在生成式大模型训练中,服务器之间需要频繁地进行大量数据的传输和交换。传统的传输控制协议/互联网协议(TCP/IP) 在数据传输的过程中需要在用户空间与内核空间之间多次拷贝,降低了数据传输效率。相比之下,RDMA允许应用程序直接访问远程节点的内存,不经过内核,具有高吞吐、低延迟、无CPU占用等优点,可提升模型训练效率,更为适合生成式大模型训练。英伟达Quantum-2 Infiniband平台技术A&Q
一颗Jericho3-AI芯片,用来替代InfiniBand?
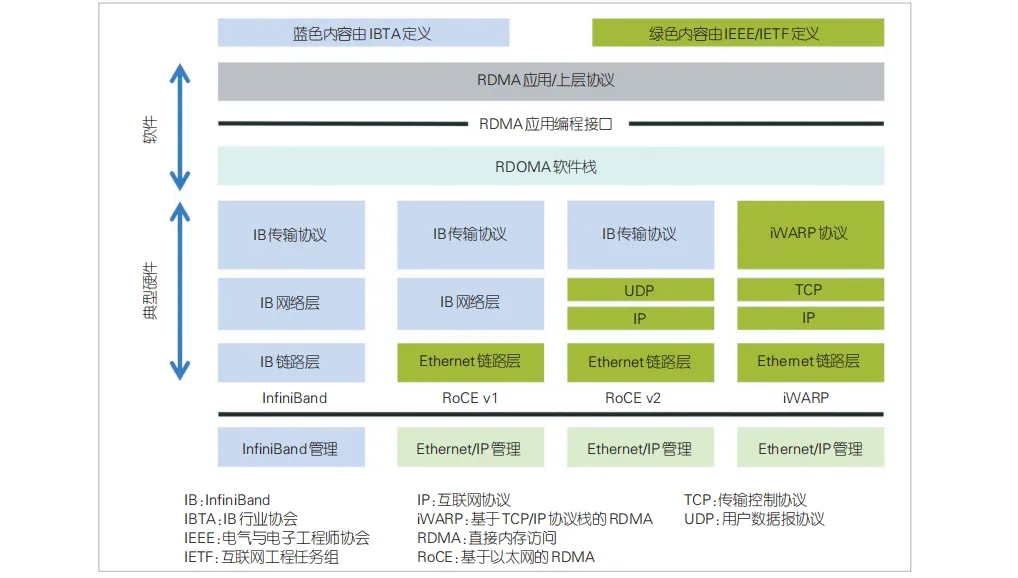
3、配置 InfiniBand 和 RDMA 网络.pdf 6、面向分布式 AI智能网卡低延迟Fabric技术.pdf7、NVMe存储SPDK 加速前后端 IO.pdf8、基于RDMA多播机制的分布式持久性内存文件系统.pdfRDMA 主要包括 3 种类型协议:InfiniBand (简称IB)、基于以太网的 RDMA(RoCE)以及基于TCP/IP协议栈的RDMA(iWARP)。3种协议都符合 RDMA 标准,使用相同的上层接口,具体如图所示。IB 从链路层到传输层定义了一套全新的层次架构,是为高性能计算设计的专用技术。IB 在部署时需要专用设备,如 IB 专用交换机、IB 专用网卡、IB专用线缆等,无法与现有的以太网设备兼容。相比于传统以太网,IB具备高带宽、低延迟的数据传输能力以及无损网络的特征,可满足大型数据中心和超级计算中心对高性能网络的需求。但是,IB 体系独立封闭,采购维护成本高昂,现阶段主要被用于高性能计算领域,如超级计算机、数据中心和科学研究机构等。现网中部署着大量基于以太网的产品。为了扩大RDMA的应用范围,IB行业协会 (IBTA) 组织定义了基于以太网(Ethernet) 的RoCE技术标准,允许在不依赖IB专用硬件的情况下使用RDMA。RoCE通过扩展以太网协议栈,使标准以太网设备支持RDMA操作,实现了高性能远程内存访问与以太网易用性和广泛部署特点的结合。现阶段RoCE有两个主要版本:Ro‐CEv1和RoCEv2。RoCE v1发布于2010年,是基于以太网链路层实现的RDMA协议,但由于它不支持路由,也没有拥塞控制机制,难以在数据中心规模使用。RoCEv2 版本是对RoCEv1版本的重大改进,它基于以太网的用户数据报协议(UDP)。RoCEv2支持路由,并且定义了基于显式拥塞通知(ECN)/拥塞通知报文 (CNP) 的拥塞控制机制。相同场景下,RoCE虽然较IB性能有所降低,但是因其性价比更高,目前已经在一些超大规模数据中心商用部署。iWARP 是国际互联网工程任务组 (IETF) 提出的基于TCP的RDMA协议。由于TCP是面向连接的可靠协议,这使得iWARP在面对有损网络场景时相比于RoCEv2和IB具有更好的可靠性。但是大量的TCP连接会耗费很多的内存资源,另外TCP复杂的流控等机制会导致性能问题,限制了其应用范围,现阶段并未大规模使用。综上所述,IB 在高性能计算领域表现出色,可提供卓越的性能、低延迟和可扩展性,目前在高性能计算领域占据较大优势。相比之下,RoCE则更容易集成到现有以太网基础设施中,并具有较低的成本,是现阶段大模型训练网络的主流方案。2023 年,由众多云计算和网络科技巨头组成超以太联盟,针对IB的封闭生态和原有RoCE的不足,提出了下一代人 工 智 能 (AI) 和 HPC 网 络 的 协 议:超 级 以 太 网 传 输(UET。