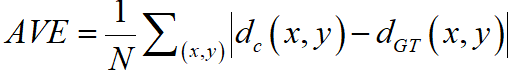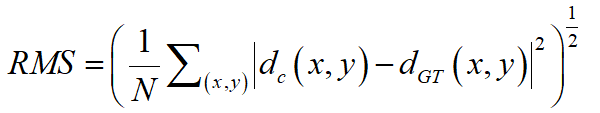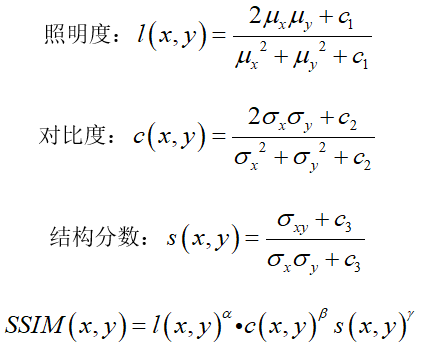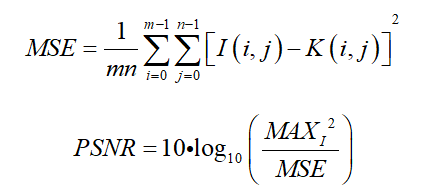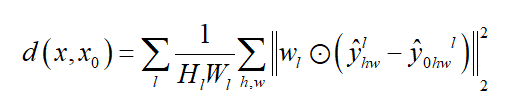今日光电
有人说,20世纪是电的世纪,21世纪是光的世纪;知光解电,再小的个体都可以被赋能。追光逐电,光赢未来...欢迎来到今日光电!

----追光逐电 光赢未来----
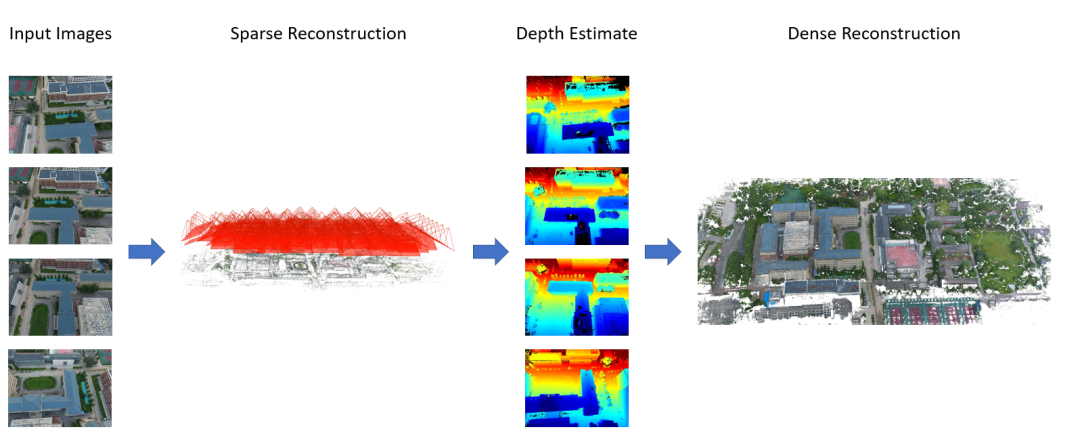
本文对利用多视角影像进行大规模场景三维重建的相关技术进行了总结与分析。三维重建方法通常分为传统方法和基于学习的方法,根据是否主动用光源照明物体又可分为主动式方法和被动式方法。本文简要介绍了结构光重建和激光扫描法重建两种主动方法,重点介绍了运动恢复结构(SfM)、立体匹配和多视图立体(MVS)等被动方法,详细阐述了这些方法在大规模场景重建中的应用挑战及改进建议,介绍了该领域常用的数据集和评估指标,并对未来发展趋势进行了预测。三维重建是用于在现实世界中表示虚拟现实的关键技术,在计算机视觉中具有重要价值。大规模三维模型在智慧城市、导航、虚拟旅游、灾害预警和搜救任务等领域具有广泛的应用前景。但是,目前大多数基于图像的研究主要关注室内场景中三维重建的速度和准确性。虽然也有一些研究涉及大规模场景,但在这一主题上没有系统、全面的研究综述。因此,本文对利用多视角影像进行大规模场景三维重建的技术进行了总结与分析。图1 三维重建示例:(左)真实图像 (右)三维模型:点云
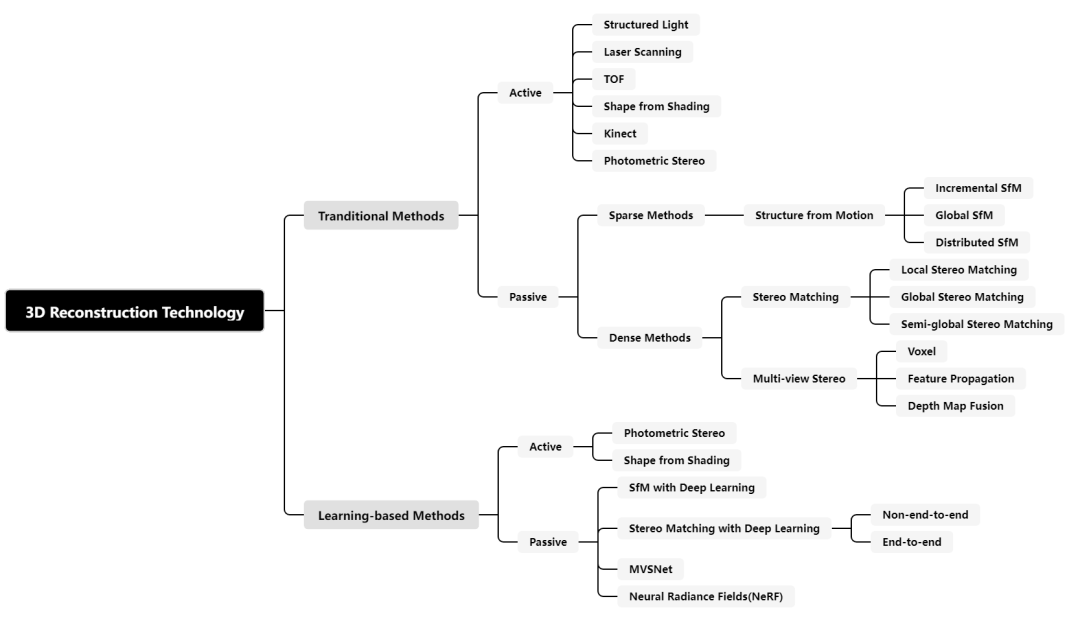
基于神经网络的使用情况,三维重建技术大致分为传统方法和基于学习的方法。此外,根据获取场景信息的方法,这些方法可以进一步分为主动和被动重建方法,如图2所示。图2 三维重建方法分类

传统方法
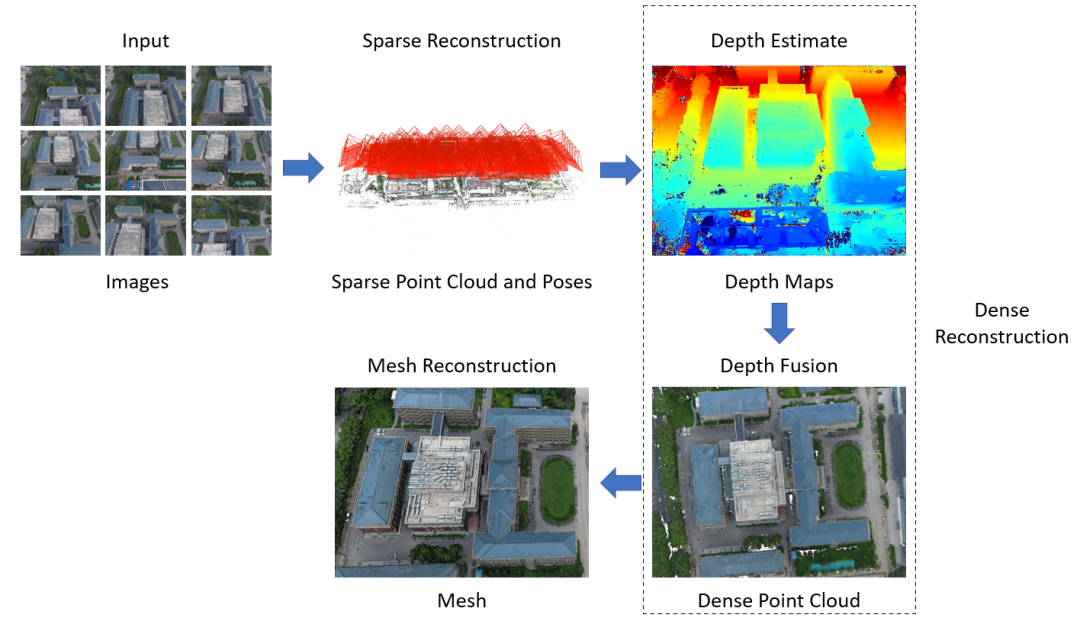
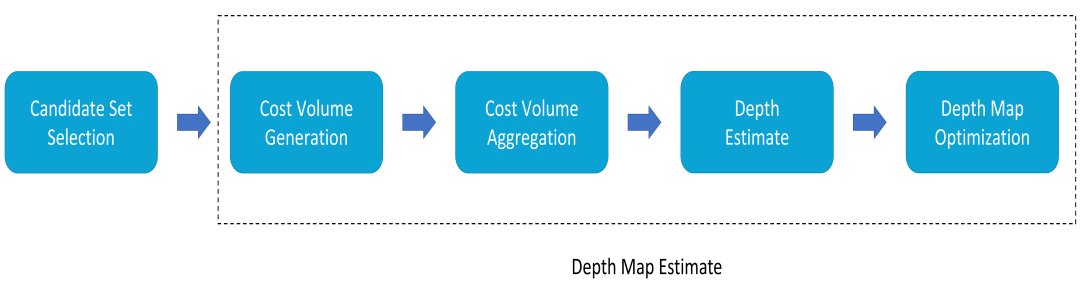
传统的被动式重建方法中,首先需要对图像中的特征点进行检测与匹配,将不同图像上的同样的特征点进行关联从而进行后续的相机位姿估计以及点云重建。一种典型的三维重建流程如图3所示。本节主要介绍点云重建中的运动恢复结构(Structure From Motion, SFM)、立体匹配(Stereo Matching)以及多视角立体视觉(Multi-View Stereo)技术及其发展。图3 一种典型的三维重建流程
2.1 稀疏重建:运动恢复结构
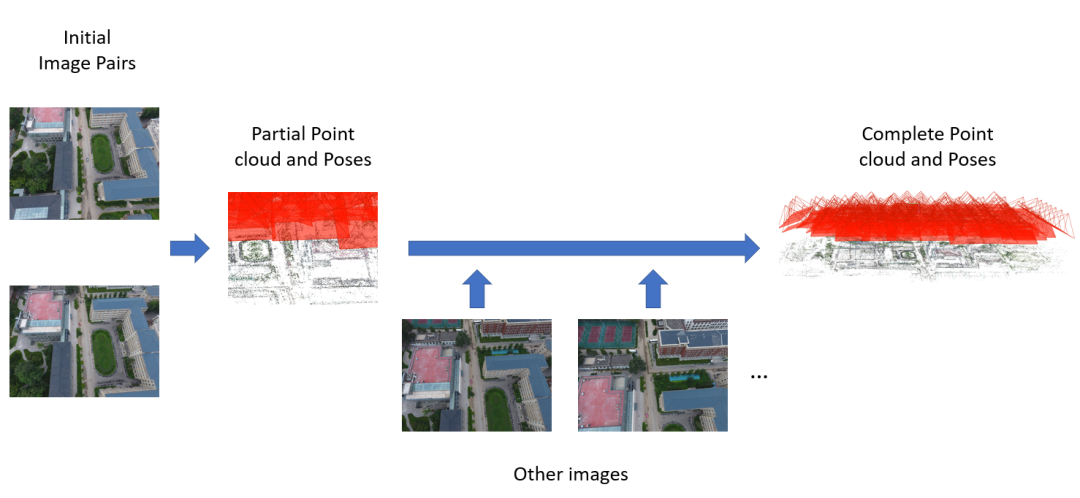
运动恢复结构(SfM)是一种从多个图像或视频序列中自动恢复相机参数和三维场景结构的技术。SfM使用相机的运动轨迹来估计相机参数。通过从不同视角捕获图像,计算相机的位置信息和运动轨迹。随后,在空间坐标系中生成3D点云。根据对未知参数的不同初始值估计方法,现有的SfM方法可以分为增量式、全局式和分布式。增量式SfM是目前最广泛使用的方法,它涉及选择图像对并重建稀疏点云。首先,选择初始图像对计算相机位姿并重建部分场景;然后,逐渐添加新图像以计算完整的点云,如图4所示。Photo Tourism是Snavley等人提出的最早的增量式SfM系统。它首先选择一对图像来计算相机位姿并重建部分场景。然后,逐渐添加新图像,并调整先前计算的相机位姿和场景模型,以获得相机位姿和场景信息。增量式SfM的主要缺点如下:
1)对初始图像对的选择敏感,导致重建质量受限于初始图像对的选取。
2)随着新图像的添加,误差会累积,导致场景漂移现象。
3)增量式SfM是一个迭代过程,每个图像都经历光束平差法优化,存在大量的冗余计算,重建效率较低较低。全局式SfM包括相机全局的旋转估计、位置估计和点云生成。相比于增量式SfM,全局SfM将所有图像作为输入,仅进行一次光束平差法优化,从而显著提高了重建速度。它均匀分布误差,避免了误差累积,从而提高了重建的精度。然而,由于相机之间的相关性不同,全局SfM对于大规模场景重建可能产生不理想的结果。2022年,Pang等人提出了一种基于全局式SfM的分段式算法用于无人机野外场景三维重建,其首先按照经纬度大小对无人机图像进行分组,进行特征提取匹配并去除误匹配,然后对不同组的图像分别进行全局式的SfM获得分组的相机姿态和稀疏点云,再根据分组顺序进行点云融合、场景空间点以及相机位姿优化,最后对融合后的数据再进行全局式的SfM,从而获得整个大场景的点云。全局SfM的主要缺点如下:
1)全局SfM方法计算密集,可能需要大量时间和计算资源,特别是对于具有许多图像和3D点的大型数据集。
2)全局相机位置估计结果不稳定。
3)全局SfM对数据中的异常值敏感。如果存在错误的对应或噪声测量,则这些因素会对全局优化过程产生重大影响。
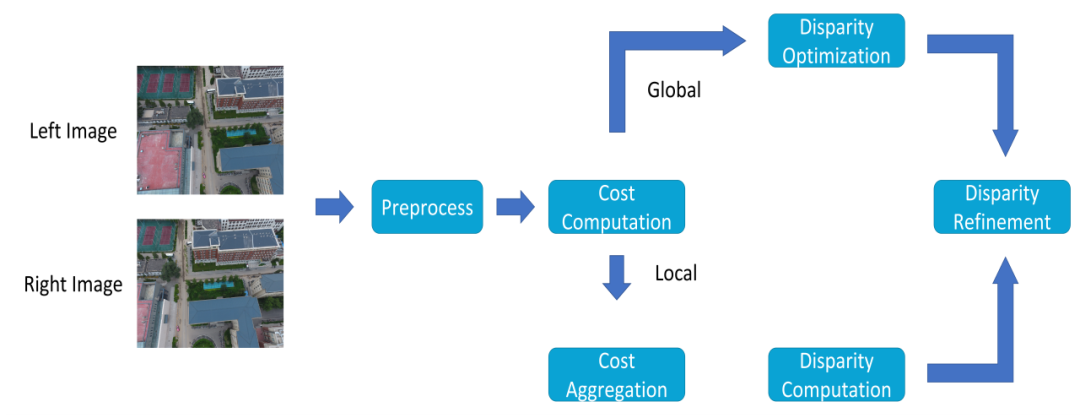
尽管增量式SfM在稳健性和准确性方面具有优势,但其效率不够高。此外,随着误差的累积,场景结构可能在大规模场景重建中出现漂移;全局SfM比增量式方法更高效;然而,它对异常值敏感。2017年,Cui等人提出了一种分布式SfM方法,将增量和全局方法结合起来。其利用全局式方法计算相机的旋转矩阵,然后通过增量式方法每增加一张图像就计算一次计算相机位置,最后进行局部的光束平差算法只针对相机光心位置以及场景空间坐标点进行优化,从而在保证鲁棒性的前提下提高了重建速度。2021年,王等人介绍了一种用于同时估计全局旋转和平移的混合全局SfM方法。分布式SfM在一定程度上结合了两种方法的优点。立体匹配是为了在左右摄像机拍摄的两幅图像中寻找像素的对应点,计算相应的视差值,然后通过三角形相似性原理求取物体到摄像机之间的深度信息,由于存在光照不均匀、遮挡、模糊以及噪声等的影响,给提升匹配精度带来了巨大的挑战。立体匹配主要分为四个步骤:匹配代价计算、匹配代价聚合、视差计算以及视差求精,同时为了提高匹配精度,立体匹配需要一些约束条件来提高准确率并降低搜索难度如:极线约束、唯一性约束、视差连续性约束、顺序一致性约束和相似性约束等,根据这些约束方法的不同,立体匹配算法可以分为全局匹配法、局部匹配法和半全局匹配方法。局部匹配法基于窗口、特征以及相位等局部约束,主要利用图像的灰度信息进行匹配。基于窗口的匹配方法通过给定感兴趣像素周围的少量像素的灰度值之间的对应关系确定视差,固定窗口、自适应窗口以及多窗口是目前主要研究的窗口算法。局部匹配算法可以快速生成视差图,但其精度不足,特别是低纹理、视差不连续的区域。局部匹配方法高效灵活,但缺乏对场景的整体理解,容易陷入局部最优。全局匹配算法主要利用图像中的全部像素信息和相邻像素的视差信息来进行匹配。它们使用约束条件创建能够整合图像中所有像素的能量函数,旨在获得尽可能多的全局信息。全局立体匹配算法可以通过动态规划、置信度传播和图分割等方法优化能量函数。全局匹配方法结合了局部匹配方法的优点,并采用了局部最优密集匹配方法中的成本聚合方法。它们引入了正则化约束以获得更稳健的匹配结果,但消耗更多的计算时间和内存资源。此外,与局部匹配方法相比,全局匹配方法更容易将附加先验信息作为约束集成,例如城市场景中普遍的平面结构信息,从而进一步增强重建结果的细化。半全局匹配也采用能量函数最小化的概念。然而,与全局匹配方法不同,其将二维图像的优化问题转化为沿多个路径(即扫描线优化)的一维优化。它沿着多个方向的路径聚合成本,并使用赢者通吃(WTA)算法计算视差,实现了匹配精度和计算成本的良好平衡。当前的半全局立体匹配算法在准确性和效率方面取得了显著进展。然而,它们在准确性和效率之间还没有实现良好的平衡。在使用SfM进行场景重建时,特征匹配点的稀疏性通常会导致稀疏的点云,重建结果也是差强人意。为了克服这一局限性,采用了多视角立体(MVS)技术来增强重建。MVS利用场景中的相机姿态参数来捕获更丰富的信息。此外,还使用了在2.2节中提到的立体匹配匹配。主要目标是通过最佳的方法对不同图像上的同一个点进行匹配,从而增强场景的稠密性,提高重建效果,如图6所示。MVS可以通过三种主要方法实现:体素重建法、特征点扩散法和深度图融合法。基于体素的算法首先确定一个空间范围,一般是一个足够包围整个待重建场景的立方体,之后对立方体进行分块得到小立方体,也就是体素。通过一些方法对体素进行填充,有场景占用的小块进行填充,没有场景的块不进行填充,这样就可以得到物体的三维模型。但是这种算法的缺点一方面在于需要首先确定一个固定的空间范围,而对于超过该范围的物体无法进行重建,另一方面算法的复杂度限制了分块的数目,导致物体的分辨率比较低。特征点扩散法涉及生成表面片和基于初始特征点的初始点云。这些特征点被投影到图像上,并传播到周围区域。