
电影《星际穿越》剧照
自动驾驶圈掀起了又一轮争吵。
「开城大战」、「是否真无图」的争端似乎还没有真正过去,一场端到端方案的较量就已经开始了。
理想的 VLM、小鹏的 XPlanner、华为的 ADS 3.0,在端到端这条路上,身处行业前沿的自动驾驶负责人们,用自己对行业的判断,结合团队能提供的资源,分别给出了接下来一段时间的最优解。
规划控制网络化 模块化端到端 完全黑盒单模型端到端
但这是一条不明朗的路,每个团队在选择了自己的答案的同时,其实也就否定了其他团队的路线。
不过,路线的分歧只是表象,每个团队的内部目标其实是一致的:「真正的无人驾驶」。
我无意于给出哪个模块更加先进的表述,在风起云涌的自动驾驶行业,每一种都有自己存在的必要性和成功的可能性。
这篇文章,我想尝试探讨一个最初的问题:什么能给我们带来真正的无人驾驶?
两个问题:
从特斯拉的白色卡车事故对感知神经网络的质疑,到今天我们对一些 AEB 误识别的争吵;
Uber 的自动驾驶事故对行业安全性和可靠性的恐惧,到最近 Cruise 依然挣扎在证明 Robtaxi 的可靠性;
特斯拉为首的纯视觉感知和多传感器融合派的多年争论,依然没有结果。
2023 年国内行业主机厂和图商之间对于是否要做去地图的争论,这似乎已经有了对错,但是轻图还在各家的技术栈里面嘲笑各家的宣传。
到今天我们开始争论端到端道路的正确性。
其实不难发现,我们争论不休的,一直是达成目标的工具,而非达成的目标本身。
如果我们要达成无人驾驶,我们忽略的房间里的大象到底是什么?
我想起来知乎上一个著名的问题: 自动驾驶什么时候才会凉凉,估计还要多久?
曾在 Google 无人驾驶项目组(现在的 Waymo)工作过的田渊栋对此非常悲观。
自动驾驶是个很有趣的问题,它不像传统的有监督学习,不在固定数据集上算性能,它的数据集是 on-policy 的,就是说会随着当前驾驶策略的变化而变化。
另外,并不是所有的数据都有用,对自动驾驶来说,大量数据都是单调重复的(比如说天气晴好,周围无车也没有行人),对改进行驶策略没有太大帮助。
所以,如果以自动驾驶道路数据闭环,不断改进性能的话,行车策略质量越好,人工干预的频率越低,得到的有效训练数据就越少,继续改进就越难。
为此他给出了下面这条曲线,自动驾驶性能可能在拉平之前,可能永远无法到达人类的水平。
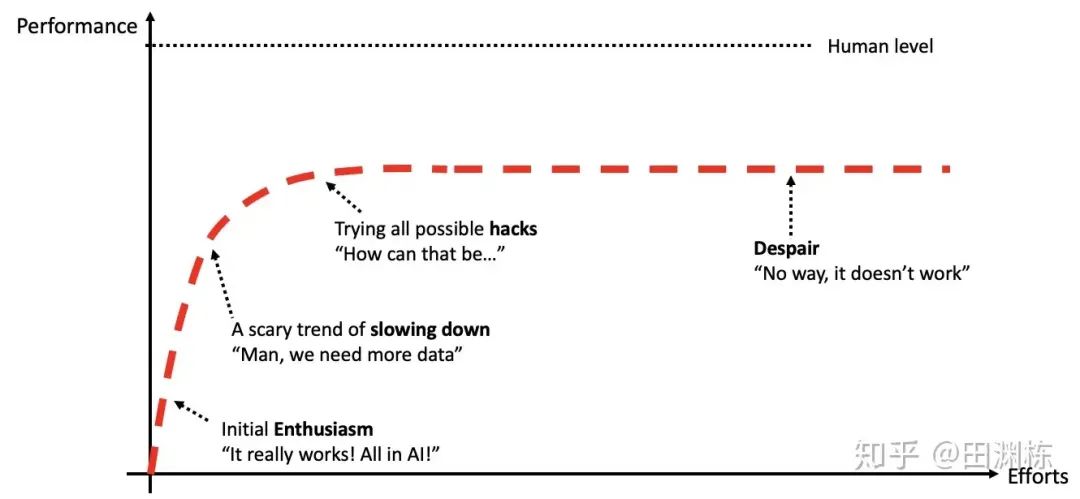
这是一个悲观的结果,他的回答来自于 2020 年。
这个话题回答的末尾是:
在 AI 能有下一步的理论突破之前,这些都是悬在大家头上的达摩克利斯之剑,随时要掉下来的。
从他的回答我们不难看出,基于纯道路数据的自动驾驶任务几乎是一个不可能完成的任务。
那么来到 2024 年,AI 有了进一步的突破了吗?
