


深度学习已经彻底改变了人工智能(AI),在计算机视觉、语音识别和自然语言处理等领域取得了显著进展。此外,近年来大型语言模型(LLMs)的成功推动了大规模神经网络研究的热潮。然而,计算资源和能耗需求的不断增加促使人们开始寻找更加节能的替代方案。
受人脑启发,脉冲神经网络(SNNs),即第三代神经网络,通过事件驱动的脉冲提供了节能计算的前景。为了为构建节能的大规模SNN模型提供未来方向,我们对现有深度脉冲神经网络开发方法进行了综述,重点介绍了新兴的脉冲Transformer:
(1)概述了深度脉冲神经网络的学习方法,按人工神经网络(ANN)到SNN的转换以及使用替代梯度的直接训练进行分类;
(2)概述了深度脉冲神经网络的网络架构,按深度卷积神经网络(DCNNs)和Transformer架构进行分类;
(3)对当前最先进的深度SNNs进行了全面比较,重点分析了新兴的脉冲Transformer。
最后,我们进一步讨论并概述了大规模SNN的未来发展方向。
在过去十年中,深度学习取得了显著成就【1】,在计算机视觉【2】、语音识别【3】、自然语言处理(NLP)【4】和围棋【5】【6】等领域展现了可与甚至超越人类表现的成果。最近,大型语言模型(LLMs),即基于Transformer架构【7】的超深神经网络,包含数千亿个参数,吸引了全球的广泛关注。受到ChatGPT【8】(一个具备卓越沟通能力的大型语言模型)成功的推动,人工智能(AI)领域在2022年和2023年见证了关于大规模神经网络研究的迅速扩展。
尽管深度神经网络(DNNs)展示了强大的潜力,但其对内存和计算资源需求的不断增加,给DNNs的发展和应用带来了重大挑战,尤其是在边缘计算等资源受限的环境中。此外,DNNs不断增长的碳足迹也加剧了全球变暖等环境问题。例如,GPT-3在训练过程中据称消耗了1,287 MWh,而OpenAI每天大约消耗564 MWh来运行ChatGPT【9】。相比之下,人类大脑能够以大约20瓦的功率完成一系列复杂任务【10】。为了应对深度学习的瓶颈,研究人员从人类大脑中汲取灵感,提出了脉冲神经网络(SNNs)【11】,它们有望实现高能效计算。
脉冲神经网络(SNNs)。 不同于传统的人工神经网络(ANNs),SNNs由脉冲神经元组成,这些神经元通过离散的脉冲(事件,值为0或1)而不是连续值激活来交换信息。利用事件驱动的计算模型,SNNs中的脉冲神经元只在脉冲到达时异步更新。此外,与依赖大量乘加(MAC)操作的DNNs相比,SNNs使用更节能的累加(AC)操作【10】。随着TrueNorth【12】、Loihi【13】和Darwin【14】等新兴神经形态硬件的出现,SNNs有望解决冯·诺依曼瓶颈,并通过脉冲驱动的高度并行处理实现高能效的机器智能【15】。
