


存内计算(Compute-in-Memory/Computing-in-memory,CIM)以在现代数据密集型工作负载应用程序中降低数据移动能量和延迟成本。DAC2024录用CIM相关文章16篇,主要分布在两大SESSION中,主要介绍了CIM在架构、电路、器件、设计方法的最新进展。
SESSION:MEMORIES HAVE A MIND OF THEIR OWN共录用了6篇文章,有4篇来自中国大陆高校;第一篇论文介绍了一种用于扩散模型中灵活数据重用的三齿轮异构数字CIM;第二篇论文提出了一种基于hessian迹的量化和近似计算的细粒度数字CIM;第三篇论文提出了一个混合域SRAM CIM宏,通过数模计算协同来协调精度和能效;第四篇和第五篇将RRAM和IGZO应用于CIM中;第六篇论文提出了一种替换设计,允许对内存访问和主机访问中的处理进行细粒度交错。
下面我们来看看六篇文章的核心论点:
Paper《AIG-CIM: A Scalable Chiplet Module with Tri-Gear Heterogeneous Compute-in-Memory for Diffusion Acceleration》在人工智能生成内容领域,扩散模型以其卓越的图像生成能力受到了广泛关注。然而,由于其独特的模型架构和计算需求,扩散模型在硬件部署方面面临着巨大挑战。针对这一问题,北京大学的黄如院士-叶乐教授团队提出了一种名为AIG-CIM的硬件加速器。该加速器采用三档异构数字存算一体技术,以满足扩散模型灵活的数据重用需求。AIG-CIM框架提供了一种从计算电路级到多芯片模块系统级的大型生成模型协作设计方法,该工作在22nm工艺下进行评估,在多个扩散推理任务中,可扩展的AIG-CIM芯粒相比RTX 3090 GPU实现了21.3倍的延迟减少、最高231.2倍的吞吐量提升以及1000倍以上的能效提升。
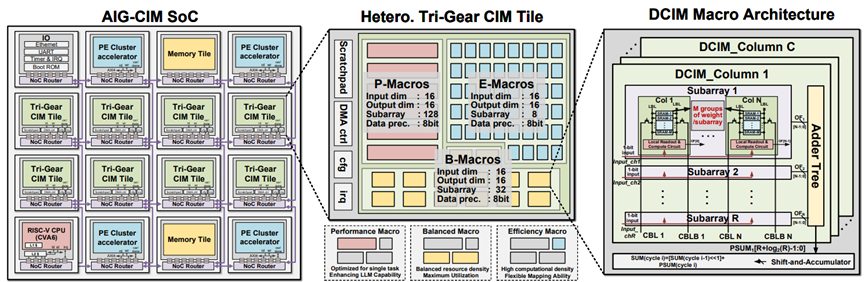
图1. AIG-CIM:从数字存算单元到SoC

图2. AIG-CIM SoC 实现和CIM tile 版图
Paper《FDCA: Fine-grained Digital-CIM based CNN Accelerator with Hybrid Quantization and Weight-Stationary Dataflow》面向卷积神经网络加速器对高能效的需求,设计并实现了一款基于数字存内计算的细粒度卷积神经网络加速器FDCA,通过混合位宽量化和权重驻留数据流优化,实现了能效与计算精度的平衡,突破了传统数字存内计算架构中寄生效应带来的能效瓶颈。团队提出了基于海森迹的混合位宽量化方案和基于笛卡尔遗传算法的近似移位累加技术,实现了基于计算负载与存储带宽平衡的混合位宽量化,通过近似加法树的自适应设计来补偿存算电路引入的计算误差,大幅提升硬件能效并有效降低计算精度损失。同时,优化的权重驻留数据流提高了存内计算单元的利用率,并减少了额外的片上存储需求。该工作在28nm下进行评估,实验结果表明在CIFAR100数据集上运行VGG16和ResNet50网络时,该加速器能效分别达到17.1TOPS/W和18.79TOPS/W,且网络识别精度仅下降了0.71%和0.98%。此外,优化后的权重驻留数据流在处理AlexNet、VGG16、ResNet50网络推理运算时,将硬件利用率分别提升了36%、5.5%、73.6%。东南大学集成电路学院刘波副教授、蔡浩教授为论文一作和通讯作者。

