


本文来自“《AI时代的网络:网络定义数据中心》”,如今,我们面临着新型数据中心的崛起:AI 云和 AI工厂,它们需要加速计算和高性能网络来支持人工智能(AI)。因此,当今的超大规模数据中心的部署格局正在发生巨大变化。随着 GPU加速计算架构的广泛应用,AI研究人员和从业者可以利用分布式加速计算的强大功能,若没有高性能网络的支持,这样大规模的高性能计算将是不可想象的。
因为数据中心进行分布式 AI模型训练和生成式 AI,这需要强大的网络连接数量众多的 GPU 节点进行计算,所以,数据中心的网络正在引领着 AI 时代的进步。
《HotChips 2024大会技术合集(1)》
《HotChips 2024大会技术合集(2)》
《HotChips 2024大会技术合集(3)》
《HotChips 2024大会技术合集(4)》
《HotChips 2024大会技术合集(5)》
《HotChips 2024大会技术合集(6)》
《HotChips 2024大会技术合集(7)》
《HotChips 2024大会技术合集(8)》
AI 是一个分布式计算问题
传统数据中心将所有计算资源(包括服务器、存储和网络)集中在供服务 一起集中使用提。对于分布式计算则是利用多个通过网络互连服务器或节点协同工作以执行任务。在此模型中,工作负载分布在各种机器上,并通过高速、低时延的网络连接在一起。
部署生成式 AI 应用程序或训练基础ChatGPT、BERT 或 DALL-E 等复杂大AI 模型需要大量的计算资源,对于模型尤其如此。随着数据量和模型大小的增加,我们采用分布式计算来应对这一挑战。它通过在多个互连的计算节点之间分配工作负载来加速训练过程。单个分布式任务的总体运行时间受最慢参与节点的运行时间所制约。
网络在确保消息及时到达所有参与节点这方面就发挥着重要作用。在这种状态下,尾部延迟(即最后参与消息的到达时间)变得非常重要,尤其是在大规模数据中心部署和存在竞争工作负载的情况下,训练大型AI模型需要越来越多的计算节点处理大量数据的情况下,需要的网络规模越大,对尾部时延的要求也就越高。
为AI构建网络
