随着人工智能、大数据等领域的兴起,计算机系统的规模和复杂度都有了显著提升。市面上出现了许多高速外设,比如高速固态硬盘、TCP/IP卸载引擎、高速网卡、高性能显卡和高性能GPU等。为了充分发挥高速外设的性能优势,必须确保外设与CPU之间的数据吞吐量大于外设自身的吞吐量,否则CPU接口将成为限制系统性能的瓶颈,所以CPU与外设之间的高速传输成为了亟需解决的问题,而DMA技术成为该问题的重要解决方案之一。
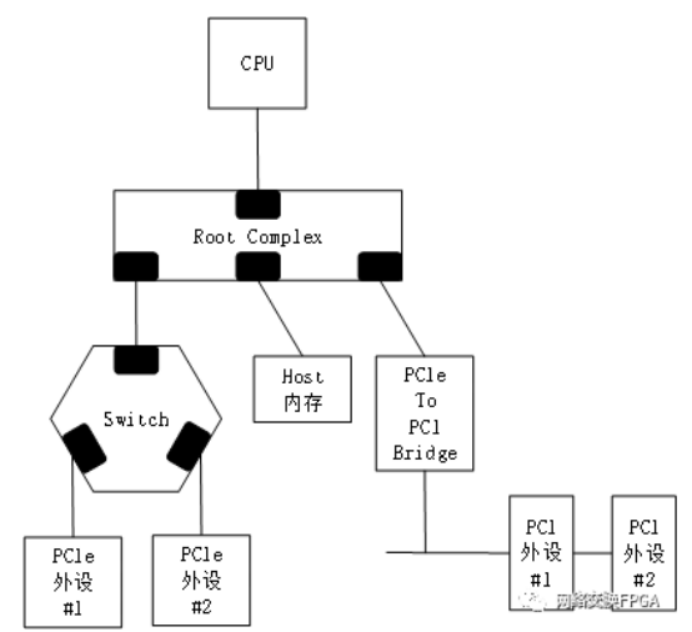
如图所示,通用处理器的结构主要由CPU、RC、Host主存、PCIe外设和PCI外设组成。在处理器工作过程中,CPU需要与Host主存和PCIe外设进行频繁的数据交互。CPU与PCIe外设之间有两种通信方式:第一,PIO操作,特点是每次访问的数据量小,一般用于CPU对PCIe外设寄存器空间的读写操作。PIO访问的优势在于操作简单,缺点在于需要占用CPU资源,访问速率低且容易达到瓶颈。在高速外设出现之前,系统性能瓶颈在于外设自身的吞吐量,所以CPU使用PIO操作进行数据传输也不会拖累系统的整体性能。第二,DMA操作,特点是每次访问的数据量大,一般用于CPU和PCIe外设之间的大数据通信,但是通信过程中,CPU需要申请一定大小的Host主存作为DMA缓冲区。DMA访问的优点在于数据搬移过程不需要CPU干预,且能够以极高的吞吐量完成外设与CPU之间的数据传输。
综上所述,DMA技术指的是在外设与主机内存之间的数据传输过程中不需要CPU干预的一种数据传输方式。
随着DMA技术的不断发展和演化,出现了一些成熟的DMA套件,比如Xilinx公司提供的XDMA,套件中包括DMA控制器的硬件逻辑和软件驱动,为DMA传输提供了相对完整的解决方案。这类IP已经将DMA控制器的核心模块封装在IP内部,用户只需要使用IP提供的标准数据总线接口就可以完成DMA读写操作。
DMA套件降低了DMA技术的使用门槛,缩短了项目的开发周期,提高了系统的稳定性,但是套件中提供的DMA控制器不能进行定制化的设计,灵活性较差。目前常用的DMA技术主要分为两种类型:Block DMA和Scatter-Gather DMA。
Block DMA,也称阻塞式DMA,Block DMA读操作中驱动与硬件的交互流程如图所示,详细的流程描述如下:
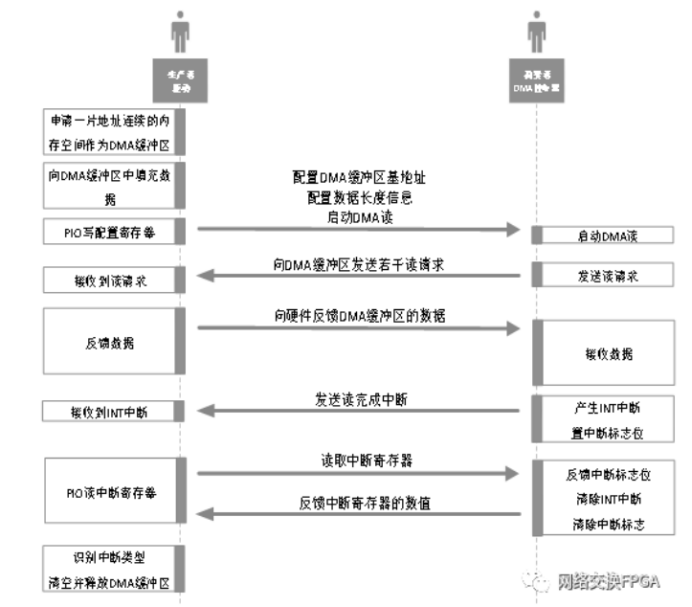
图2:Block DMA读的交互流程
Step1:驱动向内核申请一定大小的主存作为DMA读写缓冲区。需要强调的是,缓冲区的物理地址必须是连续的,不同内核允许分配的连续内存空间的大小是不同的,通常情况下,连续内存空间的申请难度与其大小成正比。
Step2:驱动将应用缓冲区中的数据拷贝至DMA缓冲区。
Step3:驱动配置相关寄存器来启动DMA读,比如基地址寄存器、长度寄存器和控制寄存器等。驱动启动DMA读意味着将总线控制权移交至DMA控制器,同时意味着搬移数据的过程不需要CPU的干预。
