NVIDIA Grace Hopper 超级芯片架构 是 高性能计算 ( HPC )和 AI 工作负载的第一个真正的异构加速平台。它利用 GPU 和 CPU 的优势加速应用程序,同时提供迄今为止最简单和最高效的分布式异构编程模型。科学家和工程师可以专注于解决世界上最重要的问题。下载链接:
《HotChips 2024大会技术合集(1)》
《HotChips 2024大会技术合集(2)》
《HotChips 2024大会技术合集(3)》
《HotChips 2024大会技术合集(4)》
《HotChips 2024大会技术合集(5)》
香山:开源高性能RISC-V处理器
人工智能系列专题报告:CoWoS技术引领先进封装,国内OSAT有望受益香山:开源高性能RISC-V处理器
AI算力研究:英伟达B200再创算力奇迹,液冷、光模块持续革新
GPU深度报告:英伟达GB200 NVL72全互联技术,铜缆方案或将成为未来趋势?
人工智能系列专题报告:CoWoS技术引领先进封装,国内OSAT有望受益
软硬件融合:从DPU到超异构计算
1、GPU高性能计算概述
2、GPU深度学习基础介绍
3、OpenACC基本介绍
4、CUDACC++编程介绍
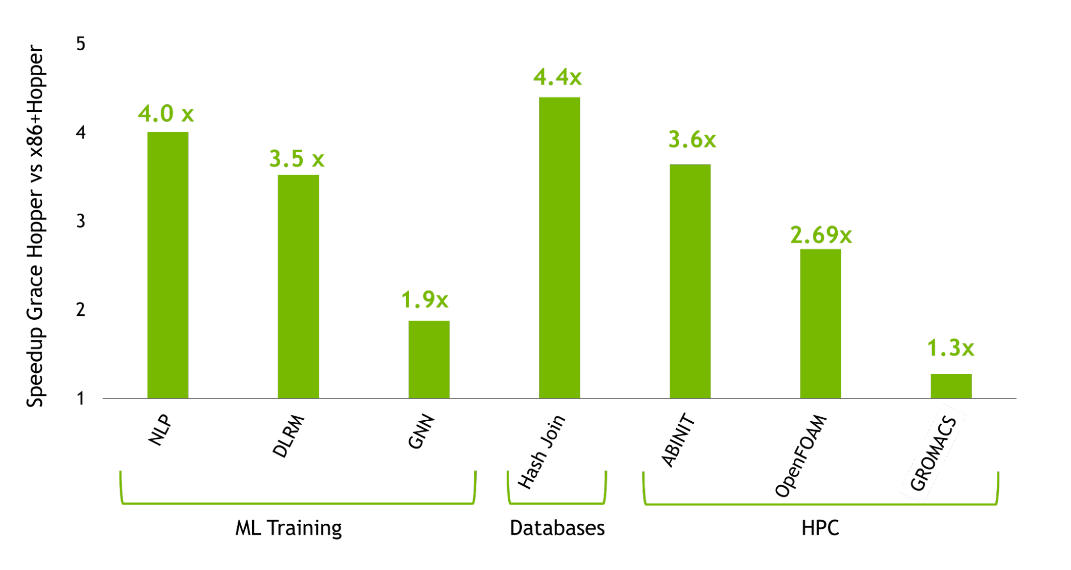
5、CUDAFortr基本介绍图 1.Grace Hopper 与 x86 + Hopper 的最终用户应用程序性能模拟(来源:NVIDIA Grace Hopper Architecture whitepaper )在这篇文章中,您将了解 Grace Hopper 超级芯片的所有信息,并重点介绍 NVIDIA Grace Hoppper 所带来的性能突破。高性能计算和巨大人工智能工作负载的性能和生产力
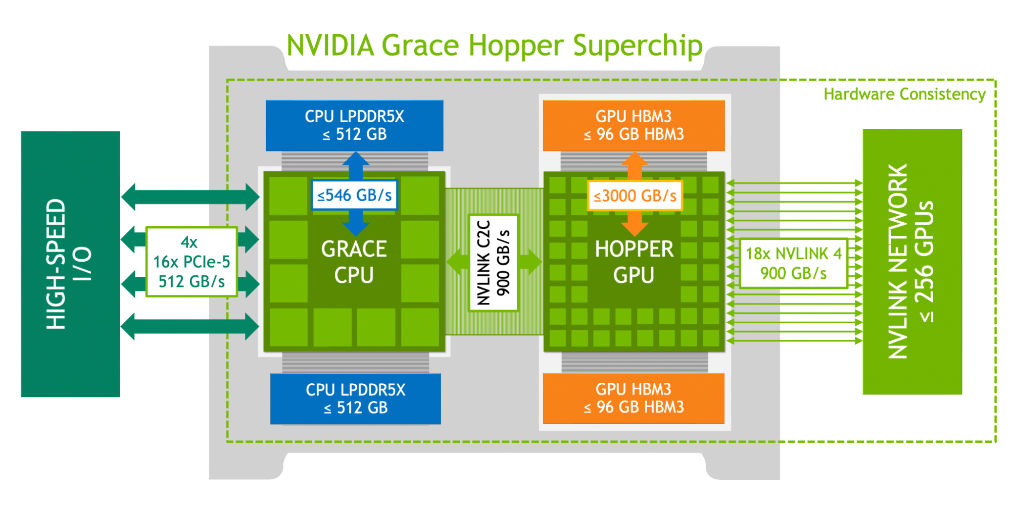
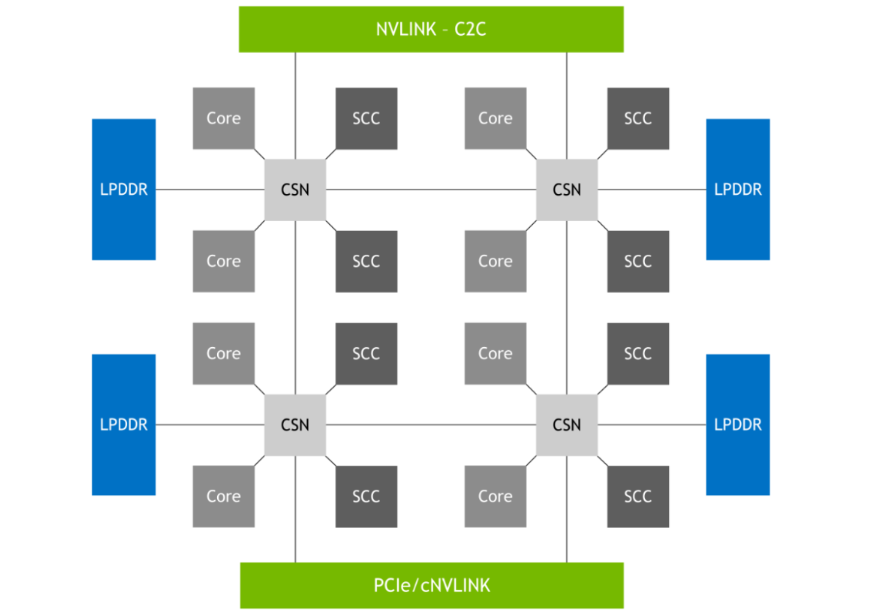
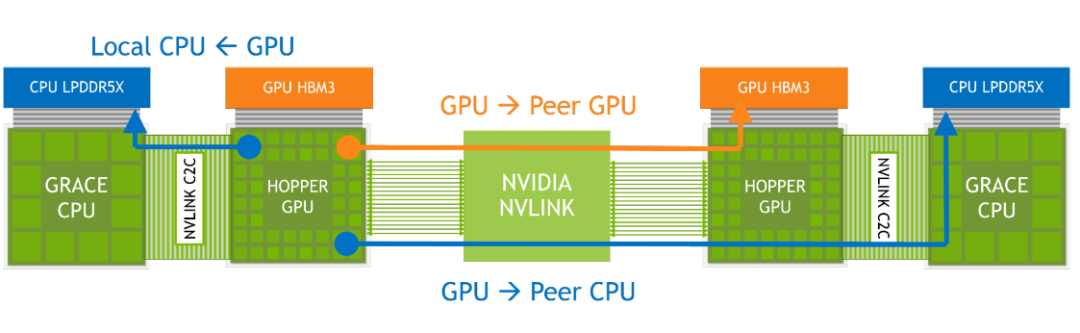
NVIDIA Grace Hopper 超级芯片架构将 NVIDIA Hopper GPU 的开创性性能与 NVIDIA Grace CPU 的多功能性结合在一起,在单个超级芯片中连接了高带宽和内存相关 NVIDIA NVLink Chip-2-Chip (C2C) 互连,并支持新的 NVIDIA NVLink Switch System 。图 2. NVIDIA Grace Hopper 超级芯片逻辑概述NVIDIA NVLink-C2C 是一种 NVIDIA 内存连贯、高带宽和低延迟超级芯片互连。它是 Grace Hopper 超级芯片的核心,提供敢达 900 GB / s 的总带宽。这比通常用于加速系统的 x16 PCIe Gen5 通道高 7 倍的带宽。NVLink-C2C 内存一致性提高了开发人员的生产力和性能,并使 GPU 能够访问大量内存。