在评估数据中心采用AI 的网络架构时,应将其视为统一的端到端解决方案,并将服务分布式计算作为首要考虑因素,兼顾实现数据中心的性能、成本和价值,以及满足分布式计算所需通信库的技术需求。
无损网络与RDMA
在有损网络中,数据传输时随时可能会发生数据包丢失而导致速率下降。网络优先考虑数据传输完整性,而不是性能。为 AI 部署有损网络将在性能、GPU利用率、功耗等方面带来严重的损害。
在无损网络中,数据传输不会出现任何丢失或损坏。网络可确保所有数据包准确到达目的地,并且在传输过程中不会丢失任何信息。InfiniBand网络是原生的无损网络,一直是大规模部署的事实标准。
虽然本质上以太网是有损网络,但如今,随着在云环境中采用 GPU计算和大规模AI应用的普及,越来越多的应用在基于RDMA(RoCE)和优先级流量控制(PFC)上的融合以太网上运行,尤其是采用诸如Spectrum-X等平台让以太网实现无损网络,以太网可以成为一种实用的解决方案。
远程直接内存访问(RDMA)可通过网络实现高速、低时延远程系统内存、 的数据传输。它允许在GPU和存储之间直接传输数据,而无需涉及这些系统的CPU。在传统网络中,数据传输涉及多个步骤:首先将数据从源系统的内存复制到网络堆栈,然后通过网络发送。最后,在接收端执行多个步骤后,将数据复制到目标系统的内存中。RDMA 绕过这些中间步骤,从而实现更高效的数据传输。
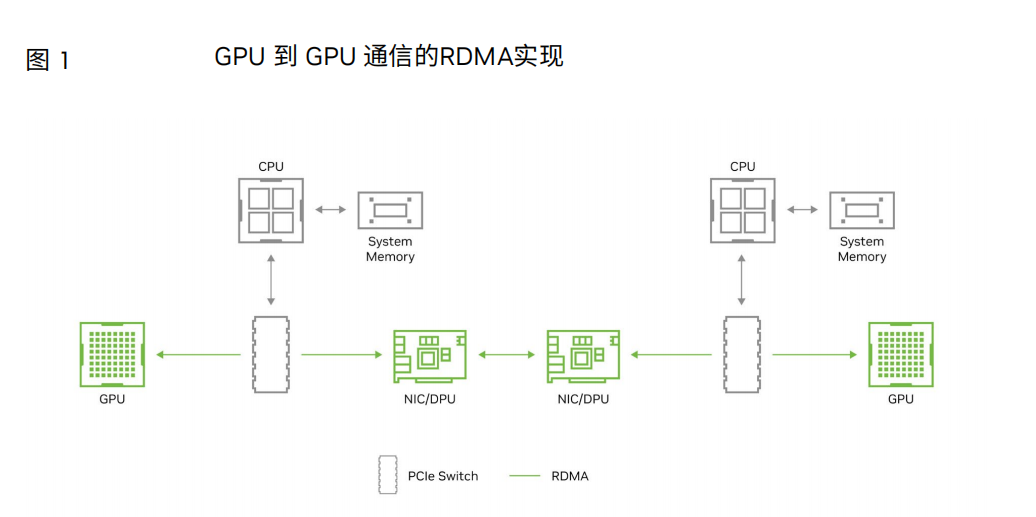
动态路由、多路径和基于包的负载分担
传统的数据中心应用程序往往会生成许多小型数据流,从而可以通过统计求平均值 来反映网络流量。这意味着,对于基于流的路由,由交换机实现的简单静态哈希算法足 以避免网络流量问题,例如等价多路径(ECMP)。相比之下,AI工作负载会生成少量 的大型数据流,即所谓的“大象流”。这些大型数据流会消耗大量的链路带宽,如果将多 个大象流转发到同一链路,则会出现拥塞和高时延。将ECMP与AI结合使用时,即使 使用无阻塞的拓扑结构,发生此类冲突的可能性也非常高。由于AI作业性能取决于网 络最坏情况下的性能,这些冲突将导致模型训练时间高于预期,并且非常不可预测。