最后,表面片用于覆盖场景表面进行三维重建。每个表面片可以被视为一个矩形,其中包含诸如其中心和表面法线向量等信息。通过估算表面片并确保完全覆盖场景,可以获得准确且密集的点云结构。如2010年, Furukawa提出了一种基于特征传播的MVS算法,称为PMVS。深度图融合方法是多视角立体视觉中最常用且有效的方法。通常包括四个步骤:参考图像选择、深度图估算、深度图优化和深度图融合。在多视角立体重建中,估算深度图是一个关键步骤,其为图像中的每个像素分配合适的深度值。这种估算通过最大化图像与以该像素为中心的参考图像中相应窗口之间的光度一致性来实现,如图7所示。光度一致性的常见度量包括平均绝对误差(MAD)、误差平方和(SSD)、绝对误差和(SAD)以及归一化交叉相关系数(NCC)。
基于学习的方法
传统的三维重建方法已被广泛应用于各个行业和日常生活中。虽然传统的三维重建方法仍然主导着研究领域,但越来越多的研究人员开始研究使用深度学习进行三维重建,探索两种方法的交叉和融合。随着深度学习的发展,卷积神经网络(CNN)在计算机视觉中得到了广泛应用。卷积神经网络在图像处理中具有显著优势,它们可以直接将图像作为输入,避免了传统图像处理算法中的特征提取和数据重建的复杂过程。尽管基于深度学习的三维重建方法相对较新,但由于其发展迅速,深度学习在三维重建研究中仍取得了重大进展。3.1 基于深度学习的运动恢复结构
由于卷积神经网络在特征提取和匹配中的高准确性和高效率,深度学习和SfM的结合使得相机姿态和场景深度的估计更加高效。2017年,Zhou等人利用无监督的光度误差最小化取得了良好的结果。他们使用两个联合训练的卷积神经网络来预测深度图和相机运动。Ummenhofer等人利用光流特征估算场景深度和相机运动,提高了在陌生场景中的泛化能力。2018年,Wang等人将深度和运动之间的多视图几何约束纳入其中。他们使用卷积神经网络来估计场景深度,并使用可微模块计算相机运动。2019年,Tang等人提出了一个名为BA-Net(Bundle Adjustment Network)的深度学习框架。网络的核心是一个可微的光束平差层,它基于卷积特征预测场景深度和相机运动,其强调了多视图几何约束的一致性,使得能够重建任意数量的图像。3.2 基于深度学习的立体匹配
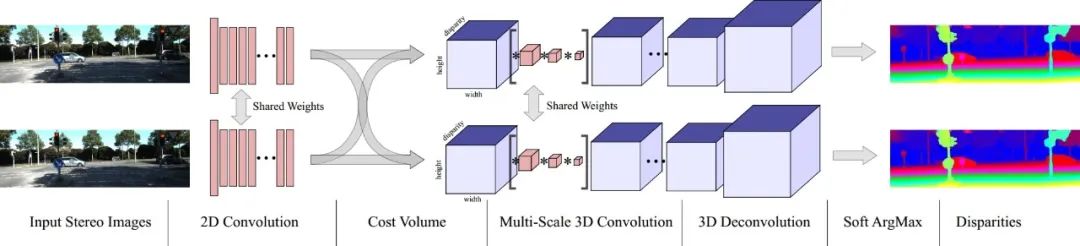
2015年,LeCun等人首次提出了在成本计算中使用卷积神经网络来提取图像特征。此外,他们提出了带有交叉成本一致性检查的成本聚合。这种方法消除了错误匹配区域,标志着深度学习作为一种重要技术的出现。用于立体匹配的非端到端图像网络可以分为三种主要类型:金字塔网络、孪生网络和生成对抗网络。基于深度学习的非端到端立体匹配方法,基本上不脱离传统方法的框架。一般来说,它们仍然需要添加手工设计的正则化函数或后处理的视差步骤。这意味着非端到端立体匹配方法具有计算复杂度高、时间效率低等缺点,并且没有解决传统立体匹配方法中存在的问题,比如有限的感受野和缺乏图像上下文信息。2016年,Mayer等人成功地将端到端网络结构引入到立体匹配任务中,并取得了良好的结果。设计更有效的端到端立体匹配网络逐渐成为立体匹配的研究趋势。当前的端到端立体匹配网络以左右视图为输入。在使用共享权重的卷积模块进行特征提取后,它们使用相关性操作构建代价体。最后,根据代价体积的维度应用不同的卷积操作来回归视差图。端到端立体匹配网络可以根据代价体积的维度分为两种方法:基于3D代价体和基于4D代价体。在本文中,重点介绍了基于4D代价体的方法。与受传统神经网络模型启发的架构相比,基于4D代价体的端到端立体匹配网络架构专门设计用于立体匹配任务。在这种架构中,网络不再对特征进行维度缩减,允许代价体保留更多的图像几何和上下文信息。2017年,Kendall等人提出了一种名为GCNet的新型深度视差学习网络,如图8所示,它创造性地引入了4D代价体,并首次在正则化模块中使用3D卷积来整合来自4D代价体的上下文信息。这种开创性的方法设计了一个专门用于立体匹配的3D网络结构。它首先使用共享权重的2D卷积层分别从左右图像中提取高维特征。在这个阶段,通过降采样将原始分辨率减半,有助于降低内存消耗。然后,左侧特征图和相应的右侧特征图通道沿着视差维度逐像素组合,形成4D代价体。之后,它利用由多尺度3D卷积和反卷积组成的编码-解码模块对代价体积进行正则化,得到一个代价体张量。最后,利用可微的Soft ArgMax回归代价体,获得视差图。3.3 基于深度学习的多视角立体
