编写完成一个 C/C++ 程序后,想要运行起来,通常必须要经过四个步骤:预处理、编译、汇编和链接。每个步骤都会生成对应的文件,如下图所示(注意后缀名):

程序从编译链接到运行的各个阶段想必很多人都知道,但是能将很多细节真正讲清楚的人怕是寥寥无几。比如,在 C/C++ 语言中,一个源文件代码(这里以 .c 为后缀的文件举例)变为可执行文件(.exe/.out 后缀)的过程,究竟有几个阶段,每个阶段又做了哪些工作?让我们娓娓道来。
【拓展:程序、数据和指令概念】
程序是由代码(指令)、数据、进程控制块组成的;
数据指程序中的全局变量、静态变量、常量;
指令指程序中除数据以外的内容;比如:
int main(){
int a=10;
}这里
a是局部变量,它并不是数据,而是一条指令,指令功能是在函数栈帧上开辟四个字节,并向其中写入指定值。
首先有两个环境:一个翻译环境,一个运行环境;
翻译环境:就是把源代码翻译为计算机可以识别出来的01 二进制代码;
运行环境:就是执行代码,运行代码的一个环境;
翻译环境完成的工作可概括为:编译+链接的过程,而编译又可分为:预处理,编译,汇编三个步骤;因此,在翻译环境中的工作总共分为 4 个步骤,即预处理、编译、汇编以及链接。每个步骤又做了哪些事情呢?详情可参考下图:
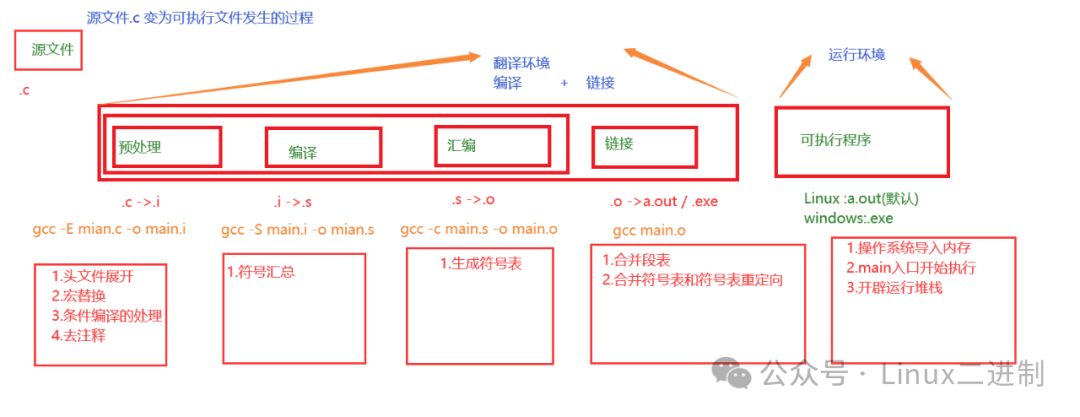
【拓展:编译和链接】
编译:把文本形式源代码翻译为机器语言形式的目标文件的过程。
链接:把目标文件、操作系统的启动代码和用到的库文件进行组织形成最终生成可加载、可执行代码的过程。
而程序从预处理、编译、汇编、链接到运行的每步操作,都是由 编译工具链(Toolchain) 的各个组件完成的,各个组件及其作用如下:
#define)、文件包含 (#include)、条件编译指令 (#ifdef, #ifndef, #if, #else, #endif) 等;替换宏定义,展开包含的文件内容,处理条件编译语句;输出经过预处理的源代码文件,通常称为预处理后的文件,它不再包含任何预处理指令。.o 或 .obj 文件),包含机器代码和符号表。.o 或 .obj 文件),如果编译器没有直接生成目标代码的话。注意:加载器会在程序运行时自动由操作系统调用。
上面内容主要帮助大家回顾一下程序编译链接流程,对于编译阶段不少人想必会更熟悉一点,但是对于链接阶段可能都知之甚少,大都是只有一个概念,真正了解的并不多。那么链接阶段,究竟做了哪些操作以及如何控制链接器做相应操作,这方面的文章也不多。本文将为大家讲解一下链接阶段的 Linker Script 脚本。
链接(Linking) 本质上就是把各个模块之间相互引用的部分处理好,使得各个模块之间能够正确衔接。链接器一般采用一种叫 两步链接(Two-pass Linking) 的方法。即整个链接过程分为两步:
【拓展:符号概念】
在程序中,所有数据都会产生符号,而对于代码节只有函数名会产生符号。而且符号的作用域有
global和local之分,对于未用static修饰过的全局变量和函数产生的均是global符号,这样的变量和函数可以被其他文件所看见和引用;而使用static修饰过的变量和函数,它们的作用域仅局限于当前文件,不会被其他文件所看见,即其他文件中也无法引用local符号的变量和函数。
注意:段(
Segment)与节(Section)的区别。很多地方对两者有所混淆。段包括代码段和数据段等,段是由节组成的,多个节经过链接后被合并为一个段。段是程序执行的必要组成,当多个目标文件链接成一个可执行文件时,会将相同权限的节合并到一个段中。相比而言,节的粒度更小。如想进一步了解二者区别,可参考Linux ELF 二进制文件解析及实战。如.data节和.bss节可能被合并到一个段中。
用一句话总结即:链接阶段主要进行地址和空间分配,符号决议和重定位等。其中地址和空间分配则是通过链接脚本(Linker Script)实现的,后续内容则将重点讲解链接脚本。
链接脚本(Linker Script,一般以 lds 作为文件的后缀名)是 ld 命令实现链接操作的规范性语义描述文件,使用链接命令语言(Linker Command Language)进行书写。链接脚本最主要的功能是描述如何将输入文件的节区(Sections)映射合并到输出文件的节中,同时对输出文件的存储布局进行控制。另外,链接脚本中还定义了其它众多的命令,可以控制链接器完成很多高级操作。链接器有个默认的内置链接脚本,可以使用 ld -verbose 查看,而ld -T 命令则可以指定链接脚本,它将代替默认的链接脚本。
注意:
输入文件指的是目标文件或链接脚本文件。
输出文件指的是目标文件或可执行文件。
链接脚本(Linker Script)是用于指导链接器如何将目标文件链接生成最终的可执行文件或者动态链接库的脚本。链接脚本描述了代码的内存分配、数据的布局、初始化、以及其他一些链接时需要的信息。下图我们通过一个例子,来说明链接脚本大致有哪些内容。如图所示:

链接脚本由一系列命令组成, 每个命令由一个关键字(一般在其后紧跟相关参数)或一条对符号的赋值语句组成。不同命令之间由分号 ; 分隔开。
文件名或格式名内如果包含分号 ; 或其他分隔符, 则要用引号”将名字全称引用起来。否则无法处理含引号的文件名。注意 /* */ 之间的是注释。
链接脚本通常使用一种简单的编程语言,例如 GNU Linker 的链接脚本是使用类似 C 的语言写成的脚本。通常它包含了以下信息:
地址空间布局:链接脚本可以指定代码节、数据节、BSS 节等在内存中的位置和大小,并决定它们的起始地址和结束地址。
符号表:链接脚本可以定义符号表,这些符号可以是全局变量、函数、常量等,它们将在链接过程中被绑定。
初始化和清除:链接器会按照链接脚本指定的顺序对节进行初始化,清除,或者进行其他的一些工作。
程序入口:链接脚本中可以指定程序入口,例如 _start() 或 main() 函数所在的地址。
注意:
_start()通常是程序第一个被执行的函数,即入口函数,而不是main()函数。我们的程序中通常并没有写_start(),它是通过链接器链接到可执行文件中的。对于
gcc编译器来说,在默认情况下:
程序加载后, _start()是第一个被执行的函数(_start()函数的入口地址就是代码节(.text)的起始地址)_start()函数,准备好参数后,立即调用__libc_start_main()函数__libc_start_main()初始化运行环境后,调用main()函数执行另外,我们可以自定义程序的入口函数,
gcc提供-e选项,用于在链接时指定入口函数,自定义入口函数时,必须使用选项-nostartfiles进行链接。
【拓展】链接器有多种方法设置进程入口地址(编号越前,优先级越高):
-e输入命令行选项;链接器控制脚本中的 ENTRY(symbol)命令;符号 start的值(如果存在)。.text节的第一个字节的地址(如果存在);地址 0。例如,您可以使用这些规则生成带有赋值语句的入口点:如果在输入文件中没有定义
start符号,则可以简单地定义它,并为其分配适当的值:
start = 0x2020; 该示例显示了一个绝对地址,但您可以使用任何表达式。例如,如果您的输入对象文件使用其他符号名称约定作为入口点,你可以将包含起始地址的符号赋值给start:start = other_symbol。
知晓了链接脚本包含的信息,接下来就让我们一起了解一下链接脚本的语法,链接脚本语法由一系列的命令和符号构成,详情见下文。
OUTPUT_FORMAT 是链接器脚本中的一个命令,用于指定输出文件的格式。这个命令对于确定输出文件的类型至关重要,因为不同的系统可能需要不同格式的输出文件。它通常出现在链接器脚本的开始部分,并且只能出现一次。语法如下:
OUTPUT_FORMAT(format, architecture)
参数解析如下:
format: 输出文件的格式,常见的格式包括 elf32, elf64, pe 等。
architecture: 目标架构,如 i386, x86-64, arm, aarch64,riscv32 ,riscv64 等。
【拓展:
OUTPUT_FORMAT指令可以接受不同数量的参数来定义输出文件的格式】
单参数形式 当
OUTPUT_FORMAT接受单个参数时,该参数通常包含两部分,用短横线-分隔,表示输出文件的格式和目标架构。这种形式通常用于ELF文件格式。示例:OUTPUT_FORMAT(elf32-i386)
elf32-i386:
elf32: 表示输出文件格式是32位的ELF。i386: 表示目标架构是32位的x86。
多参数形式 当
OUTPUT_FORMAT接受多个参数时,第一个参数通常表示输出文件的格式,第二个参数表示目标架构。这种形式通常用于ELF文件格式,特别是在需要指定字节序的情况下。示例:OUTPUT_FORMAT(elf64-little, aarch64)
elf64-little:
elf64: 表示输出文件格式是64位的ELF。little: 表示输出文件使用小端字节序。aarch64:
表示目标架构是 64位的ARM架构(AARCH64)。总结如下:
单参数形式:
通常用于 ELF文件格式。参数中包含文件格式和目标架构的信息,用短横线 -分隔。多参数形式:
通常用于 ELF文件格式。第一个参数表示文件格式和字节序。 第二个参数表示目标架构。
OUTPUT_ARCH 是链接器脚本中的一个命令,用于指定输出文件的目标架构。这个指令对于确保输出文件与目标平台兼容非常重要。它通常出现在链接器脚本的开始部分,并且只能出现一次。语法如下:
OUTPUT_ARCH(architecture)
参数解析如下:
architecture: 目标架构的名称,例如 i386, x86-64, arm, aarch64, riscv32, riscv64 等。
阅读到这里,可能有人会疑惑,既然 OUTPUT_FORMAT 已经支持指定目标架构,OUTPUT_ARCH 还有必要同时存在?实际上,在大多数情况下,OUTPUT_FORMAT 和 OUTPUT_ARCH 不需要同时存在,因为 OUTPUT_FORMAT 已经包含了足够的信息来指定输出文件的格式以及目标架构。那么,为什么还要提供 OUTPUT_ARCH 命令?因为在某些情况下,你可能需要同时使用 OUTPUT_FORMAT 和 OUTPUT_ARCH,但这通常是比较少见的情况。
【拓展:需要同时使用
OUTPUT_FORMAT和OUTPUT_ARCH的场景】
兼容特定版本的链接器工具链:
有些旧版本的工具链可能需要明确指定架构信息才能正确工作。在这种情况下, OUTPUT_ARCH提供了必要的信息。与其他工具集成:
如果其他工具期望链接器脚本中包含架构信息,则 OUTPUT_ARCH可以确保这些工具能够正确地处理链接器脚本。
ENTRY(SYMBOL) 表示将符号 SYMBOL 的值设置为入口地址,入口地址是程序执行的第一条指令在程序地址空间的地址;当一个程序被加载到内存中准备执行时,操作系统会查找程序的入口点,并从那里开始执行。在大多数情况下,这个入口点就是 _start 函数。
_start 函数通常在启动文件(如 startup.S 或 startup.asm)中定义,这是一个汇编语言文件,处理程序启动时的初始化工作,例如设置栈指针、关闭中断等。_start 函数负责完成必要的初始化后调用 main() 函数。在 main() 函数结束后,通常会返回 _start 函数中,进行清理操作并调用 exit() 函数结束程序。
例如, ENTRY(_start) 告诉链接器程序的启动点是 _start 函数。当程序被加载到内存中时,CPU 会跳转到 _start 函数的地址开始执行。ENTRY(_start) 通常放在链接器脚本的开头部分,以便明确指示程序的启动位置。
看到这里,可能有人会有疑问,如果程序入口点既不是 _start 函数,又不是 main 函数,而是自定义的其它函数,程序能否正常运行呢?毕竟一直以来我们接触到的程序,都是以 _start 或者 main 函数为入口点的,下面让我们带着这个疑问,通过一个示例来验证一下。程序的入口点是一个自定义的函数 custom_entry,而不是 main 或 _start。
我们的 C 代码如下所示,定义了一个 custom_entry 函数作为程序的入口点:
#include
#include
void custom_entry() {
printf("Starting the program from custom_entry function.\n");
exit(0);
}
