现在脑机接口的硬件部分就是Link和intan有实物了吧?Link其实也没有披露特别多的细节,但是作为构架的学习应该是够的。有微电子的基础可能做这个东西会好一些。

几代电路的样子
神经元脉冲的第一个问题是振幅,通常小于 10 微伏。放大只有 10 微伏的信号需要 43 dB 至 60 dB 的系统增益,以便将信号置于板载 ADC 的 10 位分辨率范围内(~ 1 mV)。阻抗问题加剧了 ADC 分辨率的缩小,因为电极几何形状的减小意味着系统中的电阻率和噪声更大。Neuralink 研究了两种表面处理方法(聚苯乙烯磺酸盐和氧化铱),它们具有良好的阻抗特性.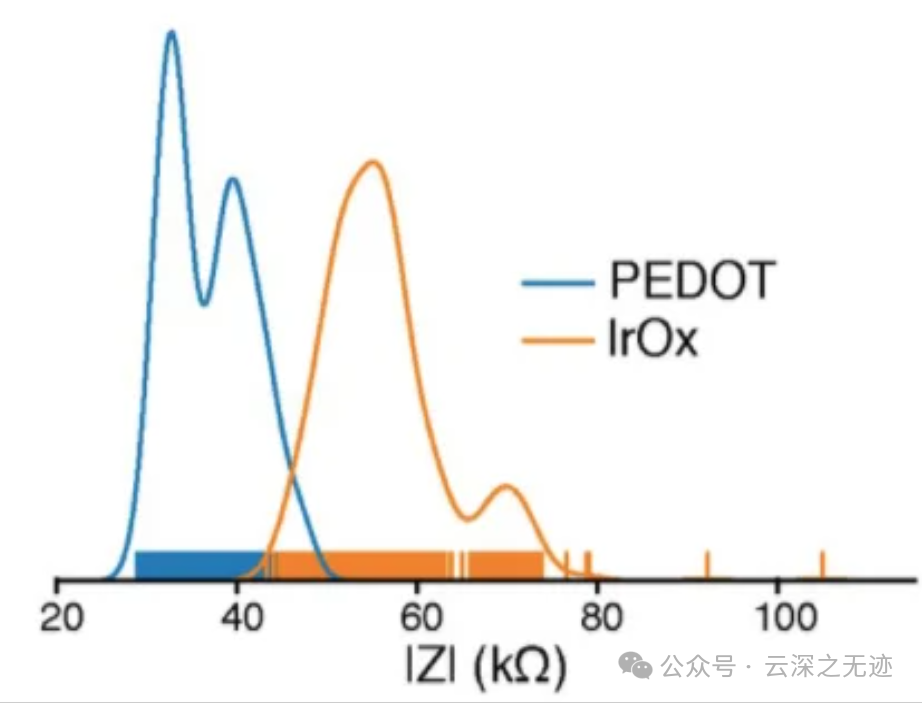
也就是这个图
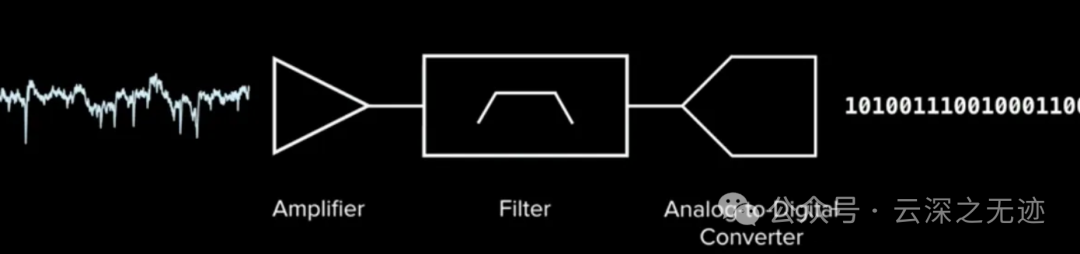
首先脑机接口第一步是信号到数字的转换:
这些通道的工作效果决定了信号质量和整个神经接口的特性。在设计模拟像素时,有三个主要考虑因素。
2.尽可能降低功率,以便产生更少的热量并延长电池续航时间3.噪音尽可能低,以获得最佳信号,但是这些是互相制约的。Neuralink 专用集成电路 (ASIC) 构建,该集成电路由 256 个可单独编程的放大器(“模拟像素”)、片上模数转换器 (ADC) 和用于序列化数字化输出的外围控制电路组成。
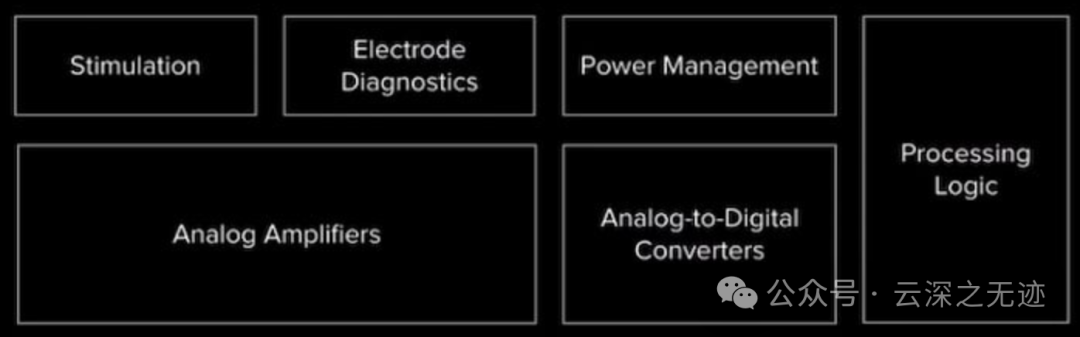
标准的SOC架构

这是目前最新的N1 SOC

其实已经有过了三代的更迭

封装的传感器设备,也是目前最多出现的样子