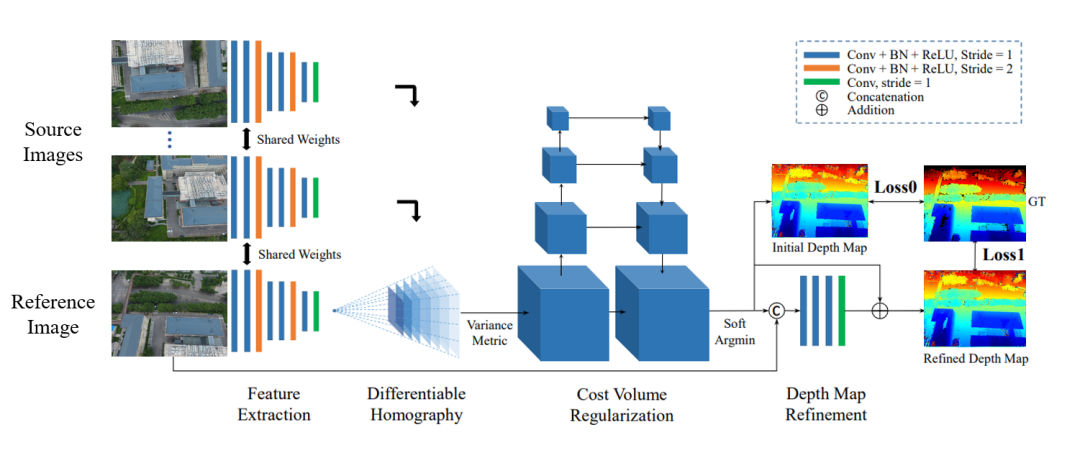
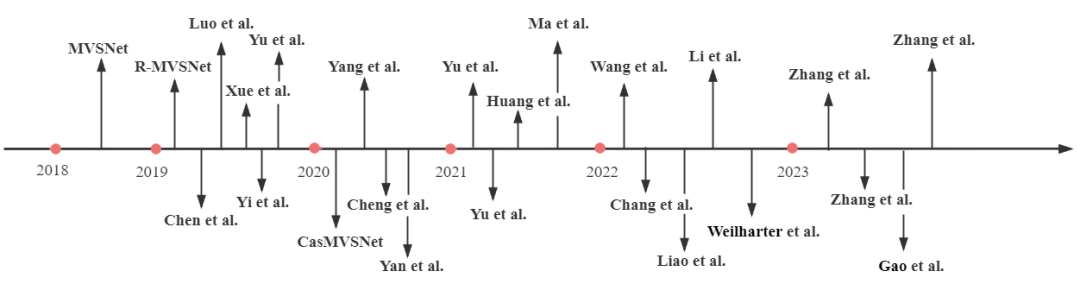
2018年,Yao等人首次将卷积神经网络与多视图立体匹配结合,首创了MVSNet。他们使用卷积神经网络提取图像特征,利用可微的单应性矩阵构建代价体,并利用3D U-Net对代价体进行正则化,实现了多视图深度估计,如图9所示。在这项工作的基础上,Yao等人在2019年引入了RMVSNet,通过在MVSNet中用门控单元替换3D卷积,实现了内存消耗的降低。Chen等人提出了PointMVSNet,采用图卷积网络对MVSNet生成的点云进行改进。介绍了P-MVSNet,该方法通过Patchwise方法显著改善了深度图的准确性和完整性,并重建了点云。Xue等人提出了MVSCRF,该方法将条件随机场(CRF)模块结合到深度图上以强制执行平滑性约束,从而提高了深度估计的精度。Yi等人提出了PVA-MVSNet,通过自适应地聚合像素和体素级别的视图来生成深度估计,具有更高的置信度。Yu等人提出了Fast-MVSNet,采用稀疏代价体和高斯-牛顿层来提高MVSNet的运行速度。2020年,Gu等人介绍了级联MVSNet,这是一个重新设计的模型,通过图像特征金字塔以级联方式编码不同尺度的特征,既节省了内存资源,又提高了MVS的速度和准确性。Yang等人提出了CVP-MVSNet,该方法采用了类似金字塔的成本-体积结构,在不同尺度上调整深度图,从粗到细。Cheng等人开发了一个网络,自动调整深度间隔以避免密集采样,并实现了高精度的深度估计。Yan等人引入了D2HC-RMVSNet,这是一个高密度的混合递归多视图立体匹配网络,包括动态一致性检查,产生了优异的结果,同时显著减少了内存消耗。提出了RED-Net。它引入了循环编码器-解码器(RED)架构来顺序地正则化代价体,实现了更高的效率和准确性,同时保持了分辨率,有利于大规模重建。图10根据时间顺序给出了一些现有的MVSNet方法。3.4 神经辐射场
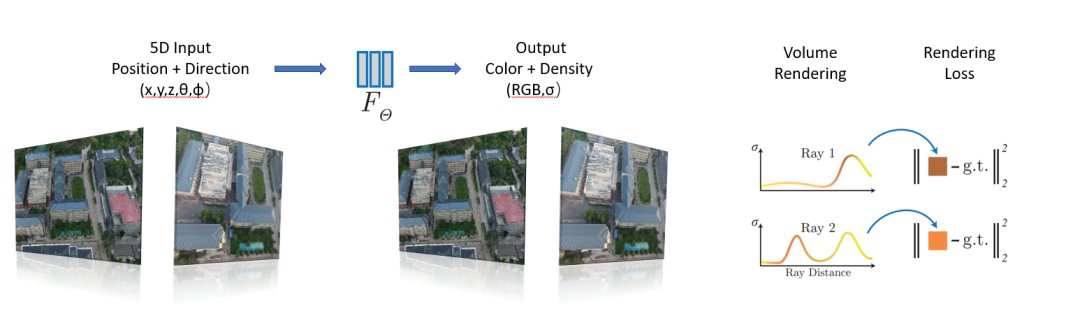
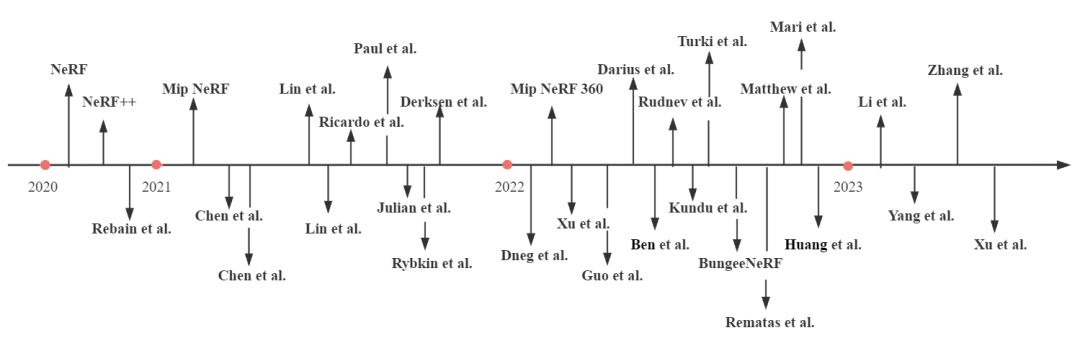
2020年,Ben等人引入了一种开创性的场景渲染技术,称为神经辐射场(NeRF)。NeRF是一个端到端的学习框架,利用对象的空间坐标和相机姿态作为输入,利用多层感知器(MLP)网络来模拟神经场,其架构如图11所示。这个神经场表示了对象在特定方向上的标量属性,比如不透明度。通过在场景中追踪光线并根据光线和不透明度进行颜色积分,NeRF可以从新的视点生成高质量的图像或视频。在NeRF的基础上,Zhang等人提出了NeRF++,它解决了潜在的形状-照明模糊问题。它认识到,虽然在训练集上训练的NeRF模型对场景的几何表示可能是不正确的,但它仍然可以在训练样本上生成准确的结果。然而,对于未见过的视图,不正确的形状可能会导致不完美的泛化。NeRF++解决了这一挑战,并解决了将NeRF应用于无界360°场景时的参数化问题。这种改进允许更好地捕捉大规模、无界的3D场景中的对象。虽然NeRF本身并没有固有的三维对象重建能力,但经过改造和变体,将几何约束整合到学习框架中,这些基于NeRF的方法同样能够端到端地重建物体或场景的3D模型。近年来对NeRF进行了大量研究,如DeRF、Mip-NeRF、Ha-NeRF和ManhattanNeRF等。面对大规模室外场景时,NeRF需要解决的主要挑战包括:
1)准确的相机姿态估计;
2)规范化光照条件以避免场景过曝;
3)处理开放式室外场景和动态物体;
4)在精度和计算效率之间取得平衡。
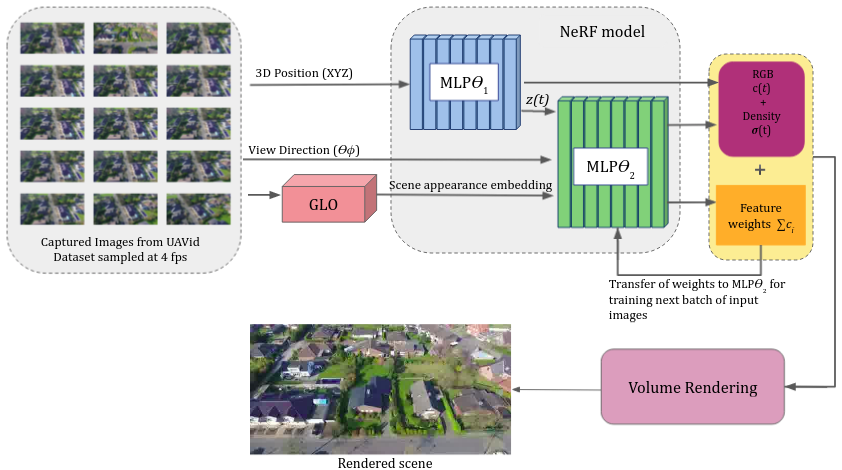