答案是毋庸置疑的,我们看到了 ChatGPT 3.5 的推理上的巨大突破,衍生的学习和工作方式的巨大变化,也看到了 Sora 在视频生成上对世界运行方式的惊人理解能力,基于大模型的具身智能的突破也让我们心潮澎湃。
那么无人驾驶从 AI 突破里看到曙光了吗?
如果路边有一个人穿着绘制着 STOP 的衣服,很有可能一辆无人驾驶车辆就会停住。

从工程师的角度看,这并不是稀奇的事情。由于北美驾驶场景中遇到路边的 STOP 是需要等待后通行的,同时在整个技术栈中,感知识别到 STOP 标志,然后向下游发送这个信号,下游进行执行。
从刚才的描述中,我们不难看出,整个技术的识别对场景没有全局的理解能力。 STOP 标志虽然识别成功了,但是系统对整体场景是没有理解能力的,识别到的是:
这是传统自动驾驶技术栈的缺陷,缺乏主动对场景的理解能力。
如果需要处理一个人穿着 STOP 标志的衣服的人,应该怎么办?
对于任何一个司机,这都不成问题,因为我们有对除了驾驶场景外的世界的理解能力,我们能理解人穿 STOP 标志的衣服。
那么就引申出来一个重要的问题,自动驾驶系统可以拥有这样的理解能力吗?或者自动驾驶系统需要怎么样才能获得这样的理解能力?
这里我们思考一个驾照申领过程,一般国内申领驾照需要成年。
为什么未成年不行?
实际上暗含的条件是:具备了足够的世界认知能力。
那么世界认知能力是怎么获得的?
从婴儿第一次睁开眼睛开始的视觉信息,到逐渐学会交流的语言信息,不断提升人的认知能力。
经过足够多的信息对人脑的训练之后,在驾校,通过集中学习,将这些能力迁移到驾驶场景中。
那么对于自动驾驶系统,如果我们想复制一个类似人学习驾照的场景需要怎么做?
用足够多的视频信息和语言信息训练一个系统(让这个系统满 18 岁),然后再用驾驶场景的数据对系统进行迁移(驾校)。
从而产生一个足够好的自动驾驶系统(拿到驾照)。
最后,用足够多的视频和语言信息训练一个系统,这听上去太熟悉了,这不就是一个多模态大模型吗?再进一步,最近最有名的多模态大模型是什么?
