·聚焦:人工智能、芯片等行业
欢迎各位客官关注、转发

近日,OpenAI硬件设施的负责人Trevor Cai在Hot Chips 2024会议上进行了长达一小时的演讲,主题聚焦于[构建可扩展的AI基础设施]。
OpenAI通过观察得出一个关键结论:规模的扩大能够孕育出更优质、更具实用价值的人工智能(AI)系统。
在演讲中,Cai先生着重探讨了如何解决能源消耗与计算能力之间的矛盾,并提到英特尔、IBM以及英伟达等公司提出了更为节能的技术方案。
根据摩根士丹利在八月份发布的研究报告预测,未来几年内,生成式AI的电力需求将每年激增75%,预计到2026年,其能源消耗量将与西班牙2022年的总消耗量相匹敌。
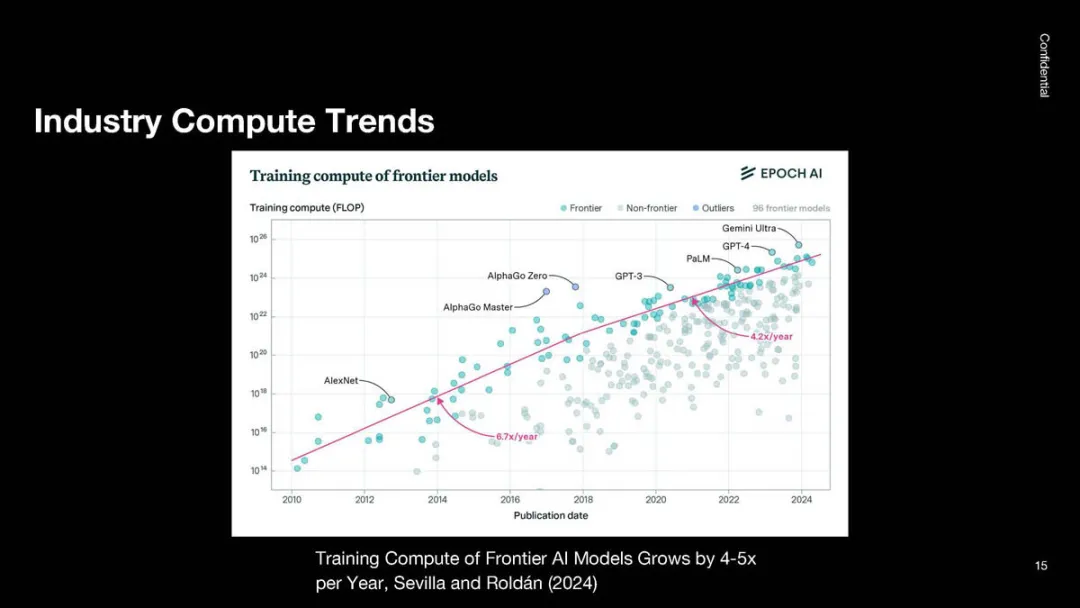
计算量每翻一番,AI模型的性能便能得到显著提升。模型的能力与计算资源消耗呈指数级增长。
自2018年以来,行业内的先进模型计算量每年增长约四倍。
OpenAI坚信,AI基础设施的建设需要巨额投资,因为计算能力的提升已经带来了超过八个数量级的效益增长。
OpenAI 对编码等任务进行了研究,并发现其中存在相似的模式。
这一发现是在平均对数尺度上得出的,因此通过/失败的判定不会过度倾向于解决较为简单的编码问题。
基于此,OpenAI 认为AI领域需要大量投资,因为计算能力的增强已经带来了超过八个数量级的效益提升。
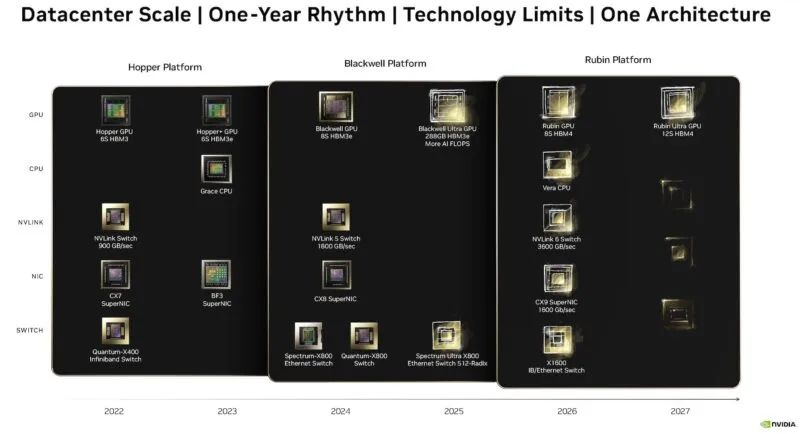
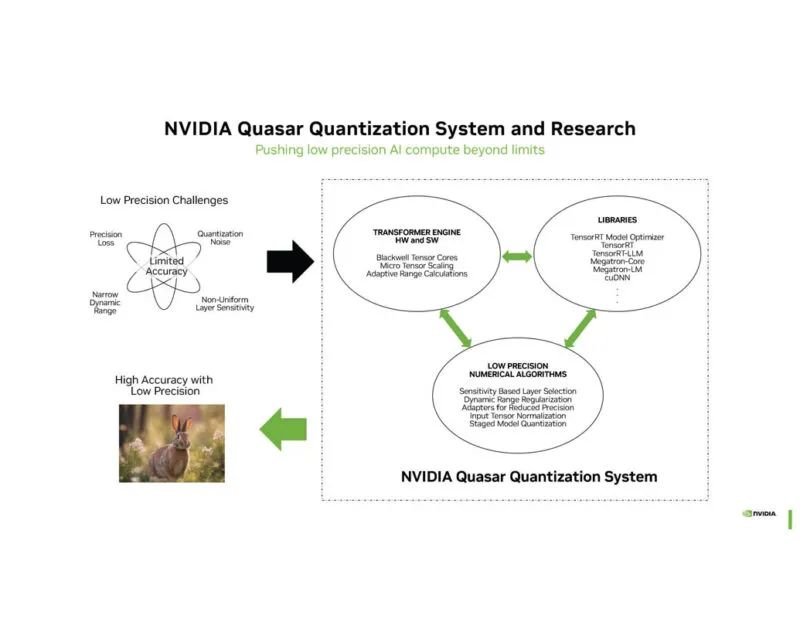