为了获得更准确的相机姿态,林等人在2021年提出了I-NeRF,该方法颠倒了NeRF的训练,通过使用预训练模型学习精确的相机姿态。Lin等人提出了BA-NeRF,即使输入带有噪声的相机位姿,也能通过计算转动相机的位姿和给定相机的位姿投影结果的差值,优化像素级别的损失,并在位置编码模块上引入了退火机制,随着训练过程深入逐步引入高频分量,获得了准确且稳定的重建结果;为了解决光照问题,Ricardo等人在2021年引入了两个新的编码层:外观嵌入层,用于建模场景的静态外观;以及瞬态嵌入层,用于建模瞬态因素和不确定性,如遮挡。通过学习这些嵌入,实现了一种用于调整场景光照的控制机制。Darius等人提出了ADOP(近似可微分的单像素点)渲染方法,该方法引入相机流程,对点云进行光栅化,然后将其输入到网络进行卷积,从而得到高动态范围的图像。然后他们利用传统的可微分图像处理技术,如光照补偿,并训练网络学习相应的权重,实现了精细的建模。建模开放场景及动态物体方面,NeRF在建模室外场景时,如果不对远景进行建模,会造成背景误差;但若考虑远景的建模,则由于尺度问题会造成前景的分辨率下降。由Zhang等人创建的NeRF++通过提出简化的反向球体参数化方法来解决这个问题,用于自由视点合成。场景空间被划分为两个体积:内部单位球代表前景和所有相机,外部体积由覆盖内部体积补充部分的反转球表示。内部体积包含前景和所有相机,而外部体积代表其余环境,并且两个部分都使用单独的NeRF模型进行渲染。在2021年,Julian等人提出了用于动态刚体对象的神经场景图(NSG)方法。它将背景视为根节点,将移动对象视为前景(相邻节点)。使用位姿和缩放因子之间的关系关联图的边,并沿边缘验证射线与对象的3D边界框之间的交点。如果存在交点,则射线会弯曲,并且在检测框的内外分别进行建模,以实现一致的前景-背景图像。Paul等人提出了基于转移学习的TransNeRF,在NeRF-W的基础上他们首先使用了一个称为GLO的生成对抗网络来学习和建模动态对象。然后,预训练的NeRF++被用作网络中的MLP模块,如图12所示。在2022年,Abhijit等人提出了Panoptic NeRF,它将动态3D场景分解为一系列前景和背景元素,并使用单独的NeRF模型表示每个前景元素。在大规模场景方面,Haithem等人提出了用于无人机场景的Mega-NeRF,它采用自上而下的二维网格方法将场景划分为多个网格。然后根据相机射线与场景的交点,将训练数据重新组织到每个网格中,使得可以为每个网格训练单独的NeRF模型。他们还引入了一种新的引导采样方法,只在对象表面附近采样点,提高了渲染速度。此外,通过使用椭球将场景划分为前景和背景区域,改进了NeRF++。利用相机高度测量,将射线终止于地面附近,以进一步精细化采样范围。Derksen等人提出了S-NeRF,这是将神经辐射场首次应用于多视角卫星图像重建3D模型。它直接建模了太阳直射光和局部光场,并学习了漫反射光作为太阳位置的函数。这种方法利用了卫星图像中的非相关效应,以生成在遮挡和光照条件变化下的逼真图像。在2022年,Xu等人提出了BungeeNeRF,它使用渐进学习逐渐完善大规模城市级3D模型的拟合,从远处开始逐渐捕获不同级别的细节。Rematas等人提出了Urban Radiance Fields,它利用来自LiDAR点云的信息指导NeRF重建街道级场景。Matthew等人提出了BlockNeRF,根据先前的地图信息将大场景划分为不同的块。他们创建了以地图块的投影点为中心的圆形块,并为每个块训练了单独的NeRF模型。通过结合多个NeRF模型的输出,他们获得了最佳结果。Mari等人通过引入有理多项式相机模型扩展了S-NeRF的工作,以提高网络对卫星相机中变化的阴影和瞬态对象的鲁棒性。Zhang等人在2023年提出了GP-NeRF,它引入了基于3D哈希网格特征和多分辨率平面特征的混合特征。他们分别提取了网格特征和平面特征,然后将它们组合为NeRF的输入以进行密度预测。平面特征也单独输入到颜色预测MLP网络中,提高了在大规模室外场景中NeRF的重建速度和准确性。Xu等人提出了Grid-NeRF,其结合特征网格提出一种双阶段训练的网格分支、NeRF分支的双分支结构。首先通过特征平面金字塔捕获场景信息,输入到浅层的MLP网络中即网格分支进行特征网格的学习,然后利用学习到的特征网格指导NeRF分支采样物体表面,将特征平面进行双线性插值来预测采样点的网格特征。最后将这些特征与位置编码一起输入到NeRF分支进行渲染。图13按时间顺序给出了一些现有的NeRF方法。
数据集与评价指标
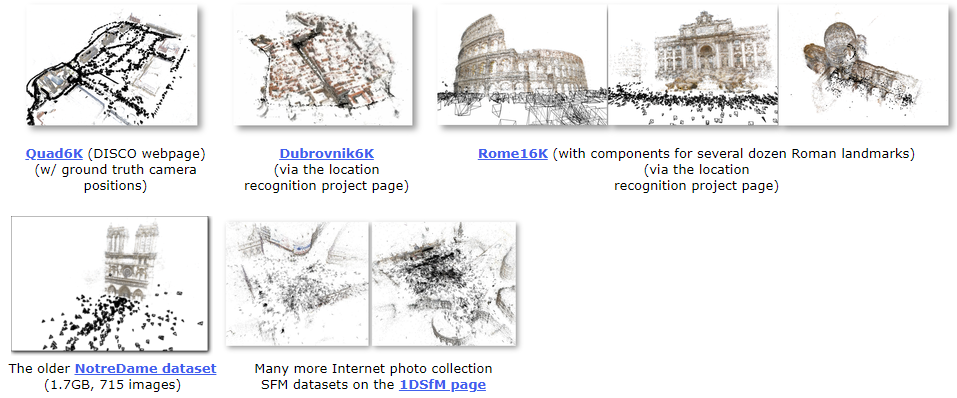
