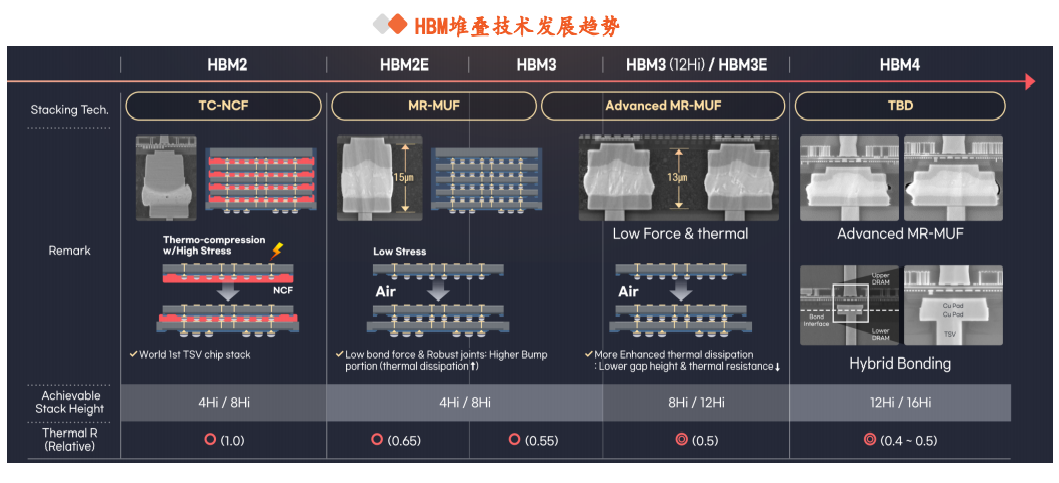

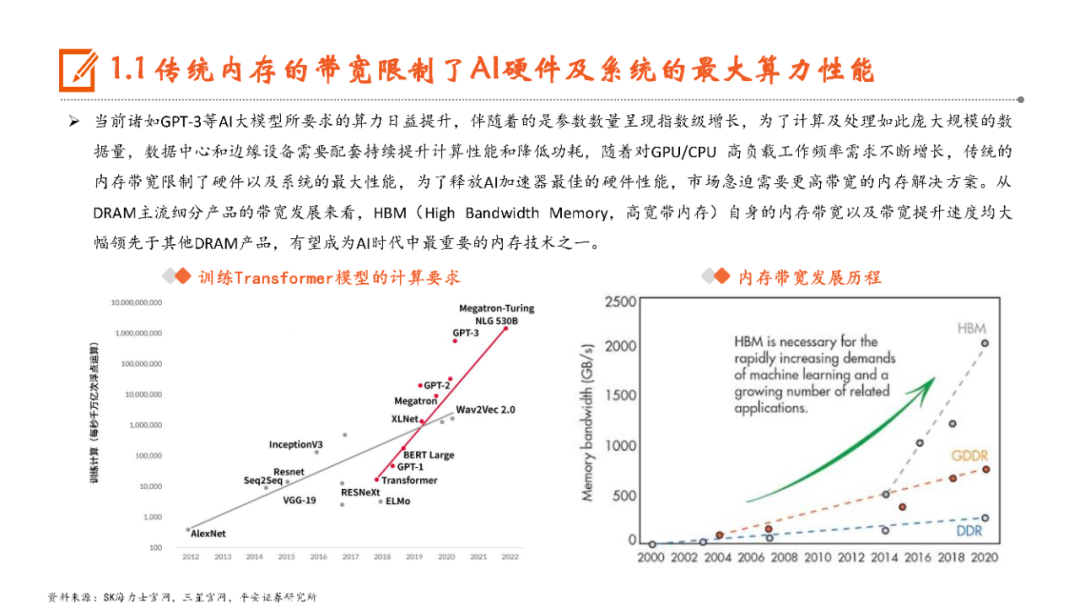
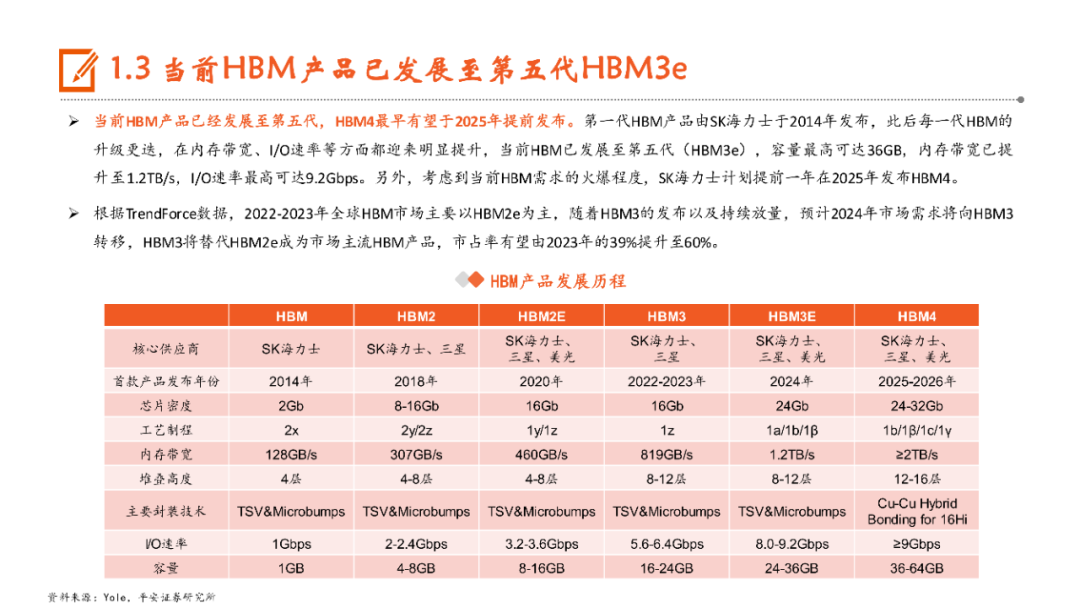
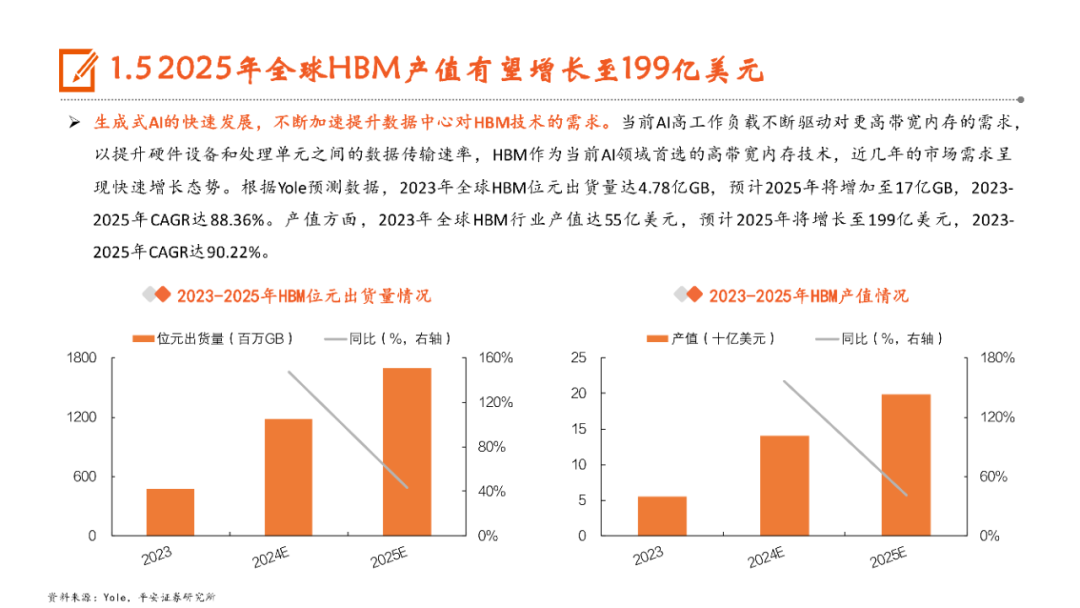
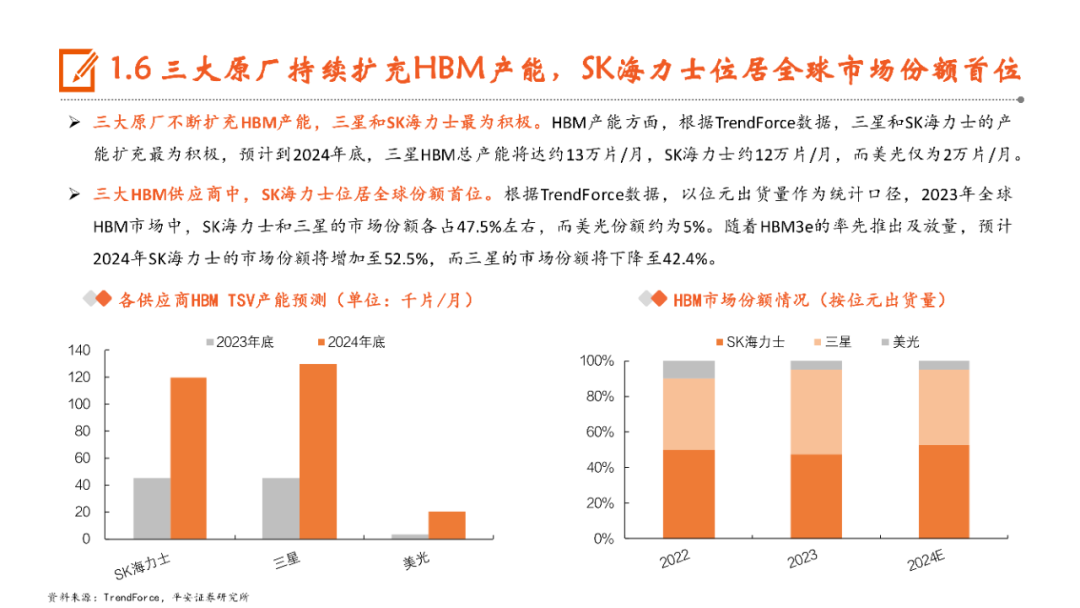
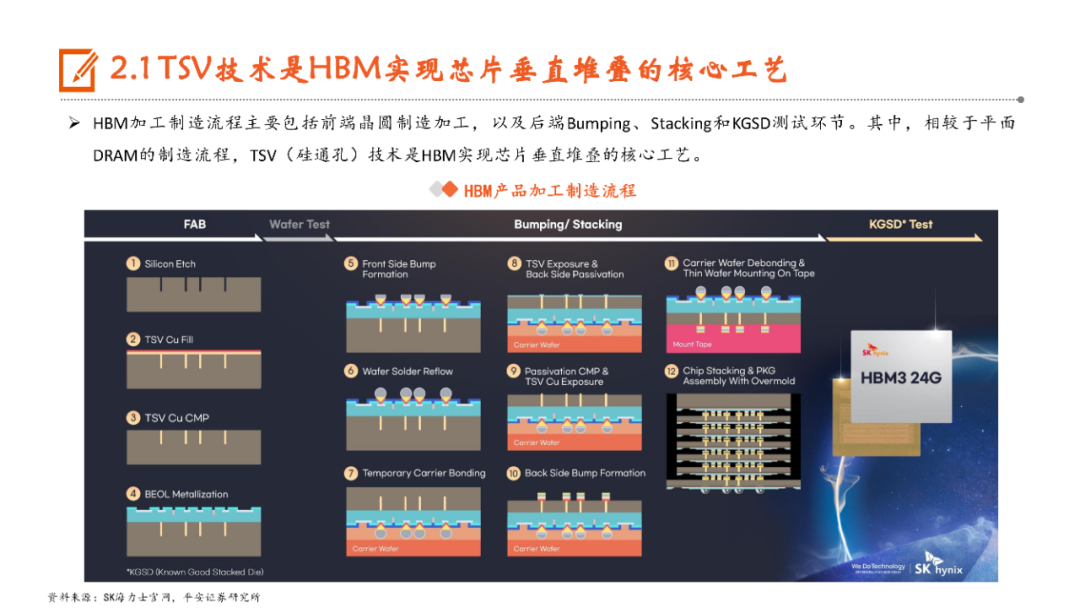
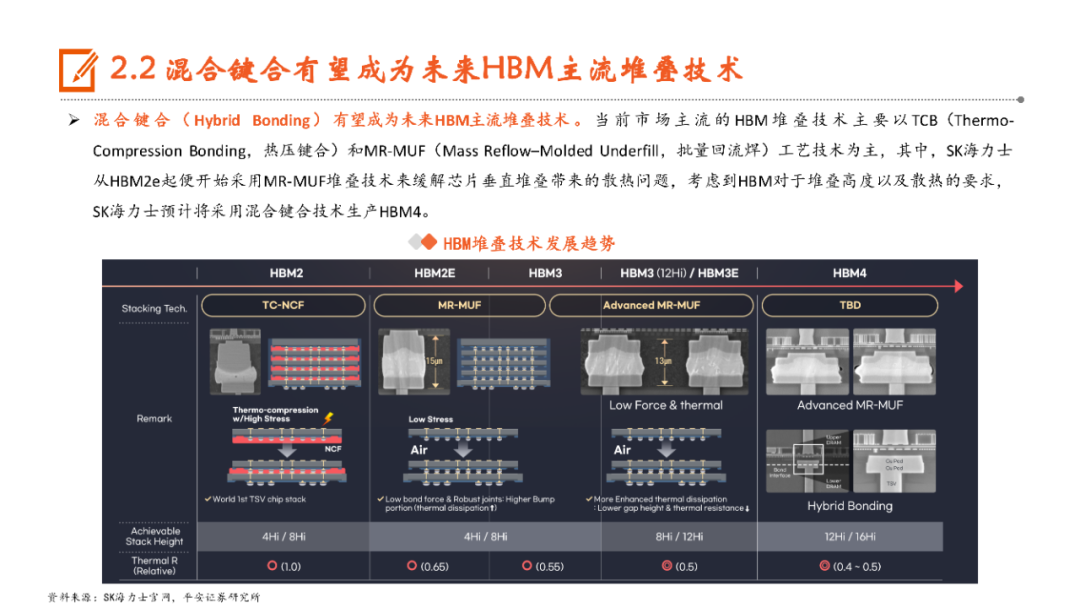
