

 芝能智芯出品
芝能智芯出品
在2024年的Hot Chips会议上,Tesla展示了其AI超级计算机DOJO的最新进展,尤其是其独特的网络架构——Tesla传输协议以太网(TTPoE)。
特斯拉不仅打造了专属的AI加速器,还开发了自家的以太网传输协议TTPoE,而非传统的TCP/IP协议,创新解决方案展现了Tesla在AI领域的自研技术实力与战略思考。

特斯拉 DOJO AI 网络的背景
特斯拉DOJO是为训练深度学习模型而设计的超级计算机,旨在加速其自动驾驶技术的发展。DOJO不仅仅是硬件创新,更在于其独特的软件和网络架构。
为了克服传统TCP/IP网络在处理海量数据时的速度瓶颈,Tesla决定引入TTPoE,构建了一个百亿亿级别的AI网络,这一选择背后的深层原因与其AI训练需求密切相关。

● 为什么特斯拉放弃TCP/IP?
特斯拉认为,TCP/IP协议在AI集群中的表现过于缓慢,尤其在面对高带宽和低延迟需求时。TCP/IP的复杂状态机和过多的包控制机制,使得其在高性能计算环境中显得笨重。
而另一种常见的无损网络解决方案——RDMA,尽管通过优先流控制(PFC)实现了无损传输,但其硬件需求高,成本高昂且对网络产生负面影响。Tesla发现这些协议无法满足DOJO对于速度、成本和性能的多重需求,因此选择自研协议以突破现有瓶颈。

● TTPoE 的独特性