在这个示例中,我们只定义了 custom_entry 函数,没有定义main 函数,随后,通过链接器脚本来指定 custom_entry 作为程序的入口点。首先我们可以通过 ld -verbose 命令获取默认的链接脚本。在默认链接脚本的基础上仅更改程序入口点,改为 custom_entry 函数。修改后链接器脚本如下:
OUTPUT_FORMAT("elf64-x86-64", "elf64-x86-64",
"elf64-x86-64")
OUTPUT_ARCH(i386:x86-64)
ENTRY(custom_entry)
SEARCH_DIR("=/usr/x86_64-redhat-linux/lib64"); SEARCH_DIR("=/usr/lib64"); SEARCH_DIR("=/usr/local/lib64"); SEARCH_DIR("=/lib64"); SEARCH_DIR("=/usr/x86_64-redhat-linux/lib"); SEARCH_DIR("=/usr/local/lib"); SEARCH_DIR("=/lib"); SEARCH_DIR("=/usr/lib");
SECTIONS
{
/* Read-only sections, merged into text segment: */
PROVIDE (__executable_start = SEGMENT_START("text-segment", 0x400000)); . = SEGMENT_START("text-segment", 0x400000) + SIZEOF_HEADERS;
.interp : { *(.interp) }
.note.gnu.build-id : { *(.note.gnu.build-id) }
.hash : { *(.hash) }
.gnu.hash : { *(.gnu.hash) }
.dynsym : { *(.dynsym) }
.dynstr : { *(.dynstr) }
.gnu.version : { *(.gnu.version) }
.gnu.version_d : { *(.gnu.version_d) }
.gnu.version_r : { *(.gnu.version_r) }
.rela.dyn :
{
*(.rela.init)
*(.rela.text .rela.text.* .rela.gnu.linkonce.t.*)
*(.rela.fini)
*(.rela.rodata .rela.rodata.* .rela.gnu.linkonce.r.*)
*(.rela.data .rela.data.* .rela.gnu.linkonce.d.*)
*(.rela.tdata .rela.tdata.* .rela.gnu.linkonce.td.*)
*(.rela.tbss .rela.tbss.* .rela.gnu.linkonce.tb.*)
*(.rela.ctors)
*(.rela.dtors)
*(.rela.got)
*(.rela.bss .rela.bss.* .rela.gnu.linkonce.b.*)
*(.rela.ldata .rela.ldata.* .rela.gnu.linkonce.l.*)
*(.rela.lbss .rela.lbss.* .rela.gnu.linkonce.lb.*)
*(.rela.lrodata .rela.lrodata.* .rela.gnu.linkonce.lr.*)
*(.rela.ifunc)
}
.rela.plt :
{
*(.rela.plt)
PROVIDE_HIDDEN (__rela_iplt_start = .);
*(.rela.iplt)
PROVIDE_HIDDEN (__rela_iplt_end = .);
}
.init :
{
KEEP (*(SORT_NONE(.init)))
}
.plt : { *(.plt) *(.iplt) }
.plt.got : { *(.plt.got) }
.plt.sec : { *(.plt.sec) }
.text :
{
*(.text.unlikely .text.*_unlikely .text.unlikely.*)
*(.text.exit .text.exit.*)
*(.text.startup .text.startup.*)
*(.text.hot .text.hot.*)
*(.text .stub .text.* .gnu.linkonce.t.*)
/* .gnu.warning sections are handled specially by elf32.em. */
*(.gnu.warning)
}
.fini :
{
KEEP (*(SORT_NONE(.fini)))
}
PROVIDE (__etext = .);
PROVIDE (_etext = .);
PROVIDE (etext = .);
.rodata : { *(.rodata .rodata.* .gnu.linkonce.r.*) }
.rodata1 : { *(.rodata1) }
.eh_frame_hdr : { *(.eh_frame_hdr) *(.eh_frame_entry .eh_frame_entry.*) }
.eh_frame : ONLY_IF_RO { KEEP (*(.eh_frame)) *(.eh_frame.*) }
.gcc_except_table : ONLY_IF_RO { *(.gcc_except_table
.gcc_except_table.*) }
.gnu_extab : ONLY_IF_RO { *(.gnu_extab*) }
/* These sections are generated by the Sun/Oracle C++ compiler. */
.exception_ranges : ONLY_IF_RO { *(.exception_ranges
.exception_ranges*) }
/* Adjust the address for the data segment. We want to adjust up to
the same address within the page on the next page up. */
. = DATA_SEGMENT_ALIGN (CONSTANT (MAXPAGESIZE), CONSTANT (COMMONPAGESIZE));
/* Exception handling */
.eh_frame : ONLY_IF_RW { KEEP (*(.eh_frame)) *(.eh_frame.*) }
.gnu_extab : ONLY_IF_RW { *(.gnu_extab) }
.gcc_except_table : ONLY_IF_RW { *(.gcc_except_table .gcc_except_table.*) }
.exception_ranges : ONLY_IF_RW { *(.exception_ranges .exception_ranges*) }
/* Thread Local Storage sections */
.tdata : { *(.tdata .tdata.* .gnu.linkonce.td.*) }
.tbss : { *(.tbss .tbss.* .gnu.linkonce.tb.*) *(.tcommon) }
.preinit_array :
{
PROVIDE_HIDDEN (__preinit_array_start = .);
KEEP (*(.preinit_array))
PROVIDE_HIDDEN (__preinit_array_end = .);
}
.init_array :
{
PROVIDE_HIDDEN (__init_array_start = .);
KEEP (*(SORT_BY_INIT_PRIORITY(.init_array.*) SORT_BY_INIT_PRIORITY(.ctors.*)))
KEEP (*(.init_array EXCLUDE_FILE (*crtbegin.o *crtbegin?.o *crtend.o *crtend?.o ) .ctors))
PROVIDE_HIDDEN (__init_array_end = .);
}
.fini_array :
{
PROVIDE_HIDDEN (__fini_array_start = .);
KEEP (*(SORT_BY_INIT_PRIORITY(.fini_array.*) SORT_BY_INIT_PRIORITY(.dtors.*)))
KEEP (*(.fini_array EXCLUDE_FILE (*crtbegin.o *crtbegin?.o *crtend.o *crtend?.o ) .dtors))
PROVIDE_HIDDEN (__fini_array_end = .);
}
.ctors :
{
/* gcc uses crtbegin.o to find the start of
the constructors, so we make sure it is
first. Because this is a wildcard, it
doesn't matter if the user does not
actually link against crtbegin.o; the
linker won't look for a file to match a
wildcard. The wildcard also means that it
doesn't matter which directory crtbegin.o
is in. */
KEEP (*crtbegin.o(.ctors))
KEEP (*crtbegin?.o(.ctors))
/* We don't want to include the .ctor section from
the crtend.o file until after the sorted ctors.
The .ctor section from the crtend file contains the
end of ctors marker and it must be last */
KEEP (*(EXCLUDE_FILE (*crtend.o *crtend?.o ) .ctors))
KEEP (*(SORT(.ctors.*)))
KEEP (*(.ctors))
}
.dtors :
{
KEEP (*crtbegin.o(.dtors))
KEEP (*crtbegin?.o(.dtors))
KEEP (*(EXCLUDE_FILE (*crtend.o *crtend?.o ) .dtors))
KEEP (*(SORT(.dtors.*)))
KEEP (*(.dtors))
}
.jcr : { KEEP (*(.jcr)) }
.data.rel.ro : { *(.data.rel.ro.local* .gnu.linkonce.d.rel.ro.local.*) *(.data.rel.ro .data.rel.ro.* .gnu.linkonce.d.rel.ro.*) }
.dynamic : { *(.dynamic) }
.got : { *(.got) *(.igot) }
. = DATA_SEGMENT_RELRO_END (SIZEOF (.got.plt) >= 24 ? 24 : 0, .);
.got.plt : { *(.got.plt) *(.igot.plt) }
.data :
{
*(.data .data.* .gnu.linkonce.d.*)
SORT(CONSTRUCTORS)
}
.data1 : { *(.data1) }
_edata = .; PROVIDE (edata = .);
. = .;
__bss_start = .;
.bss :
{
*(.dynbss)
*(.bss .bss.* .gnu.linkonce.b.*)
*(COMMON)
/* Align here to ensure that the .bss section occupies space up to
_end. Align after .bss to ensure correct alignment even if the
.bss section disappears because there are no input sections.