答案是:Sora
年初的时候,OpenAI 的视频甫一发布,整个文生视频圈发生大地震,模型展现出来非常强物理仿真能力和推理能力。

而在 OpenAI 的研究者眼中,拥有足够对世界的理解能力,并且能理解事物发生的前后关系的 Sora,就是一个世界模型了。
「世界模型」这是一个特别好理解,但却极其难以解释的概念,更别想想整个人工智能界为了将它应用在各个领域的难度了。
理解世界模型,你首先要理解的基本概念是,世界模型不是简单的「仿真系统」,这是我最近听到对世界模型描述最多,也是对它最大的误解。
仿真是工程师利用有限规则对环境的模拟,而世界模型是系统根据海量数据对物理世界的重建。
二者确实有很多相似的感觉,但所表达的内涵却完全不同,世界模型除了包含仿真可以对现实环境进行重构,其核心是,要表达物理世界里的物理规律。
理解「世界模型」的基本内涵,是理解世界模型如何帮助自动驾驶落地最重要的步骤。
世界模型相比其他自动驾驶技术,它的基本概念更加抽象,世界模型的概念最早是由 David Ha 和 Jürgen Schmidhuber 两名学术研究者发表的一篇文章里提到的。
但这篇名为「WorldModels」的文章并没有明确定义什么是世界模型,但它给出了一个概念,想让机器像人类一样认知世界,那就要像人类一样拥有理解世界构成以及元素之间关联关系的能力。
这里面的难点是,让机器做到这一点,目前最有用的方案是用大量数据进行学习训练,但本质上这所达到的还是让机器在模仿人,而不是和人一样。
而人脑的神经网路,可以基于一个极简化的数据训练后,获取一个理解物理世界环境的结果,更重要的是,人可以获取物理世界的物理定律信息。
举个例子,一个玻璃杯放在桌子上,我们知道这个玻璃杯完好静止在桌子上,但如果玻璃杯从桌子上掉下来,这个时候有趣的现象发生了,在玻璃杯没有碰到地的这个过程中,我们人类可以得到两个基本信息,一个是这个杯子会碎掉;另一个是掉地下不会碎掉,滚两圈。
你会问,这不是废话吗,谁都知道这两个结果。
但你有没有想过为什么人会知道这两个结果?
核心是,因为人知道玻璃材质会碎,上诉两个答案是根据人了解到的物理规律,关连已知玻璃这种材料得到的答案。
在硅谷101账号推文中有这么一句话,在这个 mental model 中,并不包含世界上的所有信息或细节,而只是包含了被我们选中的某些互相关联的概念。
换句话说,人们在头脑中构建的世界图像是现实世界的一个简化版,这个简化的模型不仅帮助我们理解世界,更重要的,我们还会根据这个头脑中的简化世界决定预测未来走向。
而世界模型也采用了类似的思维模式:在有限的、有选择性的信息基础上进行有效的决策和预测。更重要的是,和人脑一样,世界模型不仅需要预测立即的结果,还要能够预测更长时间序列的后果,这对于理解复杂环境和规划长期策略至关重要。
Yann LeCun 定义下的世界模型之所以强大,是因为它试图模仿智能生物与世界的互动方式:观察、理解、预测和行动,同时也考虑未知的事物和因素。
它是一个综合框架,可以应用于从玩视频游戏到导航现实世界环境的各种问题,目标是创建能够学习以对未知因素具有适应性和鲁棒性(在异常和危险情况下系统生存的能力)的方式导航和与复杂环境交互的模型。
是不是觉得以上的解释非常复杂很难懂?
根据文生视频明星创业公司 Runway 的表述:
A world model is an AI system that builds an internal representation of an environment, and uses it to simulate future events within that environment.