TTPoE(Tesla传输协议以太网)是一种专门为Tesla AI集群设计的传输层协议,在硬件中实现点对点传输。与传统的网络架构不同,TTPoE不需要特制的交换机,仅依赖二层传输。这使得特斯拉能够显著降低硬件成本,同时提高网络性能。
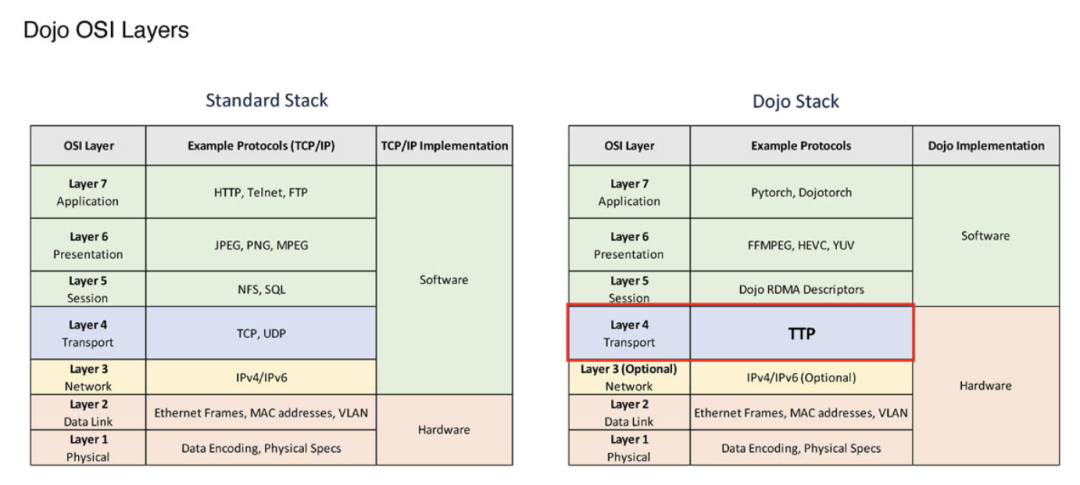
TTPoE并非简单的模仿UDP,而是采用一种有损的数据传输机制,允许数据包丢失并进行重试。这种设计类似于TCP,但又没有TCP的重负荷和过多的包确认过程。这一取舍使得TTPoE可以在高性能的AI训练场景中高效运行,而无需完全保障每个数据包的传输完美无损。
