·聚焦:人工智能、芯片等行业
欢迎各位客官关注、转发


最近,在机架内部使用光互连的趋势日益增长。受人工智能的高带宽、低延迟要求(因为人工智能模型分布在数十个处理节点上)的推动,光互连正在帮助这些多节点系统尽可能快地运行。速度一如既往地至关重要。
光互连是一个充满创新的领域。一些初创公司正在开发全光分组交换——避免在电域和光域之间转换信号的需要,从而大大节省了功耗和延迟。
其他公司正在将光学技术应用到下一层,正在开发全光芯片到芯片甚至硅片到硅片的互连。在这里,通信带宽甚至更高。为了实现这一进步,共封装光学器件至关重要。代工厂和芯片封装公司正在大力投资这一功能。

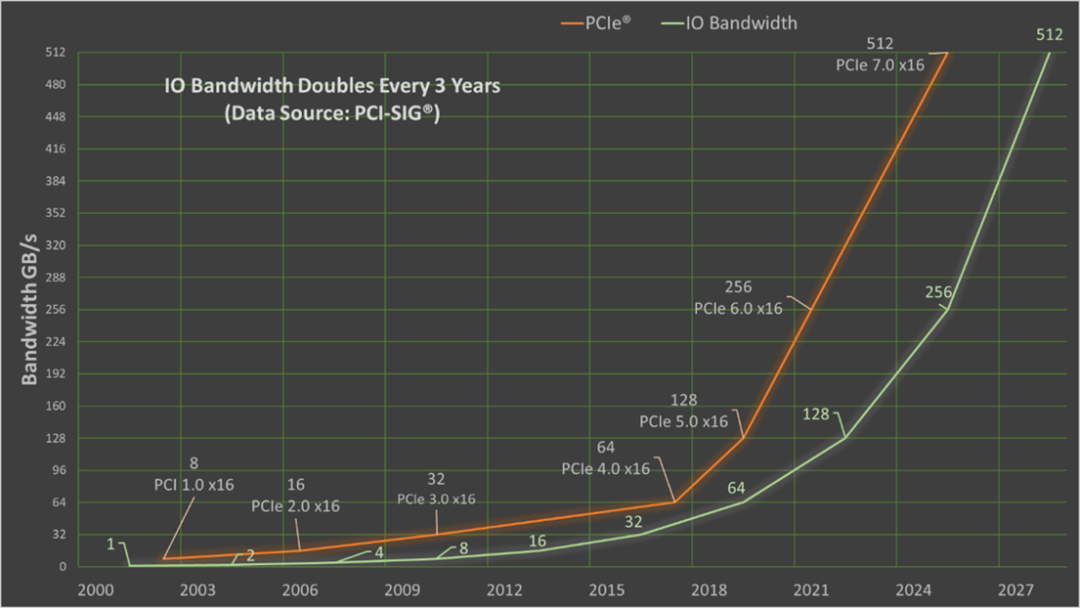
大模型时代对PCIe技术进步的需求
PCIe总线协议作为计算机和服务器中使用最广泛的高速数据传输技术,其传输性能的提升对于满足这些需求至关重要。
传统连接方案主要依赖于铜缆进行电信号传输,用于单机内部计算芯片和设备之间互连。
众所周知,铜缆在信号完整性、延迟、传输距离和功耗等方面存在日益突出的局限,无法满足PCIe高性能互连系统的需求。
所需要的算力规模也变得越来越大,万卡成为算力系统设计的起点,单机内部的PCIe连接已经不能满足需求,机柜内互连和跨机柜的互连成为新的发展方向,以实现更高效的数据交换和资源共享。
核心光互连有三种技术
垂直腔面发射激光器(VCSEL)是整个行业光学AI互连技术的主力。其低功耗和低成本使其成为数据通信和传感应用的理想选择,唯一的限制是它在较短的链路距离内运行效果最佳。
电吸收调制激光器 (EML)非常适合扩展到更远距离和数十万甚至数百万个单元的AI系统。该技术在非常高的带宽下提供更好的性能,并且通常是第一个以下一代数据速率实现批量部署的技术。
共封装光学器件(CPO)是一种将高速硅光子学异质集成到专用集成电路上的先进技术,旨在解决下一代带宽和功率挑战。
这项新技术将为未来几代人工智能系统提供功率和成本领先优势,并支持大规模人工智能网络的基础设施。

英特尔的光互连新方案
英特尔推出的光学计算互连(OCI)芯粒备受瞩目。这一尚处于技术原型阶段的创新成果,可与CPU、GPU集成,面向数据中心和高性能计算应用。
其显著优势在于能够在最长100米的光纤上单向支持64个32Gbps通道,这对于实现可扩展的CPU和GPU集群连接意义重大,极大地提高了带宽,同时还有助于降低功耗,延长传输距离,为加速机器学习工作负载等高性能计算任务提供了有力支撑。
在一些大型数据中心,采用英特尔的OCI芯粒后,数据处理速度大幅提升,原本需要数小时才能完成的复杂数据分析任务,现在可以在更短的时间内完成,大大提高了工作效率。

博通的光互连领域新尝试
博通在光互连领域也展现出了强大的实力与创新精神。在Hot Chips 2024大会上,博通展示了带有光学附件的AI计算ASIC,将硅光子学和共封装光学器件(CPO)技术巧妙融合。
在其新一代的Tomahawk 5Bailly交换机中采用了CPO技术,直接将光学模块集成到芯片封装中,不仅显著减少了系统延迟,还大幅提高了数据传输速度和能效。
并且博通采用可插拔激光器的设计策略,提高了系统的可维护性,降低了维护成本,同时通过将计算 ASIC 与光学模块和高带宽内存(HBM)封装在一起,实现了更高的计算密度和更低的功耗。
在一些高速网络通信场景中,博通的光互连方案使得网络延迟降低到微秒级别,为实时视频会议、在线游戏等对网络延迟要求极高的应用提供了稳定可靠的保障。

巨头在光互连领域的差异
这些芯片巨头的光互连新方案既有相似之处,也存在一些差异。
相似之处在于,他们都看到了光互连技术在提升数据传输速度、降低功耗、提高带宽等方面的巨大潜力,并且都在积极将光互连技术与自身的芯片产品或系统进行深度整合,以满足日益增长的高性能计算和数据中心需求。
然而,在具体的技术实现路径、集成方式以及应用场景的侧重上,又各有千秋。
例如英特尔的OCI芯粒专注于为CPU和GPU集群连接提供解决方案。
博通更强调在交换机等网络设备中的应用以及可插拔激光器等独特设计。
总之,芯片巨头们的光互连新方案正推动着整个芯片行业朝着更高性能、更低功耗、更高速数据传输的方向迈进。

结尾:
创新成果不仅将重塑数据中心和高性能计算的未来格局,也为人工智能、6G、量子计算等前沿领域的发展奠定了坚实基础,引领着信息技术进入一个全新的发展阶段。
内容参考来源于:半导体行业观察:光互联,芯片巨头再出招;半导体行业观察:PCIe,新革命;光芯之路:博通的光互连技术;地面通三网互通:光互连和光处理如何改变数据中心
本公众号所刊发稿件及图片来源于网络,仅用于交流使用,如有侵权请联系回复,我们收到信息后会在24小时内处理。
推荐阅读:



商务合作请加微信勾搭:
18948782064
请务必注明:
「姓名 + 公司 + 合作需求」