

本文分享一个SPI查询收发的问题,详细分享分析过程,并发散举一反三,分享类似常见的问题。
使用SPI查询方式发送一定数据并且同时接收一定数据。
在低速时发送能成功,在高速时一次发送数据较长时有时收不全指定的数据。
接口很简单,也是SPI通常的接口,outbuf表示发送缓存,inbuf是接收缓存,收发长度必须一致为trans_len。如果outbuf为空则只接收不发,inbuf为空则只发不收,都不为空则同时收发,当然不能全部为空。这里需要注意一下对于主机,如果只收,实际上也是需要发同样长度的数据的,否则不会产生CLK也无法收,此时接口里面就可以定义一个局部缓存发这个缓存即可,而不是发用户空间数据即可。对于只发不收,为了 逻辑一致性其实也可以这样处理,即接收到局部缓存丢弃掉,不用接收到用户空间。以上和本问题其实无关,顺便提一下。
int spi_poll_trans(uint8_t *outbuf, uint8_t *inbuf, uint32_t trans_len)
回到这个问题,发送指定长度数据同时接收指定长度数据,理论上是很简单的逻辑。
来看下这个函数的实现
该函数的实现大概是如下流程,不断调用spi_write发送数据,然后调用spi_read接收数据,
spi_write的实现是写硬件buff,buff空间有多少则写多少,返回实际写的个数,所以用户可以指定写很多,但是会返回实际写的数据。
spi_read的实现是读硬件buff,buff空间有多少则读多少,返回实际读的个数,所以用户可以指定读很多,但是会返回实际读的数据。
如果用户没有指定发送空间,则发送局部缓存tx_rx_tmp,用户没有指定接收空间,则接收到tx_rx_tmp。这样函数实现逻辑一致。
初步看好像逻辑也什么明显的问题。
int spi_poll_trans(uint8_t *outbuf, uint8_t *inbuf, uint32_t trans_len){uint8_t tx_rx_tmp[16];uint8_t *tb = outbuf;uint8_t *rb = inbuf;uint32_t txsize = 0;uint32_t rxsize = 0;uint32_t txleft = trans_len;uint32_t rxleft = trans_len;uint32_t totlen = trans_len;uint32_t retry = 0;if(((outbuf == NULL) && (outbuf == NULL)) || (trans_len == 0)){return -1;}if (outbuf == NULL) {txleft = 0;txsize = totlen;}if (inbuf == NULL) {rxleft = 0;rxsize = totlen;}while (txsize < totlen || rxsize < totlen) {if(outbuf == NULL){txsize += spi_write(tx_rx_tmp, txleft>sizeof(tx_rx_tmp)?sizeof(tx_rx_tmp):txleft);}else{txsize += spi_write(tb, txleft);}if(outbuf == NULL){rxsize += spi_read(tx_rx_tmp, txleft>sizeof(tx_rx_tmp)?sizeof(tx_rx_tmp):txleft);}else{rxsize += spi_read(rb, rxleft);}if (txsize <= totlen) {tb = outbuf + txsize;txleft = totlen - txsize;}if (rxsize <= totlen) {rb = inbuf + rxsize;rxleft = totlen - rxsize;}if (retry++ == SPI_TRANSFER_RETRY_TIMES_MAX) {break;}}return 0;}