根据不同的目标任务,三维重建的数据集也可以分为不同的类别(表1)。本节提到的数据集常用于相应的任务,主要包括大规模场景。这些数据集包括高分辨率卫星图像、无人机拍摄的低空图像以及在城市环境中用手持相机拍摄的街景图像。它们提供了丰富的城市场景,涵盖了多样的建筑结构和土地覆盖类型,这对于大规模三维重建研究至关重要。此外,评估指标依赖于重建方法,本文将在本节详细介绍这些指标。BigSfM项目包含大量主要用于重建大规模室外场景的SfM数据集,该项目由康奈尔大学提出。这些数据集通常在互联网上收集,包括从Flickr和Google下载的多组城市地标图像,例如Quad 6K,Dubrovnik6K,Rome16K和OlderNotreDame,如图14所示。Quad6K:这个数据集包含康奈尔大学艺术广场的6514张图像;约5000张图像的地理信息是使用用户自己的iPhone 3G的GPS接收器记录的,而348张图像的地理信息是使用高精度GPS设备测量和记录的。Dubrovnik6K:这个数据集包含杜布罗夫尼克市的地标6844张图像,包括SIFT特征、SfM模型和对应于SIFT特征的查询图像。Rome16K:这个数据集包含罗马城市地标的16179张图像,包括SIFT特征、SfM模型和对应于SIFT特征的查询图像。OlderNotreDame:这个数据集包含715张巴黎圣母院的图像。SfM在未知相机姿态的情况下恢复稀疏的3D结构,对于重建的真实性很难获得地面真实,因此通常使用间接评估指标来反映重建质量。因此,SfM的评估指标包括注册图像数(Registered)、稀疏点云数(Points)、轨迹平均长度(Track)和点云重投影误差(Reprojection Error):1)Registered:注册图像越多,SfM重建中使用的信息越多,间接表明了点的准确重建,因为重建注册取决于中间过程点的准确性。2)Points:稀疏点云中的点越多,相机姿态和2D点之间的匹配程度越高,因为三角测量的准确性取决于以上两者。3)Track:每个3D点对应的2D点数。点轨迹越长,使用的信息越多,间接意味着准确性高。4)Reprojection Error:每个3D点的位置在投影到每个帧上的位置与实际检测到的2D点位置之间的平均距离误差。重投影误差越小,整体结构的准确性越高。4.2 立体匹配
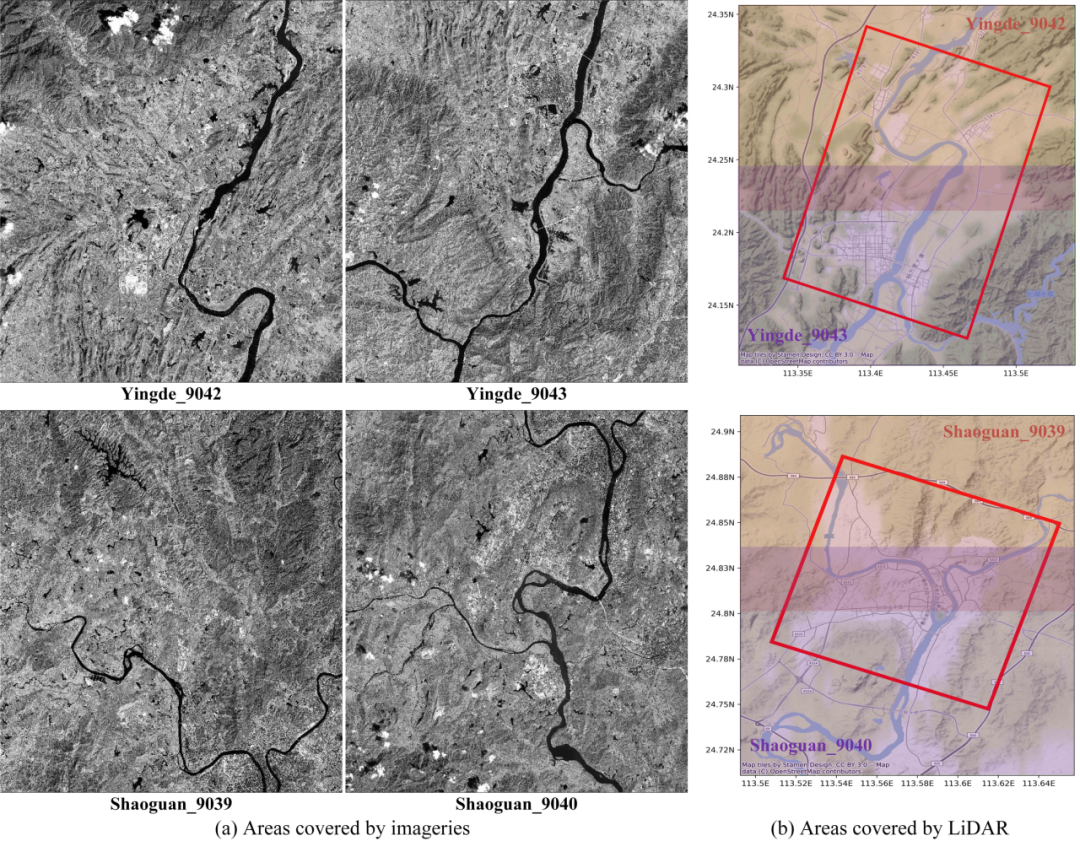
WHU-Stereo:该数据集基于GF-7卫星图像和机载激光雷达点云,如图15,包括中国六个城市的建筑和植被场景:韶关、昆明、英德、蕲春、武汉和衡阳。数据集中包含1757对具有密集视差的图像对。US3D :该数据集包含美国佛罗里达州杰克逊维尔市和内布拉斯加州奥马哈市两个城市场景,通过WorldView-3收集的26张杰克逊维尔和43张奥马哈的全色、可见光以及近红外图像构造了4292个图像对,均为密集视差(图16)。但其许多图像对是从同一地区捕获的,并且由于其图像是在不同时间的因此可能在土地覆盖上可能出现季节性外观差异。Satstereo:该数据集大部分使用了WorldView-3图像,一小部分来自WorldView-2。除了密集视差外,它还构建了掩码并为每幅图像提供了元数据。然而,与US3D一样,由于获取时间不同,地表覆盖物的外观存在季节性差异。立体匹配算法的主要评价标准为视差图精度和时间复杂度。视差图精度的评价指标有误匹配率,平均绝对误差和均方误差。误匹配率计算公式为:
平均误差计算公式为:
均方误差计算公式为:
4.3 多视角立体
ETH3D:该数据集包括用高清摄像机拍摄的图像和通过工业激光扫描仪获得的密集点云的真实数据,这两种模式的数据通过优化算法进行对齐。它涵盖了建筑物、自然景观、室内场景和工业场景(图17)。Tanks and Temples :该数据集使用高清摄像机拍摄真实场景的视频(图18)。每个场景的图像数量约为400张,且相机姿态未知。密集点云的真实数据是通过工业激光扫描仪获得的。图18 Tanks and Temples数据集示例
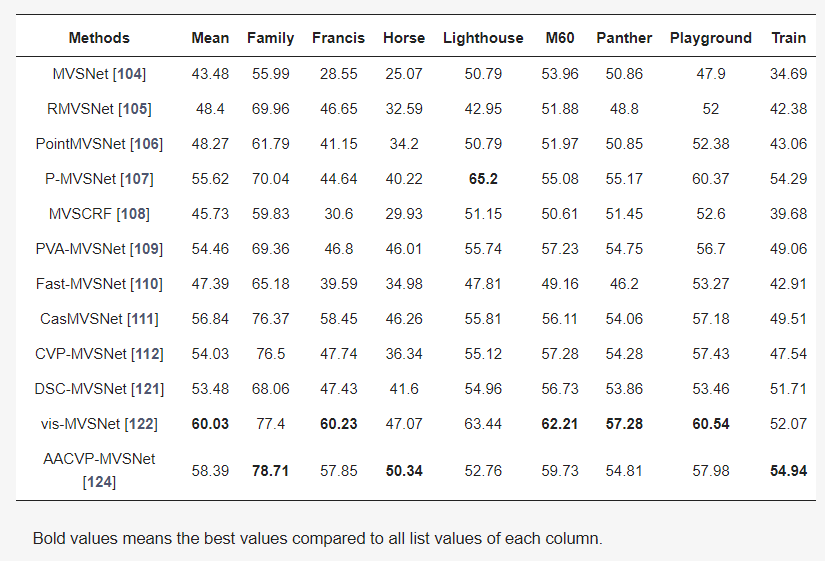
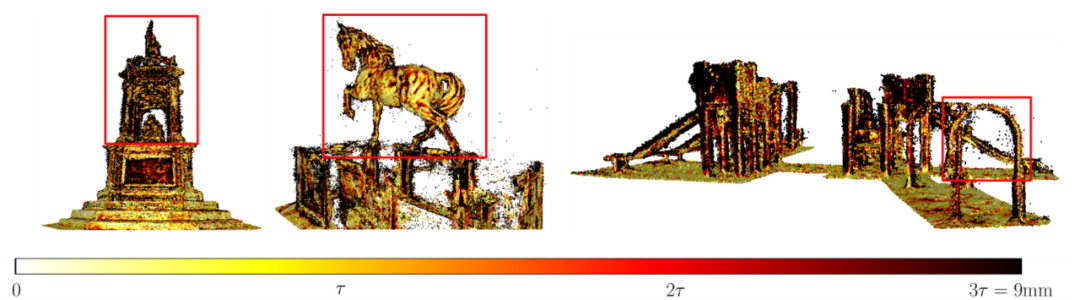