世界模型是一种人工智能系统,它构建环境的内部表示,并使用它来模拟该环境中的未来事件。
世界模型最重要的是能够对所有感官的信息进行关联,它不仅能够对基于感知获取的信息预测结果,更重要的是,世界模型可以对新的、没有见过的数据也能形成泛化的理解,也根据它对世界的理解,从而对未来做出预测。
在理想状态下,训练出的世界模型不仅能够复制它看到的数据,更能够理解数据背后的因果关系,并在新的情况下做出有效的预测。如果把世界模型的概念套用到视频生成领域则可以理解为,这个模型能够让机器像人类一样,对世界产生一个全面而准确的认知,从而生成更流畅、更符合逻辑、时间更长的视频。
在自动驾驶领域,自动驾驶端到端先驱 Wayve 和 Tesla 都用展示过自己的世界模型,通过用驾驶场景的视频训练模型,让模型在像素的变化中学会环境的理解和推理能力,进而产生足够强大的自动驾驶系统。
不论是学界还是业界,都对世界模型展现出了极大的兴趣。其中受到最多关注的还是 Wayve 的 Gaia 系列。
相较于其他模型在公开同质的数据上进行训练,Wayve 的数据来自于车辆在英国伦敦街头的数据收集结果,数据量也比学界常用的 nuScenes 大很多,自然理解世界的能力也更强。
在海量的数据进行训练之后,我们看到 Gaia 能够生成极其逼真的驾驶场景数据,并且能够产生难以收集到的驾驶场景。

根据 Wayve 的公开论文,他们会使用这些场景对自动驾驶系统进行训练、测试和仿真,加速自动驾驶系统的开发。
回到我们驾照的那个问题,我们几乎可以认为这条路可以产生对驾驶场景的深度理解,为什么不直接用这个世界模型进行自动驾驶任务呢?
蔚来的这次发布的 Nio World Model (NWM) 就是这么做的。
与 Wayve 的 Gaia 类似,蔚来的世界模型也主要通过对视频的学习,让模型学会了世界运行的规律。
具体来说,使用自动驾驶车辆收集到的原始传感器的数据,让系统在其中自动学习知识和物理规律,让整个视野的数据信息重建,并且想象下一个时间的世界。
就像我们日常驾驶一样,不断在推演下一时刻可能会发生什么,进而做出最优的选择。
但是与 Wayve 区别是,蔚来是一家量产车公司,具备足够体量和足够场景覆盖度的车队规模。
NT2.0 蔚来的传感器就非常统一,这意味着所有回流的数据都能给蔚来的世界模型进行训练,相较于 Wayve 只在伦敦运行,蔚来的世界模型所能使用的数据远远不是一个层级。
所以模型能够想象雨天、雪天、白天、黑烟等等不同的场景,也能够对成千上万个场景进行预测。
那既然可以预测千万个场景,是不是也可以让它在千万个场景中驾驶呢?这就又回到了我们驾校推演的线索里。
现在,这个模型学会了理解驾驶场景,怎么让模型学会驾驶?
NWM 可以在 0.1 s 内推演出 216 中可能发生的轨迹,寻找最佳决策,然后在接下来的 0.1s 内,根据外界信息的输入重复更新内在的模型,再去预测 216 中可能性,找到驾驶最优解。
这与我们驾驶时思考方式是基本一致的,看到一辆车,我们估计这辆车的行为,并且做出反应,然后再根据我们的动作和前方车辆的动作做出下一步的动作。
这些是模型的能力,那么这种模型要如何进行测试呢,这是一个动态的模型,需要有一个动态的场景才能进行测试。
例如我们的动作对环境的影响,还有环境接下来对系统决策的影响。
当然我们可以上实车进行测试,不过想象一下,一个刚刚训练出来的黑盒模型,我们摸不透它的想法,只知道它理解了这个世界。
但是有没有可能它学会的是迅速结束这个游戏呢?