CPU 和 GPU 线程现在可以同时透明地访问 CPU 和 GPU 驻留内存,使您能够专注于算法而不是显式内存管理。内存一致性使您能够只传输所需的数据,而不会将整个页面迁移到 GPU 或从 GPU 迁移。它还通过启用 CPU 和 GPU 的本机原子操作,实现 GPU 和 CPU 线程之间的轻量级同步原语。带地址转换服务( ATS )的 NVLink-C2C 利用 NVIDIA Hopper 直接内存访问( DMA )复制引擎,加快主机和设备间可分页内存的批量传输。NVLink-C2C 使应用程序能够超额订阅 GPU 的内存,并以高带宽直接利用 NVIDIA Grace CPU 的内存。每个 Grace Hopper 超级芯片最多 512 GB LPDDR5X CPU 内存, GPU 可直接高带宽访问比 HBM 多 4 倍的内存。结合 NVIDIA NVLink 交换机系统,在多达 256 个 NVLink 连接的 GPU 上运行的所有 GPU 线程现在可以以高带宽访问多达 150 TB 的内存。第四代 NVLink 支持使用直接加载、存储和原子操作访问对等内存,使加速应用程序比以往任何时候都更容易解决更大的问题。与 NVIDIA 网络技术一起, Grace Hopper Superchips 为下一代 HPC 超级计算机和 AI 工厂提供了配方。客户可以接受更大的数据集、更复杂的模型和新的工作负载,从而比以前更快地解决这些问题。NVIDIA Grace Hopper 超级芯片的主要创新如下:- 具有单个 CPU NUMA 节点的高开发人员生产率。
- NVIDIA 可扩展一致性结构( SCF )网格和分布式缓存,内存带宽高达 3.2 TB / s 。
- 高达 512 GB 的 LPDDR5X 内存,提供高达 546 GB / s 的内存带宽。
- 多达 72x Arm Neoverse V2 内核,每个内核配备 Armv9.0-A ISA 和 4 × 128 位 SIMD 单元。
- 高达 96 GB 的 HBM3 内存,传输速度高达 3000 GB / s 。
- 与 NVIDIA A100 GPU 相比,多达 144 个 SM ,具有第四代 Tensor 核心、 transformer 引擎、 DPX 和高 3 倍的 FP32 和 FP64 。
- 扩展 GPU 内存功能使料斗 GPU 可将所有 CPU 内存寻址为 GPU 内存。每个 Hopper GPU 可以在超级芯片内寻址多达 608 GB 的内存。
- 总带宽高达 900 GB / s , 450 GB / s / dir 。
- Grace CPU 和 Hopper GPU 之间的硬件相干互连。
- 每个 NVLink 连接的 Hopper GPU 可以寻址网络中所有超级芯片的所有 HBM3 和 LPDDR5X 内存,最多可寻址 150 TB 的 GPU 内存。
- 使用 NVLink 4 连接多达 256 倍 NVIDIA Grace Hopper 超级芯片。