英伟达:Blackwell架构细节公布
在Hot Chips会议期间,英伟达进一步揭示了Blackwell架构的细节。
B200 GPU芯片采用台积电定制的4nm工艺,集成了高达2080亿个晶体管;
NVLink-C2C技术被应用于Blackwell架构中,以实现芯片级的整合;
为了实现GPU间的无缝通信,英伟达A推出了NVSwitch,它允许服务器内的每个GPU以1.8 TB/sec的速度与其他GPU进行通信,从而使得Blackwell平台能够支持更大规模的语言模型。
例如GPT-MoE-1.8T等,以满足实时推理和训练的需求;
NVIDIA高带宽接口(NV-HBI)在两个GPU芯片之间提供了高达10TB/s的双向带宽连接;
此外,NVIDIA在Blackwell平台上原生支持FP4(四精度浮点数)和FP6(六精度浮点数)格式。
在性能方面,官方提供了一个参考数据:Llama 3.1 700亿参数大模型的AI推理性能GB200相较于H200提升了1.5倍。然而,这一性能提升是通过增加功耗实现的。
Blackwell B200单颗芯片的功耗高达1000W,而由一颗Grace CPU和两颗Blackwell GPU组成的超级芯片GB200的功耗更是达到了惊人的2700W。
相比之下,过去Hopper的H100、H200 GPU功耗均为700W,H20的功耗为400W,Grace+Hopper的功耗为1000W。
比较之下,GB200的功耗比上一代GH200大幅提升了1.7倍,但性能提升似乎并未与之匹配,具体详情还需英伟达进一步公布。