图3. 本文所使用的细粒度数字存内计算模型与提出的FDCA架构

图4. (a)混合位宽量化模型在ResNet50和VGG16上的实现; (b) 面向细粒度数字存算优化的权重驻留数据流
Paper《Addition is Most You Need: Efficient Floating-Point SRAM Compute-in-Memory by Harnessing Mantissa Addition》存内计算在高效加速机器学习任务方面具有巨大潜力。在众多存储器件中,SRAM因其在数字领域的卓越可靠性和优秀的可扩展性而脱颖而出。近年来,加速浮点DNN(深度神经网络)的SRAM CIM引起了越来越多的关注,因为它们在DNN训练和高精度推理中具有关键作用。乔治华盛顿大学和美国东北大学的研究团队提出了一种将传统的浮点尾数乘法分解为尾数子加法和尾数子乘法两部分的轻量化方法。针对尾数子加法和尾数子乘法的不同计算特性,开发了一种新颖的混合域SRAM CIM宏单元,在数字域中准确处理尾数子加法,同时使用模拟计算提高尾数子乘法的能效。通过MLPerf基准测试,研究团队的实验结果显示,与完全数字化设计基准相比,推理能效平均提高了3倍至3.6倍,训练能效则提升了2.5倍至3.1倍,且没有任何精度损失,展示了其加速浮点深度神经网络的巨大潜力。
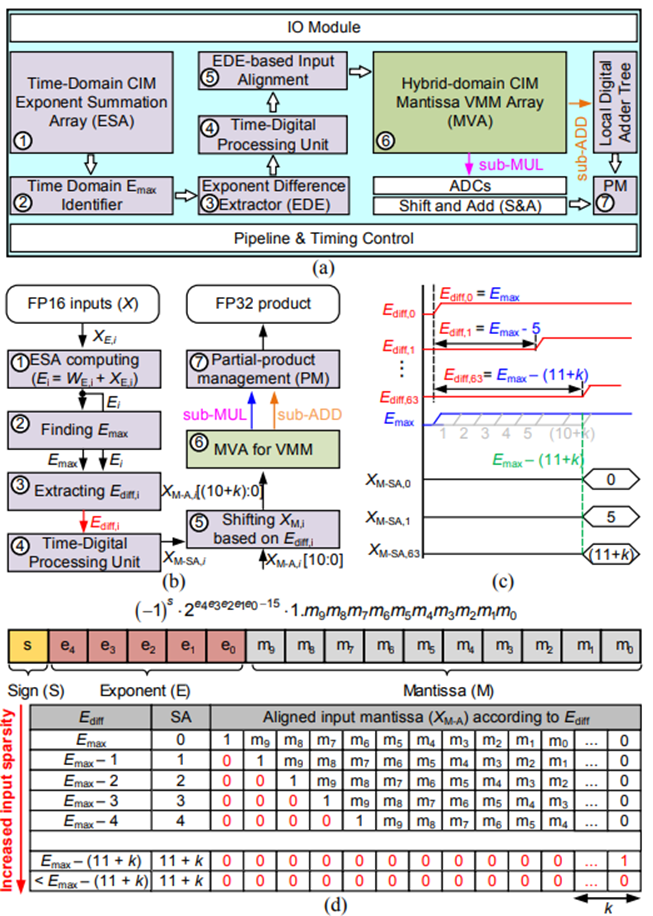
图5. (a) 所提出的浮点SRAM存算一体宏的结构概览 (b) 计算流程。 (c) 在时间域中提取指数差的示意图。 (d) 基于指数差的尾数移位示意图(以FP16为例)

图6. HD-MVA的结构 (b) 用于局部计算单元的基本电路,如模拟乘法单元和数字与门及或门 (c) 实现所提出的混合计算机制的局部计算单元
Paper《RWriC: A Dynamic Writing Scheme for Variation Compensation for RRAM-based In-Memory Computing》香港科技大学和南方科技大学合作研制了一款面向RRAM存内计算的动态写入方案RWriC,用于补偿RRAM中的设备间差异和周期间差异,显著提升了神经网络推理的准确性。为了在有限的硬件开销下,解决传统RRAM写入过程中由于差异导致的推理准确度下降问题,创新性地融合了编程目标移位和缩放技术,使得高显著性单元和低显著性单元可以协同工作,有效补偿编程误差,最小化整体误差累积。团队提出的基于编程目标移位和缩放的动态写入技术,利用高显著性单元的编程目标动态调整,使低显著性单元能够在编程范围内进行补偿;通过缩放技术扩展低显著性单元的补偿范围,防止编程目标超出设备的可编程范围。实验结果显示,通过移位和缩放技术,RWriC在面对不同的神经网络模型和数据集时均表现出了显著的鲁棒性和准确性提升。在18%的设备差异下,ResNet50在CIFAR-10数据集上的推理准确性仅下降0.9%,相比传统写入方案在差异鲁棒性上提高了5 - 11倍。此外,RWriC的硬件开销很小,不需要额外的离线训练,确保了其实用性和高效性。