(A)能够处理 256 个数据通道的独立神经处理专用集成电路。这种特殊的封装设备包含 12 个这样的芯片,总共 3072 个通道。
(B)聚对二甲苯-c 基板上的聚合物线。
(C)钛外壳(盖子已取下)。
(D)用于供电和传输数据的数字 USB-C 连接器。
记录通道的密度要求将信号放大和数字化模块放置在阵列组件内;否则,电缆和连接器的要求将过高。
记录模块放大小神经信号(< 10 µV RMS),同时抑制噪声,对放大的信号进行采样和数字化,并将结果流式传输出去并进行实时处理。

Neuralink 能够通过单个 USB C 连接器和电缆传输整个宽带信号。为了消除电缆和连接器,因此修改了算法以适应硬件,使其既可扩展又低功耗。目前,已经能够实现将神经数据压缩200多倍的算法,并且仅需900纳秒即可计算,这比大脑意识到这一点所需的时间还要快。(不知道啊)模拟像素具有高度可配置性:可以校准增益和设置滤波器,以解决由于工艺变化和电生理环境导致的信号质量变化。
片上 ADC 以 19.3 kHz 的采样率和 10 位分辨率进行采样。每个模拟像素消耗 5.2 µW,整个 ASIC 消耗约 6 mW,包括时钟驱动器。

10bit的ADC
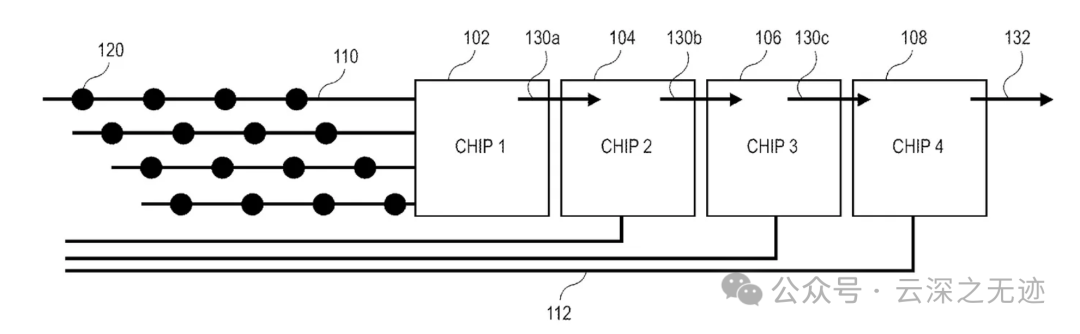
因为是多个芯片叠加的,所以专利里面出现了多个ASIC之间的通讯,可以看到是像接力一样。
第一个 ASIC从其各自的通道接收数据,对数据进行分组,并将处理后的信号以数据包的形式推送到下一个 ASIC。然后,第二个 ASIC从前一个 ASIC 及其各自的电极接收数据,并将新分组的数据与前一个 ASIC 的数据包一起传递到下一个芯片。