
近十年来,计算行业经历了从32bit、“x86-64”、多核心、通用GPGPU以及2010年“CPU—GPU”异构计算的变迁。而最近几年,随着人工智能、高性能数据分析和金融分析等计算密集型领域的兴起,异构计算才突然火了起来。
一、GPU性能高、功耗大、通用性好,适用于数据中心和训练过程
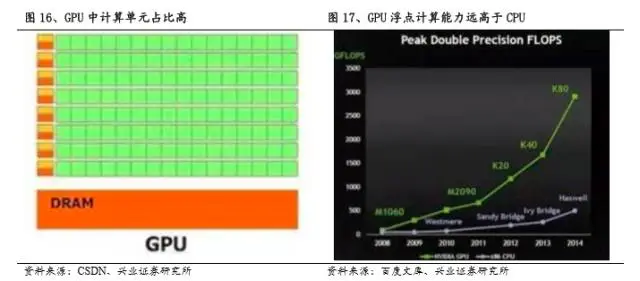
GPU是图形处理器的英文简称,是用于进行图像运算工作的微处理器,可以对图形数据、显示、可视计算等作出优化加速,现在被用于通用计算的GPU也被称作GPGPU。因为图形的结构像素点之间是独立的,图像以矩阵形式存储数据,所以GPU的设计之初就基于大吞吐量和并行计算,有80%的晶体管用作计算单元(CPU只有20%左右),具有很强的浮点运算能力和超长的流水线处理。这一特点非常适合AI计算对芯片进行大量重复运算的速度要求,故被广泛引入深度学习的训练应用领域。
GPU的主要优点:
1. 具备成熟易用的编程语言。GPU经过十几年的发展,在2006年已经实现了直接程序编写。目前有CUDA统一架构、OpenCL架构等编程环境,编程性大大提升。可以对CPU+GPU等异构进行统一编译,通过C语言也可以进行调用,为后续的发展打下基础。
2. 性能强悍,峰值计算能力强。GPU基于SMID架构,并行计算处理大规模数据,其峰值计算能力是所有芯片中最强的,处理速度可达同期CPU的10倍以上。
3. GPU应用时间早,现有产品比较成熟,价格不高。GPU是最早引入人工智能领域的芯片,近几年几乎包揽了各种初步的应用场景,所以成熟的产品和解决方案较多,价格也比较合理。
GPU的主要缺点:
1. 在深度学习推测阶段不具优势,平均性能不如专门的AI芯片。由于推测阶段为多指令流单数据流计算,传统GPU受限于冯诺依曼结构,并行度优势无法完全发挥,非专门为AI计算研发的GPU平均性能较FPGA和ASIC也偏低。
2. 总体功耗水平较高。正常情况下GPU的功耗相比定制化程度较高的芯片功耗水平较大,即便是运行在Volta架构下最新的英伟达Tesla系列GPU,相比完全定制的ASIC,在实现相同计算性能时需要的功耗也较高。
3. 硬件结构不具备可编辑性。GPU的硬件结构是提前设定好的,无法临时编辑,不够灵活,在选择通用性的同时放弃了定制化的优势。

GPU适合应用于深度学习训练和数据中心。基于强大的峰值计算能力和数据并行处理能力,GPU非常适合用于深度学习的训练阶段,形成复杂的神经网络模型。同时,GPU能够作为企业大型数据中心的加速器,数据中心依赖大量互连的通用计算节点,在性能方面难以驱动重要的高性能计算 (HPC) 和超大规模工作负载。GPU能打造出速度极快的计算节点,性能高于数百个速度较慢的通用计算节点,大幅提高数据中心的计算性能和数据吞吐量。
目前功耗是GPU发展最大的瓶颈。由于传统GPU与CPU一样使用冯诺依曼结构,需要与内存之间实现信息交换,不可避免得增大了功耗,降低了通信速度,因此相比于ASIC芯片,难以作用于智能终端。
二、FPGA效率高、灵活性好,但峰值性能较弱、成本较高,适用于虚拟化云平台和预测过程
FPGA更适合处理多指令流单数据流,从而适应于预测阶段。目前在深度学习模型的训练领域基本使用的是SIMD(Single Instruction Multiple Data:单指令多数据流架构)计算,即只需要一条指令就可以平行处理大批量数据。但是,在平台完成训练之后,它还需要进行推理环节的计算。这部分的计算更多的是属于MISD(Multiple Instruction Single Data:多指令流单数据流)。因此,低功耗,高性能,低延时的加速硬件成为了必需品,因此人们把目光转向了“FPGA”与“ASIC”。