FIXME: Why do we need it? When there is no .bss section, we don't
pad the .data section. */
. = ALIGN(. != 0 ? 64 / 8 : 1);
}
.lbss :
{
*(.dynlbss)
*(.lbss .lbss.* .gnu.linkonce.lb.*)
*(LARGE_COMMON)
}
. = ALIGN(64 / 8);
. = SEGMENT_START("ldata-segment", .);
.lrodata ALIGN(CONSTANT (MAXPAGESIZE)) + (. & (CONSTANT (MAXPAGESIZE) - 1)) :
{
*(.lrodata .lrodata.* .gnu.linkonce.lr.*)
}
.ldata ALIGN(CONSTANT (MAXPAGESIZE)) + (. & (CONSTANT (MAXPAGESIZE) - 1)) :
{
*(.ldata .ldata.* .gnu.linkonce.l.*)
. = ALIGN(. != 0 ? 64 / 8 : 1);
}
. = ALIGN(64 / 8);
_end = .; PROVIDE (end = .);
. = DATA_SEGMENT_END (.);
/* Stabs debugging sections. */
.stab 0 : { *(.stab) }
.stabstr 0 : { *(.stabstr) }
.stab.excl 0 : { *(.stab.excl) }
.stab.exclstr 0 : { *(.stab.exclstr) }
.stab.index 0 : { *(.stab.index) }
.stab.indexstr 0 : { *(.stab.indexstr) }
.comment 0 : { *(.comment) }
.gnu.build.attributes : { *(.gnu.build.attributes .gnu.build.attributes.*) }
/* DWARF debug sections.
Symbols in the DWARF debugging sections are relative to the beginning
of the section so we begin them at 0. */
/* DWARF 1 */
.debug 0 : { *(.debug) }
.line 0 : { *(.line) }
/* GNU DWARF 1 extensions */
.debug_srcinfo 0 : { *(.debug_srcinfo) }
.debug_sfnames 0 : { *(.debug_sfnames) }
/* DWARF 1.1 and DWARF 2 */
.debug_aranges 0 : { *(.debug_aranges) }
.debug_pubnames 0 : { *(.debug_pubnames) }
/* DWARF 2 */
.debug_info 0 : { *(.debug_info .gnu.linkonce.wi.*) }
.debug_abbrev 0 : { *(.debug_abbrev) }
.debug_line 0 : { *(.debug_line .debug_line.* .debug_line_end ) }
.debug_frame 0 : { *(.debug_frame) }
.debug_str 0 : { *(.debug_str) }
.debug_loc 0 : { *(.debug_loc) }
.debug_macinfo 0 : { *(.debug_macinfo) }
/* SGI/MIPS DWARF 2 extensions */
.debug_weaknames 0 : { *(.debug_weaknames) }
.debug_funcnames 0 : { *(.debug_funcnames) }
.debug_typenames 0 : { *(.debug_typenames) }
.debug_varnames 0 : { *(.debug_varnames) }
/* DWARF 3 */
.debug_pubtypes 0 : { *(.debug_pubtypes) }
.debug_ranges 0 : { *(.debug_ranges) }
/* DWARF Extension. */
.debug_macro 0 : { *(.debug_macro) }
.debug_addr 0 : { *(.debug_addr) }
.gnu.attributes 0 : { KEEP (*(.gnu.attributes)) }
/DISCARD/ : { *(.note.GNU-stack) *(.gnu_debuglink) *(.gnu.lto_*) *(.gnu_object_only) }
}
s) }
}
接着,让我们编译和运行这个程序:
[root@localhost test]# gcc -c entry_example.c -o entry_example.o
[root@localhost test]# gcc -nostartfiles -T linker_script.lds entry_example.o -o entry_example
[root@localhost test]# ls -l
total 28
-rwxr-xr-x. 1 root root 6464 Aug 20 08:27 entry_example
-rw-r--r--. 1 root root 249 Aug 20 08:20 entry_example.c
-rw-r--r--. 1 root root 1600 Aug 20 08:27 entry_example.o
-rw-r--r--. 1 root root 8664 Aug 20 08:16 linker_script.lds
[root@localhost test]# ./entry_example
Starting the program from custom_entry function.
上面内容表明程序成功从 custom_entry 函数开始执行。另外,也说明我们的程序即使没有 main 函数,依然可以运行。
【拓展】
-nostartfiles选项告诉GCC链接器不使用默认的启动文件(start-up files)。在默认情况下,GCC会在链接阶段自动包含一些启动文件,这些文件提供了C/C++程序的标准启动逻辑,包括初始化C运行时环境、设置栈和堆等。这些文件通常是操作系统特定的,并且依赖于你的目标平台。当你使用
-nostartfiles选项时,链接器将跳过这些启动文件的使用,这意味着它不会自动包含以下内容:
标准 C运行时库(如libc)的初始化代码。全局构造器和析构器的处理。 标准输入/输出流的初始化(如 stdin,stdout,stderr)。默认的异常处理机制。 标准 C运行时环境的清理。由于
-nostartfiles选项阻止了这些启动文件的加载,因此你的程序必须自己提供必要的初始化代码。这对于创建最小化的可执行文件或自定义启动过程非常有用,但同时也要求程序员自己处理这些通常由C运行时库自动完成的任务。虽然使用
-nostartfiles选项时,链接器不会自动包含默认的启动文件和C运行时库。然而,即使使用了-nostartfiles,GCC仍然能够正确地链接C运行时库中的某些函数,这是因为GCC有一个特殊机制来处理这种情况。当你在程序中使用了
printf函数,GCC 编译器会自动产生对printf的引用。即使使用了-nostartfiles,链接器仍然会尝试满足这些未解析的符号引用。在这种情况下,链接器会自动链接libc库来提供printf函数。但是,需要注意的是,虽然
printf可以正常工作,但main函数和其他一些C运行时环境的特性则不会自动被链接,除非你显式地链接libc库。
定位计数器 . 是链接器脚本中的一个特殊变量,表示当前的内存地址位置。它用于确定如何放置各个节和数据,总是代表输出文件中的一个地址(根据输入文件Section 的大小不断增加,不能倒退,且只用于 SECTIONS 命令中)。对定位计数器 . 赋值可指定其后内容的存储位置,如果没有以其它的方式指定输出节的地址,则地址值就会被设为定位计数器的当前值,下面举例说明:
SECTIONS
{
. = 0x10000;
.text : { *(.text) }
. = 0x8000000;
.data : { *(.data) }
.bss : { *(.bss) }
}
上述示例中使用 SECTIONS 来描述输出文件各节的内存布局,需要注意的是,在 SECTIONS 命令的开始处, 定位计数器当前值为0。让我们一起解析一下上面示例的含义:
.= 0x10000:表示将定位计数器赋值为0x10000;.text 即定义 .text 代码节,且其地址即为定位计数器的当前值 0x10000,通配符 * 代表所有的输入文件,即表示所有参与链接的文件中的 .text 节(例如:*main.o(.text)代表 main.o 文件中所有 .text 节);.data 即定义 .data 数据节,且其地址为定位计数器当前值 0x8000000, *(.data) 代表所有参与链接文件中的 .data 节;(注意,*(.data.*) 则表示所有参与链接文件的 .data 节中的全部数据);.bss 即定义.bss 数据节,其地址为 0x8000000 + .data section length ,(.bss) 代表所有参与链接文件中的 .bss 节。【拓展:.bss 节特点】
未初始化的数据:
.bss节通常用于存放未初始化的全局变量和静态局部变量。这些变量在程序运行时会被自动初始化为零。零填充:
因为 .bss节中的数据在程序开始执行时被初始化为零,所以这个节不包含任何实际的数据,只有大小信息。内存占用:
由于 .bss节的数据被初始化为零,因此在生成的可执行文件中并不包含.bss节的实际数据,这有助于减小程序的大小。动态分配:
.bss节中的数据在程序运行时由操作系统动态分配。这意味着,虽然编译时指定了.bss节的大小,但实际的数据分配发生在程序加载时。对齐要求:
.bss节中的数据通常需要满足一定的对齐要求,以确保数据的正确访问。链接器脚本可以用来指定对齐方式。
.bss节用于存放未初始化的数据,这些数据在程序运行时由操作系统自动初始化为零。它有助于减小程序的大小,并确保未初始化的数据具有一个已知的初始状态。在链接器脚本中,可以通过特定的指令来定义.bss节的位置、大小以及对齐方式。
在链接器脚本中,SECTIONS 命令用于定义如何组织和放置不同的Sections。这是链接器脚本的核心部分,因为它决定了最终可执行文件中各个节的布局。SECTIONS 命令告诉链接器如何将输入节映射到输出节,以及如何将输出节放在内存中。基本语法如下:
SECTIONS
{
SECTIONS-COMMAND
SECTIONS-COMMAND
...
