 芝能智芯出品
芝能智芯出品当前的人工智能领域,处理器设计正逐渐从追求绝对性能转变为寻求速度与效率之间的最佳平衡。
这一趋势在最近的Hot Chips 2024会议上得到了充分体现,多个领先的芯片制造商展示了新颖的微架构设计和改进的芯片封装技术,以应对当今复杂的计算需求和能源效率挑战。
随着大型语言模型(LLM)的迅猛发展以及异构计算架构的崛起,AI处理器正步入一个全新的时代——一个不再依赖单一计算元素,而是多种计算单元协同工作的时代。
异构架构与芯片封装的演进
异构计算架构的兴起,特别是在2.5D和3.5D封装技术上的应用,标志着AI处理器设计进入了一个新阶段。异构计算是指在一个系统中使用多种类型的处理器,各自专门处理不同类型的任务,这种架构可以显著提升系统的整体性能和能效。
在Hot Chips 24会议上,多家公司展示了利用先进封装技术和多种计算单元的处理器设计。
通过集成GPU、CPU、DPU(数据处理单元)等多种计算单元,这些芯片能够更好地应对各种AI应用场景,尤其在数据密集型任务上表现尤为突出。
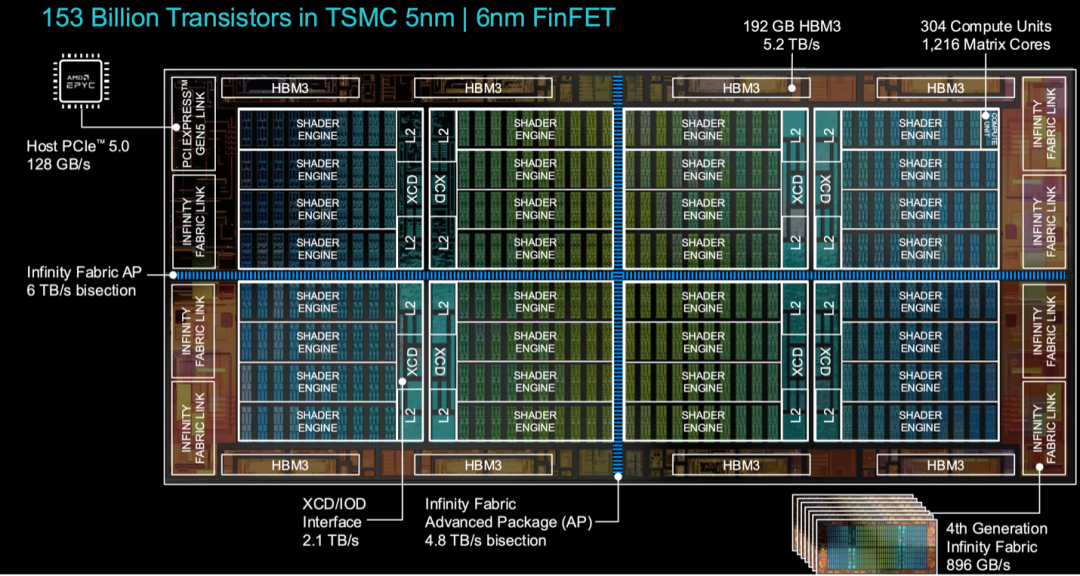
例如,NVIDIA在会议上发布的Blackwell芯片将GPU与CPU和DPU结合,并配备了一套优化的量化方案。该芯片不仅能处理更大规模的数据模型,还能高效地进行低精度AI计算。