Step4:DMA控制器接收到启动DMA读的命令后,根据基地址寄存器和长度寄存器的信息,向DMA缓冲区发送Mrd报文。
Step5:RC将DMA缓冲区数据封装在Cpld报文中并反馈至DMA控制器。DMA控制器接收并解析Cpld报文来获取有效数据,并统计Cpld报文中的有效数据量。
Step6:当DMA控制器接收的有效数据量与Mrd报文申请的数据量相等时,产生硬线INT中断和中断标志位。
Step7:驱动检测到INT中断,并通过PIO读操作读取中断寄存器。
Step8:控制器将中断标志位反馈给驱动,清除硬线INT中断和中断标志位。
Step9:驱动根据中断标志位识别中断类型属于DMA读完成中断。
Step10:驱动清空并释放DMA缓冲区,一次DMA读操作结束。
根据以上流程,总结两点结论:第一,DMA读写缓冲区的物理地址必须是连续的。申请大片连续内存空间的难度大,所以当传输的数据量较大时,驱动需要将数据进行拆分后通过多次DMA来传输,传输次数的增加降低了PCIe的带宽利用率。第二,硬件和驱动之间的交互逻辑简单且具有阻塞式的特点,即一次DMA操作彻底完成之前不能配置下一次DMA操作的参数。控制器在传输数据时,驱动处于空闲状态,而驱动在拷贝数据时,控制器处于等待状态,驱动与控制器无法同时处于工作状态,降低了DMA传输的效率。
Scatter-Gather DMA,也称分散聚集式DMA,分散聚集指的是它可以将分散的内存空间通过链表的方式聚集在一起。相比于Block DMA,Scatter-Gather DMA的操作流程更加复杂,但是可以提高主机内存的利用率以及DMA传输的效率。
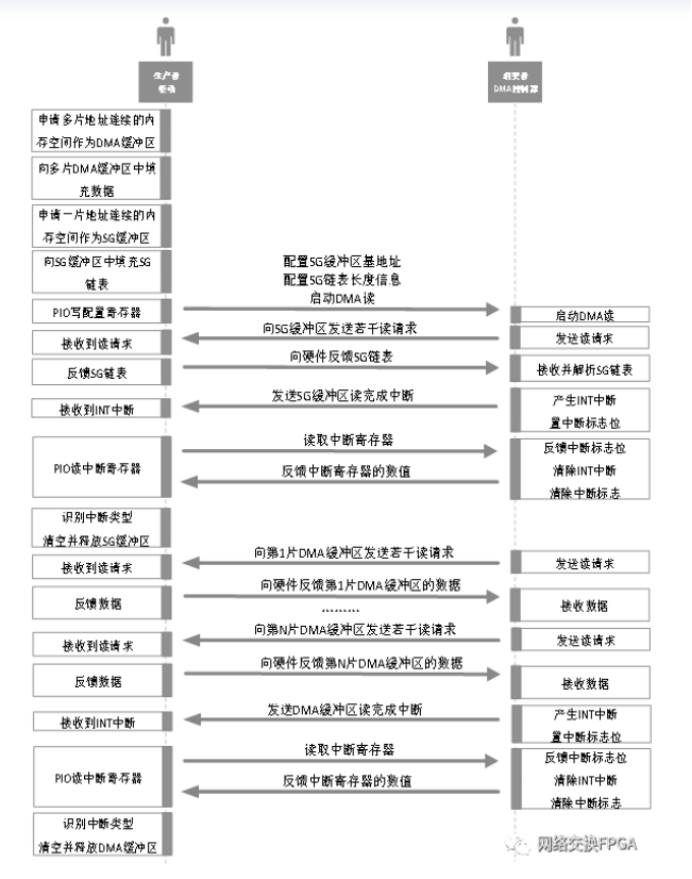
Scatter-Gather DMA读操作中驱动与硬件的交互流程如图所示,其中,驱动作为数据的生产者,DMA控制器作为数据的消费者。详细的流程描述如下:
Step1:驱动根据传输的数据量决定申请DMA缓冲区的大小。需要强调的是,DMA缓冲区可以由分散的连续内存空间拼接而成。比如驱动需要传输64KB的数据,驱动可以申请16个4KB的DMA缓冲区,然后将16个4KB的DMA缓冲区通过链表的方式拼接为一个64KB的DMA缓冲区。
Step2:驱动从上层协议栈接收有效数据,并将数据从应用缓冲区拷贝至分散的DMA缓冲区。
Step3:驱动申请SG缓冲区,该缓冲区负责存放SG链表,缓冲区的大小取决于SG链表中表项的个数。SG链表的组成方式多种多样,比如文献[27]中提出的一种改进的SG描述符。考虑到驱动的开发难度,本文采用一种简易的描述符构造方式:驱动利用每个分散DMA缓冲区的基地址和长度信息构成一条表项,然后将表项依次排列组成SG链表。SG链表中每一条表项都代表了一段物理地址连续的DMA缓冲区,DMA控制器根据SG链表中的表项信息,依次读取DMA缓冲区的数据。