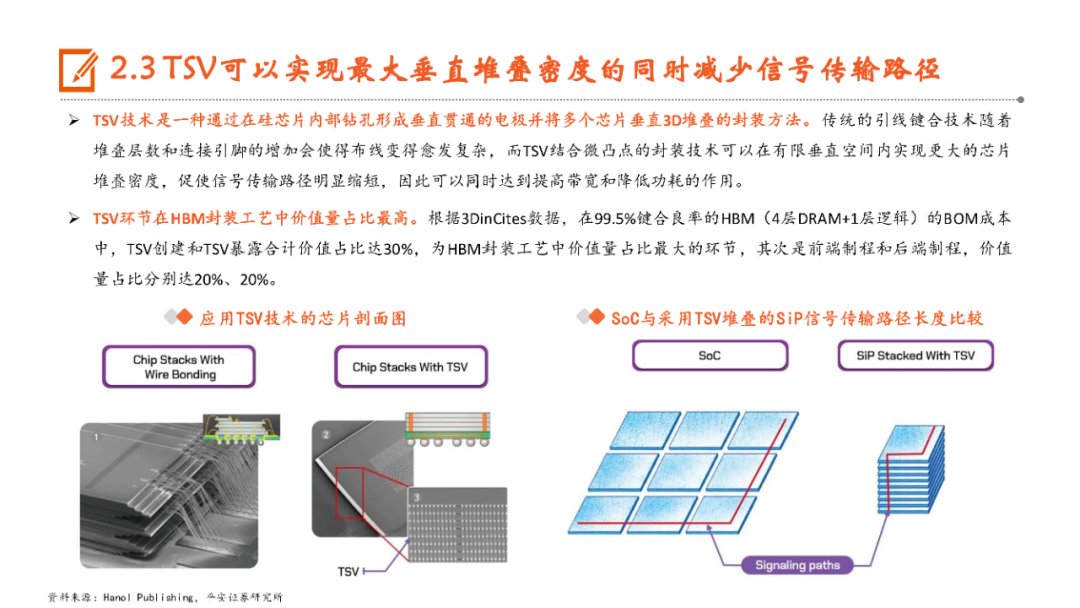
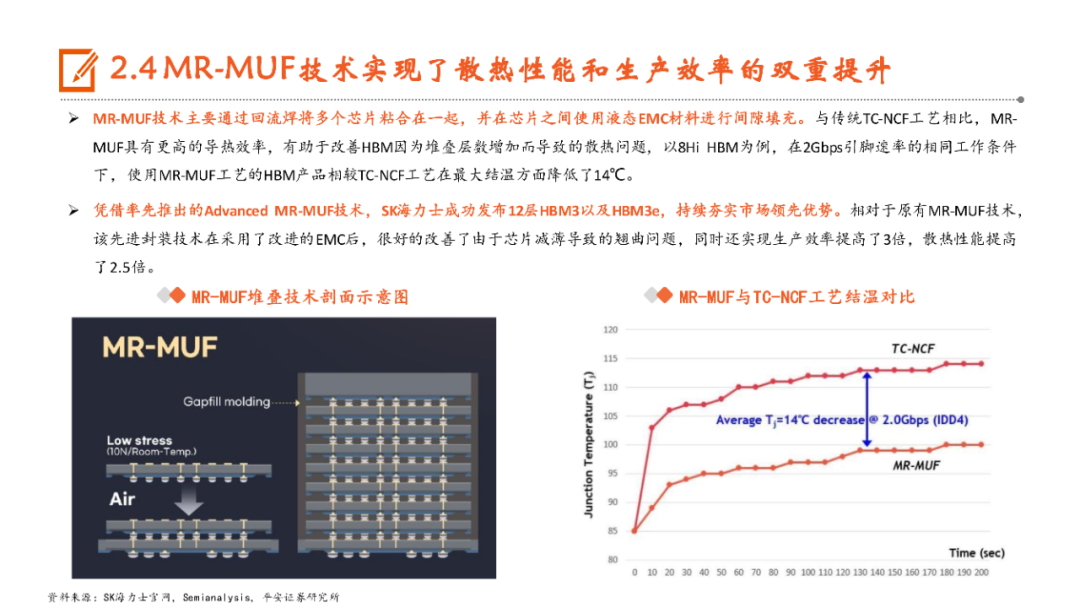
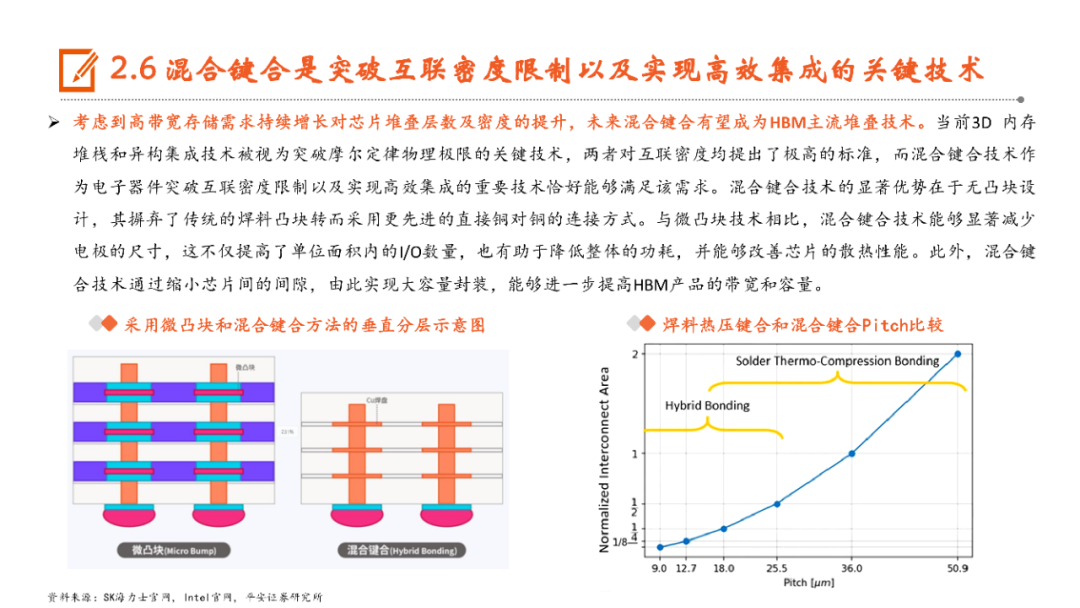
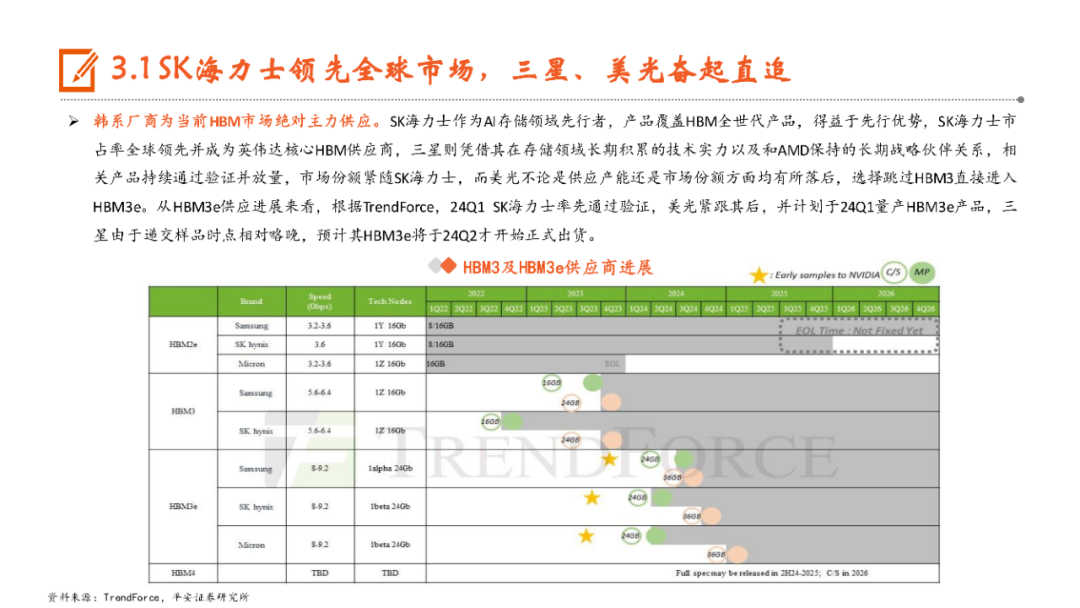
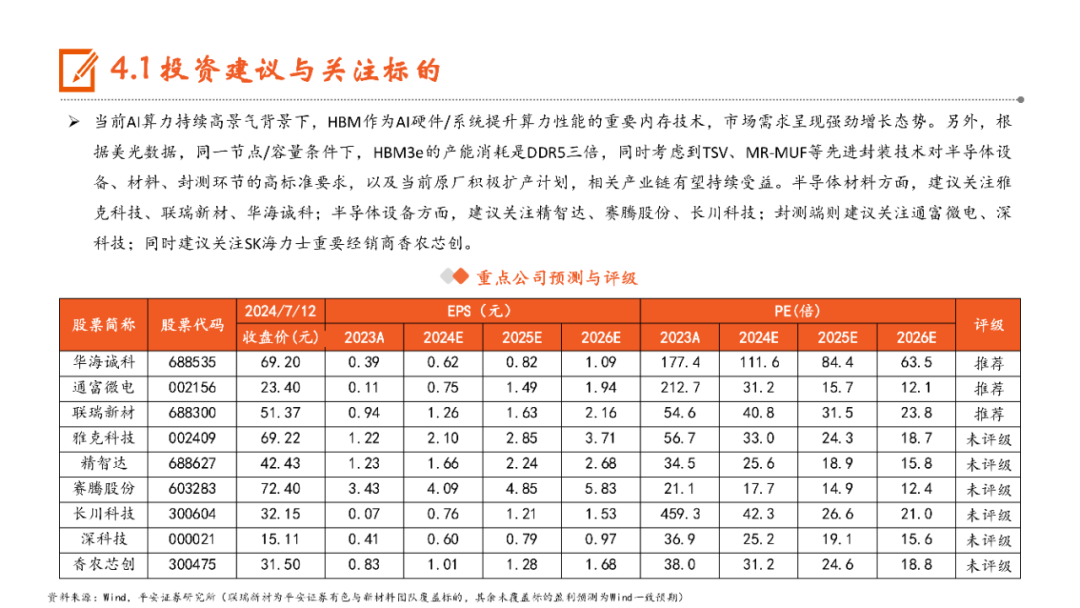
本文来自“《AI行业系列深度报告合集》”,高带宽特性释放AI硬件性能,HBM成为AI时代首选内存技术。