针对性能、可移植性和生产力的编程模型
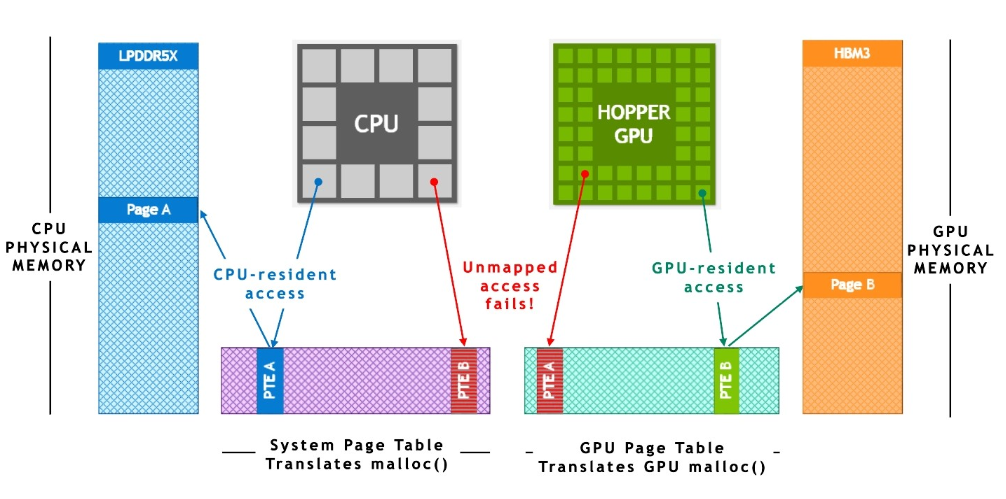
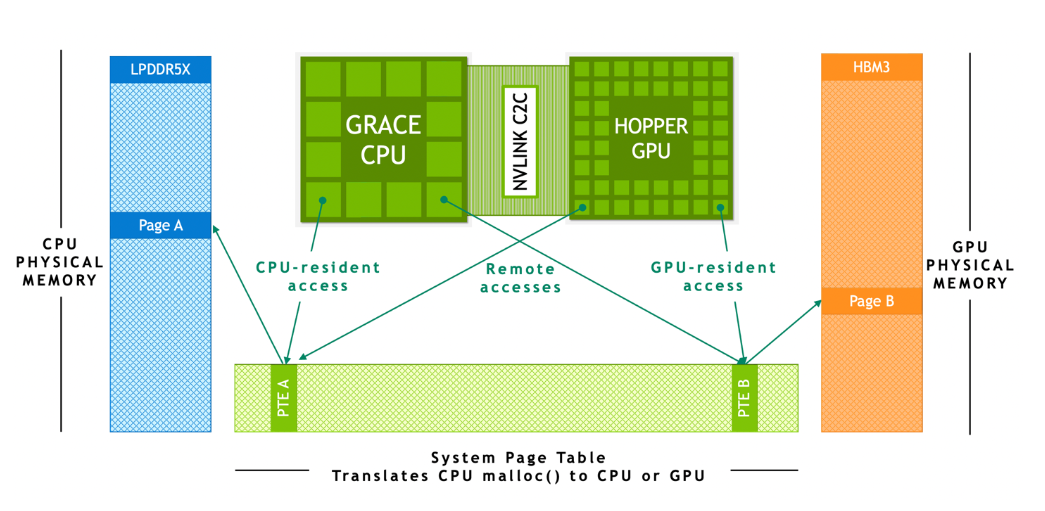
具有 PCIe 连接加速器的传统异构平台要求用户遵循复杂的编程模型,该模型涉及手动管理设备内存分配以及与主机之间的数据传输。NVIDIA Grace Hopper Superchip 平台是异构的,易于编程, NVIDIA 致力于让所有开发人员和应用程序都可以使用它,而不依赖于选择的编程语言。Grace Hopper Superchip 和平台的构建都使您能够为手头的任务选择合适的语言, NVIDIA CUDA LLVM Compiler API 使您能够将首选的编程语言带到 CUDA 平台,其代码生成质量和优化水平与 NVIDIA 编译器和工具相同。NVIDIA 为 CUDA 平台提供的语言(图 3 )包括 ISO C ++、 ISO Fortran 和 Python 等加速标准语言。该平台还支持基于指令的编程模型,如 OpenACC 、 OpenMP 、 CUDA C ++和 CUDA Fortran 。NVIDIA HPC SDK 支持所有这些方法,以及一组用于评测和调试的加速库和工具。Figure 3. NVIDIA Grace Hopper 超级芯片编程模型NVIDIA 是 ISO C ++和 ISO Fortran 编程语言社区的成员,这些社区使符合 ISO C ++和 ISOFortran 标准的应用程序能够在 NVIDIA CPU 和 NVIDIA GPU 上运行,无需任何语言扩展。有关在 GPU 上运行符合 ISO 的应用程序的更多信息,请参阅 Multi-GPU Programming with Standard Parallel C++ 和 Using Fortran Standard Parallel Programming For GPU Acceleration 。该技术严重依赖于 NVIDIA NVLink-C2C 和 NVIDIA 统一虚拟内存提供的硬件加速内存一致性。如图 4 所示,在没有 ATS 的传统 PCIe 连接 x86 + Hopper 系统中, CPU 和 GPU 具有独立的每个进程页表,系统分配的内存不能直接从 GPU 访问。当程序使用系统分配器分配内存,但 GPU 页面表中的页面条目不可用时,从 GPU 线程访问内存失败。图 4. NVIDIA Hopper 系统与不相交的页表在基于 NVIDIA Grace Hopper Superchip 的系统中, ATS 使 CPU 和 GPU 能够共享单个进程页表,使所有 CPU 和 GPU 线程能够访问所有系统分配的内存,这些内存可以驻留在物理 CPU 或 GPU 内存上。所有 CPU 和 GPU 线程都可以访问 CPU heap 、 CPU 线程堆栈、全局变量、内存映射文件和进程间内存。