英特尔:Lunar Lake和Granite Rapids-D
在2024年Hot Chips大会上,英特尔展示了专为人工智能个人电脑设计的Lunar Lake芯片,以及面向数据中心的最新至强6 SoC Granite Rapids-D。
英特尔在此次大会上推出的Lunar Lake芯片,作为其面向移动AI PC的下一代核心产品,实现了在性能、能效和集成度方面的显著提升。
相较于前代产品Meteor Lake,Lunar Lake在架构设计上进行了根本性的革新,其显著特点在于集成了片上内存。
在系统级芯片(SoC)设计方面,Lunar Lake采用了创新的多核架构,包括四个高性能的P核心(Lion Cove P-Core)以及多个效率核心(E核心)。
与Meteor Lake相比,Lunar Lake的E核心数量由两个增至四个,并且每个E核心集群配备了4MB的L2缓存以及独立的电源管理功能。
这种设计不仅增强了多任务处理能力,还有效降低了功耗。

Lunar Lake引入了8MB的内存侧缓存,旨在减少对DRAM的依赖和访问频率,从而降低功耗并提升性能。
Lion Cove和Skymont核心的设计是Lunar Lake的另一亮点,它们体现了英特尔在提升指令集架构(ISA)效率和每瓦性能方面的不懈追求。
英特尔宣称,新的核心设计在每时钟周期指令(IPC)方面提升了约14%,这意味着在相同的时钟频率下,处理器能够执行更多的指令。
Lunar Lake还对图形处理单元(GPU)和神经处理单元(NPU)进行了显著的性能提升。
新的Xe2 GPU架构将原有的两个SIMD8结构升级为一个SIMD16结构,使得在相同功率下的游戏性能提升了1.5倍。
这一变革不仅拓宽了GPU的应用范围,还提高了图形处理的效率。
在NPU方面,Lunar Lake将先前的2个神经计算引擎扩展至6个,英特尔宣称其NPU的计算能力达到了48 TOPS。
这一性能的提升使得Lunar Lake在人工智能和机器学习任务中的表现更为卓越,能够处理更为复杂的模型和算法。

此外,Xeon D系列将不会采用第四代/第五代Xeon Sapphire Rapids/Emerald Rapids的内核,而是将在2025年通过Granite Rapids-D部件实现Xeon 6的处理能力。
Intel Xeon D系列专为边缘计算设计,旨在为边缘计算带来性能核心以及集成的网络与加速功能。
该系列芯片介于采用E核心的Atom系列和主流Xeon系列之间,边缘计算因其特定的工作温度和环境配置文件而有其独特性。
新芯片支持PCIe Gen5(高于Ice Lake-D中的PCIe Gen4)以及多项新功能。
该芯片提供4通道和8通道设计,支持高速MCRDIMM内存。
具备100GbE连接、Intel QuickAssist、DLB、DSA和vRAN Boost等I/O特性。
性能核心为Granite Rapids/Redwood Cove P核心,值得注意的是,这并非英特尔Lunar Lake P核心。
新芯片支持AMX实现AI加速功能。对于习惯使用高端Xeon的用户而言,这可能不是什么新鲜事,但对于之前使用仅配备VNNI的Ice Lake-D的用户来说,AI性能将有显著提升。
同时,Atom系列与Xeon 6 SoC之间似乎存在较大的性能差距。Atom P5000/C5000系列似乎需要更新,配备更现代的E核心。

IBM:Telum II和Spyre Accelerator新款AI处理器
IBM正式宣布推出两款先进的AI处理器,即Telum II和Spyre Accelerator。
该公司表示,这些处理器将为下一代IBM Z大型机系统提供动力,特别是在增强AI功能方面,包括大型语言模型(LLM)和生成式AI。
IBM新推出的处理器延续了该公司大型机所享有的高安全性、高可用性和卓越性能的传统优势。
Telum II处理器在架构上实现了重大创新,相较于其前身,它在速度、内存容量以及功能上均有显著提升。
Telum II处理器的设计允许内核将AI任务卸载至相邻的任一处理器芯片,从而为每个内核提供了对更广泛的AI计算资源的访问权限,有效减少了对AI加速器的竞争。
该处理器采用了八个高性能内核,每个内核均以固定的5.5GHz频率运行,并配备了集成的片上AI加速器。