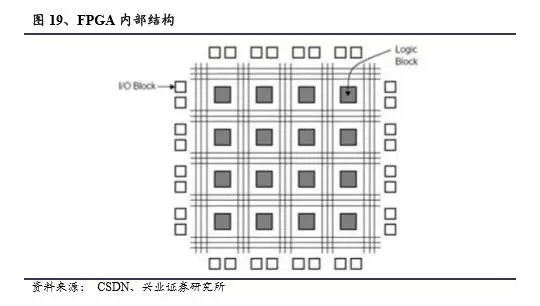
FPGA突破了冯诺依曼结构,流水线设计减少了数据在内存、缓存和处理单元之间的能耗。FPGA是指现场可编程门阵列,其中包含逻辑元件、DSP 数据块、片上内存和灵活的 I/O。芯片内部集成了大量的数字电路基本门电路以及存储器,可以直接烧入FPGA配置文件来定义电路之间的连线,所以FPGA是可定制编辑的,同一块芯片可以随时通过不同的配置文件烧入来更改功能,就像乐高积木,可以随时拆分和重组,灵活性极高,在处理小计算量大批次的实际计算时FPGA性能比GPU更强,适合深度学习的预测环节。逻辑层面上,它不依赖于冯诺依曼结构,一个计算得到的结果可以被直接馈送到下一个节点,无需在主存储器临时保存,所以其通信速度也非常快。
FPGA与深度学习中最常用的CNN网络匹配度很高。深度学习中最常用的CNN网络,其分层的结构和FPGA硬件流水线结构以及MISD的处理方式匹配度很高。利用片上DSP和存储模块,FPGA能够根据CNN的网络特征设计出有针对性的流水线,在实现MISD的同时还可以将中间结果保存在本地缓存模块,以降低内存读写的能耗,从而比GPU以更低的能耗更快完成CNN的计算。
FPGA的优点:
1. 突破冯诺依曼结构,功效能耗较低,处理效率较高。FPGA的电路可直接实现算法,没有指令译码和解读的过程,减少反复冗余访问外部存储器的需求,存储器带宽需求及能耗较低,功效能耗比是 CPU的10倍以上、GPU的3倍,处理速度和效率要高于GPU。
2. FPGA可编译,灵活性很高,开发周期短。FPGA具有可编辑性,用户可以根据自身需求实现芯片功能的转换,灵活性很强。基于FPGA灵活编译的特点,其开发周期较短,上市速度快,更好地适应当前人工智能领域技术需求的快速更迭,对制造商来说风险较小。此外,FPGA也比ASIC具有更长的可维护周期,更小的初期成本。
FPGA的缺点:
1. 价格较高,规模量产后的单价更是远高于ASIC。目前FPGA的造价相比GPU更为高昂,如果规模量产后,其不像ASIC可以分摊固定成本,存在单个芯片的编译成本,所以单价远高于ASIC。
2. 计算能力和峰值性能不如GPU。 FPGA的可编程性用在虚拟化服务的云平台很好,但其中的逻辑单元很多都是基于SRAM查找表,不如GPU中的标准逻辑模块,使得其峰值性能不如GPU。同时,在布线方面也有较大的现值,无法像在ASIC FLOW下那样较为自由的布局。
3. 灵活性占优的同时牺牲了速度与能耗。FPGA在维持了灵活性的同时,效率和功耗上劣于专用芯片ASIC。
4. FPGA的语言技术门槛较高。目前FPGA的设置要求用户用硬件描述语言对其进行编程,需要专业的硬件知识,具有较高的技术门槛,但随着包括OpenCL在内的软件级编程模型在FPGA的应用,研究时间相对有所缩短。
FPGA应用于硬件平台加速、数据中心和云端深度学习预测。FPGA兼具较高的性能和灵活性,适用于硬件平台的加速。比如微软开发了带有FPGA“硬件加速芯片”的主板来提升Bing数据中心的整体性能,相比于传统CPU在处理Bing的自定义算法时快出40倍。另外FPGA低能耗的特点也得其对大型企业的线上数据处理中心具有吸引力。
FPGA具有处理MISD的优势,所以适用于深度学习的预测阶段,同时FPGA的可编程性使其非常适合放在虚拟化的云平台背后,给予云服务商根据市场需求调整FPGA加速服务供给的能力。