}
每个 SECTIONS-COMMAND 可以是下列命令之一:
ENTRY 命令section 的描述 (output section description)section 叠加描述 (overlay description)为了方便在 SECTIONS 命令中使用位置计数器,允许在 SECTIONS 命令中使用 ENTRY 命令和符号赋值。这也可以使链接器脚本更容易理解,因为您可以在输出文件布局中在有意义的位置使用这些命令。
注意:如果整个链接脚本内没有
SECTIONS命令, 那么ld将所有同名输入section合成到一个输出section内, 各输入section的顺序为它们被链接器发现的顺序。第一个节将在地址0处。如果某输入section没有在SECTIONS命令中提到, 那么该section将被直接拷贝成输出section。
1)ENTRY 命令
ENTRY 命令用来指定程序的入口点,即程序开始执行的位置。在链接器脚本中,ENTRY 命令通常位于 SECTIONS 块之外,直接放在链接器脚本的顶层。然而,在某些情况下,ENTRY 命令可能会放在 SECTIONS 块中,尽管这不是典型的用法。尽管不是常见做法,但在某些情况下,ENTRY 命令可以放在 SECTIONS 块中,这可能是为了实现特定的目的。例如,如果你想在一个特定的段中指定入口点,或者为了兼容某个特定的工具链或平台的要求,你可能会这样做。
假设你有一个特殊的需要,希望确保程序的入口点 custom_entry 必须位于 .text 段中,并且在链接过程中能够正确处理这个入口点。你可以这样做:
SECTIONS
{
.text : { ENTRY(custom_entry) *(.text) }
.data : { *(.data) }
.bss : { *(.bss) }
}
在这个示例中,ENTRY(custom_entry) 被放在了 .text 段的定义中。这通常不是一个推荐的做法,因为 ENTRY 指令最好位于 SECTIONS 块之外,以确保它被正确处理。
2) 符号赋值语句
在 SECTIONS 块内,你也可以使用符号赋值语句来定义符号及其值。尽管在 SECTIONS 块内定义符号不是最典型的用法,但在某些情况下,你可能需要这样做以满足特定的需求。下面是对 SECTIONS 块内符号赋值的总结:
4 个语法元素:符号名、操作符、表达式、分号,一个也不能少;. 是一个特殊的符号,它是定位计数器,一个位置指针,指向程序地址空间内的某位置。该符号只能在 SECTIONS 命令内使用。赋值语句可以出现在链接脚本的三个地方:
SECTIONS 命令内;
SECTIONS 命令内的 section 描述内;
全局位置。
示例如下:
floating_point = 0; /* 全局位置 */
SECTIONS {
. = ALIGN(4);
.text :
{
sram/*(.text*)
sram/*(.data*)
sram/*(.rodata*)
*(.reset_patch)
*(.sram_text)
*(.sram)
} > sram
. = ALIGN(0x8000);
.data :
{
*(.text*)
. = ALIGN(4); /* section 描述内 */
*(.data*)
*(.rodata*)
. = ALIGN(16);
} > ddram
. = ALIGN(4); /* SECTIONS 命令内 */
.bss :
{
. = ALIGN(4);
__bss_start__ = .;
*(.bss*)
*(COMMON)
. = ALIGN(4);
__bss_end__ = .;
} > ddram
}
3) 输出 section 的描述
一个完整的输出节的描述格式如下:
SECTION [ADDRESS] [(TYPE)] :
[AT(LMA)]
[ALIGN(SECTION_ALIGN) | ALIGN_WITH_INPUT]
[SUBALIGN(SUBSECTION_ALIGN)]
[CONSTRAINT]
{
OUTPUT-SECTION-COMMAND
OUTPUT-SECTION-COMMAND
...
} [>REGION] [AT>LMA_REGION] [:PHDR :PHDR ...] [=FILLEXP] [,]
链接脚本本质就是描述输入和输出。上述字段解析如下:
SECTION: 节的名称,例如 .text, .data, 或 .bss 等。
ADDRESS: 节的起始地址,如果指定,链接器会将节放置在该地址。
Type:节的类型,常见类型如下:
NOLOAD:该段被标记为不可加载, 所以在程序运行时不会加载到内存中;
DSECT,COPY,INFO,OVERLAY:为了向后兼容,支持这些类型名,因此很少使用。它们都具有相同的效果:应该将该节标记为不可分配的,这样在程序运行时就不会为该节分配内存;
AT(LMA):AT 用表达式做参数,指定实际的加载内存地址(Load Memory Address, LMA);LMA 表示节的加载内存地址,编译后的程序在内存中的起始位置,即数据实际存储的内存地址;
ALIGN(SECTION_ALIGN) | ALIGN_WITH_INPUT:指定节的对齐方式:
SECTION_ALIGN 是具体的对齐值,例如:ALIGN(4) 表示段对齐到 4 字节边界;
ALIGN_WITH_INPUT 指示该节应该与输入文件中的对应节具有相同的对齐方式;
SUBALIGN(SUBSECTION_ALIGN):SUBALIGN 用于指定子节的对齐方式,SUBSECTION_ALIGN 是子节的对齐值;
CONSTRAINT:一个约束条件,用于限制节的位置或大小等属性;
{ OUTPUT-SECTION-COMMAND ... }:这部分是节的主体,包含了一系列的输出节命令,用于定义该节应包含哪些输入节(例如,特定的代码或数据块)、如何处理这些输入节(如合并、重定位等),以及节内的任何特定布局需求。
>REGION:REGION 指定该节应该被放置在哪个内存区域,表示存储器的种类,一般通过 MEMORY 指令定义(如RAM、ROM等)。这里的 REGION 又被称为 VMA(Virtual memory address ) ,即虚拟内存地址;
AT>LMA_REGION:类似于 AT(LMA),但是 AT> 使用内存区域名做参数,这里 LMA_REGION 是指定的内存区域名,用于进一步控制节的加载地址。
【拓展:VMA 与 LMA 区别】
通常
VMA和LMA是相同的。VMA是执行输出文件时section所在的地址,而LMA是加载输出文件时section所在的地址。一般而言,某section的VMA==LMA。但在嵌入式系统中,经常存在加载地址和执行地址不同的情况:例如,将输出文件加载到开发板的flash中 (由LMA指定), 而运行时将位于flash中的输出文件复制到
SDRAM中 (由VMA指定) 。
:PHDR :PHDR ...:指定哪些节应该包含在程序头表中(Program Header, PHDR)。多个:PHDR 则表示该节包含在多个程序头表中。程序头表使用 PHDRS 命令定义。如果一个节(section)会被分配给多个段 (segment),那么通过显示的指明 :PHDR 可以改变可分配节被分配给段的顺序。使用 :NONE 告诉链接器不要将该节分配给任何段。下面一个简单的例子:
PHDRS {
interp PT_INTERP;
text PT_LOAD;
}
SECTIONS {
.interp : { *(.interp) } :text :interp
.text : { *(.text) } :text
}
注意:一旦在链接脚本内使用了
PHDRS命令,那么链接器仅会创建PHDRS命令指定的信息,所以使用时须谨慎。
=FILLEXP:你可以使用 =FILLEXP 来设定填充模式,FILLEXP 是一个表达式。任何没有指定的输出节的内存区域(比如,因为输入节的对齐要求而产生的裂缝)会被填入这个值。如果填充表达式是一个简单的十六进制值, 比如, 一个以 0x 开始的十六进制数字组成的字符串, 并且尾部不是 k 或 M,那一个任意的十六进制数字长序列可以被用来指定填充样式;前导零也变为样式的一部分。对于所有其他的情况,包含一个附加的括号或一元操作符 +,那填充样式是表达式的最低四字节的值。在所有的情况下,数值是 big-endian。下面是一个例子:
SECTIONS { .text : { *(.text) } =0x90909090 }
注意:可能使用
FILL命令来为当前节设置填充样式。它后面跟有一个括号中的表达式。任何未指定的节内内存区域(比如,因为输入节的对齐要求而造成的裂缝)会以这个表达式的值进行填充。一个FILL语句会覆盖到它本身在节定义中出现的位置后面的所有内存区域;通过引入多个FILL语句,你可以在输出节的不同位置拥有不同的填充样式。这个例子显示如何在未被指定的内存区域填充0x90:FILL(0x90909090),FILL命令跟输出节的=FILLEXP属性相似,但它只影响到节内跟在FILL命令后面的部分,而不是整个节。如果两个都用到了,那FILL命令优先。
4) 叠加 section 的描述
覆盖描述提供了一种简单的方法来描述要作为单个内存映像的一部分加载但要在同一内存地址上运行的部分。在运行时,某种类型的覆盖管理器将根据需要将覆盖的部分复制到运行时内存地址中或从运行时内存地址中复制出来,可能只是通过简单地操作寻址位。例如,当内存的某个区域比另一个区域快时,这种方法可能很有用。
使用 OVERLAY 命令描述覆盖。OVERLAY 命令在 SECTIONS 命令中使用,就像输出部分描述一样。OVERLAY 命令的完整语法如下:
OVERLAY [START] : [NOCROSSREFS] [AT ( LDADDR )]
{
SECNAME1
{
OUTPUT-SECTION-COMMAND
OUTPUT-SECTION-COMMAND
...
} [:PHDR...] [=FILL]
SECNAME2
{
OUTPUT-SECTION-COMMAND
OUTPUT-SECTION-COMMAND
...
} [:PHDR...] [=FILL]
...