这个过程会重复进行,直到所有芯片的聚合数据包从最后一个 ASIC 卸载到另一个计算系统。传递给下一个 ASIC 的具体数据量取决于采用哪些数据管理技术来提高能效。对于跨 ASIC 芯片系列的数据包管理,流量控制是必要的,确保从每个芯片出口到片外系统的信息量足够。如果每个芯片只是在收到所有数据包时就将其传递,那么从芯片组到计算机进行存储和处理的数据流可能会偏向最近的芯片(下一个芯片从传入通道接收一半数据包,另一个从之前的芯片接收一半数据包)。有种全带宽模式,大概就是如果开始的芯片全力输出,后面的芯片吃不消。策略是:
包括在每个传输步骤中抵消偏差。例如,当芯片 2 将数据包传递给芯片 3 时,来自芯片 3 的数据包数量不会以 50% 的带宽传递,而是以 33% 的带宽传递,而来自第一和第二个芯片的数据包则以 66% 的带宽传递。第四个芯片将仅使用 25%,这导致前面的芯片也以 25% 的分割方式共享 75% 的带宽。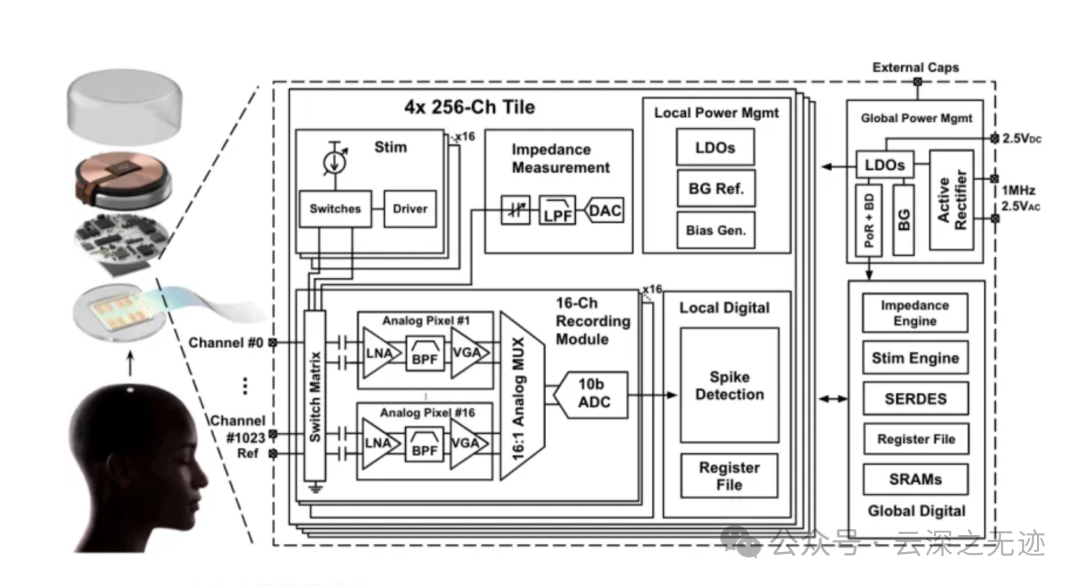
IEEE的N1构架
神经片上系统 (SoC),其尺寸仅为 5x4mm²,专为临床应用而设计,这意味着它需要体积小巧且节能。SoC 可以通过串行数字链路(类似于以前的设计)记录和刺激 1024 个植入电极,并且它包括可配置的尖峰检测,可以大大减少片外带宽。该设计还集成了电源管理电路,具有上电复位和电压不足检测功能,总功耗仅为 24.7mW。这使其成为功耗最低、密度最高的交流耦合神经 SoC,可以记录带宽为 5Hz-10kHz 的局部场电位 (LFP) 和动作电位 (AP)。- 四个 256 通道图块,每个图块包含 256 个神经放大器
