12月17日,中国电信于GTC中国线上大会发布白皮书《英伟达GPU加速中国电信Spark数据处理》。这篇白皮书介绍了中国电信在Spark业务场景中的用户数据处理中使用GPU的实践,测试了GPU对Spark的数据处理计算加速能力,展示了使用GPU加速Spark大数据处理的效果,并且分析了碰到的技术问题以及对技术的未来展望。
GPU作为通用的加速硬件,以其卓越的并行处理处理,被越来越广泛的用于图形图像处理、深度学习、高性能计算等领域, 并取得了显著的效果。
并行计算近期的热点技术之一是大数据处理,越来越多的科研人员开始研究如何使用GPU等通用加速硬件来加速大数据的并行处理。Apache Spark作为业内最广泛使用的大数据分析处理引擎,在包括中国电信在内的企业用户之间得到了广泛的应用。
Spark虽缓解了Hadoop中存在的 I/O 问题,但现在瓶颈问题已从 I/O 转变为针对日益增多的应用的计算问题。随着GPU加速计算的出现,Spark的计算性能瓶颈问题开始有了新的解决途径。
Spark从社区3.0 版本开始,加入了对GPU的支持,Spark将计算密集型的操作和处理交由GPU来执行,从而加速了端到端的处理速度。
中国电信Spark使用情况简介
中国电信建有统一的大数据处理平台。大数据平台包含数据接入、数据处理、数据输出、数据监测四个主要组成部分。如下图所示。
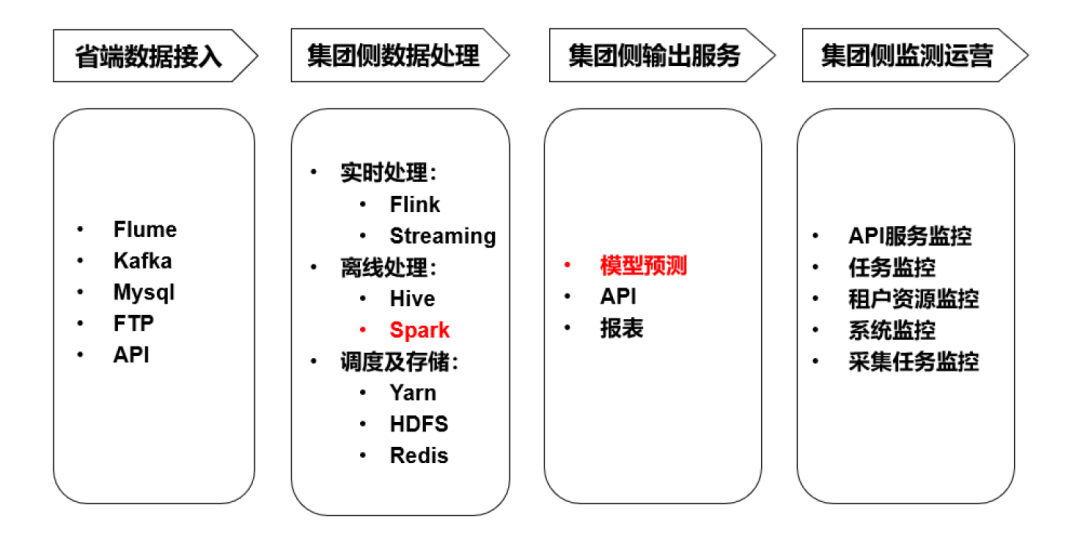
数据接入平台可以接入各个省产生的业务数据。支持多种灵活的接入方式。
数据处理平台支持各频度的多种类ETL分布式计算。由于业务场景复杂,分布式计算框架种类繁多,其中有些业务场景需要实时性要求高,需要达到分钟级别。所以,频度上需要支持实时处理;对于实时性不高但是计算量特别大的,往往采用离线处理。其中,在离线处理中采用了Spark。
数据输出平台支持机器学习及深度学习模型训练,输出模型预测结果;同时,也可以报表的方式,对内支持集团的关键业务。
从数据接入,数据处理,到数据输出,这整个一系列流程都有服务及任务监控,实现了全方位细粒度的运营管理。
GPU加速Spark大数据处理
中国电信使用GPU测试了加速其Spark数据处理的能力。
测试展示了GPU对SparkSQL的加速能力。由于Spark 3.0直接支持GPU加速SparkSQL和DataFrame应用(不支持RDD应用),因此在测试中不需要修改代码,可以直接运行。测试的SQL算子主要包含sum、partition、max、left join、group by等运算。
在第一个测试中,为模拟真实的现网环境,使用了csv文件作为输入数据,每个cvs文件大小为4GB,共101个文件,总的数据量为404GB。测试语句中主要是使用的SQL算子包括select、sum、partition、max等。
测试中使用的数据为随机生成的伪数据,但是模拟了真实数据的数据分布类型。
测试中使用的硬件配置为:Dell PowerEdge R740服务器,共使用三台 R740服务器。
每台服务器配置为:
2颗 Intel Xeon Gold 6130 CPU @2.10GHz
320GB 内存
4片 T4 GPU(只有在GPU加速测试中使用)
测试在三台R740服务器上执行。CPU和GPU查询各分别执行三次。执行结果如下:
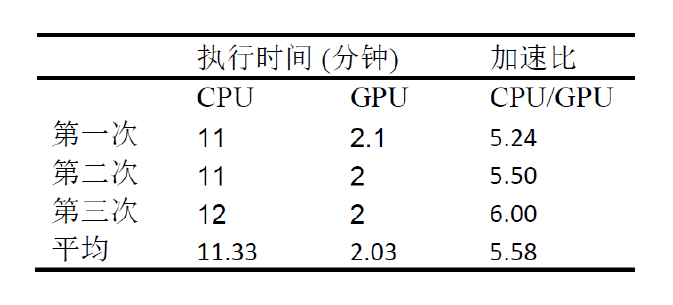
可以看出,在404GB的模拟数据上,执行SQL数据查询操作,CPU上的执行时间为11.33分钟,GPU为2.03分钟。CPU花费的时间为GPU的5.58倍。一台GPU服务器的处理能力相当于5台以上的CPU服务器。
在第二个测试中,使用了更适合GPU读取的列式数据存储格式Parquet。数据量大小为1TB。采用了和测试一中不同的SQL语句,主要的操作包括select,join,group by等。在这个测试中,同样使用了和测试一中相同的服务器,数量为一台。
测试结果为,CPU:890秒,GPU:189秒。加速比为4.7倍。
从测试结果来看,在电信行业中,通过使用GPU可显著提升Spark数据处理能力。如欲了解有关GPU加速Spark的更多详情,可扫描二维码或点击“阅读原文”,查看完整版《英伟达GPU加速中国电信Spark数据处理》白皮书。


NVIDIA 首席科学家 BILL DALLY 通过 GTC 中国线上大会 2020 主题演讲,为您解读 NVIDIA 新科技如何助力解决当今世界的巨大挑战。速速扫描下方海报中的二维码观看演讲视频!

