


点击上方↑↑↑“OpenCV学堂”关注我
来源:公众号 新智元 授权
又有多少开发者曾因为频频闪烁的警报「CUDA版本必须与安装的PyTorch匹配!!!」而企图炸键盘?
无论是TensorFlow还是Pytorch,GPU和CUDA搭配的概念早已深入骨髓。
如果我说,就在昨天,有款为LLM「量身定做」的CUDA-free推理上新了!你激不激动?

原文地址:https://pytorch.org/blog/cuda-free-inference-for-llms/?hss_channel=tw-776585502606721024
那么,让我们紧跟Pytorch的官方技术博客,一探究竟!看看它是如何将「自由」变为现实!
GPU的好搭子CUDA
CUDA(Compute Unified Device Architecture)到底是何方神物?为何被视为GPU的好搭子,LLMs的「利器」?
它是由英伟达开发的用于并行计算平台和应用程序的编程API,让开发者能通过GPU开展高性能计算,包括:
1. 多个能并行处理任务的核心,实现多线程
2. 多种高效管理GPU内存的方法,如全局内存、共享内存和常量内存
3. 创建并管理多条并行线程,提高数据处理效率
4. 编译器、调试器和性能分析工具组成的工具链,,帮助开发者优化代码
简而言之,CUDA使GPU加速LLM训练变为现实,大幅缩短了训练时间。
100%的Triton内核
Pytorch最近发表了一篇技术博客,他们以两个模型——Llama3-8B和IBM的Granite-8B Code为例,100%使用Triton内核实现了FP16推理。
Granite-8B Code是由IBM开发的一种仅限解码器的代码模型,专为代码生成任务设计。
仓库地址:https://huggingface.co/ibm-granite/granite-8b-code-base-4k
值得注意的是,PyTorch指出他们实现了F16推理,也就是使用半精度浮点计算。

FP32单精度浮点数
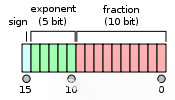
F16半精度浮点数
相对于FP32,使用FP16可以将位数减少一半,因而减少了所需内存,允许使用更大的模型或更大的批大小,且数据传输速度更快。
与F32相比,英伟达GPU提供的FP16将算术吞吐量提高了8倍,大幅加快了数学受限层的训练速度。
此外,PyTorch团队还着重强调,计算全部是依赖OpenAI的Triton语言执行的。
Triton是一种用于编写高效自定义深度学习基元的语言和编译器。
Triton的开发者致力于建立一个开源环境,以比CUDA更高效地编写代码,同时也期望它比现有的特定领域语言(domain-specific language)更具灵活性。