- 16 个逐次逼近寄存器模数转换器 (SAR ADC)
SoC 的输入开关矩阵允许动态配置通道模式,可设置为记录、刺激或测量阻抗。此外,可以根据实验设置调整参考连接,无论是参考电极、附近电极还是系统接地。电路由这些组件构成:芯片间数据传输端口(左进,右出),模拟像素/神经放大器阵列,模数转换器 (ADC),数字多路复用器,控制器,配置电路,压缩引擎,合并电路,序列化/反序列化器:充当入站和出站数据包队列。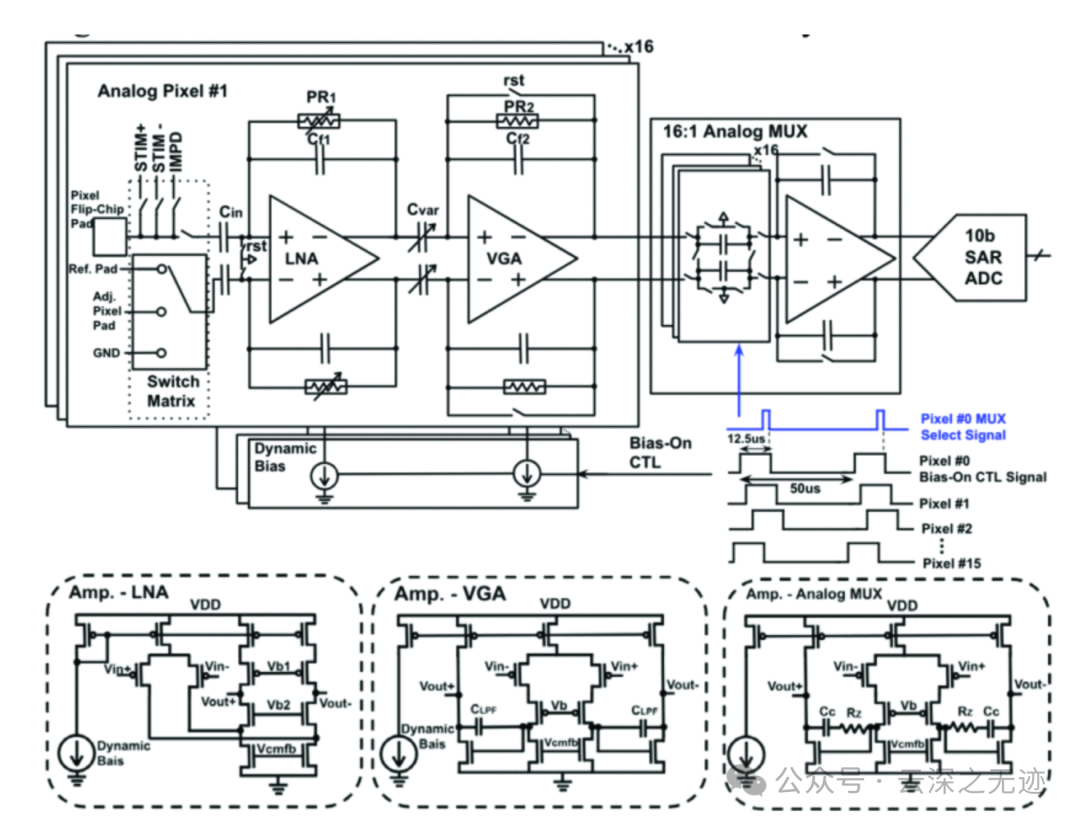
由模拟像素、动态偏置、16:1 MUX 和 10 位 SAR ADC 组成的全差分记录模块,这才是现在的样子,上面的构架是幻想。
电路图展示了这种先进技术的设置。模块内的模拟像素由电容反馈运算放大器 (OPAMP) 组成,可用作低噪声放大器 (LNA) 和可变增益放大器 (VGA)。这些组件协同工作,以可配置增益放大和配置 LFP 和 AP 频段。为了确保 LNA 输入晶体管在正确的 DC 偏置操作区域内工作,输入 AC 耦合电容器用于阻止来自大脑电极的未知 DC 偏移。反馈路径中的伪电阻 (PR) 在设置像素的高通滤波器 (HPF) 截止频率和 DC 输入偏置方面起着关键作用。借助可调 PR,可以相应地调整 LFP 和 AP 频段的 HPF 截止频率。模块内的每个模拟像素都有自己的倒装芯片焊盘,该焊盘连接到 LNA 的正输入。为了实现面积高效的抗混叠低通滤波器 (LPF),为 VGA 选择了两级米勒补偿架构。然后,VGA 的输出被多路复用到 10 位 SAR ADC 上,该 ADC 带有基于开关电容放大器的 16:1 MUX,提供足够的驱动能力,使 ADC 完全稳定在采样窗口内。