我们先来看下现象。 既然已经发现和SPI速率有关,那么我们就测试下速率和一次收发不同长度的差别。
设计测试代码,分别测试三种情况(只发不收,只收不发,同时收发),以及一次收发不同的长度1~512字节。实际上上述三种情况正如我们开始说的spi_poll_trans的处理逻辑是一致的,只是如果用户提供了收发缓存则从用户的收发缓存发送和接收,否则在函数spi_poll_trans的局部缓存收发。所以理论上和上述三种方式是无关的,只和速率有关。
static uint8_t tx_tmp[512];static uint8_t rx_tmp[512];for(uint32_t i=0;i<sizeof(tx_tmp);i++){tx_tmp[i] = i;}while(1){for(uint32_t i=0;i<sizeof(tx_tmp);i++){if(RET_OK != spi_poll_trans(0, i+1)){printf("spi tx trans err %d\r\n",i+1);}}for(uint32_t i=0;i<sizeof(tx_tmp);i++){if(RET_OK != spi_poll_trans(0, rx_tmp, i+1)){printf("spi rx trans err %d\r\n",i+1);}}for(uint32_t i=0;i<sizeof(tx_tmp);i++){if(RET_OK != spi_poll_trans(tx_tmp, rx_tmp, i+1)){printf("spi txrx trans err %d\r\n",i+1);}}}
测试来看低于5M时没问题,10M时基本发送400字节出错,20M时则可能更少或者更多都会出错。出错即上面的超时。
if (retry++ == SPI_TRANSFER_RETRY_TIMES_MAX) {
break;
}
5M
OK
10M
spi txrx trans err 394
spi txrx trans err 387
spi txrx trans err 386
20M
spi rx trans err 82
spi rx trans err 156
spi txrx trans err 370
从上述出错信息,我们倒退,
即接收超时,即发送一段数据,没有接收到指定数据,接收数据少了。
这不符合SPI的实际,SPI实际是发多少同时收多少。
首先这个和数据性无关,纯粹是接收数据少了,先排除硬件问题,因为SPI不管怎样只要发了多少就会收多少数据。
那么还有什么可能呢? 硬件不会收少,那么只可能软件收少了,
那么继续追问,什么情况会导致软件收少了呢,我们使用的是硬件FIFO接收,自然而然地会想到可能是硬件FIFO满了,溢出了。当然也不排除中间可能被其他逻辑将接收关闭了等等可能,我们可以画出问题鱼骨图来分析。当然这里最大的怀疑就是FIFO溢出了。
那么继续追问,什么情况下FIFO会溢出呢?
那就是软件来不及取走就会溢出了?
再回到上述的代码,我们不是发一笔,收一笔吗,不是先调用spi_write马上就调用spi_read了吗?理论上一来一回总是对的呀?
那么就只可能是每次spi_write和spi_read的数据长度不一样,比如spi_write这一次发了10字节,spi_read只接受了9字节,那么接收FIFO有溢出,下一次spi_write时发送FIFO空间,比接收FIFO可接收的空间大,那么发完之后接收FIFO就可能溢出。
在一连串连环追问下,其实已经大概猜测到问题所在了。
那么我们再画出图来详细的梳理下。
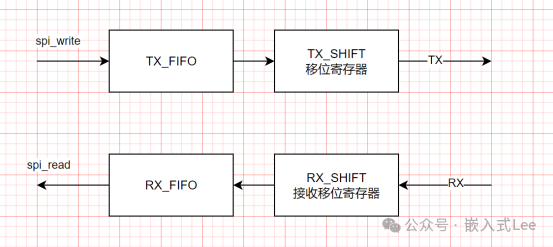