Sensefly:这是由轻型固定翼无人机公司Sensefly发布的户外场景数据集,包括学校、公园、城市等场景,数据类型包括RGB、多光谱、点云等(图19)。BlendedMVS:这是一个用于通用多视角立体网络的大规模MVS数据集。该数据集共包括17,000个MVS训练样本,涵盖了113个场景,包括建筑物、雕塑、小物体等。此外,还包括29个大型场景、52个小型场景和32个雕塑场景(图20)。多视角立体视觉的目的是在已知相机姿态的前提下估计稠密的三维结构。如果相机姿态未知,则需要首先使用运动结构(SfM)估计相机姿态。对稠密结构的评估通常基于使用激光雷达或深度摄像机获取的点云。一些对应的相机姿态是在收集过程中直接使用机器人臂获得的,例如在DTU中,而一些则是基于收集的深度估计的,例如在ETH3D或Tanks and Temples中。表2和图21、图22展示了典型MVSNet模型的一些评估和可视化结果。评估指标包括精度(Accuracy)、完整度(Completeness)以及平衡这两者的F1分数:1)精度:对于每个估计的三维点,在一定阈值内找到真实的三维点,最终匹配比率即为准确性。需要注意的是,由于点云的地面真实性本身是不完整的,因此在估计准确性时需要先估计地面真实性的不可观察部分,并在估算准确性时忽略它。2)完整度:对于每个真实的三维点,找到在一定阈值内的最近的估计的三维点,最终匹配比率即为完整性。3)F1分数:精度和完整度是一对trade-off的指标,因为可以让点布满整个空间来让完整度达到100%,也可以只保留非常少的绝对精确的点来得到很高的精度指标。因此最终评估的指标需要对二者进行融合。假设精度为p,完整度为r,则F1分数是它们的调和平均数,即2pr/(p+r)。表2 不同MVSNet模型在Tanks and Temples数据集上的F1分数图21 DSC-MVSNet在Tanks and Temples数据集上重建的点云模型误差可视化
图22 vis-MVSNet在Tanks and Temples数据集上重建的点云模型
4.4 神经辐射场
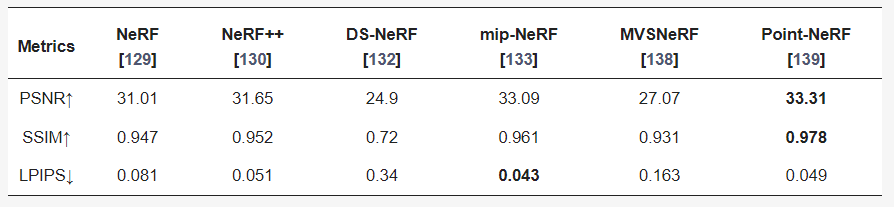
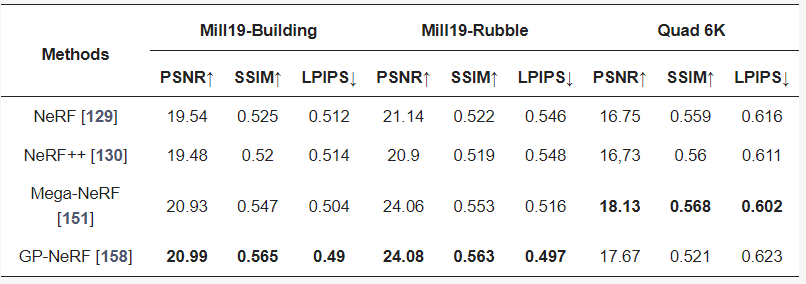
Mill 19:该数据集包含了在废弃工业园区附近拍摄的场景照片,这些照片是直接使用无人机拍摄的,分辨率为4608×3456。该数据集包含两个主要场景:Mill 19-Building和Mill 19-Rubble。Mill 19-Building包含1940张覆盖工业建筑周围500×250平方米区域的网格照片,Mill 19-Rubble包含1678张所有附近废墟的照片,如图23所示。NeRF的评估指标涉及计算机视觉中的图像生成任务,包括人工设计的相对简单的SSIM和PSNR,以及利用深度学习网络提取特征进行比较的LPIPS,此外,一些典型NeRF模型的评估和可视化结果显示在表3和4以及图24至图26中。SSIM(Structure Similarity Index Measure):结构相似性指数,用于量化两幅图像之间的结构相似性,仿照人类的视觉系统实现了结构相似性的有关理论,对图像的局部结构变化的感知敏感,从亮度、对比度以及结构量化图像的属性,用均值估计亮度,方差估计对比度,协方差估计结构相似程度。SSIM值的范围为0至1,越大代表图像越相似,如果两张图片完全一样时,SSIM值为1,公式如下:PSNR(Peak Signal to Noise Ratio):峰值信噪比,衡量图像信号最大值和背景噪声的图像质量参考值,用于评价图像质量。其值越大,图像失真越少。一般来说,PSNR高于40dB说明图像质量几乎与原图一样好;在30-40dB之间通常表示图像质量的失真损失在可接受范围内;在20-30dB之间说明图像质量比较差;PSNR低于20dB说明图像失真严重。给定大小为m x n的灰度图I和噪声图K,均方误差MSE(Mean Square Error)如下:LPIPS(Learned Perceptual Image Patch Similarity):学习感知图像块相似度,由Zhang等人提出,也称为“感知损失”(Perceptual Loss),用于度量两幅图像的区别。该度量标准学习生成图像到Ground Truth的反向映射,强制生成器学习从假图像中重构真实图像的反向映射,并优先处理它们之间的感知相似度。LPIPS 比传统方法更符合人类的感知情况。LPIPS的值越低表示两张图像越相似,反之,则差异越大。具体度量的计算就是计算真实样本和生成样本在模型内的特征差异,这个差异在每个通道内使用计算,最后是所有通道的加权平均,给定Ground Truth图像参照块x和含噪声图像失真块x0,感知相似度度量公式如下:表3 不同NeRF模型在synthetic NeRF基准数据集上的结果表4 不同NeRF模型在Mill 19 和Quad 6K数据集上的结果
图24 Point-NeRF在Tanks and Temples数据集上的结果