这样的设计可以减少训练和推理过程中的能耗,从而达到更好的每瓦性能(performance per watt)。NVIDIA GPU架构总监Raymond Wong强调,AI和加速计算是一个全栈问题,必须从硬件到软件,从芯片到系统进行全面优化。
数据中心的变化:
从计算性能到数据管理
随着AI应用的普及,数据中心的角色正在发生变化。过去,数据中心往往专注于构建强大的计算单元以加快数据处理速度,但随着数据量和数据类型的不断增加,单纯增加计算单元已经无法满足需求。
如今,智能数据管理成为关键,能够根据任务的紧急程度对数据进行优先级排序并优化存储和传输路径。
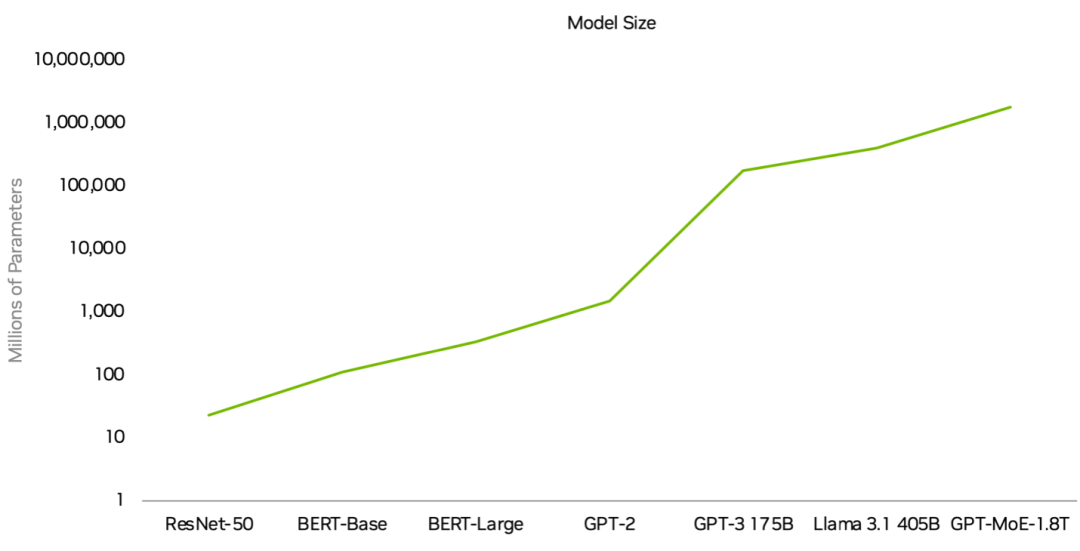
● IBM在这一领域的最新进展值得关注,最新的Telum处理器引入了创新的缓存架构和用于I/O加速的DPU。这些改进能够大幅减少数据移动过程中产生的延迟,并提高数据处理效率。
DPU可以被视为一个智能的数据交通警察,能够有效地管理数据在系统内的流动,从而降低I/O管理的功耗,这种设计能够将I/O管理功耗降低多达70%,在大规模数据处理场景中显著提升能效。
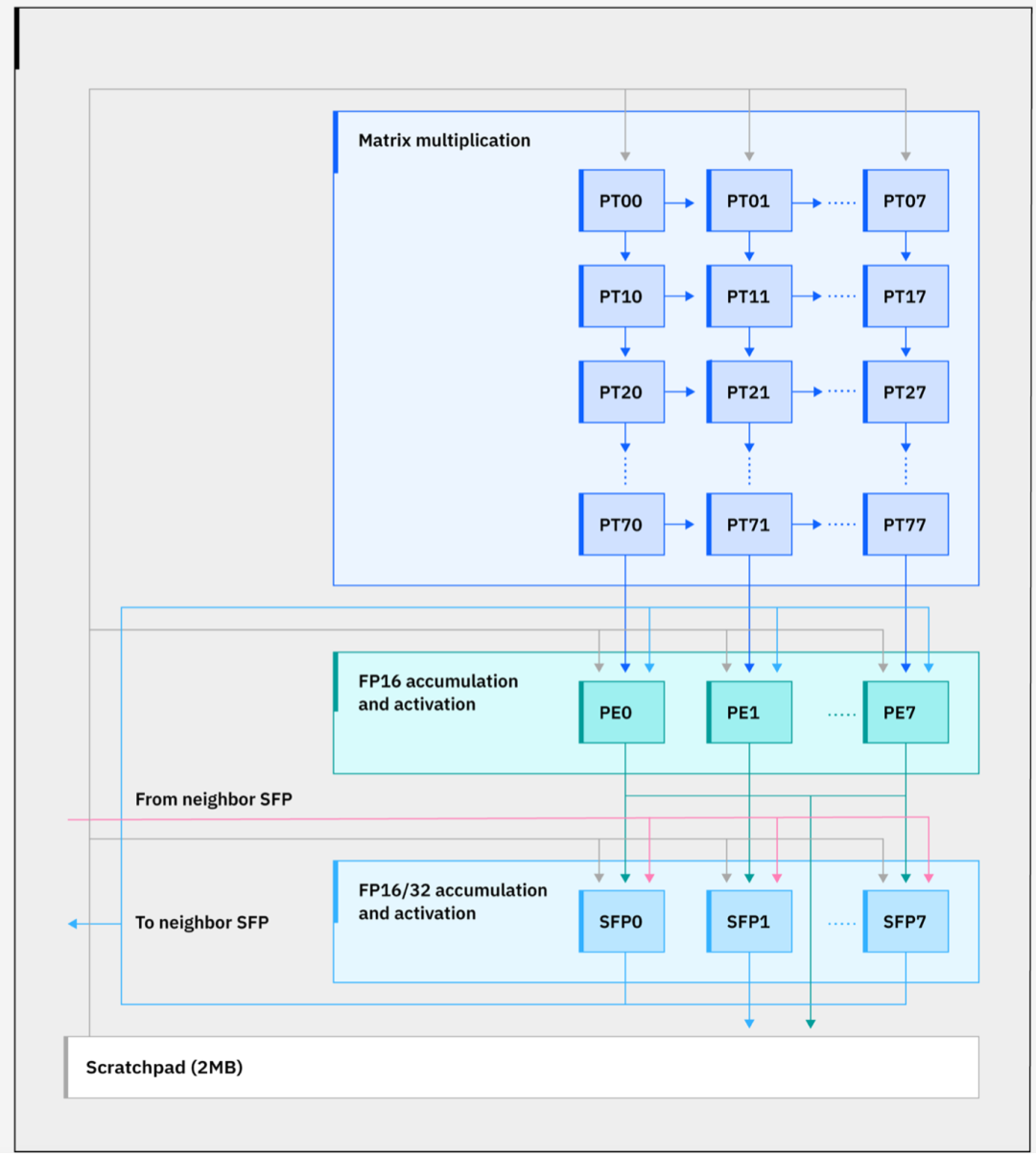
● 英特尔的Gaudi 3 AI加速器芯片在概念上与IBM类似,通过整合多个深度学习核心(DCORE)、张量处理核心(TPC)以及一个高效的内存子系统,实现了数据在不同计算单元之间的优化管理。这种架构设计可以在保持高性能的同时,显著提高每瓦性能。
随着AI应用从云端向边缘扩展,边缘计算已成为异构架构的一个重要发展方向。在边缘场景下,计算资源的限制更加严格,如何高效地进行推理计算成为设计的关键。