Step4:驱动将构造的SG链表填入SG缓冲区中。
Step5:驱动将SG缓冲区的基地址和长度信息写入寄存器,并配置控制寄存器来启动DMA读操作。
Step6:控制器启动DMA读,向RC发送Mrd报文读取SG链表。
Step7:RC接收到Mrd,将SG链表封装在Cpld报文并反馈给DMA控制器。
Step8:DMA控制器接收SG链表后,产生硬线INT中断和中断标志位。
Step9:驱动接收到硬线INT中断,立即读取中断寄存器。
Step10:控制器反馈中断标志位,清除硬线INT中断和中断标志位。
Step11:驱动根据中断标志位判断中断类型属于SG缓冲区读完成中断,清空并释放SG缓冲区。
Step12:DMA控制器解析SG链表,依次读取每一条表项对应的DMA缓冲区。首先根据第一条表项对应的缓冲区的基地址和长度,向RC发送Mrd读取DMA缓冲区数据,当第一个缓冲区数据全部读取完毕时,再处理第二条表项,以此类推,直到最后一个表项对应的缓冲区数据全部读取完毕。
Step13:RC接收到Mrd,将DMA缓冲区数据封装在Cpld报文并反馈给DMA控制器。
Step14:DMA控制器接收数据并统计数据总量,当接收到的数据总量等于SG链表对应缓冲区的数据总量时,产生INT中断和中断标志位。
Step15:驱动收到INT中断,立即读取中断寄存器。
Step16:DMA控制器将中断标志位反馈给驱动后,立即清除中断和中断标志位。
Step17:驱动根据中断标志位判断中断类型属于DMA读完成中断,清空并释放所有DMA缓冲区,一次DMA读操作结束。
上述步骤就是SG模式下驱动与硬件之间的完整交互流程,相比于Block DMA,一次SG DMA的流程更加复杂。主要包括两个阶段:第一阶段是硬件读取SG链表,第二个阶段是硬件解析SG链表后根据表项读取DMA缓冲区。这样的设计虽然导致驱动与硬件的逻辑设计难度更大,但同时提升了DMA传输的效率,降低了CPU处理中断的负载,提高了CPU内存的利用率等。
RIFFA架构中的DMA即属于Scatter-Gather DMA。
众所周知,GPU出现的最初目的仅仅是为了图像和视频并行处理的加速,但随着OpenCL 和 NVIDIA 的 CUDA 语言和工具链的出现使 GPU 更易于使用,目前已经成为一种通用的并行加速平台。然而,也正是由于GPU是为图像和视频处理这一类应用而做出来的专用ASIC,显然在非具有图像和视频加速处理特点的其它应用场景下(如计算密集型应用),GPU的加速性能也会大打折扣。在这种情况下,FPGA 与 CPU 结合的加速卡模式应运而生了。RIFFA 并不是将 FPGA 集成到传统软件环境中的第一次尝试,也并非唯一的一种架构,但它开源的巨大优势引起了越来越多的关注。如有学者将RIFFA应用于基因测序的加速(https://github.com/BilkentCompGen/GateKeeper),做出目前唯一的成本低廉便携式快速基因测试产品。笔者认为,随着各行各业不同加速应用卸载到网卡等设备的需求越来越多,开源的RIFFA架构必将越来越普及。