图 5. NVIDIA Grace Hopper 超级芯片系统中的地址转换服务NVIDIA NVLink-C2C 硬件一致性使 Grace CPU 能够以缓存线粒度缓存 GPU 内存,并使 GPU CPU 能够访问彼此的内存而无需页面迁移。NVLink-C2C 还加速了系统分配内存上 CPU 和 GPU 支持的所有原子操作。Scoped atomic operations 完全受支持,并支持系统中所有线程之间的细粒度和可扩展同步。根据 CPU 或 GPU 线程是否首先访问系统分配的内存,运行时在 LPDDR5X 或 HBM3 上第一次接触时使用物理内存备份系统分配的存储器。从操作系统的角度来看, Grace CPU 和 Hopper GPU 只是两个独立的 NUMA 节点。系统分配的内存是可迁移的,因此运行时可以更改其物理内存支持,以提高应用程序性能或处理内存压力。对于基于 PCIe 的平台(如 x86 或 Arm ),您可以使用与 NVIDIA Grace Hopper 模型相同的统一内存编程模型。这最终将通过 Heterogeneous Memory Management (HMM) feature 实现,它是 Linux 内核功能和 NVIDIA 驱动程序功能的组合,使用软件模拟 CPU 和 GPU 之间的内存一致性。在 NVIDIA Grace Hopper 上,这些应用程序可以从 NVLink-C2C 提供的更高带宽、更低延迟、更高原子吞吐量和硬件加速(无需任何软件更改)中获益。超级芯片架构特征
以下是 NVIDIA Grace Hopper 架构的主要创新:NVIDIA Grace CPU
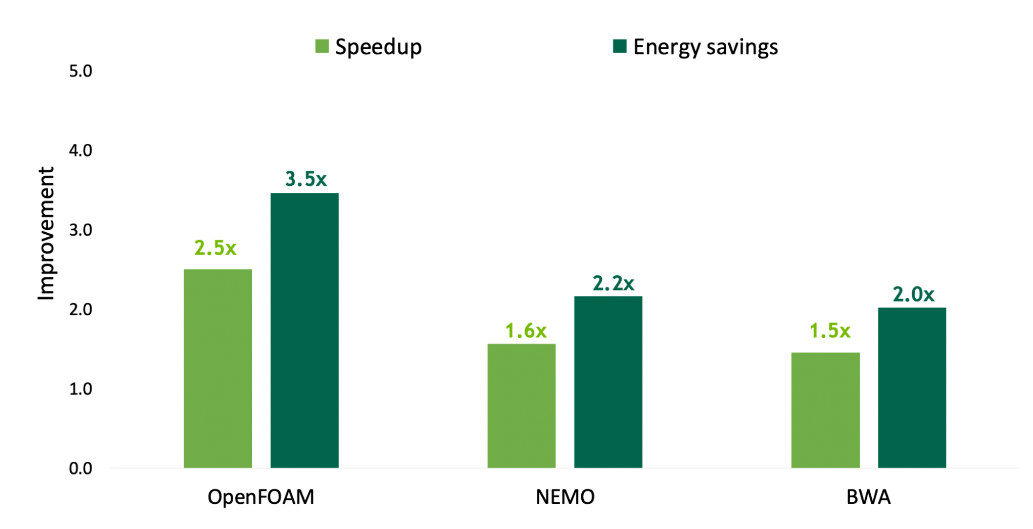
随着 GPU 的并行计算能力在每一代中持续增长三倍,快速高效的 CPU 对于防止现代工作负载中的串行和仅 CPU 部分主宰性能至关重要。NVIDIA Grace CPU 是 first NVIDIA data center CPU ,它是 built from the ground up to create HPC and AI superchips 。Grace 提供多达 72 个 Arm Neoverse V2 CPU 内核和 Armv9.0-A ISA ,每个内核提供 4 × 128 位宽的 SIMD 单元,支持 Arm 的 Scalable Vector Extensions 2 (SVE2) SIMD 指令集。NVIDIA Grace 提供领先的每线程性能,同时提供比传统 CPU 更高的能效。72 个 CPU 内核在 SPECrate 2017_int_base 上的得分高达 370 (估计),确保高性能以满足 HPC 和 AI 异构工作负载的需求。图 6 :Grace Hopper Superchip 与 AMD Milan 7763 中 NVIDIA Grace CPU 的最终用户应用程序性能和节能模拟表明, Grace CPU 的速度快 2.5 倍,能耗低 4 倍机器学习和数据科学中的现代 GPU 工作负载需要访问大量内存。