今日,2024 云栖大会在杭州云栖小镇正式举行,NVIDIA 多位技术专家将在为期三天的主论坛、专场和并行话题演讲,分享加速计算技术和产业实践。
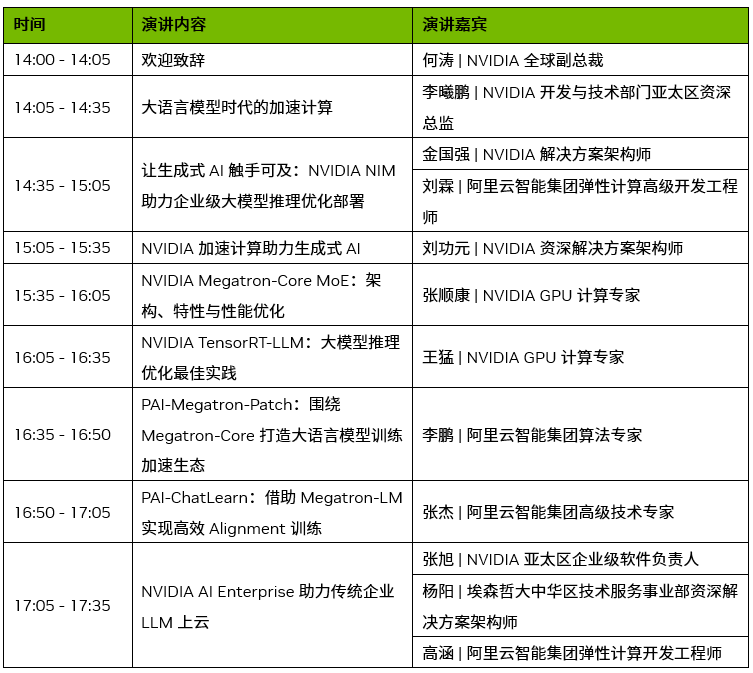
NVIDIA 专场“大语言模型时代的加速计算”
9 月 20 日 14:00 - 17:45,A 馆 A1-1
在NVIDIA 专场,NVIDIA 和阿里云、埃森哲的技术专家将分享大语言模型落地的关键要素,并分享全栈加速计算的技术经验。
上下滑动查看演讲详情
NVIDIA 展区汇聚前沿加速计算技术和实践
2 号馆 2-12
左右滑动,查看更多展位图片
精彩技术演示
学习资源分享
客户用例展示
来 NVIDIA Inception Pavilion 展区
一览前沿 AI 应用
3 号馆 3-11K
参展企业:
6Estates
FathomX Pte.Ltd.
MetaLearner
8glabs Inc.
WeShop
深圳幻影未来信息科技有限公司
万生华态科技有限公司
北京睿甄创新科技有限公司
酷牛创新技术(深圳)有限公司
埃罗科技(上海)有限公司
精彩进行时