该加速器直接与处理器的复杂指令集计算机(CISC)指令集相连,以实现低延迟的AI操作。
与依赖内存映射输入/输出的传统加速器不同,Telum II的AI加速器将矩阵乘法和其他AI基础操作作为本机指令执行,从而减少了开销并提升了吞吐量。
Telum II中每个加速器的AI计算能力翻倍,达到每芯片24万亿次运算(TOPS)。
此外,Telum II处理器显著增加了缓存容量,每个内核可访问36MB的L2缓存,片上总计达到360MB。虚拟L3和L4缓存分别增长了40%,达到360MB和2.88GB。
Telum II处理器的另一显著特点是其集成了数据处理单元(DPU)。
在IBM大型机每天处理数十亿个事务的企业环境中,I/O操作的效率至关重要。
因此,Telum II中的DPU与处理器的对称多处理(SMP)架构紧密相连,并配备了独立的L2缓存。
DPU架构由四个处理集群组成,每个集群包含8个可编程微控制器内核,共计32个内核。
这些内核通过本地一致性结构互连,保持了整个DPU的缓存一致性,并与主处理器集成。
通过将DPU置于PCI接口的处理器端,并实现DPU与运行主要企业工作负载的主处理器之间的连贯通信,整个系统的I/O管理功耗降低了70%。

AMD:详细介绍Zen 5核心架构
在Hot Chips 会议上,AMD详细介绍了其新一代 Zen 5 核心架构,该架构预计将为公司未来的高性能个人电脑发展提供强大动力。
AMD 首先明确了 Zen 5 架构的设计目标。在性能提升方面,Zen 5 力求在单线程(1T)和多线程(NT)性能上取得显著进步,旨在平衡跨核的 1T/NT 指令和数据吞吐量,构建前端并行性,增强执行并行性,提升整体吞吐量,实现数据移动和预取的高效性,并支持 AVX512/FP512 数据路径以进一步提高吞吐量和人工智能性能。
AMD 还计划通过 Zen 5 及其变体 Zen 5C 核心引入新功能,包括额外的指令集架构(ISA)扩展、新的安全特性以及扩展的平台支持。
在产品层面,AMD 的 Zen 5 核心架构将首先应用于三个系列的产品中,分别是Ryzen 9000 Granite Ridge台式机CPU、Ryzen AI 300Strix笔记本电脑CPU和第五代EPYCTurin数据中心CPU。
AMD 表示,Zen 5 架构将再次以显著提升性能的步伐呈现,特别是 AVX512 拥有 512 位浮点(FP)数据路径,这将有助于提升吞吐量和人工智能性能。
Zen 5 提供高效、高性能、可扩展的可配置解决方案,其中 Zen 5 实现峰值性能,而 Zen 5C 则着重于效率,两者均支持 4nm 和 3nm 工艺节点。

高通:骁龙X Elite中的Oryon CPU
在2024年Hot Chips会议上,高通公司详尽地介绍了骁龙X Elite中的高通Oryon CPU。
高通Oryon是专为Snapdragon X Elite系统级芯片(SoC)设计的CPU。
高通公司指出,即便调度器的规模有所增加,它依然能够满足时序要求,并有效缓解了某些瓶颈问题。
此外,该调度器除了执行加载/存储操作外,还能进行其他操作(可能包括数据存储操作),其额外的容量有助于吸收这些额外操作。
Oryon的L1数据缓存容量为96KB,它采用多端口设计,并基于代工厂的标准位单元进行设计。

高通公司确实考虑过采用更大容量的数据缓存,但最终选择了96KB的设计,以确保满足时序(即时钟速度)的要求。单个核心的传输能力略低于100GB/s。
预取技术在现代处理器核心中扮演着至关重要的角色。
Oryon特别强调了预取技术的重要性,它通过各种标准和专有预取器分析访问模式,并尝试在指令请求数据之前主动生成请求。
高通公司通过使用各种访问模式测试软件来展示预取器如何减少可见的加载延迟。
预取器所识别的模式具有较低的延迟。
对于简单的线性访问模式,预取器能够提前足够远地运行,几乎可以完全隐藏L2延迟。
在系统层面,骁龙X Elite拥有12个核心,这些核心被划分为三个四核心集群。
虽然后来该功能得到了实现,但并未出现在骁龙X Elite中。
这一策略与英特尔和AMD的做法形成鲜明对比,后者采用不同数量的核心来实现广泛的功率目标。
高通公司希望将Oryon的应用范围扩展到笔记本电脑以外的其他领域。