发展情况。 由于脉冲的不连续性,SNNs的训练一直具有挑战性,因为强大的梯度下降算法无法直接应用。早期的工作(如SpikeProp【16】、Tempotron【17】、ReSuMe【18】和无监督STDP【19】)中,由于缺乏有效的学习算法,SNNs的能力有限。受深度学习成功的启发,自2015年以来,研究人员开发了基于深度卷积神经网络(DCNNs)的各种学习算法,在复杂任务(如ImageNet分类【20】)中取得了显著进展。最近,受大型语言模型成功的启发,SNNs研究中出现了一个新趋势:构建基于Transformer架构的深度SNNs。由于Transformer模块是大多数LLM框架中的关键和恒定部分,结合脉冲Transformer与神经形态硬件有望在缓解LLM推理的能量瓶颈方面取得重大进展,通过实现大规模SNN模型。
研究范围。 我们的研究集中于深度神经网络,范围限于能够执行复杂任务(如ImageNet分类【20】)的深度脉冲神经网络。为此,我们主要考察了两个备受关注且极为重要的方面:学习规则和网络架构。关于学习规则,我们重点关注两种流行的途径:ANN到SNN的转换和使用替代梯度的直接训练。对于基于局部可塑性规则(如STDP【21】)构建的SNNs(如【22】),请参阅其他综述【23】。关于网络架构,我们集中于两类流行的架构:DCNNs和脉冲Transformer。
相关工作。 脉冲神经网络,尤其是其训练方法,已经成为近期多篇综述的主题【24】【25】【26】【27】【28】。在文献【24】中,Yi等人描述了多种SNN的学习规则。Guo等人则侧重于直接学习方法,综述了提高准确性、提升效率和利用时间动态的方法。Dampfhoffer等人【26】聚焦于深度SNNs,回顾了ANN到SNN的转换和反向传播方法,并对空间、时空和单脉冲方法进行了分类。同样,Eshraghian等人【27】探讨了SNNs如何利用深度学习技术。在文献【28】中,Rathi等人提供了对SNNs的系统回顾,涵盖了算法和硬件。然而,以上综述中都未涉及新兴的脉冲Transformer架构,而这类架构有望实现大规模SNN模型。
论文概述。 首先,第2.1节对构建深度SNNs的学习方法进行了综述。第2.2节对深度SNNs的网络架构(如DCNNs和脉冲Transformer)进行了综述。第2.3节比较了在ImageNet基准上当前最先进的深度SNNs。第3节讨论了构建大规模脉冲神经网络的挑战与未来方向。第4节提供了总结。
ANN到SNN的转换有助于高效利用预训练模型,使其兼容现有框架,并减少训练和推理过程中的资源需求。这种转换方法促进了迁移学习和微调,同时增强了神经网络的生物学合理性。SNNs固有的稀疏性和事件驱动处理方式与硬件实现高度契合,推动了神经形态计算中的可扩展性和能效。
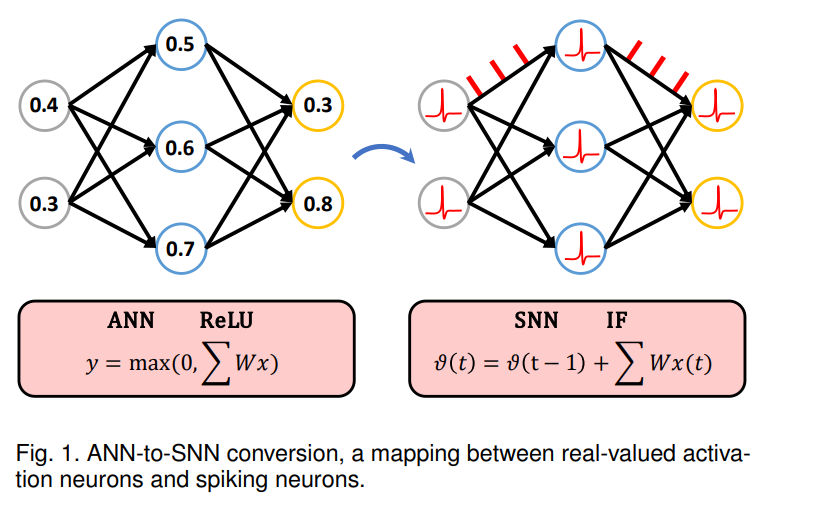
基于ANN激活近似SNN发放率的假设,研究人员提出了多种转换方法,以利用深度神经网络的优势,通过将实值激活神经元映射为离散的脉冲神经元来构建深度SNN(图1)。Cao等人【38】最早提出将带有ReLU激活且无偏置的CNN映射为由积分-发放(IF)神经元组成的SNN。ReLU函数定义为:

