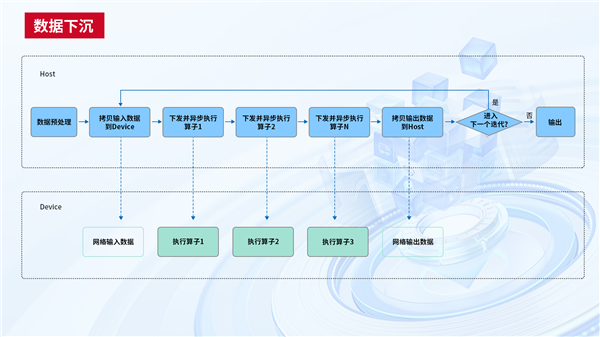
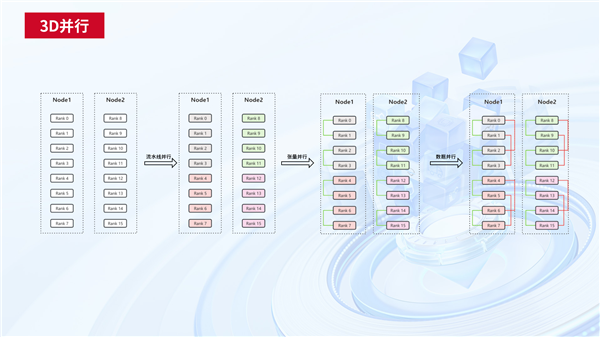
自适应并行策略方面,基于对3D并行中各类计算单元的分析,天翼云设计了多种自适应的3D并行策略,依据模型规模和硬件资源的不同可以自动选择合适的并行策略,充分利用计算资源和显存资源,缩短模型训练中每轮的迭代时间。
说到国产GPU,另一个不得不提的名字就是摩尔线程。它也有好消息传来。
近期在工业和信息化部公布的第六批专精特新“小巨人”企业名单中,摩尔线程凭借在GPU领域的突出表现与创新实力,荣获国家级专精特新“小巨人”企业认定。
专精特新“小巨人”企业,是“专精特新”中小企业中的佼佼者,是专注于细分市场、创新能力强、市场占有率高、掌握关键核心技术、质量效益优的排头兵企业。
摩尔线程此次获得该项殊荣,既是对其强大技术实力、持续创新能力和独特市场竞争力的高度认可,更是对其在推动产业升级和引领行业发展中所发挥重要作用的充分肯定。

自2020年10月成立以来,摩尔线程一直专注于全功能GPU的研发与技术创新,依托先进的MUSA架构,不到4年时间就建立了涵盖芯片、板卡、集群、软件的全栈AI智算产品线。
尤其是夸娥(KUAE)智算集群,作为以全功能GPU为底座、软硬一体化全栈解决方案,具备高兼容性、高稳定性、高扩展性等综合优势,致力于成为大模型训练的先进基础设施。
摩尔线程的目标:成为具备国际竞争力的GPU领军企业!

摩尔线程近期公布的合作进展一览——
与中国建设银行北京市分行战略合作:
基于摩尔线程全功能GPU与夸娥智算集群,共同推动AI技术在金融行业的应用与发展,推动智算集群的测试与评估,加快开发和部署智能服务系统,评估和推进基于GPU的云桌面方案在金融行业的部署。
与苏州德锐特成像技术有限公司达成深度战略合作:
共同研发基于国产全功能GPU的冷冻电镜及计算化学相结合的一站式解决方案,已顺利完成技术适配工作,是德锐特首次在国产GPU平台上完成技术迁移和实际应用,实现了与国际先进GPU相媲美的数据精度,也充分验证了国产GPU在高端生物科技应用中的潜力。
携手索贝共同展示“国产化全域超清解决方案”:
得益于摩尔线程全功能GPU的强大支持,索贝的MetaClip Pro(墨逸)非线性编辑系统及图文包装系统能够在国产环境中流畅稳定地运行,标志着我国超高清制播关键技术设备国产化率的显著提升。