因此,需要使用动态路由算法来动态地负载均衡通过网络传输的数据。此外,路由 需要非常精细,以避免冲突。如果路由是逐流完成的,仍然有很大统计概率会发生拥 塞。然而,当基于包的负载分担时,数据包到达目的地时很可能会乱序。对于基于数据 包粒度的动态路由,必须建立灵活的重新排序机制,以便动态路由对应用程序不可 见。Spectrum-X通过将Spectrum-4交换机的负载均衡功能与BlueField-3 DPU执行 的直接数据放置(DDP)相结合来实现这一点,以提供端到端的动态路由。
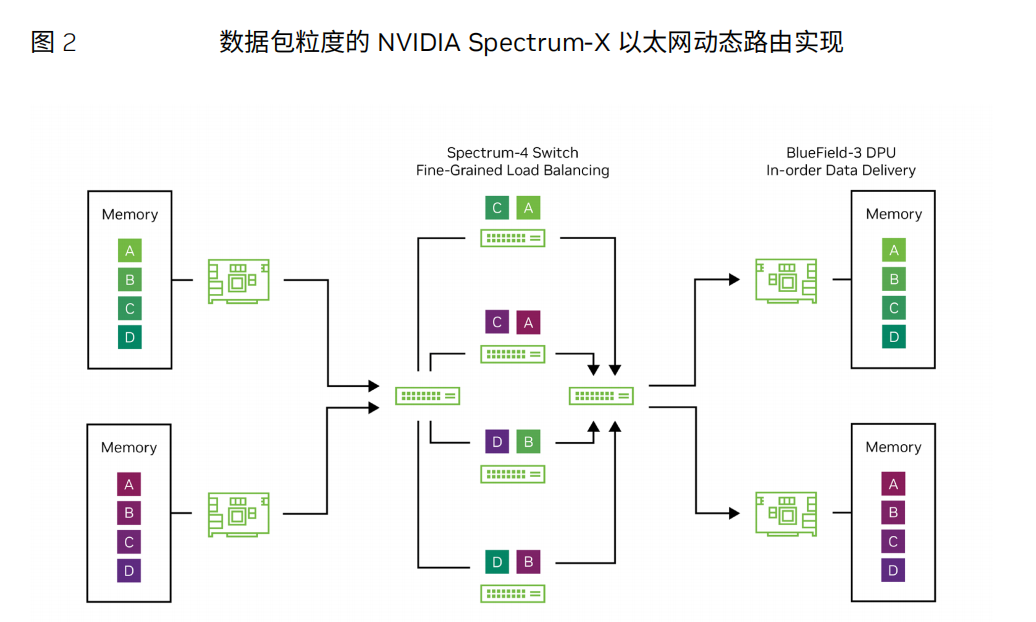
拥塞控制
在同时运行不同AI作业的多租户AI云环境中,可能会出现网络拥塞。当n个发 送方尝试将数据传输到一个目的地(或者具有n个不同目的地和n个发送方的数据 流,途径具有来自其他应用程序的后台网络流量的交换机)时,这种情况尤为明显。 这种网络拥塞不仅会导致更高的时延和有效带宽的降低,而且网络“热点”的传播和相 关的背景流也会受害;也就是说,相邻的租户可能会受到来自另一个租户拥塞的影 响。
在部署基于以太网的生成式AI时,使用最典型的拥塞控制方法,即显式拥塞通知 (ECN)是不够的。最终,为了缓解拥塞,必须对传输数据(网卡或DPU)的网络设 备进行计量。使用ECN时,这种计量只有在交换机缓冲区达到特定容量阈值时才会发 生。然后,接收方通知发送方测量其吞吐量,直到接收方看到拥塞已得到根治。但 是,在大规模AI模型常见的突发流量情况下,这种拥塞通信的时延可能过高,导致缓 冲区溢出和数据包丢弃。虽然深度缓冲区交换机可以降低缓冲区溢出的可能性,但它 们引入的额外时延违背了拥塞控制的初衷。
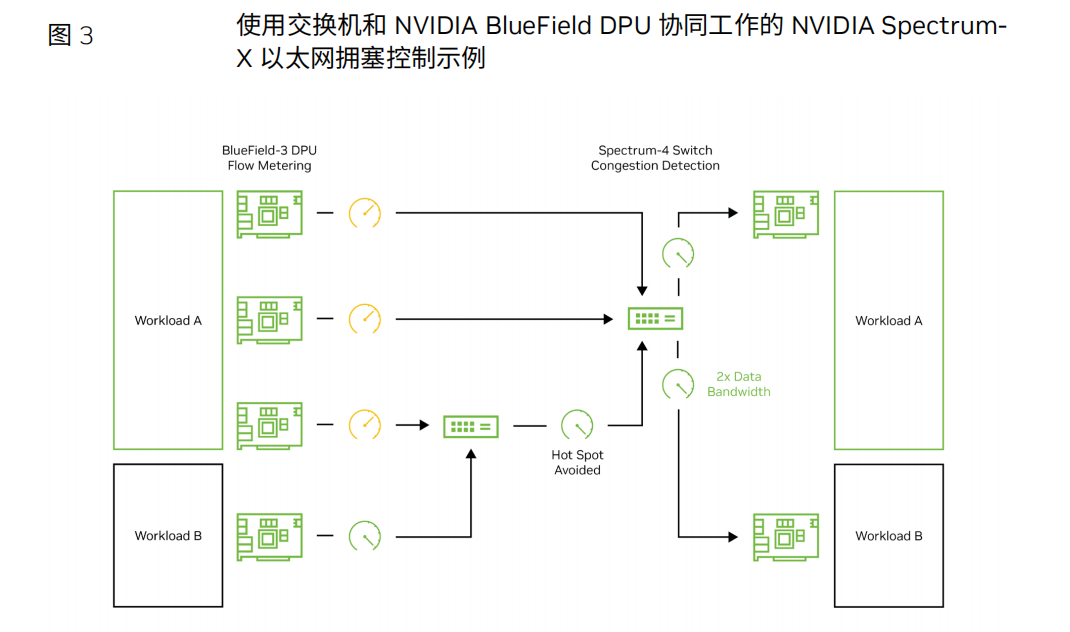
性能隔离与安全
AI云等多租户环境需要保护,以免受到在同一基础设施上运行的其他作业的影 响。许多以太网ASIC设计并不具有ASIC级别的作业保护。当“嘈杂的邻居”(另一 项相邻作业)将网络流量发送到同一目标端口时,这可能会导致某些作业因有效带宽 非常低而“受到损害”。