没有极致的性能特点与量产单价高是其未来发展的瓶颈。FPGA仍然具有通用类芯片的特点,为实现灵活性,FPGA的各项指标均有折扣,尽管在能耗方面相比CPU和GPU有明显优势,但随着人工智能应用领域的扩大,FPGA的半定制性可能会使得芯片逐渐成为一种过渡和替代性质的附注品,训练阶段的性能不如GPU,预测环节下的计算效率与功效能耗比则不如ASIC。
另外,FPGA的量产单价高,意味着其无法大量生产,更适合用于细分、快速变化的垂直行业,在应用面上较为狭窄。
三、ASIC效率高、功耗比佳,但量产前成本高,适用智能终端和AI平台
ASIC是指专用集成电路,为符合特定用户需求而设计的专用人工智能芯片。不同于FPGA,ASIC的电路一旦设计完成后就不可更改,用乐高积木比喻FPGA的话,ASIC更像是3D打印,是完全定制化的芯片,当然相比FPGA也更加精致,有更多的物理设计,运行速度在同等条件下也比FPGA更快。
ASIC的优点:
1. 性能上的优势非常明显,具有最高的功效能耗比。ASIC是专业AI芯片,相比GPU和FPGA没有多余的面积或架构设计,可以实现最快的通信效率与计算速度,实现最低的能耗。
2. 下游需求促进人工智能芯片专用化。随着人工智能的发展和下游智能终端的普及,AI芯片需求大幅上升,而出于对信息隐私保护和云端计算需要联网的考虑,完全依赖云端是不现实的,需要有要有本地的软硬件基础平台支撑,所以专有化的AI芯片有很大的优势。
ASIC的缺点:
1. 造价昂贵,需要保证量产才能降低成本。ASIC由于是定制化芯片,有大量附加工艺设计需要考虑,投入的成本非常高,对企业带来资金风险。若芯片能实现量产并大规模投入使用,其单价成本才能有效降低。
2. 不可编辑,灵活性较差。定制化芯片的算法是固定的,研发时间较长,灵活性不够高,在行业发展初期面对日新月异的人工智能算法其适应性相对较低,尤其对于技术能力和市场能力不足的企业,风险非常大。
ASIC芯片应用于人工智能平台和智能终端。ASIC芯片由于其定制化的特点,具有功能的多样性,应用非常广泛。高性能和低功效使其不再局限于深度学习的训练或推测阶段的其中之一,而是可以作为支撑人工智能平台全阶段加速的芯片。
ASIC虽然其一次性成本远远高于FPGA,但量产成本低,另外ASIC的定制功能和神经网络预测能力能够解决FPGA在设备端的劣势,因此应用上就偏向于消费电子,如移动终端等领域。
四、类脑芯片能耗低、感知力强,但缺乏训练方法、精度低
类脑芯片仍属于小众芯片,突破性发展需要更好的深度学习训练方法。类脑芯片是从架构上模仿人脑神经结构的芯片,与当前AI芯片普遍作为神经网络算法加速器不同,前者模仿神经结构从底层构建人工智能,后者则模仿神经处理信息的功能流程。IBM在10年前就开始类脑芯片的研究,主要基于脉冲神经网络(Spiking Neural Network,SNN),通过脉冲的频率或者时间在神经元之间传递信息,而不是通过节点之间的权重。
这种芯片把数字处理器当作神经元,把内存作为突触,跟传统冯诺依曼结构不一样,它的内存、CPU和通信部件是完全集成在一起。因此信息的处理完全在本地进行,而且由于本地处理的数据量并不大,传统计算机内存与CPU之间的瓶颈不复存在了。同时神经元之间可以方便快捷地相互沟通,只要接收到其他神经元发过来的脉冲(动作电位),这些神经元就会同时做动作。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。