图25 Mega-NeRF和GP-NeRF在Mill19和Quad6K数据集上的可视化结果
图26 Sat-NeRF在其自有数据集上的DSM结果:(a) Scene608的2D可视化;(b) Scene608的3D可视化。
4.5 综合数据集
GL3D:这是一个为三维重建相关问题创建的大规模数据集,总共包含大量图像。大部分图像是通过无人机从多个尺度和角度拍摄的,具有较大的几何重叠,覆盖了543个场景,如城市、农村和风景名胜区。每个场景的数据点包含完整的图像序列、几何标签和重建结果。除了大场景外,GL3D还包括小物体的重建,以丰富数据的多样性。对于SfM任务,GL3D提供去畸变后的图像和相机参数;对于MVS任务,GL3D基于Blended MVS数据集提供渲染融合图和不同视角的深度图。UrbanScene3D:这是一个用于感知和重建城市场景的大规模户外数据集,总共包含超过128,000张高分辨率图像,包括10个虚拟场景和6个真实场景。面积为136平方公里,其中包括三个覆盖超过24平方公里的大规模城市场景和两个覆盖超过一平方公里的完整的真实场景。为了评估真实场景重建模型的准确性和完整性,UrbanScene3D使用带有GPS定位设备的激光雷达扫描仪对场景中的整个建筑进行扫描,以获取高精度的场景扫描点云。图28 UrbanScene3D数据集示例:10个虚拟场景(上),6个真实场景(下)

结果与讨论
随着深度学习技术的进步,基于图像的三维重建任务已经从静态室内场景发展到了大规模室外环境。然而,仍然存在一些挑战:1)重建具有重复纹理或弱纹理的区域,如湖泊和墙壁,往往会导致重建失败或重建模型中出现孔洞,物体细节的重建精度仍然不足。2)构建大规模室外场景的数据集对于三维重建技术的发展至关重要。目前专门用于大规模室外场景的数据集,特别是城市级的真实场景数据集仍然稀缺。3)现有的大规模场景三维重建方法耗时长,无法实现实时重建。尽管在训练过程中采用了场景分区和利用计算集群来加快过程,这些方法仍然未能达到工业应用所需的效率水平。4)室外场景包含大量动态物体,这些物体会显著影响图像特征匹配和相机姿态估计等过程,导致重建模型的准确性下降。鉴于上述挑战和基于图像的三维重建关键技术的现状,有几个重要领域值得关注:1)解决弱纹理区域的问题:以往的研究集中在室内场景中结合语义信息来识别和约束弱纹理区域,从而提高重建精度。然而,在大规模室外场景的重建中,不仅要为弱纹理区域,还要为室外场景中的常见物体(如建筑物和动态物体)整合语义信息,这种语义信息的整合是一个重要的研究方向。2)构建大规模真实世界数据集:使用卫星、飞机、无人机等数据构建城市场景的综合数据集至关重要。此外,需要更鲁棒的三维重建评估算法。目前的指标大多借鉴自二维图像领域,可能无法完全反映三维重建的复杂性。未来的研究应集中于结合全局和局部、视觉和几何精度的评估算法,以提供更全面的三维重建结果评估。3)实时重建:最近的研究探索了诸如联邦学习的方法,通过让单个无人机使用自身数据进行训练以提高效率。因此,结合联邦学习和场景分区等技术,利用大规模场景数据训练轻量级网络模型将是实现室外场景实时三维重建的关键且十分具有挑战性。这一研究对智慧城市和搜救任务等领域的应用具有重要意义。4)图像与其他传感器的融合:另一个有价值的方向是探索将图像与其他传感器数据(如LiDAR数据)结合的高效融合技术,以解决在室外场景重建中涉及的复杂问题,包括非传统建筑、植被和遮挡等。通过有效整合多种传感器模式,可以显著提高重建的准确性。这可以为不规则结构的平面度提供显著改进,并有助于恢复密集植被场景中的地面点。
总结
三维重建是计算机视觉领域的基础任务,研究大规模室外场景重建的方法具有重要意义。本文分析了运动恢复、立体匹配、多视图立体视觉和神经辐射场等传统方法和基于深度学习的方法,介绍了本领域数据集以及常用的质量评估指标,对每种方法的核心技术和应用进展进行了详细讨论。此外,本文还讨论了弱纹理或重复纹理重建质量较差、大规模室外场景专用数据集缺乏及大数据量重建时间漫长等问题。突破相关关键技术,解决这些问题是三维重建领域未来研究和发展的方向。
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----
【说明】欢迎企业和个人洽谈合作,投稿发文。欢迎联系我们诚招运营合伙人 ,对新媒体感兴趣,对光电产业和行业感兴趣。非常有意者通过以下方式联我们!条件待遇面谈联系邮箱:uestcwxd@126.com
QQ:493826566