为了确保模块的效率,采用了动态偏置电路。该电路在输出采样后立即关闭 LNA 和 VGA,从而仅消耗 25% 的静态功耗。由于模拟像素输出从无电状态到采样的稳定时间比通道采样周期短得多,因此整体模拟像素尺寸保持较小,尺寸为 65×71µm2,包括路由通道、输入开关矩阵、动态偏置和倒装芯片焊盘。在模块的全局电源管理中,级联 LDO 的第一级采用 2.5V DC 或由 1MHz 2.5V AC 生成的有源整流器输出。第二级 LDO 为本地电源管理、刺激引擎、pad 驱动器和数字生成单独的电源轨,以减少电源域之间的噪声耦合。每个 256 通道 Tile 都有自己的本地电源管理,以在整个 Tile 中均匀分配电源。ASIC 中的数据流始于模拟像素,这些像素是可调放大器,排列成 8x8 网格。2019 年白皮书中描绘的 ASIC 拥有 4 个这样的放大器网格,总共 256 个模拟像素,与芯片接口的通道数之比为 1:1。低噪声信号放大对于获取和调节电极收集的微弱神经信号至关重要。此外,放大器阵列还可以通过对来自电极的原始数据应用配置电路设置的阈值来参与信号压缩。信号放大后,ADC 会将其数字化。在专利中描述的设置中,有 8 个 ADC 接收来自八排放大器中的每一排的信号。在白皮书中的版本中,将有 32 个 ADC。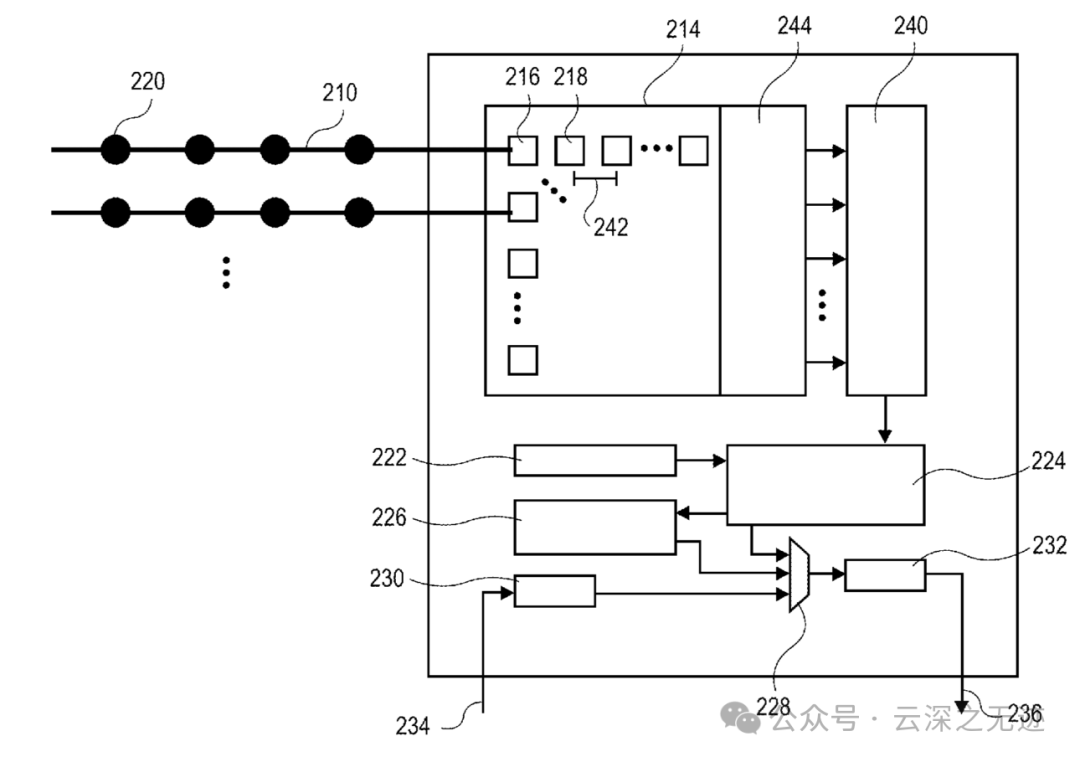
嗯
就这样,不然你以为真的有那么多ADC