} [>REGION] [:PHDR...] [=FILL…]
除了 OVERLAY 关键字, 所有的都是可选的, 每一个节必须有一个名字(上面的 SECNAME1 和 SECNAME2)。在 OVERLAY 结构中的节定义跟通常的 SECTIONS 结构中的节定义是完全相同的,除了一点,就是在 OVERLAY 中没有地址跟内存区域的定义。
节都被定义为同一个开始地址
这些节都用相同的起始地址(VMA)定义。节的加载地址是这样安排的,它们在内存中是连续的,从用于 OVERLAY 的加载地址作为一个整体开始(与正常的节定义一样,加载地址是可选的,默认为开始地址;起始地址也是可选的,默认为位置计数器的当前值)。
如果使用NOCROSSREFS 关键字,并且节之间有任何引用,则链接器将报告错误。由于所有节都运行在相同的地址,因此一个节直接引用另一个节通常是没有意义的。
对于 OVERLAY 中的每个部分,链接器自动提供两个符号。符号 __load_start_secname 被定义为该 section 的起始加载地址。符号__load_stop_secname 被定义为该 section 的最终加载地址。secname 中任何在 C 标识符中不合法的字符都将被删除。C (或汇编)代码可以根据需要使用这些符号来移动覆盖的部分。
在覆盖结束时,位置计数器的值被设置为覆盖的起始地址加上最大部分的大小。
这里有一个例子。记住,这将出现在一个 SECTIONS 构造中。
OVERLAY 0x1000 : AT (0x4000)
{
.text0 { o1/*.o(.text) }
.text1 { o2/*.o(.text) }
}
这段代码会定义 .text0 和 .text1,它们都从地址 0x1000 开始。.text0 会被载入到地址 0x4000 处,而 .text1 会被载入到紧随 .text0 后的位置。下面的几个符号会被定义: __load_start_text0,__load_stop_text0, __load_start_text1,__load_stop_text1。
拷贝 .text1 到覆盖区域的 C 代码看上去可能会像下面这样:
extern char __load_start_text1, __load_stop_text1;
memcpy ((char *) 0x1000, &__load_start_text1,
&__load_stop_text1 - &__load_start_text1);
注意 OVERLAY 命令只是为了语法上的便利, 因为它所做的所有事情都可以用更加基本的命令加以代替。上面的例子可以用下面的完全特效的写法:
.text0 0x1000 : AT (0x4000) { o1/*.o(.text) }
PROVIDE (__load_start_text0 = LOADADDR (.text0));
PROVIDE (__load_stop_text0 = LOADADDR (.text0) + SIZEOF (.text0));
.text1 0x1000 : AT (0x4000 + SIZEOF (.text0)) { o2/*.o(.text) }
PROVIDE (__load_start_text1 = LOADADDR (.text1));
PROVIDE (__load_stop_text1 = LOADADDR (.text1) + SIZEOF (.text1));
. = 0x1000 + MAX (SIZEOF (.text0), SIZEOF (.text1));
链接器的默认配置允许分配所有可用内存。可以使用 MEMORY 命令覆盖该配置。MEMORY 命令描述目标中内存块的位置和大小,通过仔细使用它,您可以描述链接器可以使用哪些内存区域,以及它必须避免使用哪些内存区域。链接器不会打乱部分以适应可用的区域,而是将请求的部分移动到正确的区域,并在区域太满时发出错误。一个命令文件最多只能包含一次对 MEMORY 命令的使用;但是,您可以根据需要在 MEMORY 中定义任意数量的内存块。
MEMORY 块对于定义不同节的内存位置非常重要,特别是当你要在特定地址加载代码或数据时。通常每个区域都有一个名称、类型和大小。基本语法如下:
MEMORY
{
NAME1 [(ATTR)] : ORIGIN = ORIGIN1, LENGTH = LEN1
NAME2 [(ATTR)] : ORIGIN = ORIGIN2, LENGTH = LEN2
}
MEMORY 命令定义了存储空间。
NAME:内存区域的名字,每一块内存区域必须有一个唯一的名字;
ATTR:定义该存储区域的属性。ATTR 属性内可以出现以下 7 个字符:
R 只读 section
W 读/写 section
X 可执行 section
A 可分配的 section
I 初始化了的 section
L 同I
! 反转以上任何属性的含义
ORIGIN:物理内存中区域的起始地址。它是一个表达式,必须在执行内存分配之前求值为常数。关键字 ORIGIN 可以缩写为 org 或 o(但不能写成 ORG);
LENGTH:以字节为单位的地址空间的长度,可缩写为len或l。
MEMEORY 定义示例如下:
MEMORY
{
rom (rx) : ORIGIN = 0, LENGTH = 256K /* 只读和可执行存储器rom,起始地址0,大小256K字节 */
ram (!rx) : org = 0x40000000, l = 4M /* 不可读且不能执行存储器ram,其地址0X40000000,大小4M字节 */
}
一旦定义了一个名为 mem 的内存区域,就可以在 SECTIONS 命令中使用以 >mem 结尾的命令,将特定的输出部分定向到该区域。如果指向某个区域的组合输出部分对于该区域来说太大,则链接器将发出错误消息。示例如下:
ENTRY(_start) /* 程序入口点 */
MEMORY /* 定义存储区 */
{
ROM (rx) : ORIGIN = 0X00000000, LENGTH = 2M
RAM (rw) : ORIGIN = 0X30000000 , LENGTH = 64M
}
SECTIONS
{
. = 0; /* 程序起始地址 */
.text BLOCK(4) (NOLOAD): { /* 块4字节对齐, 不加载 */
*(.text)
} > ROM /* 存放在ROM中,ROM起始地址为MEMORY定义的 */
.rodata : { /* 只读数据节 */
*(.rodata)
*(.rodata.*)
. = ALIGN(4); /* 进行4字节对齐 */
} > ROM /* 同样存放在ROM中,紧挨着上面的.text存放 */
load_addr = LOADADDR(.rodata) + SIZEOF(.rodata); /* 计算当前的加载地址, 相当于load_addr = .; */
.data : AT(load_addr) { /* .data存放在ROM中load_addr处 */
. = ALIGN(4);
__data_start = .;
*(.data)
*(.data.*)
__data_end = .; /* 用于重定向的时候操作标志符号 */
} > RAM /* 其实这里的RAM其实就相当于指定了运行地址.相当于startaddr */
.bss : { /* 同.data,紧挨着存放 */
. = ALIGN(4);
__bss_start = .;
*(.bss)
*(.COMMON)
__bss_end = .;
} > RAM
}
在链接器脚本中,PHDRS 命令用于定义程序头表(Program Header Table)。程序头表描述了如何将 ELF 文件映射到内存中,并包含了段的属性信息,如段的起始地址、长度、权限等。通过使用 PHDRS 命令,您可以定义多个程序头表条目,从而控制段的加载方式。
PHDRS 命令的基本语法如下:
PHDRS
{
NAME TYPE [ FILEHDR ] [ PHDRS ] [ AT ( ADDRESS ) ] [ FLAGS ( FLAGS ) ] ;
}
其中FILEHDR、PHDRS、AT、FLAGS为关键字。
NAME:为程序段名,此名字可以与符号名、section 名、文件名重复,因为它在一个独立的名字空间内。此名字只能在 SECTIONS 命令内使用;一个程序段可以由多个可加载的 section 组成。通过输出 section 描述的属性:PHDRS 可以将输出 section 加入一个程序段,: PHDRS 中的 PHDRS 为程序段名。在一个输出 section 描述内可以多次使用 :PHDRS 命令,也即可以将一个 section 加入多个程序段。如果在一个输出 section 描述内指定了 :PHDRS 属性,那么其后的输出 section 描述将默认使用该属性,除非它也定义了 :PHDRS 属性。显然当多个输出 section 属于同一程序段时可简化书写;
FILEHDR:在 TYPE 属性后存在 FILEHDR 关键字,表示该段包含 ELF 文件头信息;
PHDRS:表示该段包含 ELF 程序头信息;
TYPE:TYPE 可以是以下八种形式:
PT_NULL(0) :表示未被使用的程序段
PT_LOAD(1) :表示该程序段在程序运行时应该被加载
PT_DYNAMIC(2) :表示该程序段包含动态连接信息
PT_INTERP(3) :表示该程序段内包含程序加载器的名字,在 Linux 下常见的程序加载器是 ld-linux.so.2
PT_NOTE(4) :表示该程序段内包含程序的说明信息
PT_SHLIB(5) :一个保留的程序头类型,没有在 ELF ABI 文档内定义
PT_PHDR(6) :表示该程序段包含程序头信息。
EXPRESSION:表达式值,以上每个类型都对应一个数字,该表达式定义一个用户自定的程序头。
AT(ADDRESS) :定义该程序段的加载位置(LMA),该属性将覆盖该程序段内的 section 的 AT() 属性;
FLAGS:链接器通常会基于组成段的节来设置段属性。你可以通过使用 FLAGS 关键字来显式指定段标志。 FLAGS 的值必须是一个整型值。它被用来设置程序头的 p_flags域;
下面是一个关于 PHDRS 的例子。它展示一个在纯 ELF 系统上的一个标准的程序头设置。
PHDRS
{
headers PT_PHDR PHDRS ;
interp PT_INTERP ;
text PT_LOAD FILEHDR PHDRS ;
data PT_LOAD ;
dynamic PT_DYNAMIC ;
}
SECTIONS
{
. = SIZEOF_HEADERS;
.interp : { *(.interp) } :text :interp
.text : { *(.text) } :text
.rodata : { *(.rodata) } /* defaults to :text */
…
. = . + 0×1000; /* move to a new page in memory */
.data : { *(.data) } :data
.dynamic : { *(.dynamic) } :data :dynamic
…
}
这个示例定义了一个自定义的程序头(Program Header)布局,并展示了如何将特定的节(sections)映射到这些程序头中。下面是对脚本的详细解析:
PHDRS 命令
PHDRS 命令用于定义程序头表中的条目,这些条目将被用在 ELF 程序的程序头表中。在这个例子中,定义了以下几种类型的程序头:
headers: 一个特殊的程序头,指向程序头表自身。interp: 用于动态链接的程序,指向程序的解释器(通常是 ld.so)。text: 包含程序的文本(代码)部分。data: 包含程序的初始化和未初始化数据部分。dynamic: 包含动态链接信息。SECTIONS 命令
SECTIONS 命令定义了程序的内存布局和各个节的属性。
. = SIZEOF_HEADERS;: 设置当前位置计数器(.)为头部大小,这是所有节的起始位置。
.interp: 定义了 .interp 节,它包含了程序解释器的路径。这个节被映射到 :text 和 :interp 程序头中。:text 表示它与 text 程序头相关联,:interp 是自定义的程序头。
.text: 定义了 .text 节,包含了程序的可执行代码,并映射到 :text 程序头。
.rodata: 定义了 .rodata 节,包含了只读数据。默认情况下,它也映射到 :text 程序头。
接下来的代码 . = . + 0x1000; 将位置计数器增加 0x1000 字节,这通常是为了在内存中移动到新的一页,确保 .data 节按照页对齐。
.data: 定义了 .data 节,包含了初始化的全局变量和静态变量,并映射到 :data 程序头。
.dynamic: 定义了 .dynamic 节,包含了动态链接信息,并映射到 :data 和 :dynamic 程序头。:dynamic 是自定义的程序头,用于指定包含动态链接信息的段。
程序头的映射
:TEXT, :DATA: 这些是伪程序头名称,用于将节映射到程序头。:TEXT 通常与代码相关,:DATA 与数据相关。:interp 和 :dynamic 是在这个脚本中自定义的程序头名称,它们通过 PHDRS 命令定义,并在 SECTIONS 命令中使用。这个链接脚本通过 PHDRS 定义了程序头的布局,并通过 SECTIONS 将特定的节映射到这些程序头中。自定义的程序头名称允许更细粒度的控制程序的加载和执行。例如,自定义的 :interp 程序头可以用于指定解释器的加载位置,而 :dynamic 程序头可以用于指定动态链接信息的加载位置。
在链接器脚本中,PROVIDE 命令是一个非常有用的指令,它用于在链接过程中提供全局符号。PROVIDE 命令允许您在链接器脚本中定义全局符号的值,这些符号可以在程序的其他部分引用。这对于解决某些符号未定义的情况特别有用,或者用于定义一些全局变量的默认值。PROVIDE 命令的基本语法如下:
PROVIDE ( symbol = value );
这里,symbol 是您要定义的全局符号,value 是该符号的初始值。PROVIDE 命令会在链接过程中为该符号提供一个定义,即使在其他地方没有定义该符号。
PROVIDE 命令的特点:
覆盖规则:
PROVIDE 命令提供的定义会被忽略。PROVIDE 提供的定义就会生效。灵活性:
PROVIDE 命令可以用来提供默认值或作为备用定义。PROVIDE 是一个理想的选择。全局可见性:
PROVIDE 命令定义的符号在整个链接过程中都是全局可见的。PROVIDE 命令的使用场景:
提供全局变量的默认值:
PROVIDE 指令可以在链接器脚本中为这个变量提供一个默认的地址(或说是“定义”),这样即使源代码中没有显式定义这个变量,链接也能成功进行。这个地址通常指向某个内存位置,该位置的内容将作为该全局变量的初始值。解决未定义的符号:
PROVIDE,可以为这些未定义的符号指定一个默认的地址,从而避免链接错误。然而,需要注意的是,PROVIDE 通常用于变量,而对于函数,通常需要使用其他机制(如链接器脚本中的 ENTRY 指令或编译器提供的弱函数定义)来提供默认的实现。内存布局的控制:
PROVIDE 可以用来指定全局变量或特定内存区域的地址。这有助于确保数据或代码被放置在内存中的预期位置,这对于满足硬件要求或优化性能至关重要。PROVIDE 提供的地址通常是一个占位符,它告诉链接器在找不到符号定义时使用该地址。但是,如果链接器在后续的链接过程中找到了该符号的实际定义,它将使用实际定义中的地址,而不是 PROVIDE 指定的地址。这种机制允许开发者在需要时覆盖默认设置。
下面让我们通过一个示例说明 PROVIDE 的作用:
test.c 源文件:
#include
extern int my_global_var;
void init(void) {
/* 定义一个指向该地址的指针 */
volatile int* ptr = &my_global_var;
/* 通过指针写入值 100 */
*ptr = 0x64; // 现在,地址处的值被设置为 0x64
}
int main(void)
{
init();
printf("Value of my_global_var: %d\n", my_global_var);
return 0;
}
使用 ld -verbose > test.lds 把编译器默认的链接脚本输出到 test.lds 文件,修改链接脚本 (test.lds),增加 PROVIDE(my_global_var = .); 用于定义全局符号 my_global_var,test.lds 链接脚本文件部分内容如下:
.data :
{
PROVIDE(my_global_var = .); /* 新增使用PROVIDE定义 my_global_var 全局符号 */
*(.data .data.* .gnu.linkonce.d.*)
SORT(CONSTRUCTORS)
}
通过如下命令编译运行程序,如下:
gcc -O0 test.c -T test.lds -o test -g -Wl,-Map=test.map
这个命令使用 GCC 编译器,指定了优化级别为 0(-O0),链接器脚本为 test.lds,输出文件为 test,启用了调试信息(-g),并生成了一个映射文件 test.map(通过 -Wl,-Map=test.map 传递给链接器)。运行结果如下:
[root@localhost provider]# ls
test test.c test.lds test.map
[root@localhost provider]# cat test.map | grep my_global_var
0x0000000000601020 PROVIDE (my_global_var = .)