特斯拉的解决方案更关注的是整体吞吐量和传输效率,而非数据的完美传递,这对于AI训练来说至关重要。
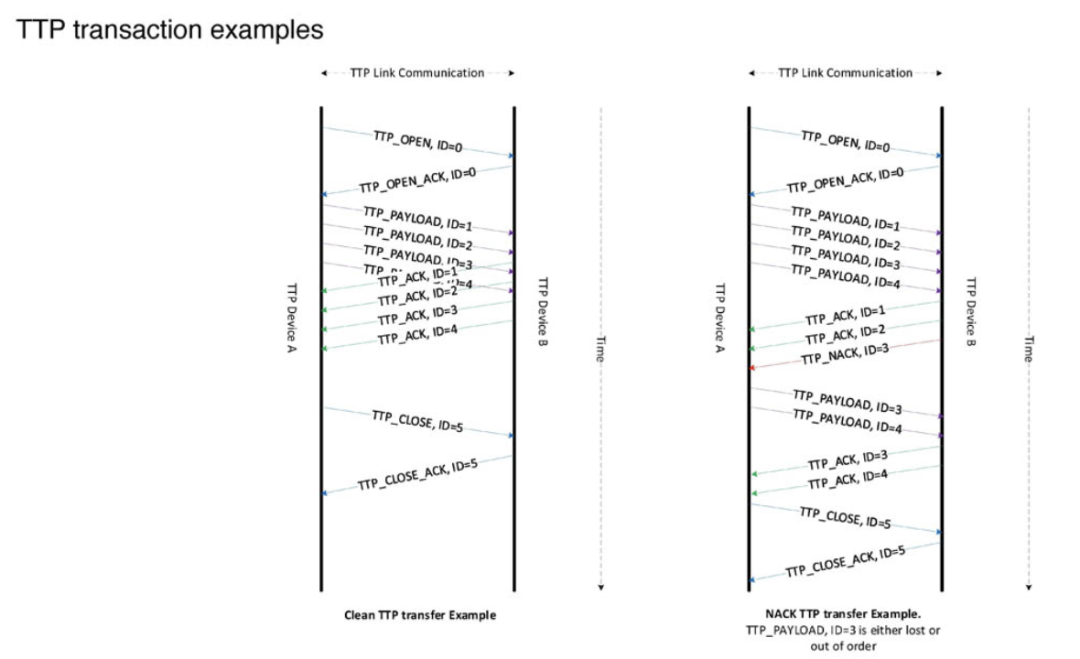
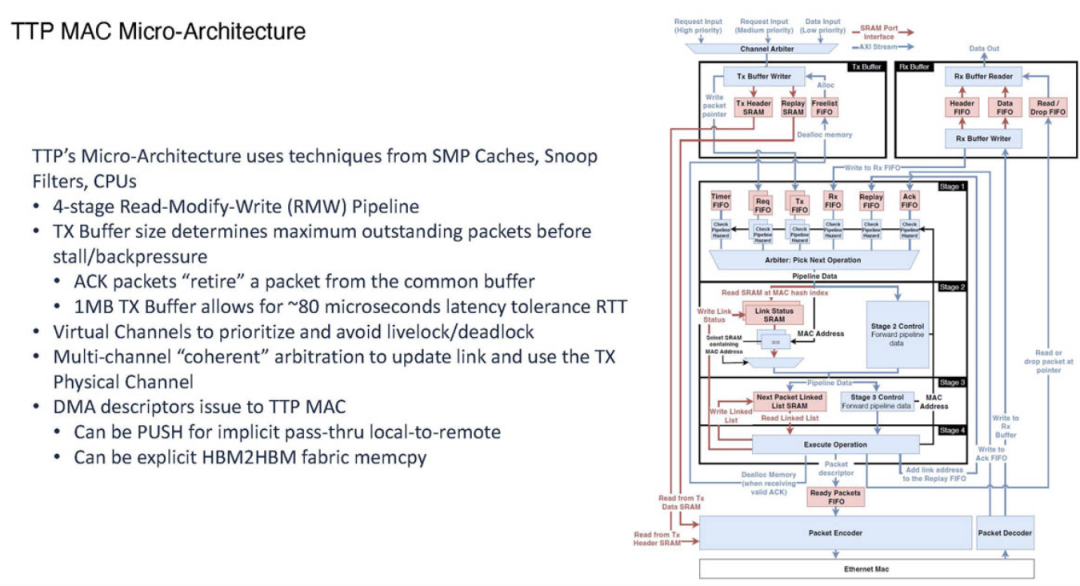
● TTPoE 的微架构设计
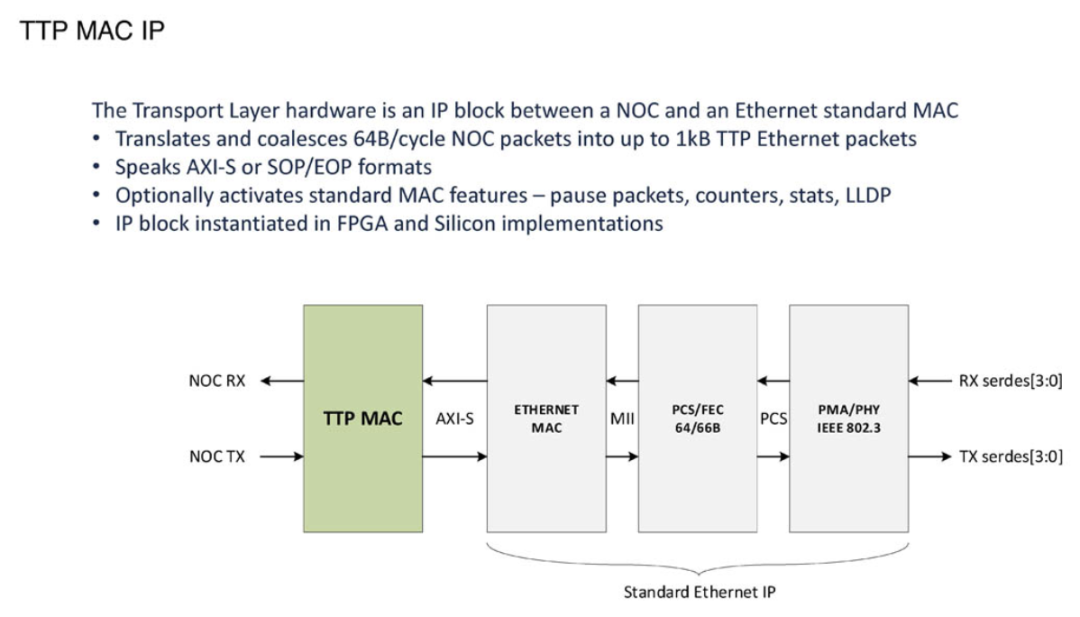
TTPoE协议的核心是其微架构设计。特斯拉将其传输协议的实现直接集成到硅片和FPGA中,使数据传输效率最大化。
1MB的传输(TX)缓冲区作为第一代产品的一部分,被设计为类似于L3缓存的结构,配合高带宽内存(HBM),这一设计大大减少了数据在不同存储器之间传输的延迟。