其中T表示总的时间步数。
为提高转换SNN的性能,Diehl等人【22】检查了转换过程,报告了脉冲神经元的过度/不足激活,这扭曲了ANN激活和SNN发放率之间的近似。为解决这一问题,他们提出了权重归一化和阈值平衡,这在数学上是等效的。
在文献【39】中,Rueckauer等人对ANN到SNN的转换进行了详细分析。他们发现,由于脉冲神经元的重置操作,信息丢失严重,并提出使用减法重置或软重置来替代原来的归零重置方法。他们进一步指出,由于残余膜电位未被整合到脉冲中的量化问题是导致转换SNN性能下降的主要因素。为解决此问题,他们通过使用激活的第99或99.9百分位数代替最大值来改进权重归一化【22】。此外,他们实现了现代DCNN中的常见操作(如批归一化)的脉冲版本,促使了更深层CNN的转换。
继【22】和【39】之后,出现了几种新颖的归一化方法以减轻转换后的性能退化问题。在【40】中,Sengupta等人提出了一种动态阈值平衡策略,可以在运行时对SNN进行归一化。基于【40】的工作,Han等人【41】提出根据IF神经元的fan-in和fan-out缩放阈值。Kim等人【42】引入了通道级权重归一化,以消除极小的激活值,并实现了Spiking-YOLO,用于目标检测,它引入了负脉冲以表示负激活值。
为提高转换SNN的性能,一些有趣的工作在转换后使用了微调方法。在【29】中,Yan等人提出了一个框架,通过引入SNN中时间量化的知识来调整预训练的ANNs。他们在ANN中引入了一个残差项来模拟SNN中的残余膜电位,从而减少量化误差。在【31】中,Wu等人提出了一种名为渐进双学习的混合框架,以通过时间量化知识微调全精度浮点ANNs。
为了缓解转换误差导致的性能下降和推理延迟增加,多个研究进一步分析了转换过程,并开发了促进ANN到SNN转换的方法。在【30】中,Hu等人提出通过基于统计估计误差增加深层神经元的发放率来抵消累积误差。在【32】中,Deng等人建议使用截顶ReLU函数(如ReLU1和ReLU2)训练ANNs,并通过最大激活值对发放阈值进行归一化。在【33】中,Li等人引入了逐层校准来优化SNN的权重,逐层修正转换误差。与优化突触权重不同,Bu等人【34】提出通过优化初始膜电位来减少转换误差。在【35】中,Bu等人引入了一种量化截顶-地板-移位激活函数来替代ReLU,实现了超低延迟(4个时间步)的转换SNN。通过分析ANN量化与SNN脉冲发放的等效性,Hu等人【36】提出了一个映射框架,促进从量化ANN到SNN的转换。他们还展示了一个带符号的IF神经元模型,并提出了逐层微调方案以解决低延迟SNN中的顺序误差问题。在【37】中,Li等人提出了一组逐层参数校准算法,以应对激活不匹配问题。
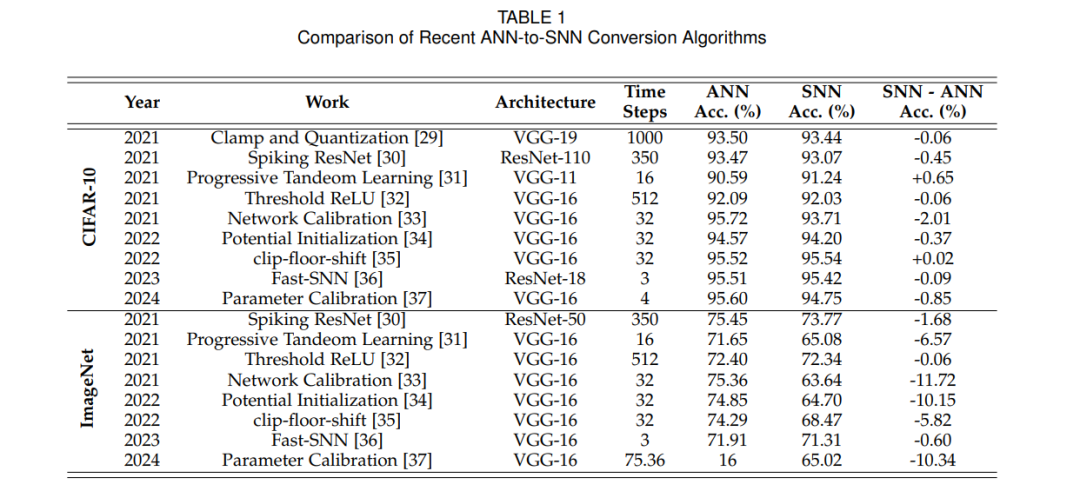
在表1中,我们总结了ANN到SNN转换方法在CIFAR-10和ImageNet数据集上的最新成果。