图7. 动态写入方案流程图与示例

图8. 不同模型的推理精度
中国科学院微电子研究所的李泠、岳金山团队在《IG-CRM: Area/Energy-Efficient IGZO-Based Circuits and Architecture Design for Reconfigurable CIM/CAM Applications》提出IG-CRM架构,一种基于IGZO(Indium-Gallium-ZineOxide,氧化铟镓锌)晶体管的可重构CIM(存内计算)和CAM(内容可寻址存储器)架构。该架构旨在解决现有CIM/CAM电路中的低密度和耐久性限制问题,利用IGZO晶体管的超低漏电流和高密度特性,实现了更高效的面积和能量利用率。他们团队提出一种基于IGZO的3T0C/4T0C单元设计,实现CIM和CAM功能,并与CMOS电压兼容。在电路层面,利用BEOL IGZO 晶体管减少数字加法树面积。在架构层面,提出可重构CIM/CAM架构,支持不同AI工作负载的高效利用。实验结果表明,IG-CRM与传统SRAM非可重构CIM/CAM基准相比,面积节省达8.09倍,速度提升最高可达1530倍,能效提高最高可达16300倍,展现出显著的性能优势。
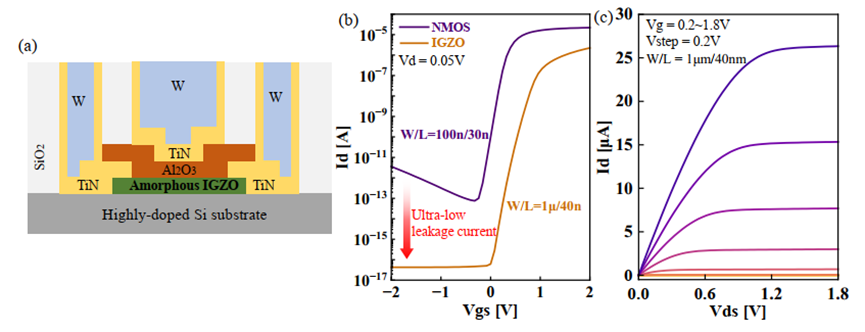
图9. (a) IGZO的横截面。(b) 与NMOS相比的传输曲线和漏电流。(c) IGZO的IV曲线

图10. 提出的可重构IG-CRM架构
韩国的Sung-Joon Jang 团队在《HAIL-DIMM: Host Access Interleaved with Near-Data Processing on DIMM-based Memory System》中介绍了HAIL-DIMM,一种基于LRDIMM的NDP(Near-Data Processing, 近数据处理)架构,旨在减少主机与存储之间的数据移动开销,同时确保系统公平性。HAIL-DIMM通过使用现有内存控制器的BANK 交叉存取功能,提出了一种支持细粒度NDP操作的架构,实现了NDP与主机访问的无缝交叉存取,并可以直接替换现有的主内存模块。此外,他们也提出了一种基于DMA的NDP卸载技术,用于细粒度NDP操作。团队在FPGA平台上实现了所提出的NDP架构原型,进行了可行性和性能评估。评估结果显示,与基准系统相比,HAIL-DIMM在内存受限负载中将内存延迟加速了高达2.19倍,同时降低了45.4%的数据移动能耗。

图11. 传统的NDP架构

图12. HALF-DIMM

图13. 在 HAIL-DIMM 上执行 NDP(近数据处理)操作的执行流程。此示例对数据内存和四个 DRAM 存储BANK中的数据执行逐元素乘法操作
致 谢
本文得到东南大学集成电路学院韦庆文和邹子涵同学的大力支持,再此深表感谢!