[root@localhost provider]# ./test
Value of my_global_var: 100
通过 test.map 文件可知 my_global_var 被分配到了地址 0x0000000000601020,当运行程序时,init 函数被调用,它修改了 my_global_var 的值为 100(十六进制表示为 0x64)。然后,main 函数打印出这个值,与预期相符。
这个程序成功地使用了链接器脚本中的 PROVIDE 指令来定义一个全局变量 my_global_var,并在运行时通过指针修改了这个变量的值。展示了如何在没有显式在源代码中分配内存的情况下,通过链接器脚本来定义全局变量的地址,并在程序中通过指针来访问和修改这个变量的值。
注意:经过测试,实际上不加
PROVIDE关键字,在链接文件中直接定义的变量(符号)也可以在目标文件中直接使用。在链接文件中直接定义变量与加PROVIDE关键字区别如下:
可见性和强制性:直接在链接脚本中定义符号是强制性的,它会在链接脚本的当前位置创建一个符号。而
PROVIDE则是可选的,它只在需要时才“提供”符号,如果链接器在其他地方找到了这个符号的定义,它就不会使用PROVIDE提供的地址。灵活性:
PROVIDE提供了更高的灵活性,因为它允许链接器在需要时“填补”符号的空白,而不是强制在链接脚本的某个具体位置定义它。用途:直接在链接脚本中定义符号通常用于指定内存布局中的固定点,如段的起始地址。而
PROVIDE则更适用于处理可选的或条件性的符号定义,以避免链接错误。因此,在选择使用哪种方式时,你需要根据你的具体需求来决定。如果你需要确保某个符号在链接脚本的特定位置被定义,那么直接在链接脚本中定义它可能是更好的选择。如果你希望链接器能够更灵活地处理符号的存在与否,那么使用
PROVIDE可能更合适。
REGION_ALIAS 命令用于在链接器脚本中为已定义的内存区域创建别名,使得在链接器脚本中可以使用更有意义的名字来引用这些区域。这样做的好处包括提高脚本的可读性、可维护性,并简化脚本的编写。REGION_ALIAS 的基本语法如下:
REGION_ALIAS("别名", 已定义的内存区域);
MEMORY 块中定义的内存区域名称。下面是一个详细的示例,展示了如何使用 REGION_ALIAS 来定义别名,并在脚本中引用这些别名。
链接脚本 test.lds:
MEMORY
{
RAM : ORIGIN = 0, LENGTH = 4M
}
SECTIONS
{
.text :
{
*(.text)
} > RAM
.rodata :
{
*(.rodata)
rodata_end = .;
} > RAM
.data : AT (rodata_end)
{
data_start = .;
*(.data)
} > RAM
data_size = SIZEOF(.data);
data_load_start = LOADADDR(.data);
.bss :
{
*(.bss)
} > RAM
}
这个里面,我们定义了一个内存区域,叫做 RAM;上面的链接脚本,所有的东西都被 Layout 到 RAM 中;试想一下,如果现在需要将 .text 和 .rodata 节放到另一个内存区域 ROM,岂不是要将每个需要放到 ROM 中的节后的 > RAM 都修改一遍?这里只修改两处内容,改起来工作量还好,如果需要修改更多处位置呢?每次改起来岂不是很麻烦!
假如我们使用 REGION_ALIAS 定义了 4 个别名:REGION_TEXT、REGION_RODATA、REGION_DATA、REGION_BSS;并在 SECTIONS 中,引用这些别名,可以使得我们的链接脚本则会更加健壮!修改后的链接脚本 test.lds 如下:
MEMORY
{
RAM : ORIGIN = 0, LENGTH = 4M
}
REGION_ALIAS("REGION_TEXT", RAM);
REGION_ALIAS("REGION_RODATA", RAM);
REGION_ALIAS("REGION_DATA", RAM);
REGION_ALIAS("REGION_BSS", RAM);
SECTIONS
{
.text :
{
*(.text)
} > REGION_TEXT
.rodata :
{
*(.rodata)
rodata_end = .;
} > REGION_RODATA
.data : AT (rodata_end)
{
data_start = .;
*(.data)
} > REGION_DATA
data_size = SIZEOF(.data);
data_load_start = LOADADDR(.data);
.bss :
{
*(.bss)
} > REGION_BSS
}
如果使用这种方式,就不用每次都修改各个节后的 > REGION_XXX,仅直接改这个存储描述文件的如下部分即可:
MEMORY
{
ROM : ORIGIN = 0, LENGTH = 3M
RAM : ORIGIN = 0x10000000, LENGTH = 1M
}
REGION_ALIAS("REGION_TEXT", ROM);
REGION_ALIAS("REGION_RODATA", ROM);
REGION_ALIAS("REGION_DATA", RAM);
REGION_ALIAS("REGION_BSS", RAM);
SECTIONS 中的内容则无需任何修改,这样当链接脚本内容较多时,工作量是不是比原来小多了?
通过使用 REGION_ALIAS,您可以使链接器脚本更加简洁、易读和易于维护。这对于大型项目尤其重要,因为良好的组织结构可以显著减少错误并提高开发效率。REGION_ALIAS 使得脚本更加模块化和灵活,从而提高了开发者的生产力。
HIDDEN 命令用于将符号的可见性设置为隐藏,这样符号就只在本模块内可见,不会暴露给外部模块。这在控制符号范围和避免命名冲突时非常有用。当我们说 HIDDEN (symbol = expression) 时,这意味着我们正在定义一个隐藏的符号,并为其赋值。下面我们将详细介绍 HIDDEN 命令的使用方式,并通过具体例子来说明其应用。语法如下:
HIDDEN (symbol_name)
symbol_name:要隐藏的符号名称。expression:为符号赋值的表达式。HIDDEN 命令的作用:
HIDDEN 命令定义的符号在最终的输出文件中是不可见的,这意味着外部代码无法直接访问这些符号。示例如下:
SECTIONS
{
.text : {
HIDDEN(hidden_symbol = .);
*(.text)
HIDDEN(hidden_end = .);
} > FLASH
}
在这个例子中:hidden_symbol 和 hidden_end 是隐藏的符号,只在本模块内可见。
PROVIDE_HIDDEN 命令同 PROVIDE,区别是 PROVIDE 定义的符号是全局符号,PROVIDE_HIDDEN 定义的符号只在本脚本中可见,PROVIDE_HIDDEN 结合了 PROVIDE 和 HIDDEN 的功能,用于有条件地定义一个隐藏的符号。如果符号在其他地方已经定义,则不会重新定义它。语法如下:
PROVIDE_HIDDEN(symbol = expression);
symbol 是符号的名称。expression 是要赋给符号的值。示例如下:
SECTIONS
{
.text : {
PROVIDE_HIDDEN(__hidden_start = .);
*(.text)
PROVIDE_HIDDEN(__hidden_end = .);
} > FLASH
}
在这个例子中,__hidden_start 和 __hidden_end 将在没有其他定义的情况下被赋值,并且这些符号是隐藏的,只在本模块内可见。
KEEP 命令用于在链接过程中保留某些符号或节,即使它们看起来不是必需的也会被包含在最终的输出文件中。这通常用于保留调试信息、未使用的代码节或特殊配置项等。KEEP 命令的基本语法如下:
KEEP (expression)
expression:需要保留的符号或节的表达式。KEEP 命令通常用于以下场景:
当你使用 GCC(或类似的编译器)并希望启用链接器节(section)垃圾收集(-Wl,--gc-sections)来优化最终的可执行文件或库大小时,你可能会希望保留某些特定的节或符号。示例如下:
源文件 test.c :
#include
// 初始化函数,通常在程序启动时调用
void __attribute__((constructor)) init_func(void) {
printf("Initialization function called.\n");
}
// 不常使用的函数,可能会被编译器优化掉
void unused_func(void) {
printf("This function is not often used.\n");
}
int main(void) {
printf("Main function called.\n");
return 0;
}
链接脚本 linker.lds:
ENTRY(_start)
SECTIONS
{
. = 0x2000;
.rela.plt :
{
*(.rela.plt)
}
. = 0x1000;
.text . : { *(.text) }
.data . : { *(.data)}
.bss : { *(.bss) }
_bss_end = (. + 0x20000 - 1) / 0x20000 * 0x20000;
__init_array_start = .;
__init_array_end = .;
/DISCARD/ : {*(.note.*)}
}
基于上面代码和链接脚本,编译生成可执行文件如下:
[root@localhost keep]# gcc -O2 -ffunction-sections -fdata-sections -o test test.c -Wl,--gc-sections -Tlinker.lds
/usr/bin/ld: warning: .note.gnu.build-id section discarded, --build-id ignored.