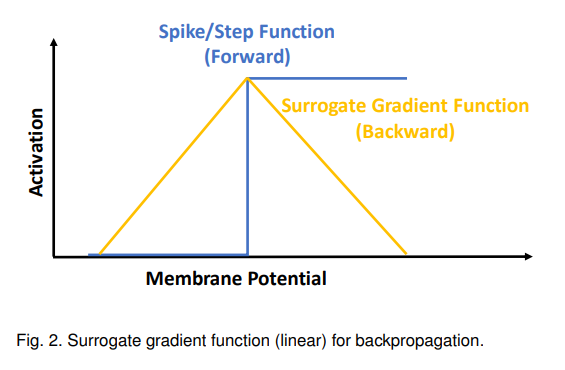
使用替代梯度直接训练脉冲神经网络(SNNs)可以通过提供平滑近似来使用标准优化算法,如随机梯度下降(SGD)或Adam。这简化了SNNs的端到端学习过程,使训练更加便捷。
为解决不连续的脉冲函数,研究人员使用替代梯度(可微函数的导数)来近似脉冲非线性的导数。对于深度脉冲神经网络,一种常用方法是将SNN视为具有二进制输出的循环神经网络(RNN),并使用时间反向传播(BPTT)来训练SNN【27】【62】。类似于RNN中链式法则的迭代应用,BPTT展开SNN并将梯度从损失函数传播到所有后代。例如,突触权重可以通过以下规则更新:

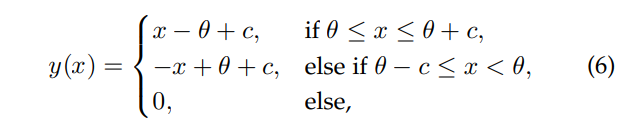
2.2 大规模脉冲神经网络的网络架构
在过去十年中,深度卷积神经网络(DCNNs)【2】在各种应用中取得了显著的成功。基于这些进展,深度脉冲神经网络(SNNs)的开发也借鉴了DCNNs中的经验。最近,基于Transformer架构的人工神经网络(ANNs)【7】在性能上设立了新标杆。基于Transformer骨干的大型语言模型展示了强大的能力,引发了神经形态计算领域的广泛兴趣。因此,结合Transformer架构的SNNs成为了研究热点。本节中,我们将深度脉冲神经网络的网络架构分为两类:DCNN架构和Transformer架构。
在早期的研究中,Cao等人【38】展示了带有ReLU激活函数的卷积神经网络(CNNs)可以映射为由积分-发放(IF)神经元组成的脉冲神经网络(SNNs)。在这个框架中,人工神经网络(ANNs)中的卷积和池化操作可以解释为SNNs中的不同突触连接模式。因此,SNNs可以看作是具有脉冲神经元作为激活函数的CNN,这为构建具有DCNN架构的深度SNN铺平了道路。Esser等人【69】进一步展示了批归一化(BN)可以集成到推理过程中的发放函数中。这一发展促进了使用DCNN架构构建深度SNNs的可能,因为批归一化是高效训练DCNNs的常用技术。因此,像AlexNet【2】、VGG【70】和ResNet【71】这样的流行ANN架构已经广泛应用于SNNs中。
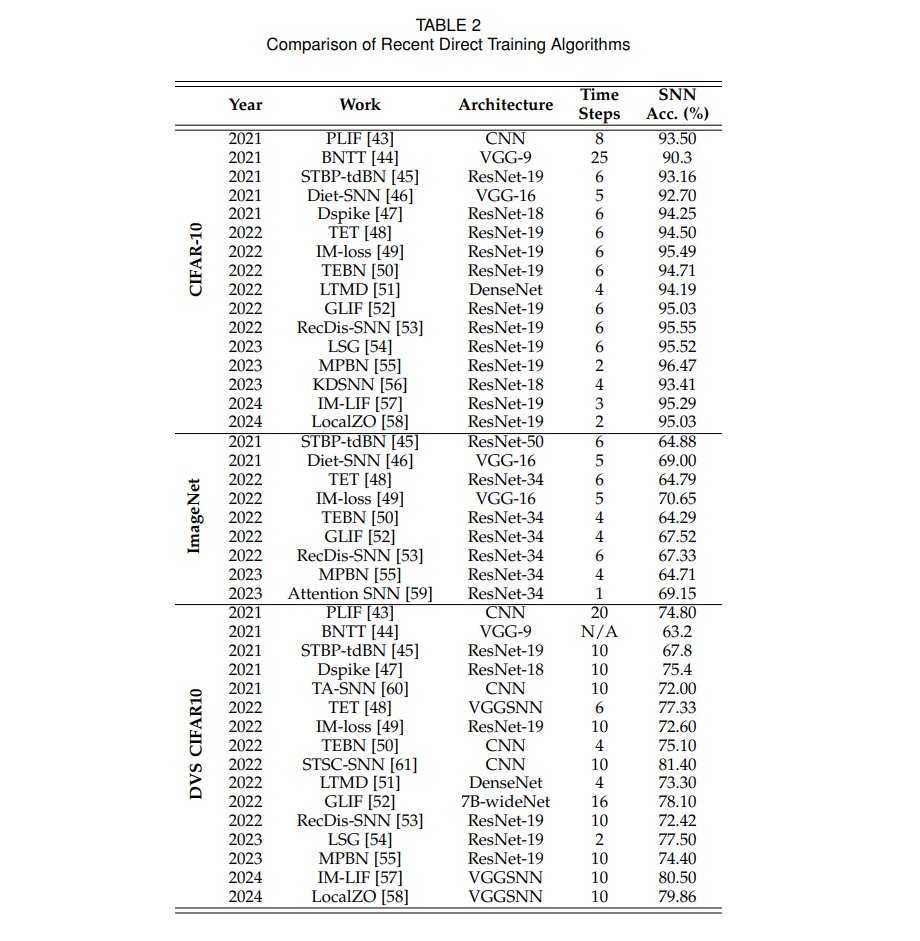
在深度SNN架构的探索中,ResNet架构【71】因其有效缓解梯度爆炸/消失问题而受到关注。在【30】中,Hu等人展示了一种用于转换残差结构的ANN到SNN转换方法,并报告了与同等深度的普通网络相比,ResNet在转换过程中产生的误差较小。在【67】中,Fang等人提出了脉冲元素级ResNet(SEW-ResNet),该架构通过激活-加和方式取代了标准的残差结构,允许脉冲神经元发放正整数脉冲。虽然这一修改增强了脉冲的表示能力,但也削弱了事件驱动计算的优势。在【68】中,Hu等人引入了膜快捷ResNet(MS-ResNet),结合了ANNs中的预激活结构。此方法采用了一条快捷路径,将脉冲神经元的全精度膜电位直接传播到所有后续的残差块。然而,这种ANNs和SNNs的混合结构也减少了事件驱动计算的优势。图3展示了这三种不同的快捷方式实现。