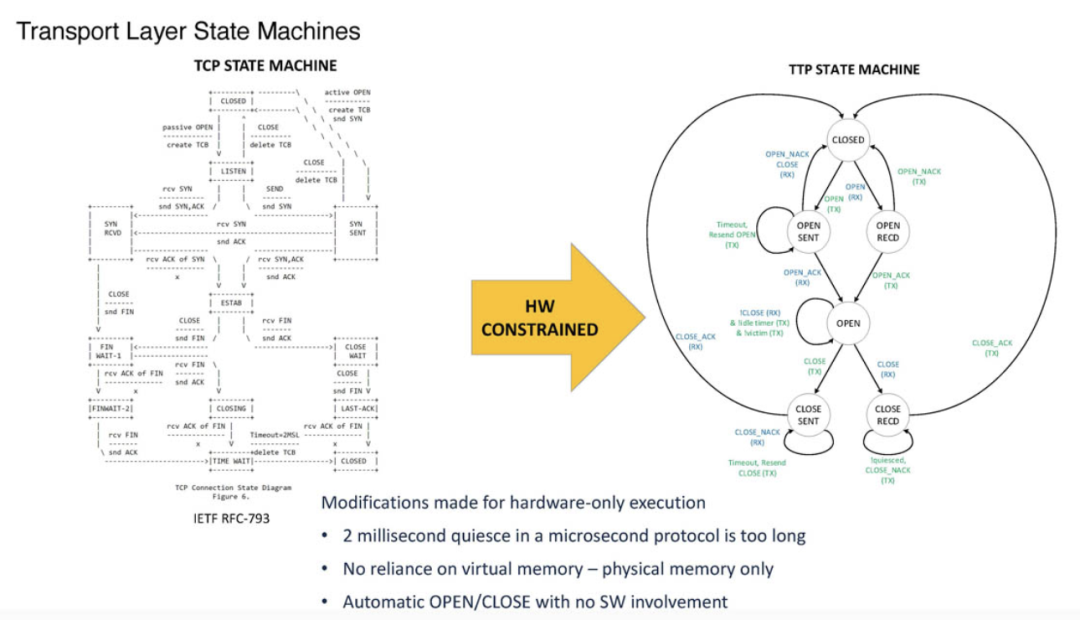
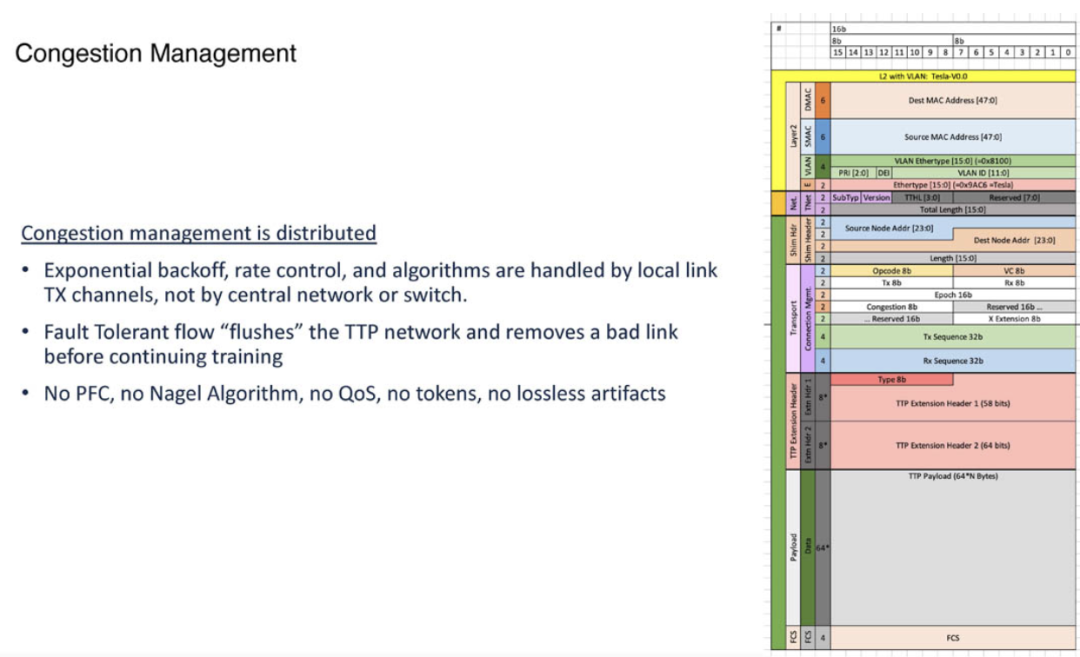
TTPoE使用了本地链路通道进行拥塞管理,而非依赖交换机或网络级别的控制。这种独特的本地处理方式大大减少了拥塞管理的复杂性,也避免了高负载情况下对整个网络性能的拖累。
虽然TTPoE支持QoS(服务质量)管理,但在实际应用中特斯拉选择关闭了该功能,以进一步提升性能和简化管理。

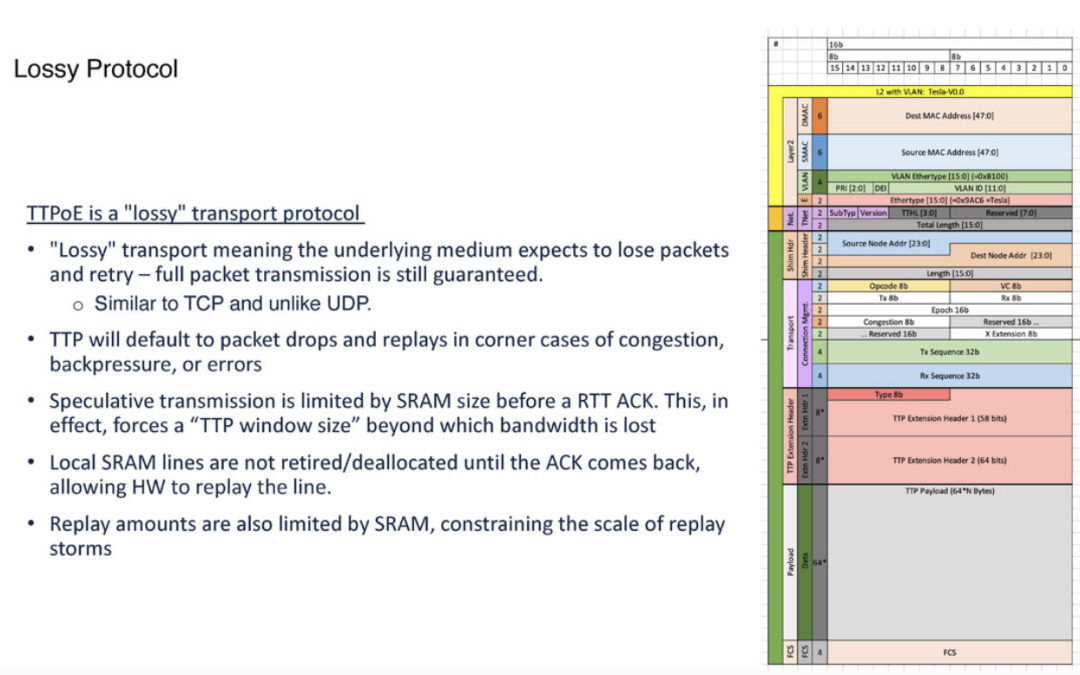
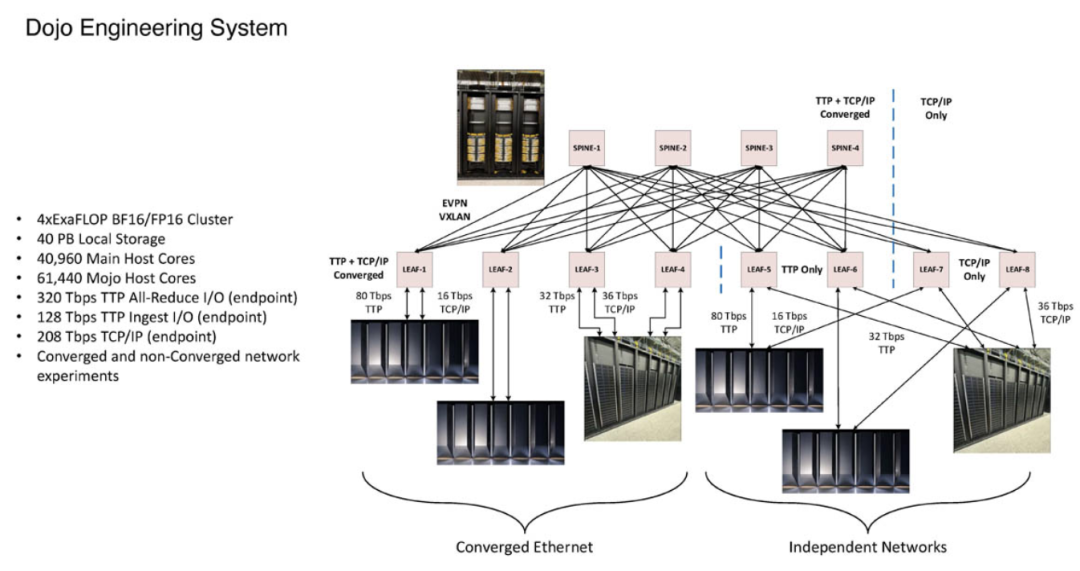