假设我们要收发512字节,TX和RX的FIFO都是16字节。
512字节一次发不完,需要分次发,
先如下,spi_write写完TX_FIFO 16字节返回
if(outbuf == NULL){txsize += spi_write(tx_rx_tmp, txleft>sizeof(tx_rx_tmp)?sizeof(tx_rx_tmp):txleft);}else{txsize += spi_write(tb, txleft);}
紧接着执行接收
if(outbuf == NULL){rxsize += spi_read(tx_rx_tmp, txleft>sizeof(tx_rx_tmp)?sizeof(tx_rx_tmp):txleft);}else{rxsize += spi_read(rb, rxleft);}
在执行完发送代码段,到执行接收代码段之间有一个时间间隔假设是t,
这一段时间SPI总线上就会发送数据,此时RX FIFO可能接收到数据,收到数据的个数和这个时间间隔t有关,如果这个时间间隔很长,SPI发送很快,那么此时接收就能读到全部收回来的数据。
这个时间间隔是波动的,可能由于任务调度等变化很大,这可能会导致随机现象,比如上午在执行某些逻辑会抢占导致这里间隔很长,下午没执行特定逻辑,这里就不会间隔很长,甚至比如某些依赖温湿度的可能还和温湿度有关,这就说明了很多玄学问题根本不是玄学,只是没有找到原因而已,这里一个例子其实就可以解释可以构造一个,让温湿度,甚至时间来决定BUG是否触发的案例。
如果这个时间很短,SPI发送很慢,那么就可能这一次接收不到,等下一次发送,发送也没发完没有FIFO空间写不进去,直到后面发送完一个字节,此时就可以接收到一个字节,发送FIFO又腾出一个字节空间,等后面接收又接收一个字节。这样发送接收每次都是一个字节,也没问题。
但是很可能是t和SPI时间在中间,也就是可能t时间间隔之后,硬件上已经发送了少于16个字节,假设发送了14个字节,接收也接收到了14个字节,那么此时只会接收到14个字节。但是在接收的过程中,发送还在继续,此时剩余的两个字可能发出去了,也进了接收FIFO,此时发送FIFO就腾出来了16个字节的空间,此时发送会发16个字节,此时接已经有两个字节了,无法接收新到的16个字节,就会导致溢出。
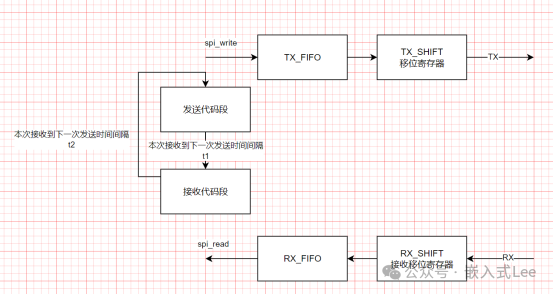
过程如下
开始发送
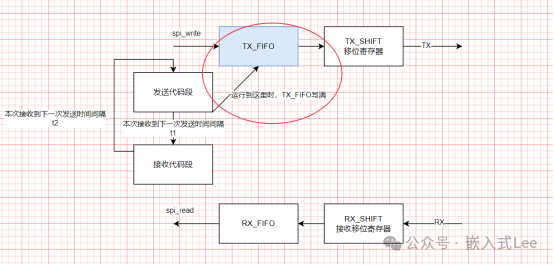
T1后开始接收,接收到14字节
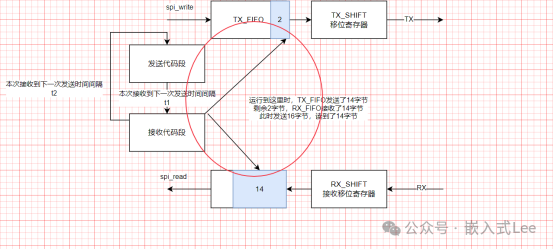
接收完,到再次发送之前,t2这段时间,剩余的TX_FIFO2字节发送出去,接收FIFO也接收了两字节。
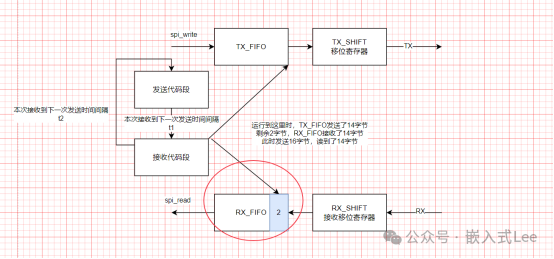
此时再次发送,TX_FIFO可以写16字节
T1这段时间,如果比较长,大于14字节的传输时间,那么RX_FIFO只能接收14字节,将会溢出。
所以t1决定了,上一次RX_FIFO中会残留多少字节未接收,同时也决定了,下一次是否能来得及读取剩余的数据。
上述t和SPI的速率综合就导致了不同的现象。
那么怎么解释,低速时没问题,中间速度时都是在发送比较多字节才出问题,高速时反而有可能发送很少字节就出错,也可能发送很多字节才出错呢。
低速时软件跑一个发送接收循环远快于发送接收一个字节,所以发送完一个字节,接收一个字节,不会有溢出。
中间速度时,可能发送大于一个字节,接收一个字节,这个比例可能是比如101:100,那么由于有接收16字节的FIFO,会直到FIFO溢出才会出现问题,所以基本靠后。
而高速SPI时,可能发送很多字节, 才接收很少字节,这个比例就不再接近于1:1, 比如是120:100。并且由于t的时间也是动态变化的也会导致现象有一些变化。