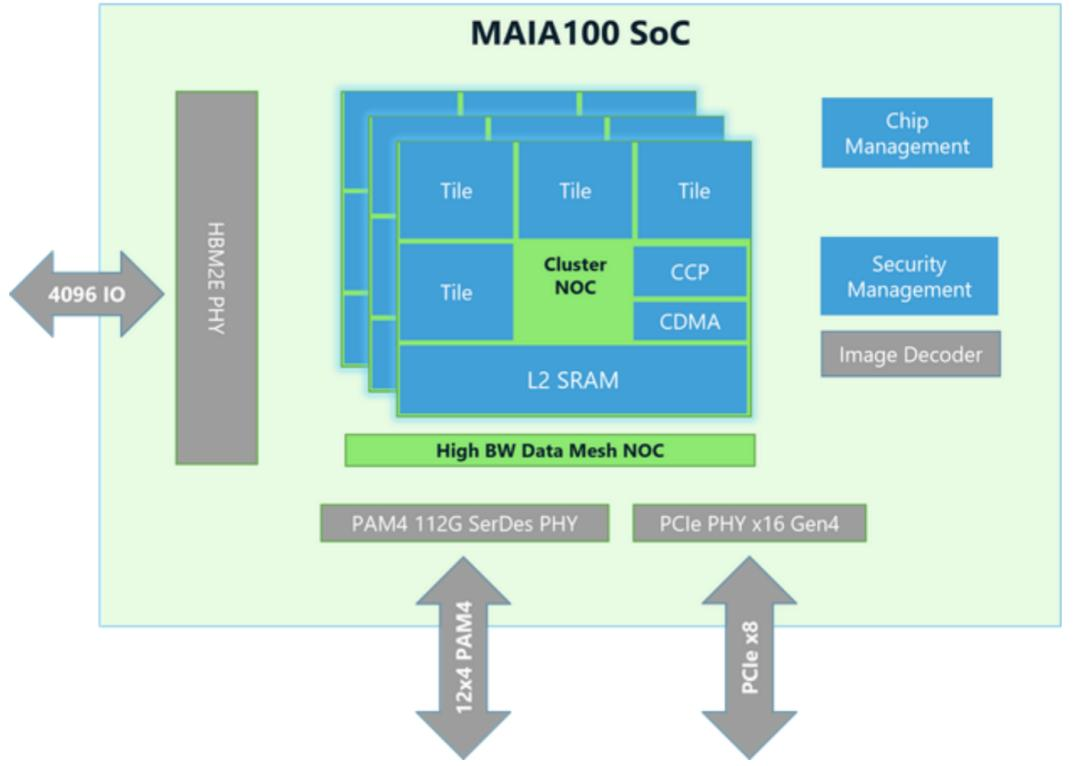
微软:Maia 100第一代自定义 AI加速器
在Hot Chips会议上,微软公布了Maia 100的详细规格。
Maia 100作为微软首款定制化的AI加速器,是为在Azure平台上部署的大型AI工作负载量身打造的。
Maia 100系统通过垂直集成来优化性能并降低成本,整合了定制的平台架构、服务器板以及软件堆栈,旨在提升Azure OpenAI服务等高级AI功能的性能和成本效益。
该加速器是为云基础的AI工作负载特别设计的。其芯片面积为820mm²,采用台积电N5制程技术及COWOS-S中介层技术制造。
Maia 100的标线尺寸SoC裸片配备了大容量片上SRAM,并结合四个HBM2E裸片,提供每秒1.8TB的总带宽和64GB的存储容量,以满足AI级别数据处理的需求。
该加速器旨在支持高达700W的热设计功耗(TDP),但其配置为500W,能够在提供高性能的同时,根据目标工作负载高效地管理电源。
可以合理推测,Maia 100主要应用于OpenAI的推理业务。在软件方面,它表现出色,能够通过一行代码执行PyTorch模型。
在高密度部署、标准以太网融合ScaleUP、ScaleOut方面表现良好,但若使用RoCE,则需要额外的Tile控制器。
这与英特尔Gaudi3需要中断管理器的情况类似,存在一定的局限性。
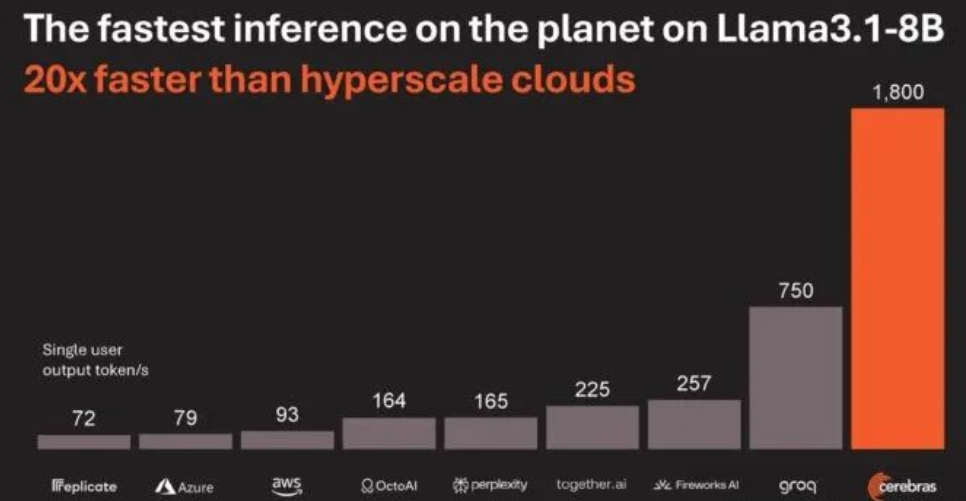
Cerebras:推出WSE-3人工智能芯片