当前诸如GPT-3等AI大模型所要求的算力日益提升,伴随着的是参数数量呈现指数级增长,传统的内存带宽及传输速率限制了AI硬件以及系统的最大性能,相较于传统DDR内存,HBM具有高带宽、低功耗、低延时等优势,已成为当前高性能计算、人工智能等领域的首选内存技术。当前HBM产品已经发展至第五代HBM3e,内存带宽相较上一代提升47%至1.2TB/s,堆叠层数最高可达12层,对应最高容量达36GB,当前三大原厂均已入局并在24H1陆续出货,考虑到HBM需求的火爆程度,SK海力士还计划提前一年在2025年发布HBM4。HBM主要采用TSV技术将多个DRAM芯片进行垂直堆叠,并与GPU一同进行封装,形成大容量、高位宽的DDR组合阵列,从而克服单一封装内的带宽限制。在加工制造过程中,TSV是HBM实现芯片垂直堆叠的核心制备工艺,占封装成本达30%。而 从当前原厂采用的封装技术来看,三星主要采用TC-NCF技术,而SK海力士则通过Advanced MR-MUF技术并结合改良EMC材料来进行HBM的封装生产,在改善散热方面具有明显优势。考虑到未来因带宽、容量增长所带来的堆叠层数及密度提升,SK海力士将利用混合键合技术来加工生产HBM4。混合键合摒弃了无凸块设计并采用直接铜对铜的连接方式,相较微凸块技术,能够在进一步提升互联密度的同时实现功耗降低,有望成为未来HBM主流堆叠技术。