基于 IP 和以太网进行设计,在基于多路径和数据包喷洒负载均衡、Incast管理机制、高效的速率控制算法、允许乱序数据包传递的应用程序编程接口 (API) 等方向进行了创新,以减少针对特定网络和负载对拥塞算法的复杂参数调优,支持百万节点的大规模网络扩展。RDMA 的大规模组网通常采用基于 Fat-Tree 的 Clos 架构。基于Fat-Tree的Clos架构的基本理念是使用大量的商用交换机,在服务器之间构造出多个等价路径,交换机对流进行ECMP实现负载均衡,进而形成大规模的无阻塞网络。与传统数据中心的流量分布不同,大模型训练网络中多为大象流,数量相对较少。这使得传统的ECMP存在哈希极化现象,即多个流可能分配到同个链路上,负载不均造成流冲突。同时,由于ECMP还是一个无状态的局部决策,不关心不同流的大小差异,在流数目不多且大小流长尾严重时,容易造成多条路径中某些路径拥塞而另一些路径空闲,从而造成带宽浪费和影响传输效率。因此,负载均衡是大规模AI集群网络面临的又一挑战。针对ECMP存在问题,有以下两种负载均衡优化方案:第1种方案是改变流的属性,把流分散到多个等价路径上。在交换机ECMP不变的情况下,改变流的标签,或增加流的熵(将流分割成更小的流或基于报文头的其他位置字段做哈希),让流变得更多从而能通过哈希散开。代表性方法有PLB,在主机端利用拥塞探测感知拥塞的流,对拥塞流的流标签进行更改,引导交换机对流进行重新等价多路径ECMP/加权多路径 (WCMP) 哈希,从而为拥塞流选择新路径。第2种方案是基于网络状态的流量调优。通过实时收集网络拓扑和流量等信息,由集中软件定义网络(SDN)控制器为每条流计算出最优路径,或由交换机进行自适应路由选择,包括集中式流量工程、自适应路由技术和网络级负载均衡技术等。1) 集中式流量工程:SDN控制器实时收集网络拓扑和任务放置信息,基于约束最短路径算法为各个流计算最优路径。2) 网络级负载均衡技术:根据大模型训练的流量特征,综合网络拓扑等整网信息,计算出最优的流量转发路径。3) 自适应路由技术:交换机根据出口队列负载评估拥塞情况,为每个数据包选择最不拥塞的端口进行数据传输,以实现负载均衡。由于同一流的不同数据包可能由不同网络路径传输,到达目的节点时可能出现乱序,因此需要网卡侧在RoCE传输层完成对无序数据的转换,再将有序数据传递给应用程序。此外,目前一些研究也指出:原生RoCE协议中规定数据包顺序到达的设计弊端是制约负载均衡的关键因素。未来应从根本上改进传输协议,采用数据包喷洒等技术,使得数据包可以通过多路径顺序传输,然后再利用可编程交换机或智能网卡重新对数据包排序,以充分利用网络的多个可用路径实现负载均衡。2024年中国AI大模型场景探索及产业应用调研报告:大模型“引爆”行业新一轮变革3D DRAM行业报告:3D DRAM时代或将到来,国产DRAM有望迎来变革契机光芯片研究报告:高速互联需求驱动光通信行业发展,国产光芯片有望加速渗透1、艾媒咨询:2024年中国信创产业发展白皮书(精简版)
2、艾媒咨询:2023年中国信创产业发展白皮书(精简版)1、2024大模型典型示范应用案例集
2、2023大模型落地应用案例集2024亚太不同国家和区域对生成式AI的反应白皮书计算机自主可控系列:国产AI算力万卡集群,多芯混合时代来临计算机行业深度:从技术路径,纵观国产大模型逆袭之路
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。