


----追光逐电 光赢未来----


这篇论文全面回顾了YOLO(You Only Look Once)目标检测算法的发展历程,重点关注了YOLOv5、YOLOv8和YOLOv10。 作者分析了这些版本在架构改进、性能提升以及适用于边缘部署方面的进展。YOLOv5引入了重要的创新,如CSPDarknet Backbone 网和Mosaic增强,平衡了速度和精度。YOLOv8在此基础上加强了特征提取和 Anchor-Free 点检测,提高了灵活性和性能。 YOLOv10代表了向前的一大步,无需NMS训练、空间通道解耦下采样和大核卷积,在减少计算开销的同时取得了最先进的性能。 作者的发现突出了在准确度、效率和实时性能方面的逐步提升,特别是强调它们在资源受限环境中的应用性。 这篇综述提供了模型复杂度与检测精度之间权衡的见解,为选择最适合特定边缘计算应用的YOLO版本提供了指导。 论文链接:https://arxiv.org/pdf/2407.02988

最小且最快的模型,输入大小为640像素。
达到COCO AP(val)28.0%和AP(val)50 45.7%。
CPU延迟为45毫秒。
包含190万个参数,需要45亿FLOPs。
比YOLOv5n稍大且稍慢。
达到COCO AP(val)37.4%和AP(val)50 56.8%。
CPU延迟为98毫秒。
包含720万个参数,需要165亿FLOPs。* 较大的模型,性能有所提升。
达到COCO AP(val)49.0%和AP(val)50 67.3%。
CPU延迟为430毫秒。
包含4650万个参数,需要1091亿FLOPs。
YOLOv5系列中最大且最复杂的模型。
在COCO上达到50.7%的AP(验证)和68.9%的AP (val) 50。
CPU延迟为766毫秒。
包含8670万个参数,需要2057亿FLOPs。

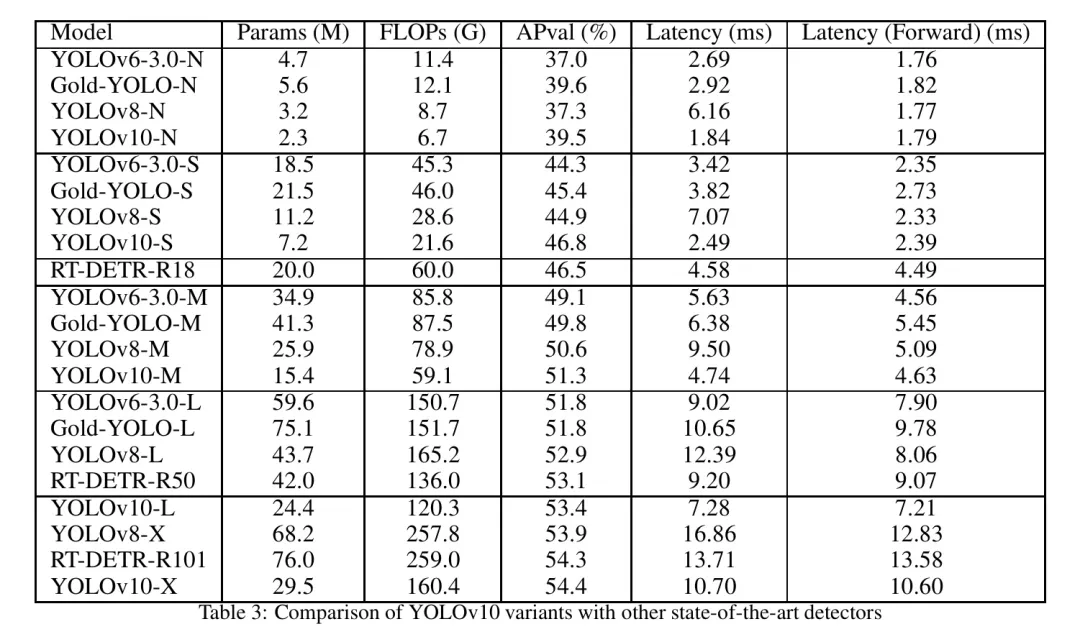
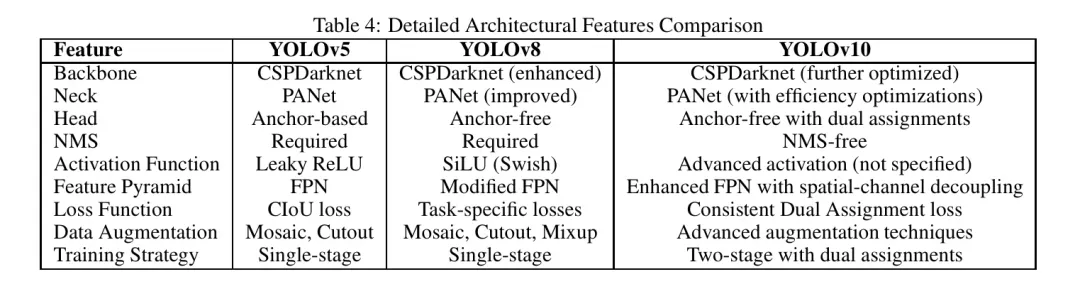
改进的小目标检测:与之前版本相比,YOLOv10在小目标检测方面显示出更强的能力。这种改进对于监控和医学成像等经常需要小目标检测的应用至关重要。
减少误报:该模型展示了更低的误预测率,提高了整体检测的可靠性。通过更好的特征提取和更准确的分类,实现了误报的减少。
置信度得分提升:YOLOv10对其预测的置信度得分更高,表明检测更可靠。更高的置信度得分意味着模型对其预测更加确定,这对于准确性至关重要的应用非常重要。
可伸缩性:YOLOv10提供了多种模型大小(n, s, m, l, x),以满足不同的计算需求和用例。这种可伸缩性确保了模型可以适应广泛的应用,从资源受限的边缘设备到高性能服务器。
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