面向新算力硬件体系的调度技术挑战
面向智能应用的算力硬件调度与管理
1、海外AI研究系列(一):算力帝国的挑战者(2024)
2、海外AI研究系列(二):AI时代的算力领军人1、AI行业系列深度报告(一):光模块:AIGC高景气持续,800G+产品需求旺盛
2、AI行业系列深度报告(二):HBM,高带宽特性释放AI硬件性能,AI高景气持续驱动需求高增行业深度:更快的PCIe6.0,更快的1.6T光模块《算力网络:光网络技术合集(1)》
1、面向算力网络的新型全光网技术发展及关键器件探讨
2、面向算力网络的光网络智能化架构与技术白皮书
3、2023开放光网络系统验证测试规范
4、面向通感算一体化光网络的光纤传感技术白皮书
《算力网络:光网络技术合集(2)》
1、数据中心互联开放光传输系统设计
2、确定性光传输支撑广域长距算力互联
3、面向时隙光交换网络的纳秒级时间同步技术
4、数据中心光互联模块发展趋势及新技术研究











1、Computex 2024系列AMD主题演讲:CPU+GPU+UA互联厂商
2、Computex 2024英伟达主题演讲:AI时代如何在全球范围内推动新的工业革命2024面向未来的算力网络连接:中国算力网络市场发展白皮书2024面向AIGC的数智广电新质生产力构建白皮书存储器行业:双墙阻碍算力升级,四大新型存储应用探讨生成式人工智能专题研究:国内大模型(生成式AI加速,国内厂商聚力突破)2、存储专题系列二:存力需求与周期共振,SSD迎量价齐升 国产AI算力行业报告:浪潮汹涌,势不可挡(2024)2024中国“百模大战”竞争格局分析报告(2024)《半导体行业深度报告合集(2024)》
《70+篇半导体行业“研究框架”合集》
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