RIFFA 是一种开源通信架构,它允许通过 PCIe 在用户的 FPGA IP 内核和 CPU 的主存储器之间实时交换数据。为了建立其逻辑通道,RIFFA 在 CPU 端拥有一系列软件库,在 FPGA 端拥有 IP 核。本文主要针对其中的DMA性能(Scatter-Gather DMA)进行测试。
RIFFA是一个用于PCIe设备的可重用集成框架。
RIFFA(用于FPGA加速器的可重用集成框架),它是用于通过PCIe总线从主机CPU到FPGA相互之间进行数据交互的简单框架。该框架要求具有PCIe的上位机PC或者工控机和带有PCIe接口的FPGA硬件。RIFFA中间层驱动支持Windows和Linux,底层驱动FPGA PCIe IP核支持Xilinx和Altera芯片,上位机应用层支持LabVIEW、C / C ++、Python、Matlab和Java。
软件方面,RIFFA有两个主要功能:数据发送和数据接收。上层提供C / C ++、Python、MATLAB、Java下的DLL链接库。中间层驱动程序在每个系统(Linux和Windows操作系统)下支持识别多个FPGA(最多5个)。
硬件方面,用户访问具有独立发送和接收信号的接口(全双工),无需了解总线地址,缓冲区大小或者PCIe数据包格式。只需在FIFO接口上发送数据并在FIFO接口上接收数据即可。RIFFA不依赖于PCIe桥接器,因此不受桥接器实现的限制。取而代之的是,RIFFA直接与PCIe端点一起使用,RIFFA使用直接内存访问(DMA)传输和中断信号传输数据。这样可以在PCIe链路上实现高带宽。软件和硬件接口都已大大简化。
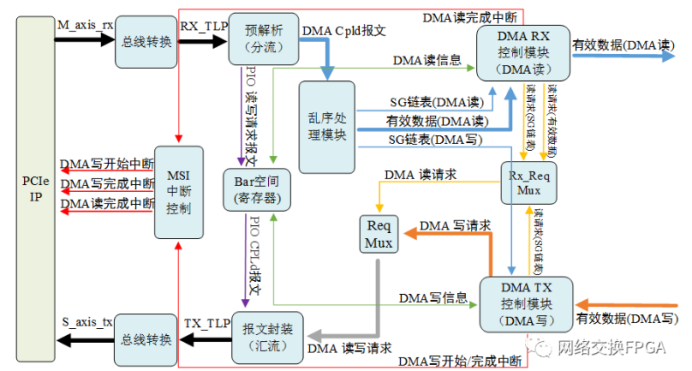
RIFFA的Linux驱动文件夹下有6个C源码文件,riffa_driver.c、riffa_driver.h、circ_queue.c、circ_queue.h、riffa.c、riffa.h。
其中riffa.c和riffa.h不属于驱动源码,它们是系统函数调用驱动封装的一层接口,属于用户应用程序的一部分。
circ_queue.c和circ_queue.h是为在内核中使用而编写的消息队列,用于同步中断和进程;riffa_driver.c和riffa_driver.h是驱动程序的主体。
注意:RIFFA驱动全程采用面向对象的编程思想。
由于篇幅所限,本公众号后续将会给出RIFFA驱动的详细解读。
Riffa测试端系统SG DMA控制器的设计与实现在Xilinx开发平台(具体的FPGA芯片型号:xc7k325tffg676-2和xcku040-ffva1156-2-i)上进行测试,该平台具有丰富的逻辑资源和大量高速接口,支持PCIe Gen3x8总线,理论带宽可达64Gbps。