论文:https://www.eecs.harvard.edu/~htk/publication/2019-mapl-tillet-kung-cox.pdf
仓库:https://github.com/triton-lang/triton
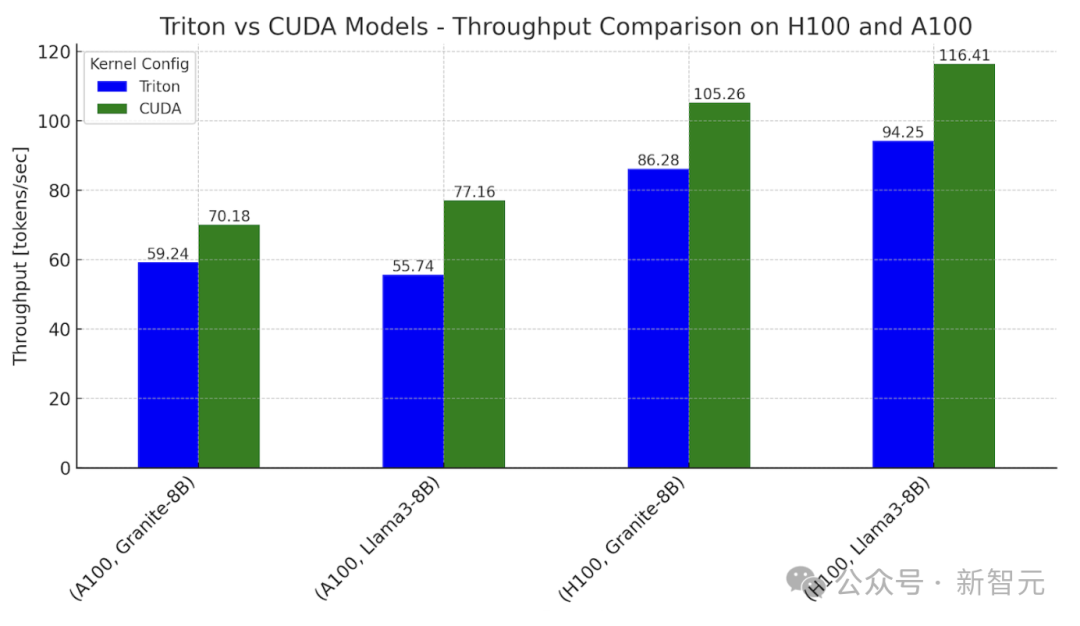
团队发现,在英伟达H100上使用Triton内核训练模型,性能可达CUDA内核的76%~78%,在A100上也能达到62%~82%。
既然相比CUDA有一定的性能损失,那为什么要全部使用Triton语言?
PyTorch团队称,Triton实现了LLM在GPU上的「可移植性」,能跨越多个不同个品牌的硬件,如英伟达、AMD、英特尔等。
此外,它还在Python中为GPU编程提供了更高的「抽象层」,使开发者有机会编写自定义的具备更高性能的内核。
最终,通过在H100和A100上使用Llama3-8B和Granite-8B的Triton和CUDA变体,并进行推理阶段的基准测试,PyTorch团队证实了,Triton内核能实现CUDA-Free的计算,且生成token的吞吐量有显著提升。
内核架构
以Llama3为例,经典的Transformer块由一般由以下部分组成:
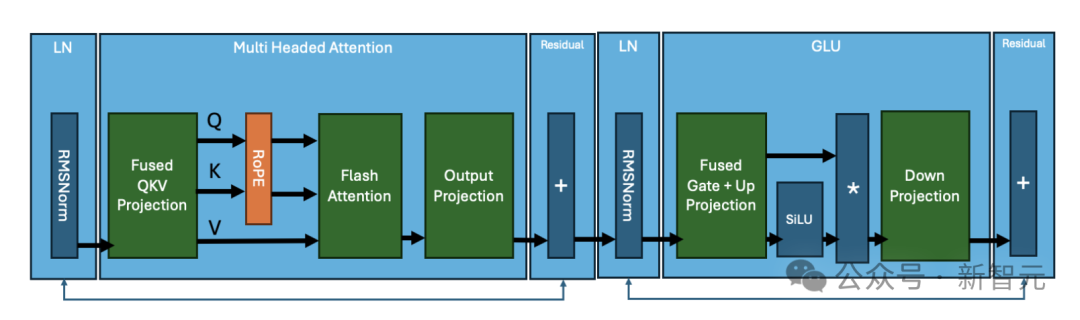
其中涉及的核心操作包括:
- RMS归一化
- 矩阵乘法:融合QKV矩阵
- 旋转位置编码(RoPE)
- Flash Attention
- 矩阵乘法:投影为为输出矩阵
- RMS归一化
- 矩阵乘法:融合门控+向上投影
- 激活函数SiLU
- 逐元素(element-wise)矩阵乘法
- 矩阵乘法:向下投影
这些操作中都需要一个或多个GPU内核进行计算,虽然不同的Transformer模型的执行细节可能有所不同,但核心操作是类似的。
例如,与Llama 3不同,IBM的Granite 8B Code模型在MLP层中使用了bias,此类更改确实需要对内核的修改。
将这些Transformer块堆叠在一起,再连接编码层,就组成了一个经典的Transformer模型。
模型推理
这些架构代码都会包含在model.py文件中,在PyTorch的eager执行模式下,C会启动CUDA内核执行这些代码。
为了让Llama3-8B和Granite-8B模型100%用Triton语言实现端到端推理,我们需要手写Triton内核(kernel),或利用torch.compile模块自动生成。
对于较小的操作,比如 RMS归一化、RoPE、SiLU函数和element-wise矩阵乘法,torch.compile可以自动生成Triton内核。
使用Nsight等工具即可对这些内核进行观察,如下图所示,自动生成的内核显示为QKV乘法和flash attention之前的深绿色方块:

使用torch.compile跟踪 Llama3-8B,显示CUDA内核
通过Nsight的跟踪信息可以观察到,在Llama3-8B中,占端到端延迟80%的两个主要操作是矩阵乘法和注意力内核,而且它们依旧由CUDA内核操作。
为了进一步提升性能,我们开始手写Triton内核来替换上述两个操作。
手写Triton内核
对于线性层中的矩阵乘法,编写一个自定义的 FP16 Triton GEMM (General Matrix-Matrix Multiply)内核,执行通用的矩阵-矩阵乘法,其中利用了SplitK进行工作分解。
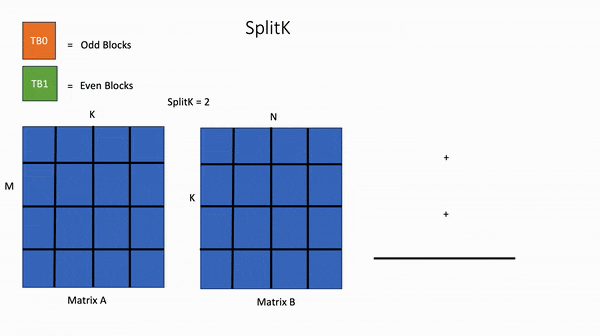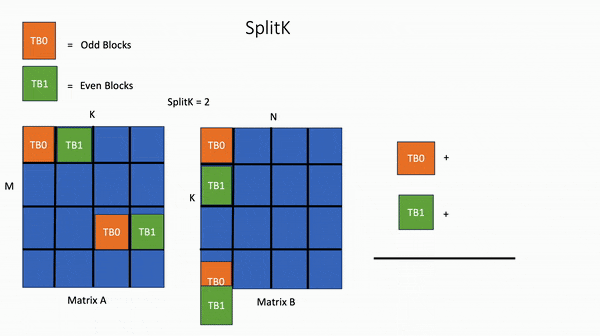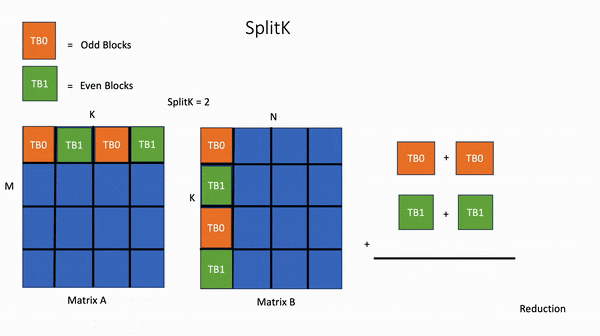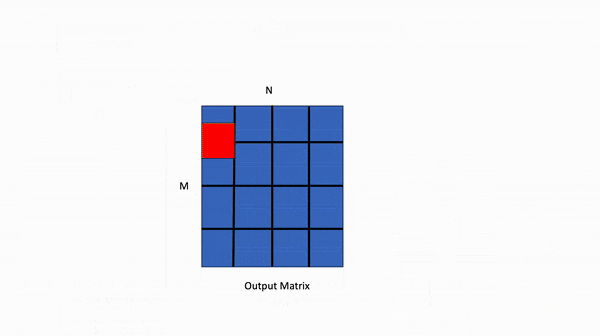
为了实现最佳性能,还使用了穷举搜索来调整SplitK GEMM内核。
因为每个线性层的权重矩阵都有不同的形状,如果要获得最佳性能,就需要针对每种矩阵形状调整Triton内核。
Granite-8B和Llama3-8B的线性层权重矩阵规格如下:

调整每个线性层后,相比未调整的Triton内核,可以实现1.2倍的端到端加速。
Triton的flash attention内核有一系列不同的配置和实现,包括:
- AMD Flash
- OpenAI Flash
- Dao AI Lab Flash
- XFormers Flash
- PyTorch FlexAttention
首先,采用eager模式,之后用torch.compile的标准方法进行编译,并对文本生成质量进行评估;

上表总结了第2~5个内核「开箱即用」时的表现。
这些结果表明,如果目标是构建一个端到端的生产级内核,那么拥有一个能跑基准测试的内核还远远不够。
后续测试中使用AMD flash attention内核,因为它可以通过torch.compile进行编译,且在eager和compile模式下都有清晰的输出。
为了满足torch.compile与AMD flash attention内核的兼容性,我们需要自定义torch运算符,主要包括以下两步:
1. 将函数包装到PyTorch自定义运算符中

2. 在运算符中添加一个FakeTensor Kernel,给定flash输入张量的形状(q、k 和 v),它可以提供一种计算flash内核输出形状的方法

将模型中的运算换为Triton的自定义内核后,就能成功地进行编译和运行,Nsight跟踪信息如下图所示:
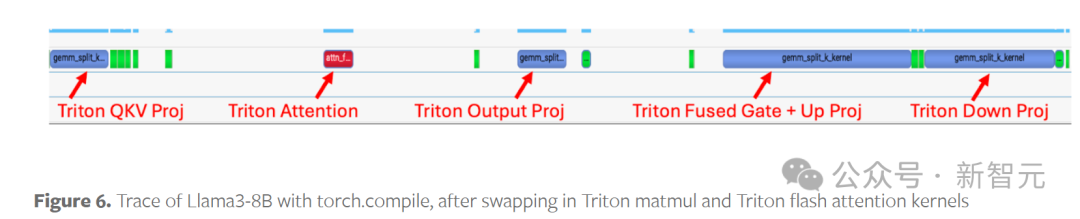
对比图5可以发现,图6就是100%使用Triton内核的前向计算。
基准测试
基准测试中使用Granite-8B和Llama3-8B模型,在英伟达H100和A100上进行单GPU运行,并定义了两种不同的配置:
Triton内核配置使用:
1. Triton SplitK GEMM
2. AMD Triton Flash Attention
CUDA 内核配置使用:
1. cuBLAS GEMM
2. cuDNN Flash Attention - 缩放点积注意力 (SDPA)
在典型的推理设置下,eager和torch编译模式的吞吐量和token间延迟如下:

批大小=2,输入序列长度=512,输出序列长度=25
Triton模型在H100上的性能最高可达CUDA模型的78%,在A100上的性能最高可达82%。两者间性能的差距可能源于矩阵乘法和flash attention的内核延迟,下一节将详细讨论。

解码延迟时间对比,输入是任意提示,批大小=1,提示长度=44
将端到端推理中的各部分进行单独对比,我们注意到以下两点:
1. Triton的matmul内核比CUDA慢1.2~1.4倍
2. AMD的Triton Flash Attention内核比CUDA SDPA慢1.6倍
这些结果表明,需要进一步提升GEMM和Flash Attention等关键原语的内核性能。
比如最近提出的FlashAttention-3、FlexAttention等工作提供了更好的方法来利用底层硬件,有希望在此基础上为Triton进一步加速。
将 FlexAttention与SDPA和AMD 的 Triton Flash内核进行比较,微基准测试结果显示,Flex有望被用于上下文更长、解码规模更大的问题场景。
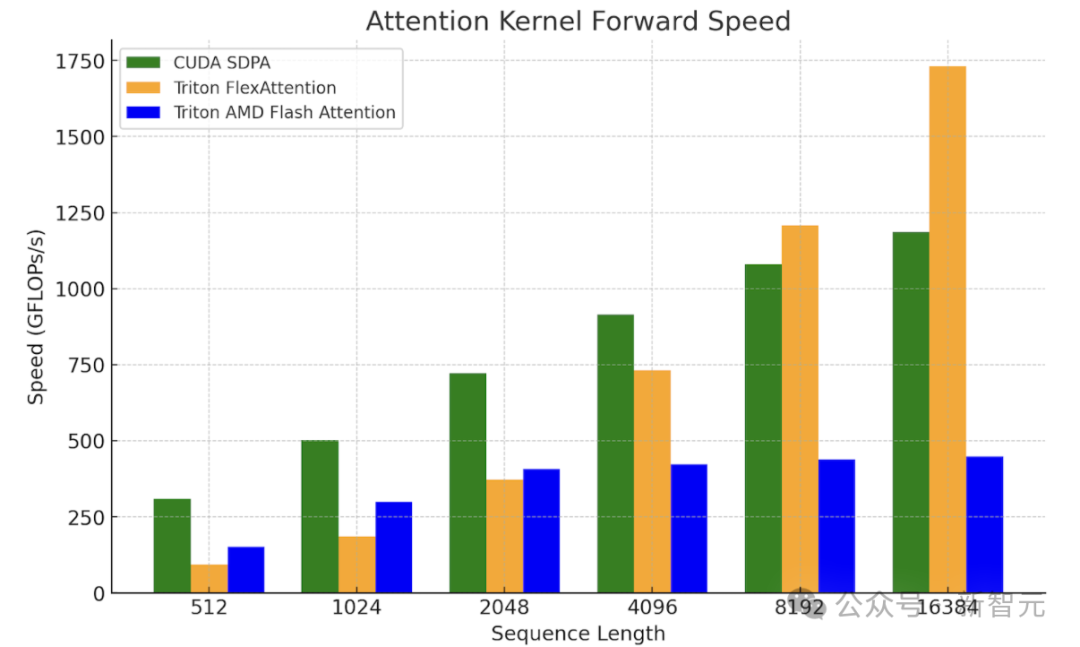
英伟达H100 SXM5 80GB上的FlexAttention内核基准测试
未来展望
接下来,我们期望进一步优化矩阵乘法(matmuls),以更充分地利用硬件。
比如使用不同的工作分解方法(类似StreamK的持久内核技术),以加快基于Triton的方法。
我们还期望继续探索FlexAttention和FlashAttention-3,进一步缩小Triton和CUDA间的差距。
以上的实验只针对FP16精度,但早前的研究表明,与cuBLAS FP8 GEMM相比,FP8 Triton GEMM内核表现更好。因此接下来的工作还会探讨端到端FP8 LLM推理。
https://pytorch.org/blog/cuda-free-inference-for-llms/?utm_content=306418723&utm_medium=social&utm_source=twitter&hss_channel=tw-776585502606721024
OpenCV4系统化学习


推荐阅读
OpenCV4.8+YOLOv8对象检测C++推理演示
ZXING+OpenCV打造开源条码检测应用
攻略 | 学习深度学习只需要三个月的好方法
三行代码实现 TensorRT8.6 C++ 深度学习模型部署
实战 | YOLOv8+OpenCV 实现DM码定位检测与解析
对象检测边界框损失 – 从IOU到ProbIOU
初学者必看 | 学习深度学习的五个误区