与上述手动设计的架构相比,一些研究提出使用**神经架构搜索(NAS)**来自动发现SNN的最佳架构。Kim等人【72】提出了SNASNet,能够同时搜索前向和后向连接。Na等人【73】开发了AutoSNN,一个脉冲感知的NAS框架,旨在有效探索已定义的节能搜索空间中的SNNs。Yan等人【74】提出将候选架构编码到无分支的脉冲超级网络中,以应对长时间的搜索问题,并通过突触操作(SynOps)感知优化来减少计算需求。
受Transformer网络优异性能的启发,研究人员提出将Transformer架构引入脉冲神经网络(SNNs),以缩小最先进的人工神经网络(ANNs)与SNNs之间的性能差距。随着大型语言模型(LLMs)的成功,基于Transformer架构的深度SNNs研究已经成为神经形态计算领域的焦点。
1)基础自注意力机制:早期的研究通常结合基于ANN的自注意力模块和脉冲组件构建混合结构。例如,Mueller等人【75】提出了一种使用Rueckauer等人【39】转换方法的脉冲Transformer。Zhang等人【76】提出了用于基于事件的单目标跟踪的脉冲Transformer,使用SNN进行特征提取,同时保留实值Transformer。同样,Zhang等人【77】开发了一种模型,将Transformer集成到连续脉冲流(由脉冲摄像机生成的)中以估计单目深度。然而,这些使用基础自注意力机制的方法在充分利用SNNs的事件驱动特性以及减少资源消耗方面面临挑战。
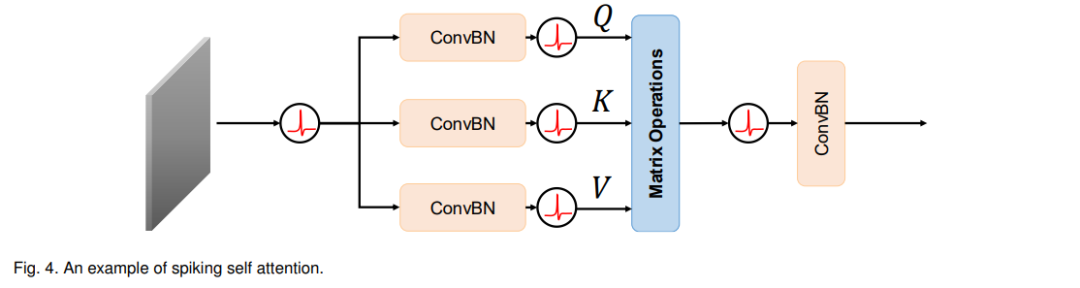
2)脉冲自注意力机制:Zhou等人【78】取得了突破,首次引入脉冲自注意力机制,并提出了一个框架,即Spikformer,用于构建具有Transformer架构的深度SNN。与基础自注意力【7】不同,脉冲自注意力(图4)摒弃了复杂的softmax操作,后者难以用脉冲操作替代,而是对Query(Q)、Key(K)和Value(V)的脉冲形式执行矩阵点积。在ImageNet上,Spikformer使用Spikformer8-768架构和4个时间步达到了74.81%的准确率。然而,ANNs和SNNs之间仍然存在性能差距(Transformer-8-512的准确率为80.80%,而Spikformer-8-512的准确率为73.38%)。
继【78】之后,一些研究进一步探索了脉冲Transformer中自注意力机制的实现。在【80】中,Yao等人引入了脉冲驱动Transformer和脉冲驱动自注意力(SDSA),该方法仅利用掩码和加法操作来实现自注意力机制。Shi等人【105】提出了双脉冲自注意力机制(DSSA),它能够高效处理多尺度特征图并兼容SNN。在【104】中,Zhou等人开发了Q-K注意力机制,仅采用了两种脉冲形式的组件:Query(Q)和Key(K)。