以上两个因素t的时间,SPI的速率共同决定了不同的现象。
实际可以打印SPI的寄存器,查看FIFO的状态确实是溢出了,这里就不再贴图了。
实际这里FIFO是异步机制,而这里需要实现的是同步处理,所以本质上就是冲突的,理论上不应该使用FIFO,使用FIFO也并不能带来效率收益(因为这里实现的就是同步处理),就是按照字节同步查询收发。
找到问题了,修改就很简单了,以上根本原因是由于FIFO的缓存,和时间t的波动导致的收发不一致。所以保证收发一致即可,即发送完后,必须等到接收完再发送。
int spi_poll_trans(uint8_t *outbuf, uint8_t *inbuf, uint32_t trans_len){uint16_t tx_rx_tmp[16];uint8_t *tb = outbuf;uint8_t *rb = inbuf;uint32_t tx_rx_size = 0;uint32_t t_cnt = 0;uint32_t r_cnt = 0;uint32_t r_cnt_total = 0; /* 本次发送,一共接收到的数据 */uint32_t tx_rx_left = trans_len;uint32_t retry = 0;while (tx_rx_size < trans_len){/* 发送一笔 */if(outbuf == NULL){/* outbuf为空则发固定数,一次最多发tmp缓存大小 */t_cnt = spi_write(tx_rx_tmp, (tx_rx_left>sizeof(tx_rx_tmp))?sizeof(tx_rx_tmp):tx_rx_left);}else{t_cnt = spi_write(tb, tx_rx_left);}tx_rx_size += t_cnt;/* tx data */tb += t_cnt;tx_rx_left = trans_len - tx_rx_size;/* 接收一笔和发送同样大小的数据* 接收超时则退出** 以上发送数据写入TX FIFO,到此时并不一定马上RX FIFO中就开始能收到数据* 所以要等,要不断查询读,直到读到和发送一样多的数据!* 等到收到和发送一样多的数据为止,这样才能保证发多少收多少,避免接收缓存区有数据遗留,下一次继续发送后,* 接收缓存区叠加新的数据,导致溢出*/r_cnt_total = 0;retry = 0;do{if(inbuf == NULL){/* outbuf为空则发固定数,一次最多发tmp缓存大小 */r_cnt = spi_read(tx_rx_tmp, t_cnt-r_cnt_total);}else{r_cnt = spi_read(rb, t_cnt-r_cnt_total);}if(r_cnt>0){retry = 0;}rb += r_cnt;r_cnt_total += r_cnt;}while((r_cnt_total < t_cnt) && (retry++if (retry >= SPI_TRANSFER_RETRY_TIMES_MAX) {ret = -1;break;}}return 0;}
以上问题实际上有几点需要主义的,FIFO的使用,会导致和用户感知的不一致,执行时间可能波动会导致现象不一样。
举一反三,同样的类似有FIFO缓存的地方都需要注意,写入缓存区了并不代表发送完成了,比如SPI,比如串口。
比如类似的485发送完切换到接收的时机,要用发送完中断,没有发送完中断的则可根据波特率设置定时器,确定发送完时间。
比如SPI发送完拉高CS,要以发送完中断,而不是FIFO空,FIFO空数据还可能在移位寄存器中没有发送完。用户感知的发送和接收完成的时机不一样,发送完如果使用FIFO是超前的即并没有真实发送完,接收是滞后的接收完了肯定总线上也是接收完了。所以有些双工的没有发送完标志,可以使用接收到数据标志代表完成。