例如在强化学习中,错误的奖励函数可能让这个智能体认为迅速结束游戏可以获得更好的结果。
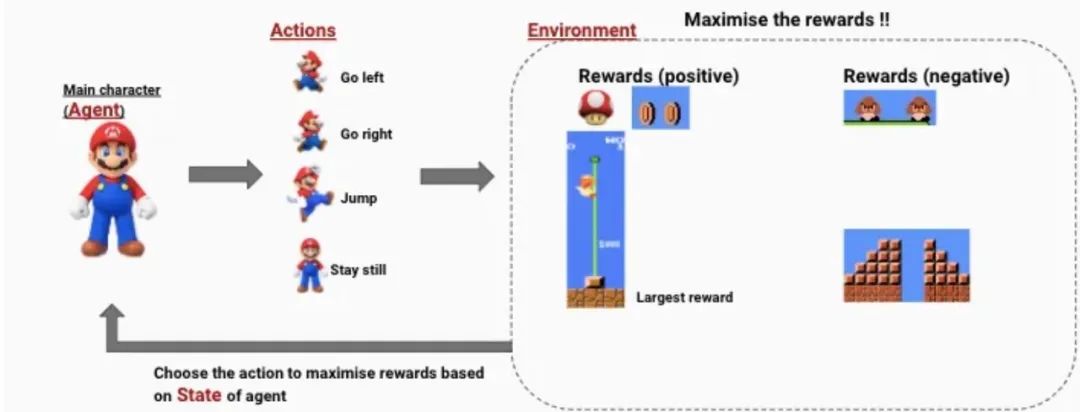
但这可是性命攸关的自动驾驶啊。
NSim 就出现了,这是蔚来为世界模型提供的驾校。
蔚来自动驾驶团队使用了现在非常流行的 Gaussian Splatting 技术,用行车的多个传感器共同重建出 3D 世界,并且能够让自动驾驶系统在其中进行测试,计算出更好的轨迹。
例如下面的视频,重建完了之后,提供了一定的视角转换能力,例如可以将视角抬升,左偏或者右偏。
对应的,对应左边变道和右边变道的轨迹就能在虚拟世界中进行严谨的验证。
那么测试团队就有机会看到,自动驾驶系统给出了不同的轨迹之后,是否会发生碰撞,是否会产生不合理的驾驶感受。
原本只能与真实世界中唯一的轨迹进行比对,有了 NSim 之后,更多比对的可能性迅速增加,千万个世界共同验证轨迹,进一步进行训练,让输出的智能驾驶轨迹更加合理和高效。
更重要的是,依托蔚来的群体智能,日行千万公里的真实场景数据,不仅可以用来训练世界模型,也可以用来进行三维重建,整个系统内部逻辑自洽而强大。
当然,关于模型的具体细节,巨大的参数量如何上车和具体表现,蔚来并未透露。
但是一幅完整的实现途径已经展现在了我们面前。
写在最后
最近刚好在看人工智能先驱李飞飞的自传《我所看到的世界》,惊讶于她波折的成长史的同时,也看到她在人工智能领域的超前布局。
她执意于数据集的收集和标注,为此才有了 ImageNet 上的巨大突破。
那时连神经网络的研究都没有成为主流,学界认为是扫进历史垃圾堆的老古董。
在 AlexNet 算法变革产生之前,ImageNet 就像一座宝库在等待未来的骑士。
而蔚来这么多年的群体智能积累,似乎也在等待对数据有着更大要求的这一天。
端到端、世界模型,这些无不告诉我们海量数据的重要性。在新的数据组织方式没有出现前,或许这海量的道路上收集的驾驶视频,就是指引我们的北极星。
那么端都端或者世界模型会是自动驾驶的终局吗?
这个问题似乎依然没有答案,但是我们看到所有的模型进步都在学习人类。
不论是神经网络类似于突触的结构,还是现在世界模型希望找到人类的认知方式,到我们期待能逐渐完成通用人工智能。
ImageNet 以 1500 万张图片的规模,涵盖 2.2 万个类别,让神经网络实现了在分类任务上对人类的超越。
那是在 2015 年 ResNet 问世,视觉识别错误率仅 4.5%,人工智能开始井喷发展。而蔚来的自动驾驶负责人任少卿,就是 ResNet 的重要贡献者。
ResNet 问世十年的时候快要到了,我们也期待有一个新的范式出现,在复杂的驾驶任务上超过人类。
那么我们是否能够期待,这个新的任务十年后也由任少卿带领的蔚来自动驾驶团队完成?