● 新兴公司FuriosaAI开发的RNGD(Renegade)推理芯片就专注于这种高效的边缘计算场景。其架构核心在于快速的数据移动和高带宽内存(HBM)支持,以在边缘设备上实现高效的AI推理。
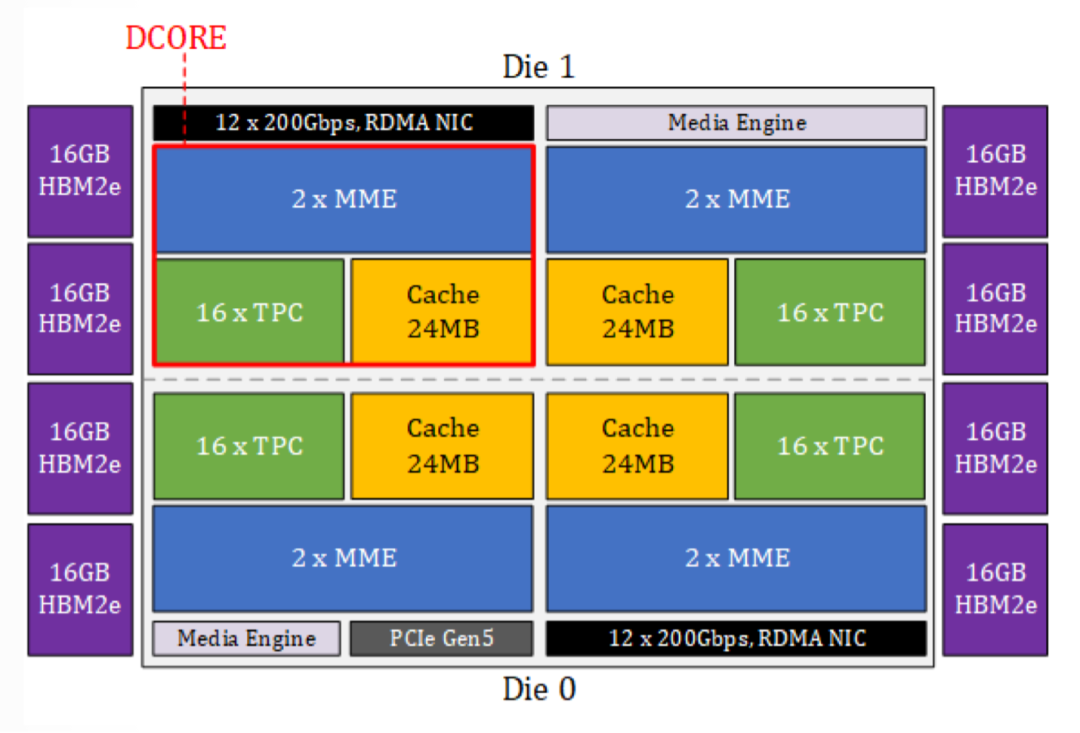
● 高通的Oryon SoC芯片也采用了多集群的设计,每个集群包含多个核心,以实现性能和能效的最佳平衡,特别重视内存管理和指令执行优化,能够在边缘计算场景下高效处理大量数据。

AI技术推动新的处理器架构设计不仅要在计算性能上继续进步,还要在能效和数据管理方面做出重大改进。未来的AI芯片可能会更倾向于通过更加智能和高效的设计,平衡性能和功耗之间的矛盾。
在这种背景下,AI芯片将不仅仅是一个计算硬件的组合,而是一个涉及从芯片到系统,再到软件的全面优化的复杂系统。从可持续计算的角度来看,这些改进非常重要。
AI模型的计算需求不断增加,而电网的能源供给并不总能跟上这样的增长速度。因此,降低AI处理器的能耗,尤其是在超大规模数据中心和边缘设备中,是未来AI处理器设计的重要目标。
小结
新型AI处理器架构的出现,标志着AI计算领域正在走向一个更加均衡和高效的未来。
无论是通过异构计算架构的应用、先进封装技术的利用,还是更智能的数据管理策略,这些新的发展方向都表明,AI处理器设计已经从单一追求极限性能,转向追求在不同应用场景下的最佳平衡。