[root@localhost keep]# readelf -s test | grep unused_func
在上面编译命令中:
-O2 启用了优化,这可能会导致未使用的函数被优化掉。-ffunction-sections 和 -fdata-sections 选项告诉编译器将每个函数和变量分别放入自己的节中,这样链接器就可以单独地对它们进行垃圾收集。-Wl,--gc-sections 启用了链接器的垃圾收集功能。-Tlinker.lds 指定了链接脚本。紧接着,在生成的可执行文件 test 中检索函数符号 unused_func ,发现并未包含其中,可见使用 -O2 编译选项确实导致未使用的函数被优化掉了。如果我不想让 unused_func 函数被优化掉,该怎么办呢?这就得使用我们这里提到的 KEEP 命令了。让我们修改链接脚本和源码文件。
修改后的 linker.lds:
ENTRY(_start)
SECTIONS
{
. = 0x2000;
.rela.plt :
{
*(.rela.plt)
}
. = 0x1000;
.text . : { *(.text) }
/* 保留未使用的函数 */
.text_unused :
{
KEEP(*(.text_unused))
}
.data . : { *(.data)}
.bss : { *(.bss) }
_bss_end = (. + 0x20000 - 1) / 0x20000 * 0x20000;
__init_array_start = .;
__init_array_end = .;
/DISCARD/ : {*(.note.*)}
}
在这个链接脚本中,我们创建了一个名为 .text_unused 的新节,并使用 KEEP 命令来保留其中的符号。在 C 代码中,我们将 unused_func 函数标记为放在 .text_unused 节中。
修改后的 test.c:
#include
// 初始化函数,通常在程序启动时调用
void __attribute__((constructor)) init_func(void) {
printf("Initialization function called.\n");
}
// 不常使用的函数,可能会被编译器优化掉
void __attribute__((section(".text_unused"))) unused_func(void) {
printf("This function is not often used.\n");
}
int main(void) {
printf("Main function called.\n");
return 0;
}
在这个修改后的 C 代码中,我们使用 __attribute__((section(".text_unused"))) 将 unused_func 函数放入 .text_unused 节中,这样链接脚本中的 KEEP 命令就可以保留这个函数。
编译时,我们需要确保 C 代码中的函数被放置到正确的节中,并且使用链接脚本来控制最终的二进制文件。
[root@localhost keep]# gcc -O2 -ffunction-sections -fdata-sections -o test test.c -Wl,--gc-sections -Tlinker.lds
/usr/bin/ld: warning: .note.gnu.build-id section discarded, --build-id ignored.
[root@localhost keep]# ls
linker.lds test test.c test.map
[root@localhost keep]# readelf -s test | grep unused_func
52: 00000000000011d0 10 FUNC GLOBAL DEFAULT 8 unused_func
紧接着,在生成的可执行文件 test 中检索函数符号 unused_func ,发现包含其中,说明我们的策略生效了,KEEP 命令在链接过程中保留了我们的节和其中的符号。通过这种方式,即使启用了垃圾收集,unused_func 函数也会被保留在最终的二进制文件中。
LOADADDR 是一个内置函数,用于获取指定节的加载地址,这个地址是节在程序内存映射中的位置,而不是它在可执行文件中的位置。这个函数非常有用,特别是在需要计算节的大小或者在节之间需要保持某种特定关系的时候。与 AT 不同的是,LOADADDR 不用于指定加载地址,而是获取已经设置的加载地址。LOADADDR 命令的基本语法如下:
LOADADDR(section)
section:是节的名称,例如 .text、.data 或者用户定义的节。。【拓展:加载地址与运行地址】
加载地址:加载器决定将程序加载到内存的哪个位置。这个位置是程序在内存中的起始地址,称为加载地址。 运行地址:程序在内存中实际执行时的地址。在没有地址空间布局随机化( ASLR)的情况下,运行地址通常与加载地址相同。
假设我们有一个嵌入式系统的应用程序,我们希望 .text 节加载到特定的内存地址,比如 0x08000000。我们可以使用 LOADADDR 来获取这个地址:
MEMORY //定义存储区
{
ROM (rx) : ORIGIN = 0x08000000, LENGTH = 2M
RAM (rw) : ORIGIN = 0X30000000 , LENGTH = 64M
}
ENTRY(_start) //开始地址,这个不一定正确
SECTIONS
{
. = 0; //程序起始地址
.text : AT(ROM) { *(.text) } > RAM
load_addr = LOADADDR(.text) + SIZEOF(.text); //计算当前的加载地址, 相当于load_addr = .;
.data : AT(load_addr) { //.data存放在ROM中load_addr处
. = ALIGN(4);
__data_start = .;
*(.data)
*(.data.*)
__data_end = .; //用于重定向的时候操作标志符号
} > RAM //其实这里的RAM其实就相当于指定了运行地址.相当于startaddr
.bss : { //同.data,紧挨着存放
. = ALIGN(4);
__bss_start = .;
*(.bss)
*(.COMMON)
__bss_end = .;
} > RAM
}
在这个例子中,LOADADDR 用于创建一个符号 load_addr,该符号代表了 .data 节的加载地址。这个符号可以在程序中使用,例如,用于初始化代码,或者在启动时将数据从 ROM 复制到 RAM。
LOADADDR 是链接脚本中的一个有用工具,它可以帮助开发者在复杂的内存布局中管理和引用节的加载地址。通过在链接脚本中使用 LOADADDR,可以确保程序的各个部分被加载到预期的内存位置。
在链接脚本中,ALIGN 命令用于确保节(section)的内容在内存中按照特定的边界对齐。对齐可以提高内存访问的效率,因为许多处理器在访问对齐的内存地址时会有更快的访问速度。此外,一些硬件平台可能要求特定的数据结构必须对齐到特定的边界。ALIGN 命令的基本语法如下:
. = ALIGN(value);
. 是一个特殊的符号,代表当前节的地址。value 是一个整数,表示对齐的边界。这个值通常是 2 的幂次方,如 4、8、16、32等。ALIGN 命令的作用是将当前位置计数器,即. 调整到最接近的、大于当前地址的 value 的倍数。这样,接下来的数据或代码将从这个对齐的地址开始。
假设你有一个链接脚本,你希望确保 .data 节的内容在 8 字节边界上对齐:
SECTIONS
{
.data :
{
*(.data)
. = ALIGN(8);
*(.data.*)
} > RAM
}
在这个例子中,. = ALIGN(8); 命令确保 .data 节的内容在 8 字节边界上对齐。这意味着,即使 .data 节中的数据大小不是 8 的倍数,链接器也会在节的末尾添加足够的填充(padding),以确保下一个数据或代码段从 8 的倍数地址开始。
ALIGN 命令是链接脚本中的一个有用工具,它允许开发者在内存中精确控制节的对齐。这有助于优化程序的性能,同时确保程序符合硬件平台的要求。然而,使用 ALIGN 命令时需要考虑对齐带来的内存使用增加,以及对齐值对性能的实际影响。
在链接脚本中,FILL 命令用于在指定的输出节中插入填充字节。这通常用于确保节之间的空间或者在特定的地址范围内创建一个特定的模式。FILL 命令的基本语法如下:
FILL(value)
value 是一个表达式,表示要填充的字节值。如果 value 是单个字节(8位),则可以是一个介于 0 和 255 之间的整数。如果需要填充多字节值,可以使用 {long} 语法来指定一个长整型数。假设你想要在 .data 节和 .bss 节之间插入 32 字节的填充,你可以在链接脚本中这样写:
SECTIONS
{
.data :
{
*(.data)
} >RAM
/* 插入32字节的填充 */
FILL(32) >RAM
.bss :
{
*(.bss)
} >RAM
}
在这个例子中,FILL(32) 命令会在 .data 节和 .bss 节之间创建 32 字节的填充。填充的值默认为 0,除非你指定了其他值。
FILL 命令是链接脚本中的一个有用工具,它允许你在输出文件的特定位置插入填充字节。这可以用于内存对齐、创建特定的内存模式或者简单地分隔不同的节。使用 FILL 命令时,需要确保你了解填充的用途和目标平台的内存布局要求。
在链接脚本中,/DISCARD/ 是一个特殊的节,它用于指示链接器应该丢弃所有分配给这个节的内容。任何放入 /DISCARD/ 节的内容都不会被包含在最终的输出文件中,相当于被“丢弃”了。
/DISCARD/ 节通常用于以下几种情况:
移除未使用的符号: 如果链接器在进行垃圾收集(garbage collection)时需要丢弃未使用的符号,可以将这些符号放入 /DISCARD/ 节。
移除调试信息: 为了减小最终二进制文件的大小,可以将所有的调试信息(如 .debug、.line 等节)放入 /DISCARD/ 节。
移除注释: 如果不需要保留注释信息(如 .comment 节),也可以将其放入 /DISCARD/ 节。
移除特定节: 有时候,你可能想要丢弃特定的节,比如 .note 节或者其他任何不需要的节。
以下是一个链接脚本的示例,展示了如何使用 /DISCARD/ 节:
SECTIONS
{
.text : {
*(.text)
}
.data : {
*(.data)
}
.bss : {
*(.bss)
}
/* 丢弃所有调试信息 */
/DISCARD/ : {
*(.debug*)
*(.note*)
*(.comment)
}
}
在这个例子中,所有以 .debug、.note 和 .comment 开头的节都会被放入 /DISCARD/ 节,因此它们不会出现在最终的输出文件中。
注意:
使用 /DISCARD/时,确保你不会意外地丢弃需要的内容。在某些情况下,你可能想要保留调试信息或其他特殊节,因此在使用 /DISCARD/时要谨慎。/DISCARD/节通常与其他链接脚本命令结合使用,以实现更复杂的链接逻辑。
/DISCARD/ 是链接脚本中的一个有用工具,它允许你控制哪些内容应该被包含在最终的输出文件中,哪些应该被丢弃。这可以用于优化输出文件的大小,或者在不需要某些信息时移除它们。在使用 /DISCARD/ 时,应该仔细考虑哪些内容是真正不需要的,以避免意外地丢弃重要信息。
在链接脚本中,ASSERT 命令用于在链接时检查某个条件是否为真。如果条件为假(即检查失败),链接器会报错并停止链接过程。这通常用于确保程序的内存使用不超过特定限制,或者确保某些符号在预期的地址范围内。ASSERT 命令的一般语法如下:
ASSERT(expression, message);
expression 是一个在链接时评估为真或假的表达式。message 是一个字符串,当表达式评估为假时,链接器会显示这个消息。示例如下:
ASSERT(_end <= 0x20008000, "Not enough RAM");
这行命令的意思是:
_end 通常是程序中最后一个使用的内存地址的符号,它由链接器在处理 .bss、.data 等节后自动计算得出。0x20008000 是一个十六进制数,表示一个内存地址,这里假设是 RAM 的最大地址。ASSERT 命令检查 _end 是否小于或等于 0x20008000。如果是,条件为真,链接过程继续。如果不是,条件为假,链接器会报错,并显示消息 "Not enough RAM"。这个 ASSERT 命令的作用是确保程序的总内存使用量不超过 RAM 的大小。如果程序的末尾地址 _end 超过了 RAM 的最大地址 0x20008000,这意味着程序需要的内存超出了可用的 RAM,链接器会报错,提示内存不足。
ASSERT 命令在链接脚本中用于条件检查,可以帮助确保程序的内存布局符合预期。
在链接脚本中,EXTERN 命令用于声明外部符号,这些符号在链接过程中需要被解析,但它们的定义不在当前的链接脚本或对象文件中。通常,这些外部符号会在其他对象文件或库中定义,或者在程序的其他部分定义。EXTERN 命令的基本语法如下:
EXTERN symbol [, symbol ...];
symbol 是一个或多个要在链接过程中解析的外部符号的名称。EXTERN 命令的作用是告诉链接器,即使在当前的链接单元中没有定义这些符号,也应该在链接过程中保留这些符号。
假设你有一个全局变量 global_var 和一个函数 global_func,它们在另一个源文件或库中定义。你可以在链接脚本中这样声明它们:
EXTERN global_var;
EXTERN global_func;
这样,链接器在处理链接脚本时会知道 global_var 和 global_func 是外部符号,需要在链接过程中解析。可能有人会思考,一般这种不是需要在源文件中用 extern 声明吗?源文件中用 extern 声明了,为什么还要在链接脚本中用 EXTERN ?