以太网还必须考虑网络公平性。Al云必须在同一基础设施上支持异构应用程序组 合。不同的应用程序可能会使用不同的数据帧大小,如果不进行隔离优化,更大的数 据帧将在与较小的数据帧传输到同一目标端口时占用过多的带宽。
共享数据包缓冲区是实现性能隔离、防止嘈杂邻居和网络不公平的关键。通用 共享缓冲区可对交换机上的每个端口提供相同的缓存访问,从而为混合AI云工作负 载提供所需的可预测性和一致的低时延。
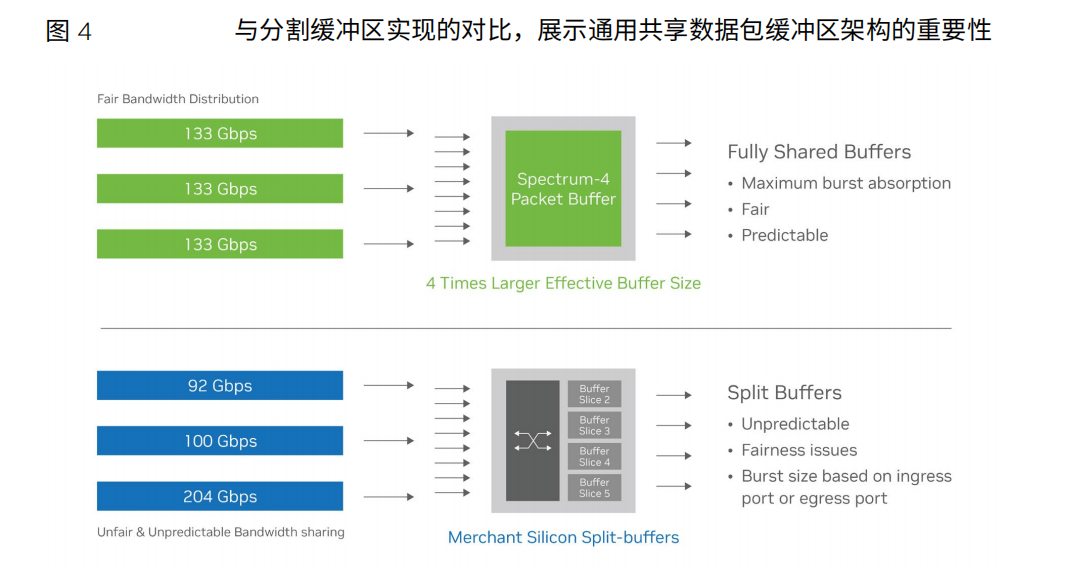
除了从有效带宽角度考虑性能隔离之外,还必须认识到性能隔离和零信任安全架构是多租户环境中网络安全的关键。必须使用高效的加密和身份验证工具来保护静态和动态数据,并在不影响性能的情况下提供安全性。BlueField-3 DPU(兼容以太网和InfiniBand)具有基于硬件信任根的安全启动功能,还支持用于动态数据加密的MACsec和IPsec,以及用于静态数据的AES-XTS 256/512加密。
《HotChips 2024大会技术合集(1)》
《HotChips 2024大会技术合集(2)》
《HotChips 2024大会技术合集(3)》
《HotChips 2024大会技术合集(4)》
《HotChips 2024大会技术合集(5)》
《HotChips 2024大会技术合集(6)》
《HotChips 2024大会技术合集(7)》
《HotChips 2024大会技术合集(8)》
《算力网络:光网络技术合集(1)》
1、面向算力网络的新型全光网技术发展及关键器件探讨
2、面向算力网络的光网络智能化架构与技术白皮书
3、2023开放光网络系统验证测试规范
4、面向通感算一体化光网络的光纤传感技术白皮书
《算力网络:光网络技术合集(2)》
1、数据中心互联开放光传输系统设计
2、确定性光传输支撑广域长距算力互联
3、面向时隙光交换网络的纳秒级时间同步技术
4、数据中心光互联模块发展趋势及新技术研究
面向超万卡集群的新型智算技术白皮书
面向AI大模型的智算中心网络演进白皮书
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