通常,这些工作负载必须使用多个 GPU 将数据集存储在 HBM 内存中。NVIDIA Grace CPU 提供高达 512 GB 的 LPDDR5X 内存,可在内存容量、能效和性能之间实现最佳平衡。它提供高达 546 GB / s 的 LPDDR5X 内存带宽, NVLink-C2C 使 GPU 能够以 900 GB / s 的总带宽访问该内存。单个 NVIDIA Grace Hopper 超级芯片为 Hopper GPU 提供了总计 608 GB 的快速可访问内存,几乎是 DGX-A100-80 中可用的慢速内存总量;上一代的 8- GPU 系统。这是通过图 7 所示的 NVIDIA SCF 实现的,这是一种网状结构和分布式缓存,提供高达 3.2 TB / s 的总二等分带宽,以实现 CPU 内核、内存、系统 I / O 和 NVLink-C2C 的全部性能。CPU 核心和 SCF 缓存分区( SCC )分布在整个网格中,而缓存交换节点( CSN )通过结构路由数据,并充当 CPU 核心、缓存存储器和系统其余部分之间的接口。NVIDIA Hopper GPU
NVIDIA Hopper GPU 是第九代 NVIDIA 数据中心 GPU 。与前几代 NVIDIA Ampere GPU 相比,它旨在为大规模 AI 和 HPC 应用提供数量级的改进。料斗 GPU 还具有多项创新:- 新的第四代 Tensor 核心在更广泛的 AI 和 HPC 任务上执行比以往更快的矩阵计算。
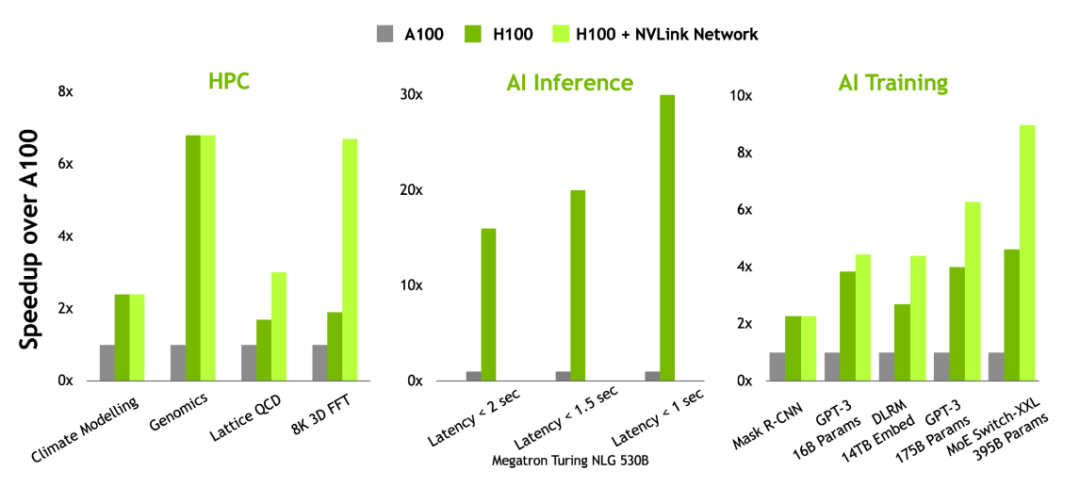
- 与上一代 NVIDIA A100 GPU 相比,新的 transformer 引擎使 H100 在大型语言模型上提供高达 9 倍的 AI 训练和高达 30 倍的 AI 推理加速。
- 改进的空间和时间数据位置和异步执行功能使应用程序能够始终保持所有单元忙碌,并最大限度地提高能效。
- 安全 Multi-Instance GPU (MIG ) 将 GPU 划分为独立的、适当大小的实例,以最大限度地提高服务质量( QoS ),以适应较小的工作负载。
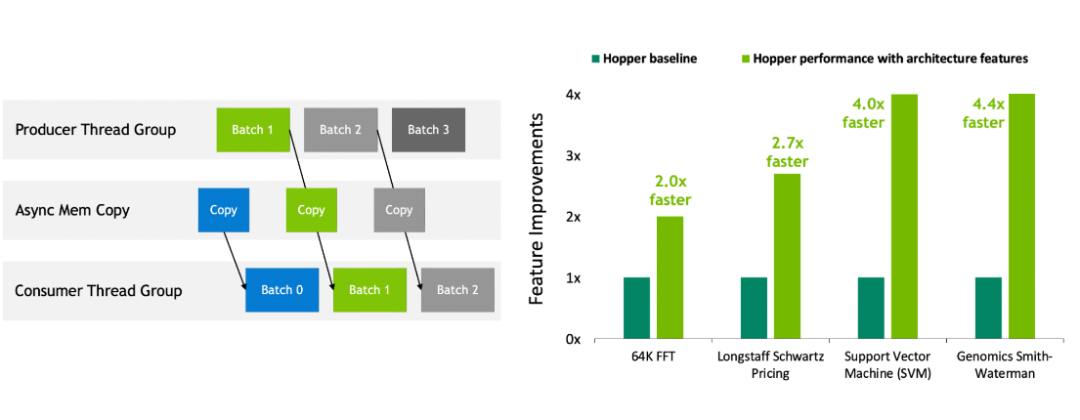
NVIDIA Hopper 是第一款真正的异步 GPU 。它的 Tensor Memory Accelerator ( TMA )和异步事务屏障使线程能够重叠和流水线无关的数据移动和数据处理,使应用程序能够充分利用所有单元。新的空间和时间局部特性,如线程块集群、分布式共享内存和线程块重新配置,为应用程序提供了对更大量共享内存和工具的快速访问。这使应用程序能够在数据在芯片上时更好地重用数据,从而进一步提高应用程序性能。图 9 NVIDIA Hopper GPU 异步执行实现了与计算重叠的独立数据移动(左)。新的空间和时间局部特性提高了应用程序性能(右)。NVLink-C2C :用于超级芯片的高带宽芯片到芯片互连