因为在某些情况下,即使全局变量或函数在源代码中被声明为 extern,链接器在处理多个对象文件和库时可能会因为优化而移除未引用的符号。在链接脚本中使用 EXTERN 可以确保这些符号在链接过程中被保留。
EXTERN 命令是链接脚本中的一个有用工具,它允许你在链接过程中声明和保留外部符号。这在处理大型项目或使用外部库时尤其重要,因为它确保了所有必要的符号都能被正确解析。
在链接脚本中,INCLUDE 命令用于包含另一个链接脚本文件的内容。这使得链接脚本的编写更加模块化,允许将复杂的链接逻辑分散到多个文件中,从而提高可读性和可维护性。
INCLUDE 命令的基本语法如下:
INCLUDE "filename"
或
INCLUDE
filename 是要包含的链接脚本文件的名称。如果文件名用双引号包围,它会在当前目录中查找文件。如果使用尖括号,链接器会在标准目录中查找文件。INCLUDE 命令的作用是将指定文件的内容插入到当前链接脚本的位置。这可以用来:
重用代码:将常用的链接脚本片段放入单独的文件中,然后在需要时包含它们。
组织复杂的链接逻辑:对于大型项目,将链接脚本分割成多个小文件,每个文件处理特定部分的链接逻辑。
条件包含:根据编译时的某些条件,包含不同的链接脚本片段。
简化维护:当链接脚本需要更新时,只需修改被包含的文件,而不必修改主链接脚本。
假设你有一个名为 memory.ld 的文件,它定义了内存布局:
/* memory.ld */
MEMORY
{
FLASH (rx) : ORIGIN = 0x08000000, LENGTH = 512K
RAM (rwx) : ORIGIN = 0x20000000, LENGTH = 256K
}
你可以在主链接脚本中包含这个文件:
/* main.ld */
INCLUDE "memory.ld"
SECTIONS
{
.text : { *(.text) } > FLASH
.data : { *(.data) } > RAM
.bss : { *(.bss) } > RAM
}
在这个例子中,memory.ld 文件的内容会被插入到 INCLUDE 命令的位置,从而定义了内存布局。
注意:
确保被包含的文件存在并且路径正确。 如果被包含的文件名包含空格或特殊字符,确保使用正确的引用方式。 INCLUDE命令不仅限于包含其他链接脚本文件,也可以用于包含其他文本文件,只要这些文件的内容是有效的链接脚本命令。
INCLUDE 命令是链接脚本中的一个重要工具,它允许你将链接逻辑分散到多个文件中,使得链接脚本更加清晰和易于管理。通过使用 INCLUDE,你可以创建更加模块化的链接脚本,提高构建过程的可维护性和可扩展性。
SEARCH_DIR 命令在链接脚本中用于添加链接器搜索库文件的目录。这个命令告诉链接器在哪些额外的路径中查找需要链接的库文件。这与在命令行中使用 -L 选项指定库文件搜索路径是等效的。SEARCH_DIR 命令基本语法如下:
SEARCH_DIR("path");
path 是要添加到链接器搜索路径中的目录路径。SEARCH_DIR 命令的作用是扩展链接器的库文件搜索路径。这对于以下情况很有用:
SEARCH_DIR 来指定库文件的位置。SEARCH_DIR 可以在主链接脚本中统一指定库文件的搜索路径。SEARCH_DIR,可以避免在命令行中每次都指定这些路径。假设你的库文件位于 /opt/mylibs 目录下,你可以在链接脚本中这样使用 SEARCH_DIR:
SEARCH_DIR("/opt/mylibs");
这样,链接器在搜索库文件时,会包括 /opt/mylibs 目录。
注意:
使用 SEARCH_DIR时,确保路径是正确的,并且库文件确实存在于指定的位置。如果路径以 =开头,这通常表示该路径是一个相对路径,相对于sysroot目录。例如,SEARCH_DIR("=/usr/local/lib");会将sysroot目录下的/usr/local/lib作为搜索路径。SEARCH_DIR可以多次使用,以添加多个搜索路径。
SEARCH_DIR 是链接脚本中的一个实用命令,它允许你指定链接器在链接过程中搜索库文件的额外路径。这使得链接脚本更加灵活,能够适应不同的库文件布局和构建环境。
在链接脚本中,INPUT 命令用于显式地指定链接器应该包含哪些文件作为输入。这与在命令行上直接指定文件的方式相似,但INPUT命令允许你在链接脚本中指定这些文件,而不是在命令行上。INPUT 命令基本语法如下:
INPUT(file, ...)
INPUT(file file ...)
file 是要包含在链接过程中的文件名,可以是一个对象文件(.o)、库文件(.a 或 .so)或其他链接器输入文件。INPUT 命令的作用是告诉链接器在链接过程中包含指定的文件。这可以用来确保特定的文件被包含在最终的输出文件中,即使它们没有被程序的其他部分直接引用。
假设你有一个链接脚本,你想要确保特定的对象文件 myobject.o 和库文件 mylib.a 被包含在链接过程中:
INPUT("myobject.o" "mylib.a")
在这个例子中,myobject.o 和 mylib.a 将被链接器作为输入文件处理,即使在命令行中未直接指定链接该文件。
注意:
INPUT命令通常用于确保即使某些文件中的符号未被引用,它们也会被包含在最终的输出文件中。如果文件名包含空格或特殊字符,可以使用双引号将文件名括起来。 INPUT命令可以与GROUP命令结合使用,后者用于处理库文件,确保只有在实际需要时才包含库文件中的符号。
INPUT 命令是链接脚本中的一个有用工具,它允许你在链接脚本中指定输入文件,而不是在命令行上。这可以提高链接过程的可配置性和灵活性,特别是在复杂的构建系统中。
在链接脚本中,OUTPUT 命令用于指定生成的输出文件的名称。这个命令对于重写默认的输出文件名(通常是 a.out)或者当你想要明确指定输出文件名时非常有用。OUTPUT 命令基本语法如下:
OUTPUT("filename")
"filename" 是你想要为输出文件指定的名称,包括扩展名。如果文件名包含空格或特殊字符,必须使用双引号。OUTPUT 命令的作用是告诉链接器输出文件应该使用指定的名称。如果不使用 OUTPUT 命令,链接器会使用默认的输出文件名,这通常是 a.out,或者如果你在命令行上使用了 -o 选项,那么会使用 -o 选项后面指定的名称。
假设你有一个链接脚本 mylink.lds,你想要生成的可执行文件名为 myprogram:
OUTPUT("myprogram")
SECTIONS
{
.text : { *(.text) }
.data : { *(.data) }
.bss : { *(.bss) }
}
在这个例子中,链接器会生成一个名为 myprogram 的可执行文件。
注意:
OUTPUT命令通常放在链接脚本的开始部分。如果你在命令行上使用了 -o选项,那么该选项指定的文件名会覆盖链接脚本中的OUTPUT命令。OUTPUT命令只能指定一个输出文件名,如果你需要生成多个输出文件,你需要为每个文件编写单独的链接脚本。
OUTPUT 命令是链接脚本中的一个基本工具,它允许你控制生成的输出文件的名称。这对于创建具有特定名称的可执行文件或库文件非常有用,尤其是在自动化构建系统中,你可能需要确保输出文件名符合特定的命名约定。
Linker Script 是嵌入式系统和高级软件工程中不可或缺的工具,它提供了对程序内存布局的精细控制。通过 Linker Script,开发者可以精确指定程序各部分在内存中的位置,这对于内存资源有限的嵌入式系统尤为重要。Linker Script 能够优化内存使用,确保程序各部分按预定顺序加载,从而提升程序性能。它还可以帮助开发者保留关键功能,便于调试和未来的功能扩展。通过定义固定的内存布局,Linker Script 增强了代码的一致性和可维护性,确保团队成员遵循相同的规范。总体而言,Linker Script 通过优化内存布局,提高了程序的稳定性和效率,是现代软件开发中的重要组成部分。
本文仅列出部分链接脚本命令,具体详情请参见官方文档 GNU Linker。
https://ftp.gnu.org/old-gnu/Manuals/ld-2.9.1/html_chapter/ld_toc.html#TOC6