DOJO 超级计算机的硬件创新
Tesla DOJO的硬件设计进一步强化了其网络架构的独特性。DOJO的100Gbps网络接口卡(NIC)被称为Mojo,其运行功率低于20W,配有8GB DDR4内存以及板载的DOJO DMA引擎。
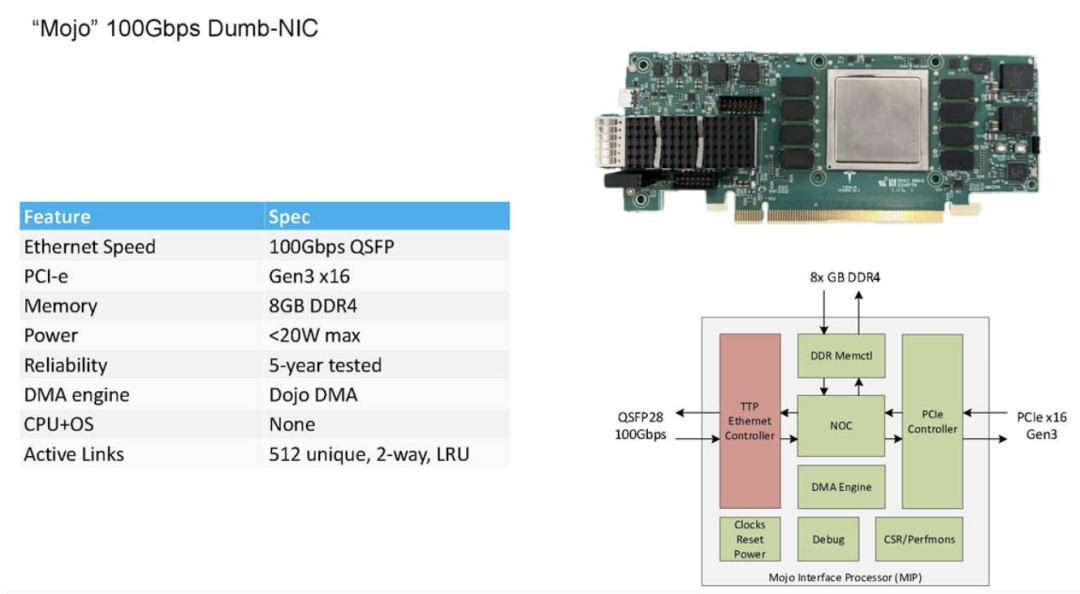
这些硬件组件都经过定制,专门优化以满足TTPoE协议的高效传输需求。特斯拉的DOJO还采用了一个带有32GB HBM的接口处理器,支持高达900GB/s的传输速率。
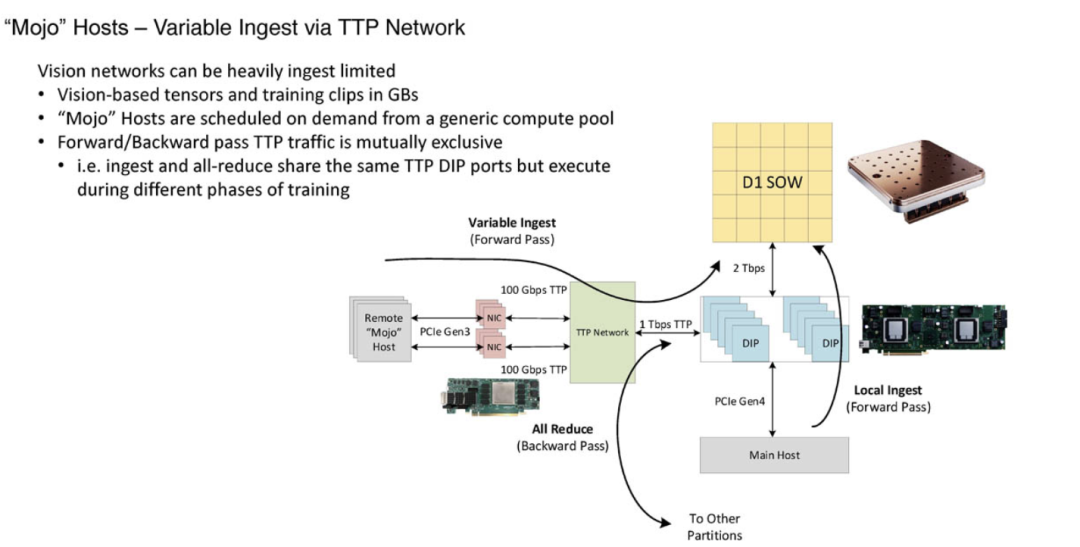