数字化信号随后被传送到多路复用器,多路复用器将数据串行化,并针对放大器阵列中的特定行和列进行滤波。配置电路可通过扫描链或 JTAG 接口(一种将指令注入闪存的方法)进行编程,以启用所需模式,指示多路复用器从哪个模拟像素进行采样。从底层角度来看,数字多路复用器通过实现多个 NAND 门(与非)来控制哪些输入信号传递到输出。在简单的 2 输入多路复用器中,单独的控制信号被发送到多路复用器以在模式之间切换:输入 1 或输入 2 传递到输出。模式数量与 2^n 成比例,其中 n 是控制输入的数量。配置电路是 ASIC 的主要编程接口,它可以在几种操作模式之间切换芯片,包括跳过通道、预定列和事件电压尖峰。这些模式本质上是一组指令,用于在 ASIC 的不同组件(包括压缩引擎、合并电路和多路复用器)中实现阈值。专利中的一行优雅地总结了配置电路的作用:“由于其余电路是管弦乐队中扮演特定角色的独特乐器,因此配置电路是指挥。”配置电路还设置芯片的所有参数,包括安培设置(读出的安培数)、电极的轮询频率、压缩引擎阈值等。利用存储的程序指令,配置电路在运行期间继续向芯片的其余部分发送指令。数据流,串行信号被发送到控制器,控制器与压缩引擎和合并电路通信。控制器的主要功能是打包数据。控制器可以通过通信从放大器的哪些列采样以及何时采样来协调模拟到数字的转换。此外,控制器会调节采样率或以选定的步骤停止从放大器采样。控制器指令可以每 6.25 µs (160 kHz) 更改一次。从此时起,数据流根据配置电路编程的模式而分流。数据包可能首先通过压缩引擎进行压缩,或者可能直接发送到合并电路。当放大器阵列不对传入数据应用阈值时,压缩引擎执行有效数据管理的关键功能。在这些情况下,压缩引擎从放大器接收原始的高带宽信号,在某些情况下可以以 20 kHz 采样。压缩策略主要涉及应用阈值来检测特定范围内的峰值、汇总统计数据(例如通道平均值)和/或基于事件的片外触发器。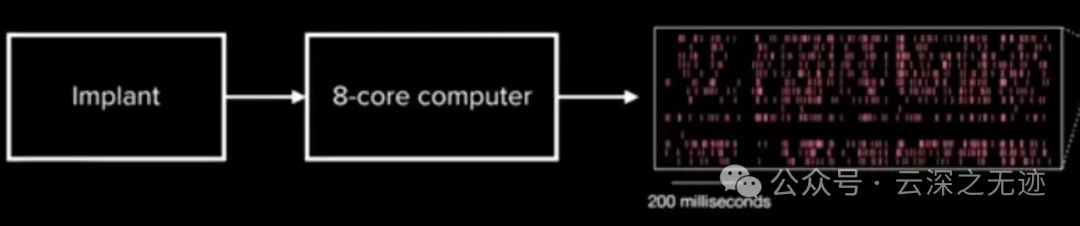