NVIDIA Grace Hopper 通过 NVIDIA NVLink-C2C 将 NVIDIA 格雷斯 CPU 和 NVIDIA Hopper GPU 融合到一个超级芯片中, NVIDIA NVLink-C2C 是一个 900 GB / s 芯片到芯片的连贯互连,可以使用统一的编程模型对格雷斯 Hopper 超级芯片进行编程。NVLink 芯片 2 芯片( C2C )互连在 Grace CPU 和 Hopper GPU 之间提供了高带宽的直接连接,以创建 Grace Hopper 超级芯片,该芯片专为 AI 和 HPC 应用的降速加速而设计。凭借 900 GB / s 的双向带宽, NVLink-C2C 以较低的延迟提供了 x16 PCIe Gen 链路的 7 倍带宽。NVLink-C2C 也仅使用 1.3 微微焦/比特传输,这比 PCIe Gen 5 能效高 5 倍以上。此外, NVLink-C2C 是一种相干存储器互连,具有对系统范围原子操作的本地硬件支持。这提高了对非本地存储器的内存访问的性能,例如 CPU 和 GPU 线程访问驻留在其他设备中的内存。硬件一致性还提高了同步原语的性能,减少了 GPU 或 CPU 彼此等待的时间,提高了系统的总利用率。最后,硬件一致性还简化了使用流行编程语言和框架开发异构计算应用程序。有关更多信息,请参阅 NVIDIA Grace Hopper 编程模型部分。NVLink 交换机系统
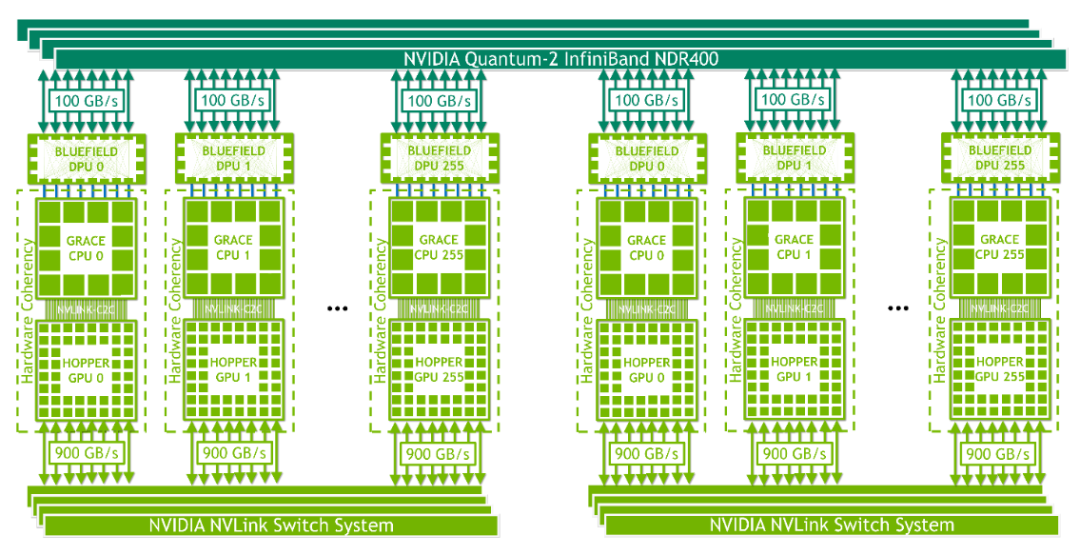
NVIDIA NVLink 交换机系统将第四代 NVIDIA NVLink 技术与新的第三代 NVIDIA NVSwitch 结合在一起。NVSwitch 的一级可连接多达八个 Grace Hopper 超级芯片,而另一级采用胖树拓扑结构,可通过 NVLink 连接多达 256 个 Grace Hopper 超级芯片。Grace Hopper 超级芯片对以高达 900 GB / s 的速度交换数据。凭借多达 256 个 Grace Hopper 超级芯片,该网络可提供高达 115.2 TB / s 的全天候带宽。这是 NVIDIA InfiniBand NDR400 全对全带宽的 9 倍。图 10. NVIDIA NVLink 4 NVSwitch 的逻辑概述第四代 NVIDIA NVLink 技术使 GPU 线程能够使用正常内存操作、原子操作和批量传输来寻址 NVLink 网络中所有超级芯片提供的高达 150 TB 的内存。MPI 、 NCCL 或 NVSHMEM 等通信库在可用时透明地利用 NVLink 交换机系统。扩展 GPU 存储器