为增强脉冲Transformer的时空注意力机制,一些研究提出了时空自注意力机制。Xu等人【95】提出了具有内在可塑性和时空注意力的去噪脉冲Transformer(DISTA),它结合了神经元级和网络级的时空注意力机制。他们还引入了一个非线性去噪层,以减轻计算出的时空注意力图中的噪声信号。Wang等人【88】开发了时空自注意力(STSA),使脉冲Transformer能够从时间和空间域中捕获特征。他们将时空相对位置偏差(STRPB)集成到他们的时空脉冲Transformer(STS-Transformer)中,以注入脉冲的时空位置信息。
为了利用频率表示,Fang等人【114】提出了脉冲小波Transformer(SWformer)。该模型结合了负脉冲和一个频率感知的token混合器(FATM),旨在有效提取空间和频率特征。
3)提升性能:为了提高网络性能,一些研究集中于优化网络结构。Zhou等人【93】提出了Spikingformer,它修改了脉冲元素级(SEW)快捷方式【43】,改用膜快捷方式,避免了整数脉冲。Zhou等人【94】引入了ConvBN-MaxPooling-LIF(CML),以增强深度SNN中的下采样模块,与ConvBN-LIF-MaxPooling相比,促进了梯度反向传播。为了进一步改进Spikformer【78】,Zhou等人【97】开发了Spikformer V2,结合了脉冲卷积干(SCS)。类似地,Li等人【100】提出了用于patch嵌入的卷积Tokenizer(CT)模块。在【98】中,Yao等人引入了Spike-driven Transformer V2,并结合了一种元架构来提高性能和多功能性。Zhang等人【111】提出了脉冲全局-局部融合Transformer(SGLFormer),设计用于高效处理全球和局部尺度的信息,并引入了一个新的最大池化模块和分类头。
4)降低复杂性:为减少复杂性,Wang等人【91】提出了AutoST,这是一种无训练的神经架构搜索方法,旨在识别最优的脉冲Transformer架构。通过强调浮点运算量(FLOPs),该方法提供了对模型效率和计算复杂性的标准化和客观评估。Wang等人【82】旨在通过用未参数化的线性变换(LTs)替代脉冲自注意力,减少Spikformer【78】的时间复杂度,例如傅里叶和小波变换。
为了避免从头训练的高成本,一些研究采用ANN到SNN的转换方法来构建脉冲Transformer。Wang等人【92】提出基于ANN到SNN转换构建脉冲Transformer,并结合量化剪切-移位【35】。为了应对Transformer中的非线性机制(如自注意力和测试时归一化),Jiang等人【107】提出了时空近似(STA),通过引入新的脉冲操作符和层来近似ANN中的浮点值。
.jpg")