应该是有8个独立的MCU来控制上面的内容
这些阈值可以设置在信号的电压或频率上。低频和高频信号可能对记录器没有价值,可以通过压缩引擎过滤掉。非尖峰信号被丢弃,本质上减少了数据包的大小,并压缩了信号。对于基于电压的阈值,可以使用一种称为非线性能量算子 (NEO) 的技术来自动找到准确检测尖峰的阈值。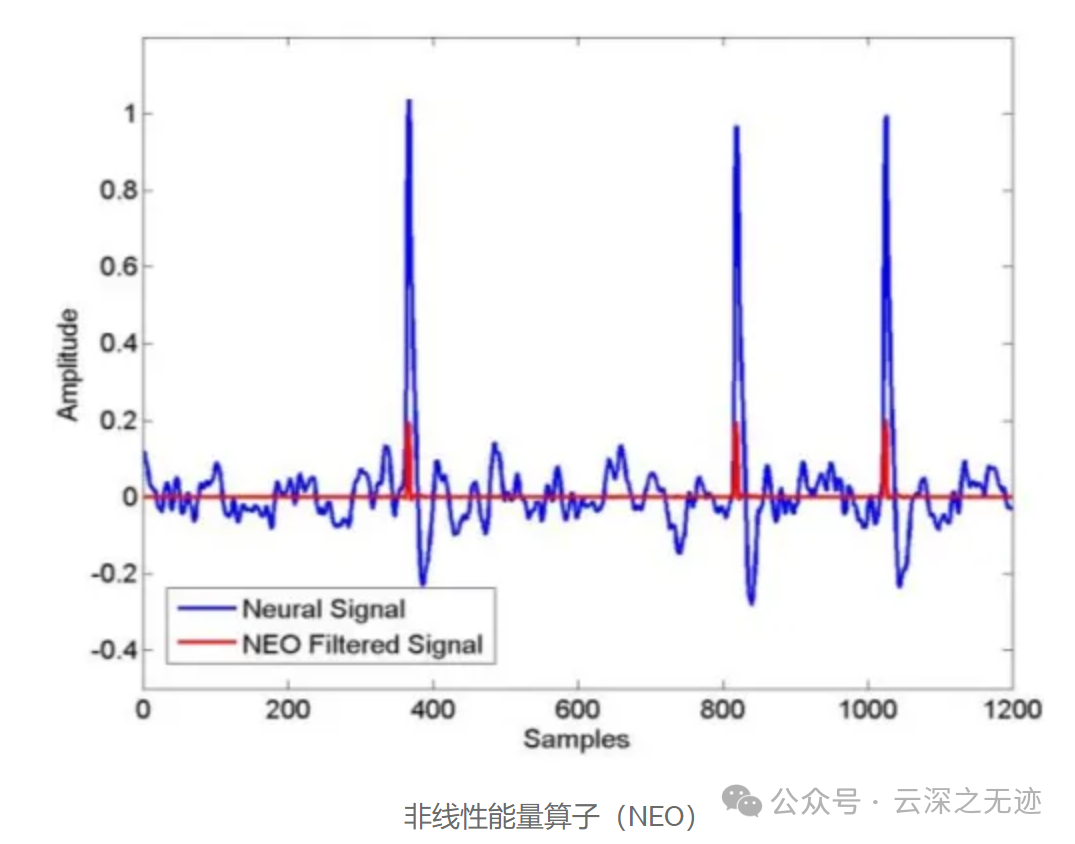
NEO,它本质上是对尖峰频率和幅度快速变化的周期内的信号进行滤波,这些尖峰在 NEO 滤波输出中可以看作是短峰值。
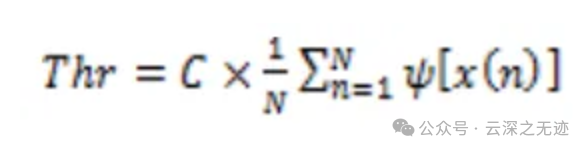
此外,NEO 检测的阈值可以计算为 NEO 滤波输出的平均值乘以因子C。在这个等式中,N是信号样本的数量。C 是根据经验得出的,应该事先在几个神经数据集上进行测试,以获得最佳结果。压缩引擎和控制器在限制每个芯片生成的数据量方面都发挥着至关重要的作用,限制可以提高 N1 系统的功率和性能效率。
DJ Seo(设计者) 介绍了一种新颖的片上脉冲检测算法,该算法直接描述脉冲的形状。这种方法能够将神经数据压缩 200 倍以上,并且仅需 900 纳秒即可完成计算,这比大脑意识到发生这种情况所需的时间还要快。该技术甚至可以根据形状识别来自同一电极的不同神经元。最后,合并电路从控制器、压缩引擎和解串器接收数据包。解串器将数据包从片外链路转换为片内链路,本质上是将来自前一个 ASIC 的数据排队。