自推出采用整片晶圆制造的芯片技术以来,Cerebras公司近年来的市场推广活动一直以进军由英伟达主导的人工智能芯片市场为核心目标。
Cerebras Systems公司推出了专为训练AI领域中最大型模型而设计的WSE-3人工智能芯片。
这款基于5纳米工艺、拥有4万亿个晶体管的WSE-3芯片,为Cerebras CS-3人工智能超级计算机提供了强大的动力,通过其900,000个针对人工智能优化的计算核心,实现了125千万亿次的峰值人工智能性能。
特别值得注意的是,这一尺寸是其半导体代工合作伙伴台积电目前能够生产的最大尺寸芯片。
目前生成式AI应用存在响应延迟,但快速处理请求可构建无延迟问题的代理应用,快速处理Token能让LLM在多个步骤中迭代答案。
WSE-3芯片每秒可生成超过1,800个Token,但受限于计算能力。
Meta的Llama 3 8B模型是WSE-3的理想应用场景,因为它可以完全装入SRAM,留下足够空间给键值缓存。
Cerebras通过跨多个CS-3系统并行化模型来应对挑战,例如将Llama 3 70B的80层分布在四个系统中。尽管存在性能损失,但节点间延迟较小。
对于更大的模型,Cerebras预计使用12个CS-3系统能实现每秒约350个Token。
Cerebras使用片上SRAM替代HBM,与Groq的LPU不同,后者需要更多加速器来支持大模型。
Cerebras能在不量化的情况下达到性能目标,而Groq使用8bit量化以减少模型大小和内存压力,但牺牲了准确性。
然而,仅比较性能而不考虑成本是不公平的,因为WSE-3芯片的成本远高于Groq LPU。