这种强大的数据处理能力,再加上内部集成的TTPoE协议,使得DOJO能够在不依赖第三方设备的情况下,完成海量数据的高速传输。
特斯拉在其AI超级计算机中全面部署TTPoE,显示了其强大的自研能力和对未来的布局。然而,TTPoE不仅仅适用于DOJO系统。特斯拉还加入了UltraEthernet联盟,这意味着其创新的网络协议可能在未来被广泛应用于其他领域。
特斯拉的此举或许代表着一种新的网络架构趋势,将定制化与高效化带入到其他高性能计算和数据中心环境中。

特斯拉选择Arista交换机为TTPoE提供支持,这进一步强化了其系统的灵活性与兼容性。通过优化跳数和降低延迟,TTPoE将以太网在AI集群中的应用潜力进一步释放,为未来的超大规模AI训练网络铺平了道路。

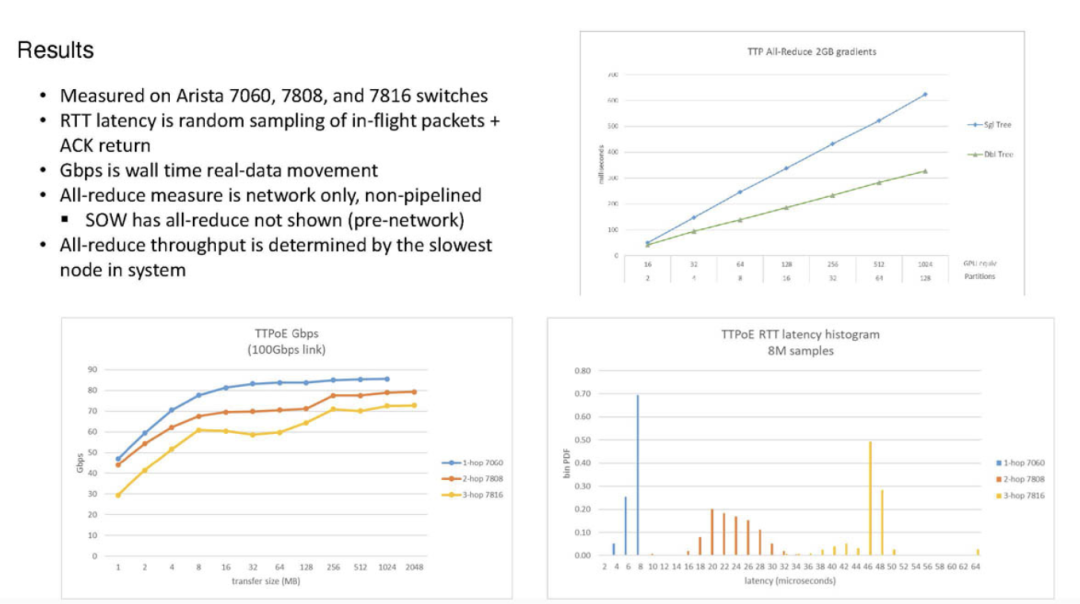
特斯拉的TTPoE协议展示了其在AI计算领域的开拓性思维和技术实力。通过抛弃传统的TCP/IP协议,特斯拉为DOJO超级计算机打造了一个前所未有的高速、有损网络架构。
这一设计不仅提高了AI训练的效率,还降低了硬件成本,为特斯拉的AI技术发展提供了重要支撑。
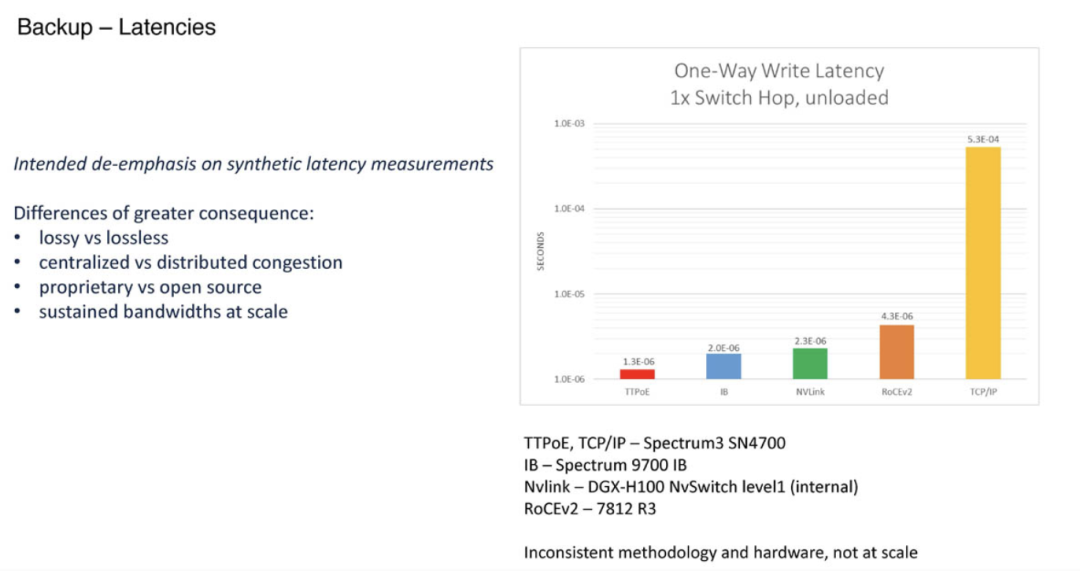
小结
TTPoE可能不仅限于特斯拉的内部使用,以性能为导向的网络架构思维,或许将在整个高性能计算领域掀起新的变革浪潮。