合并电路本质上是从片上创建的数据包和来自前一个 ASIC 的数据包中选择要发送的数据包以及发送时间。然后,所选数据包通过串行器发送到片外。还有一段关于带宽控制的,但是我不懂哪个背压是啥意思?有机会写,大概就是说输出的payload是实时控制的。来自每个芯片的数据包具有可变大小,而不是固定大小,因此相对容易预测何时生成数据以及生成多少数据。无需使用充满空数据集的有效载荷来实现长度标准化,而是可以最小化每个数据包的结构以提高效率。可以根据数据包所封装数据的需求对其进行定制,从而最大限度地减少空数据包和浪费的带宽,从而缓解拥塞。
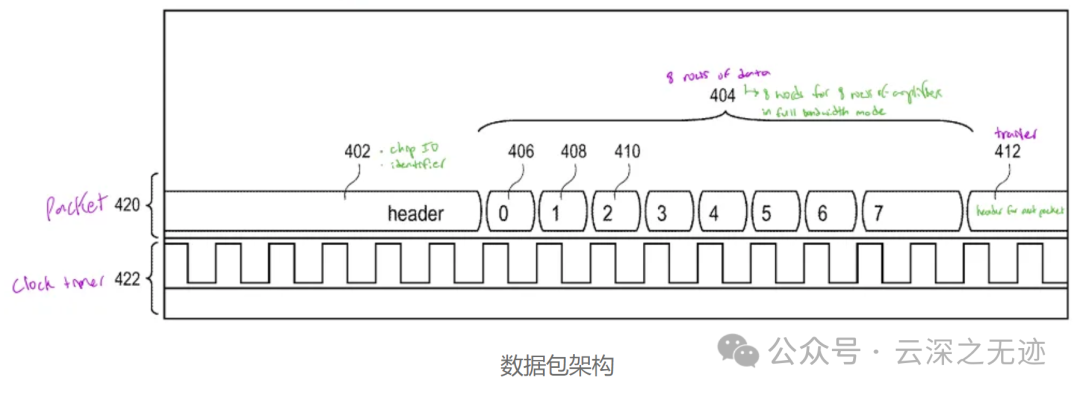
显示了一个示例数据包结构以及一个时钟定时器。数据包由一个报头、数据包和尾部组成,尾部是下一个数据包的报头。本例中的数据包由 10 位字组成:1 个为报头,8 个为每行放大器的数值,1 个为尾部。
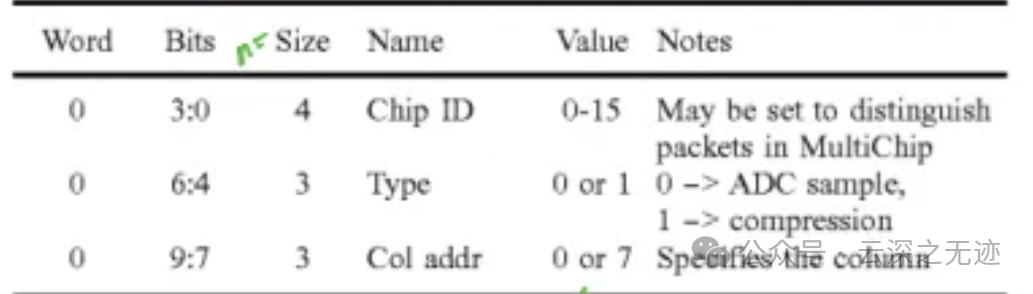
数据的样子

但是最终你能买到的也就是intan的芯片了
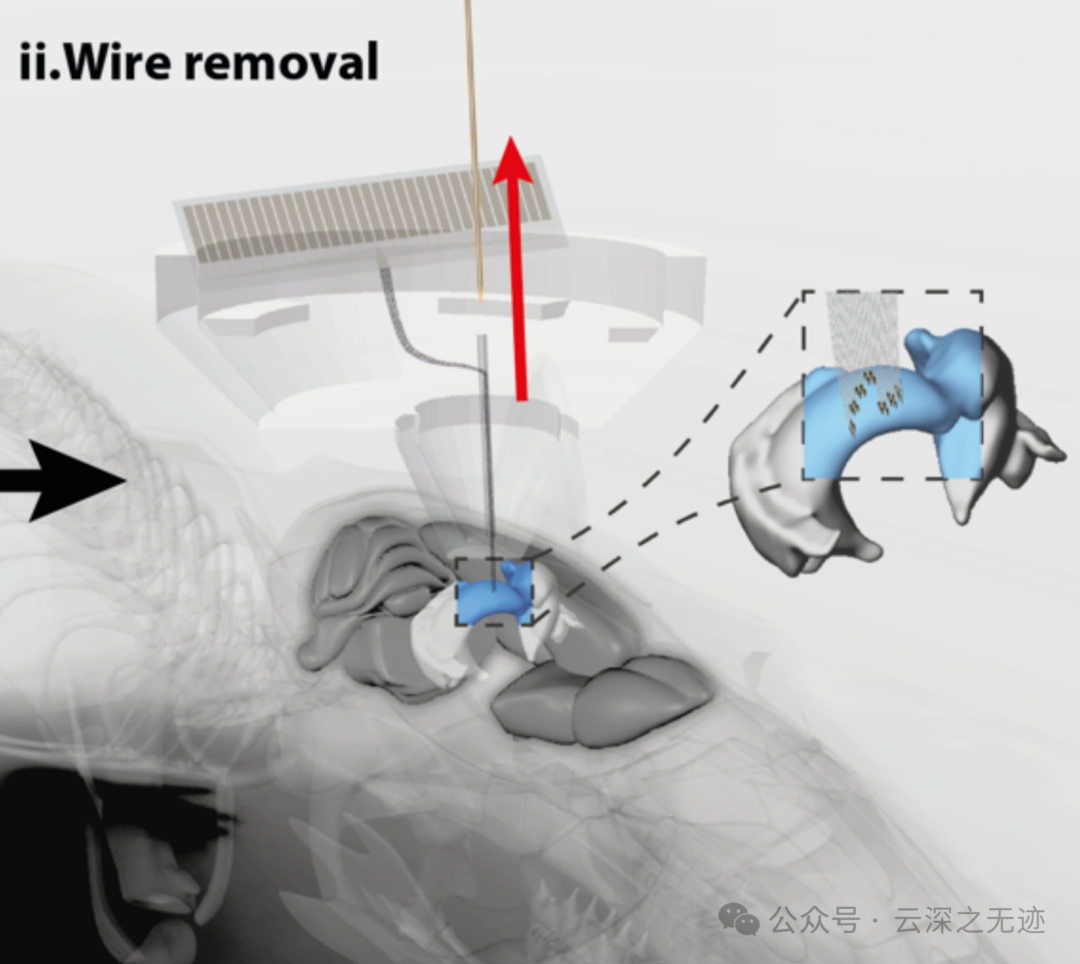
最后看一个电极插在老鼠头上的图吧

电极线路是印刷在这个上面的

一种长条的电极,这种应该是平铺的

束状是要垂直插入的

单个电极的线路,很细
NeuraLink植入式系统解读
Blackrock-Nerotech神经科学设备
Precision完成4096个脑电极植入工作
SCI-无线微型脑刺激器
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6914248/