但是Riffa最大只能支持到gen2x8/gen3x4速率,Riffa目前只能支持32/64/256bit数据位宽,其原作者在2016后就没有对新特新进行支持。
K7325T Riffa测试工程所占资源:
Ku040 Riffa测试工程所占资源
本人亲自测试:gen2x8,在k7和ku040都能达到3.5GByte/s.
在ku040的gen2x8/gen3x4跟k7的gen2x8 性能相似。
通过计算:3.5*8Gbit/s / (40*0.8) = 87.5%,测试表明Riffa的传输效率比较高。
(1)支持xilinx A7/K7的经典7 系列PCIe Integrated IP接口,支持xilinx ultrascale Integrated IP接口,支持64/128 axistream data width.
(2)支持altera PCIe Stratix V, Cyclone V, and Arria V, Hard IP类似接口,支持Stratix IV, Cyclone IV and Arria II devices,支持64/128 axistream data width.
(3)一个主机最多支持5 个fpga,一个Rifffa最多支持12个传输通道
(4)RIFFA中间层驱动支持Windows和Linux
(5)上位机应用层支持LabVIEW、C / C ++、Python、Matlab和Java
(1)本项目自2016年开源后,代码已经8年未更新,虽然Riffa已经相当老旧,已经不维护支持及开发,陷入无人支持状态。
(2)不支持256 bit,不能支持到Gen3x8。
(3)只有数据通信接口,没有控制接口,不能对外部提供控制,对系统集成不方便。
(4)缺少DFT设计,对IP使用不能很好的定位问题。
(5)不支持非DWORD对齐传输,如果需要Byte对齐传输。
(6)不支持mmap传输。
(7)没有仿真环境
版权所有(c)2016,加州大学董事会保留所有权利。
允许以源代码和二进制形式重新分发和使用,无论是否进行修改前提是满足以下条件
• 重新分发源代码必须保留上述版权声明,此条件列表以及以下免责声明。
• 以二进制形式重新分发必须复制上述版权声明,此列表包含-提供的文件和/或其他材料中的附加条款和以下免责声明随着分布.
• 无论是加州大学董事会的名字还是其成员的名字-贡献者可用于背书或推广源自此软件的产品,而无需事先获得特别书面许可
尽管Riffa功能有很多缺陷和支持特性不够丰富,但是Riffa确实是一个优质的PCIe DMA方案,其许可可以提供源代码或者二进制分发,允许修改。作为PCIe的学习和使用都是不可多得的资源。
本人有多年fpga及驱动开发经验,近几年专注于PCIe应用开发和测试,本人打算对Riffa进行大规模改进,增加更多特性,增加工程可测试性和可维护性。欢迎有学习PCIe DMA的技术的小伙伴联系我,一起为这个开源项目添砖加瓦。