NVIDIA Grace Hopper 超级芯片设计用于加速应用程序,其内存占用量非常大,大于单个超级芯片的 HBM3 和 LPDDR5X 内存容量。有关更多信息,请参阅 NVIDIA Grace Hopper 加速应用程序部分。高带宽 NVLink-C2C 上的扩展 GPU 内存( EGM )功能使 GPU 能够高效地访问所有系统内存。EGM 在多节点 NVSwitch 连接的系统中提供高达 150 TB 的系统内存。使用 EGM ,可以分配物理内存,以便从多节点系统中的任何 GPU 线程访问。所有 GPU 都可以以 GPU- GPU NVLink 或 NVLink-C2C 的最低速度访问 EGM 。Grace Hopper 超级芯片配置中的内存访问通过本地高带宽 NVLink-C2C ,总速度为 900 GB / s 。远程内存访问通过 GPU NVLink 执行,根据访问的内存,还通过 NVLink-C2C 执行(图 11 )。使用 EGM , GPU 线程现在可以以 450 GB / s 的速度访问 NVSwitch 结构上的所有可用内存资源,包括 LPDDR5X 和 HBM3 。图 11 NVLink 连接的 Grace Hopper 超级芯片的内存访问NVIDIA HGX Grace Hopper
NVIDIA HGX Grace Hopper 每个节点都有一个 Grace Hoppper 超级芯片,与 BlueField-3 NIC 或 OEM 定义的 I / O 和可选的 NVLink 交换机系统配对。它可以是空气冷却或液体冷却, TDP 高达 1000W 。NVIDIA HGX Grace Hopper 与 InfiniBand
具有 Infiniband (图 13 )的 NVIDIA HGX Grace Hopper 非常适合扩展传统机器学习( ML )和 HPC 工作负载,这些工作负载不受 Infiniband 网络通信开销的限制, Infiniband 是可用的最快互连之一。每个节点包含一个 Grace Hopper 超级芯片和一个或多个 PCIe 设备,如 NVMe 固态驱动器和 BlueField-3 DPU 、 NVIDIA ConnectX-7 NIC 或 OEM 定义的 I / O 。NDR400 InfiniBand NIC 具有 16x PCIe Gen 5 通道,可在超级芯片上提供高达 100 GB / s 的总带宽。结合 NVIDIA BlueField-3 DPU ,该平台易于管理和部署,并使用传统的 HPC 和 AI 集群网络架构。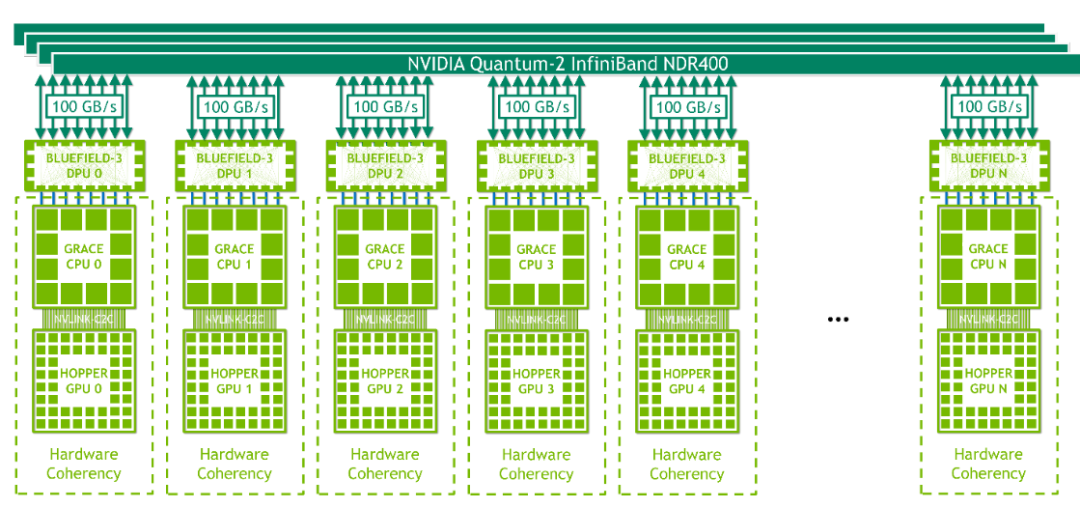 图 13. NVIDIA HGX Grace Hopper 和 InfiniBand 用于扩展 ML 和 HPC 工作负载
图 13. NVIDIA HGX Grace Hopper 和 InfiniBand 用于扩展 ML 和 HPC 工作负载带 NVLink 开关的 NVIDIA HGX Grace Hopper