FuriosaAI:最新研发的AI加速器RNGD
在Hot Chips会议上,FuriosaAI正式发布了其最新研发的AI加速器RNGD,该产品专为数据中心的高性能、高效率大型语言模型(LLM)以及多模态模型推理量身定制。
RNGD具备150W的热设计功耗(TDP)、创新的芯片架构以及HBM3等先进内存技术,针对严苛要求的LLM和多模态模型推理进行了精细优化。
FuriosaAI在获得台积电代工的第一颗芯片后仅三周,便提交了首个MLPerf基准测试成绩。
随后,通过编译器增强技术,在六个月后的MLPerf更新提交中实现了113%的性能增长。
简而言之,FuriosaAI充分利用了芯片的全部潜能。
在执行GPT-J 6B模型时,单个RNGD每秒可生成约12个查询。随着未来几周及数月内软件堆栈的持续改进,这一数字预期将有所提升。
根据目前的性能表现,RNGD能够在较低的TDP下实现优异的性能,显示出其强大的实力。
然而,迄今为止,FuriosaAI一直保持低调,因为他们深知,在该行业中,对于尚未实现的技术,过度炒作和大胆承诺是不被需要的。

Tenstorrent:Blackhole成为独立AI计算平台
芯片工程师Jim Keller,因其在业界的杰出贡献而备受瞩目,他作为Tenstorrent公司的首席执行官,在Hot Chips 2024会议上展示了更多关于公司Blackhole芯片的细节。
据悉,Blackhole是Tenstorrent公司下一代独立AI计算平台,将搭载140个Tensix++核心、16个中央处理器(CPU)核心以及一系列高速互连技术。
Blackhole芯片预计可提供高达790万亿次运算每秒(TOPS)的计算能力,采用FP8数据格式。
Blackhole芯片预计将于2023年及以后推出,代表了对前代Grayskull和Wormhole芯片的重大技术进步。
芯片内部集成了16个RISC-V核心,这些核心被划分为4个集群,每个集群包含4个核心。
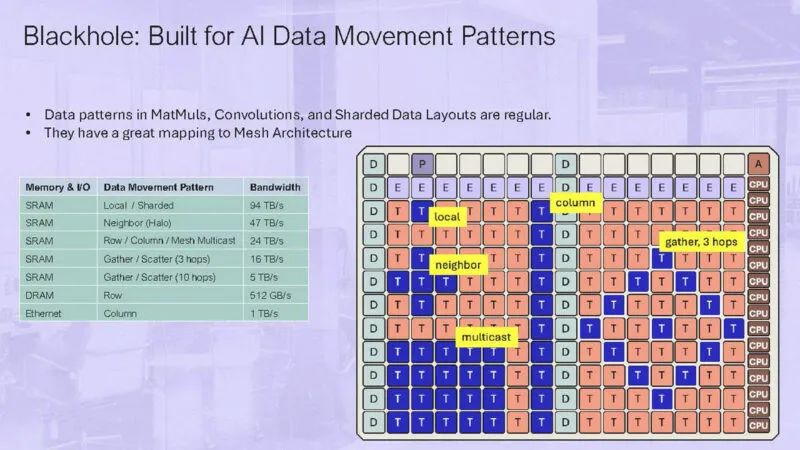
Tensix核心位于芯片中心,而以太网接口则位于芯片的顶端。
该芯片具备10个400Gbps的以太网端口和512GB/s的带宽性能。
其中16个大型RISC-V核心能够运行Linux操作系统;而其余的752个RISC-V核心则被定义为[小型]核心,它们支持C语言编程,但不兼容Linux操作系统。
这些小型RISC-V核心被设计用于可编程计算、数据传输和存储任务。
在RISC-V核心与以太网技术的结合使用方面,Tenstorrent公司正致力于推动开放系统的AI加速技术,这一点颇具前瞻性。
正是由于这种设计理念,以太网技术,特别是51.2T的高速以太网,将在AI领域扮演关键角色。
类似Blackhole这样的AI芯片正是利用高端以太网技术实现性能的扩展。
结尾:
随着AI热潮推动数据中心激增,能源需求同步增长,微软、谷歌等大型科技公司投资数十亿美元建设数据中心基础设施。在此背景下,节能成为关键议题。
为应对日益复杂的 AI 模型和大规模数据处理需求,芯片在算力与带宽方面不断突破,芯片架构不断创新以适应各类计算需求。
部分资料参考:半导体行业观察:《热门芯片,亮相Hotchips》,芝能智芯:《英特尔Lunar Lake AI PC芯片》,芯芯有我:《Hot Chips 2024 分析》,半导体产业纵横:《Hot Chips,芯片疯狂》,芯智讯:《晶圆级AI芯片WSE-3推理性能公布:在80亿参数模型上每秒生成1800个Token》,芯片讲坛:《AI芯片市场,再一次迎来激烈的竞争》,电子工程世界:《AI芯片,再一次开战》
本公众号所刊发稿件及图片来源于网络,仅用于交流使用,如有侵权请联系回复,我们收到信息后会在24小时内处理。
推荐阅读:



商务合作请加微信勾搭:
18948782064
请务必注明:
「姓名 + 公司 + 合作需求」