配备 NVLink Switch 的 NVIDIA HGX Grace Hopper 非常适合大规模机器学习和 HPC 工作负载。它使 NVLink 连接域中的所有 GPU 线程能够在 256- GPU NVLink 连接系统中以每个超级芯片高达 900 GB / s 的总带宽寻址高达 150 TB 的内存。简单的编程模型使用指针加载、存储和原子操作。它的 450 GB / s 全部减少了带宽,最高可达 115.2 TB / s 的二等分带宽,使该平台成为强大扩展世界上最大、最具挑战性的 AI 训练和 HPC 工作负载的理想平台。NVLink 连接的域通过 NVIDIA InfiniBand 网络进行网络连接,例如, NVIDIA ConnectX-7 NIC 或 NVIDIA BlueField-3 数据处理器( DPU )与 NVIDIA Quantum 2 NDR 交换机或 OEM 定义的 I / O 解决方案配对。图 14. NVIDIA HGX Grace Hopper ,配备 NVLink 交换机系统,适用于大规模 ML 和 HPC 工作负载实现性能突破
NVIDIA Grace Hopper Superchip Architecture 白皮书详细介绍了本文中的内容。它将带您了解 Grace Hopper 是如何实现图 1 所示的性能突破的,而目前最强大的基于 PCIe 的加速平台是由 NVIDIA Hopper H100 PCIe GPU 提供支持的。下载链接:
《高性能计算GPU合集》
1、GPU高性能计算概述
2、GPU深度学习基础介绍
3、OpenACC基本介绍
4、CUDACC++编程介绍
5、CUDAFortr基本介绍
2024中国半导体深度分析与展望报告
面向异构硬件架构软件支撑和优化技术
AI大模型赋能手机终端,拥抱AI手机新机遇
全球AI算力行业首次覆盖:从云到端,云端协同,AI开启科技行业超级成长周期
2024年中国大模型行业应用研究:大模型引领智能时代,助力各行业全面升级
《半导体行业系列专题合集》
1、半导体行业系列专题:刻蚀—半导体制造核心设备,国产化典范
2、半导体行业系列专题:碳化硅—衬底产能持续扩充,加速国产化机会
3、半导体行业系列专题:直写光刻篇,行业技术升级加速应用渗透
4、半导体行业系列专题:先进封装—先进封装大有可为,上下游产业链受益
“人工智能+”进入爆发临界,开启繁荣生态前景
鲲鹏处理器软件性能调优(精编版)
《算力网络:光网络技术合集(1)》
1、面向算力网络的新型全光网技术发展及关键器件探讨
2、面向算力网络的光网络智能化架构与技术白皮书
3、2023开放光网络系统验证测试规范
4、面向通感算一体化光网络的光纤传感技术白皮书
《算力网络:光网络技术合集(2)》
1、数据中心互联开放光传输系统设计
2、确定性光传输支撑广域长距算力互联
3、面向时隙光交换网络的纳秒级时间同步技术
4、数据中心光互联模块发展趋势及新技术研究
计算机行业深度:从技术路径,纵观国产大模型逆袭之路
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。