
「自动驾驶是人工智能技术最大的应用之一」,这句话经常出现在我们的内容里,其本意是想和读者分享,不管是将来的真无人驾驶,还是现在的辅助驾驶,它都具有技术高度复杂的特征。
这也让头部厂商之间的能力,会在一些具体功能或者一些特定场景下出现交替领先的现象。所以如果你愿意长期关注这个领域,你可以尝试去看你所关注的公司对智驾产品和技术的理解上。
这是「端端的自动驾驶」系列的第二篇内容,因为理想汽车的夏季发布会,所以原本是讲另一个技术的稿子临时改成了理想汽车的。
所以今天聊聊理想汽车的自动驾驶技术。
几乎一夜之间,端到端自动驾驶突然成为众多团队争相抢夺的标签。
这是又一次猛烈的行业技术变革,没有一个厂商不想跟上这波浪潮。
细节是乐于表达的王乃岩,在知乎上曾多次抨击端到端自动驾驶。
但是与 2021 年 BEV + Transformer 的切换不一样的是,Tesla 自动驾驶团队在 AI Day 上已经用非常清晰的路线图和技术架构图告诉了所有后来者,按照这种方式走,这条路是可行的。
众多 Tesla 的跟随者,开始写命题作文,用千篇一律的方式展示自己的 BEV 架构,架构里都是 Tesla 的影子。
可是,在 Tesla 示范了端到端可行之后,却迟迟不公开架构,可能是架构并未如马斯克所说如此先进,也可能是表现暂时不如人意,乃至于 2024 年 CVPR 特斯拉竟然破天荒缺席了。
没有了特斯拉的引路,端到端有没有自己开路的机会?
端到端这件事情,就像本身被诟病神经网络黑盒一样,实现的路径也成为了黑盒。
这是一次开放式作文题目就三个字:端到端。
要求:题材不限、长度不限。
这道题如何作答?尤其是答题需要付出极大资源支持下,各大自动驾驶团队开始踌躇不前,虽然对外宣称端到端架构,但是如何实现却三缄其口,需要哪些投入也都讳莫如深,观众开始纷纷质疑。
但是今天理想夏季发布会,展现出来的内容详细又合理,让我不得不相信,整个团队思考得非常清楚,而且已经找到了一条关键路径。
这里我不想再次重复发布会的内容。
我想从发布会里提到的内容出发,来试图去理解理想汽车是否真的拥有完成端到端系统量产的所有能力。
同时来证明这句话:想要完成一个自动驾驶系统,那么设计算法架构,获取需要的数据用来训练,测试和验证的手段缺一不可。
众多车企不做端到端是因为没有公开的端到端架构吗?
其实并不是,CVPR 2023 的 Best Paper UniAD 便早早公开了架构及源码,以及在著名自动驾驶数据集 nuscenes 的训练方式,甚至也有不少团队基于此在进行端到端算法的开发。
但是显然 UniAD 粗暴地将原有的模块使用神经网络连接的方式依然保有了原有技术栈的影子,这是取巧的做法。
这样可以很方便地进行每个模块的设计,甚至也可以进行单个模块的训练。
显然这不是终局,这些残留的一个个模块,是旧技术栈在新浪潮切换时留下的影子。
不久之后 ECCV(计算机视觉顶级会议之一)VAD 发布,同样开源。
架构进一步简化,从模块上来看,就进一步去除了占据网格(OCC)模块,而使用了更多关于碰撞和路线的约束,降低了计算开销,但是表现更好。
这似乎能够证明,进一步简化模块可以带来更好的效果。
到这里,就基本上是目前端到端能获取到的效果比较好的公开代码了,也有不少团队就基于这些内容在进行开发。
一个已经在学术界被验证过的架构,工业界进行工程优化,最后推向市场。对于一个未知的内容,这是比较稳妥的做法。
但是理想汽车自动驾驶团队并没有。
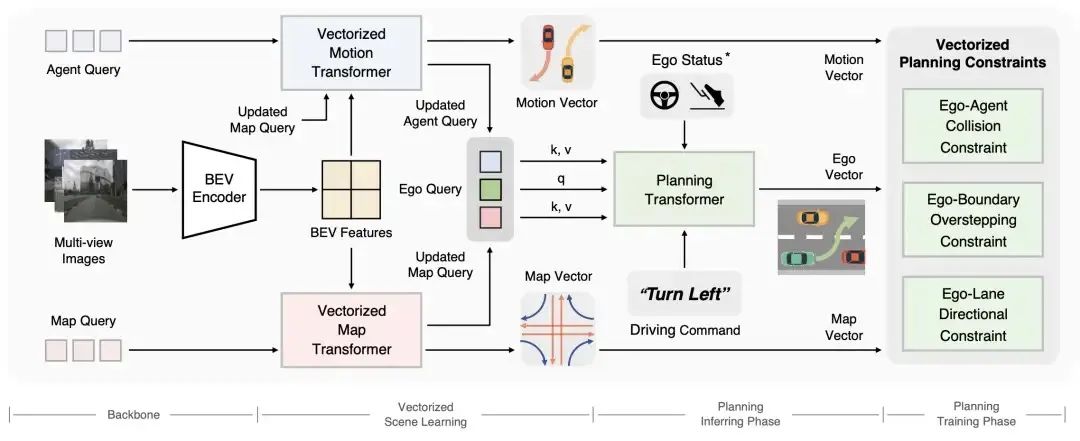
或许是在自己尝试分段式端到端过后效果不佳,又或许是看到了端到端黑盒简化趋势之后,决定跳过这一步,直接开始做端到端完整模型,输入传感器信息和导航信息,直接从解码器中获得轨迹信息。
而障碍物、道路结构和 OCC 的结果,都不再是轨迹信息的输入,更多是为了 EID 显示。
这比 UniAD 和 VAD 的思路都要进一步,也更加冒险,几乎可以称得上一次豪赌。
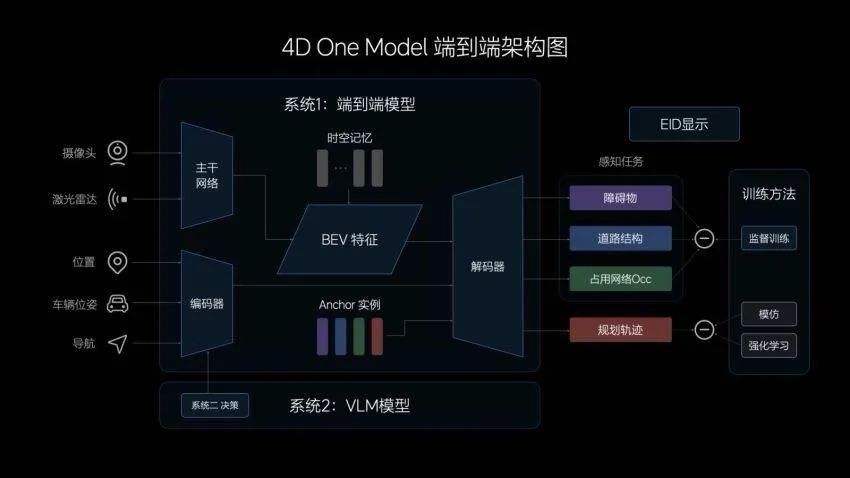
不仅如此,为了提升整个系统对世界的理解能力,理想汽车与清华大学共同研发了 DriveVLM 系统,将大模型的视频语言模型与端到端系统结合,组成一个完整的系统。
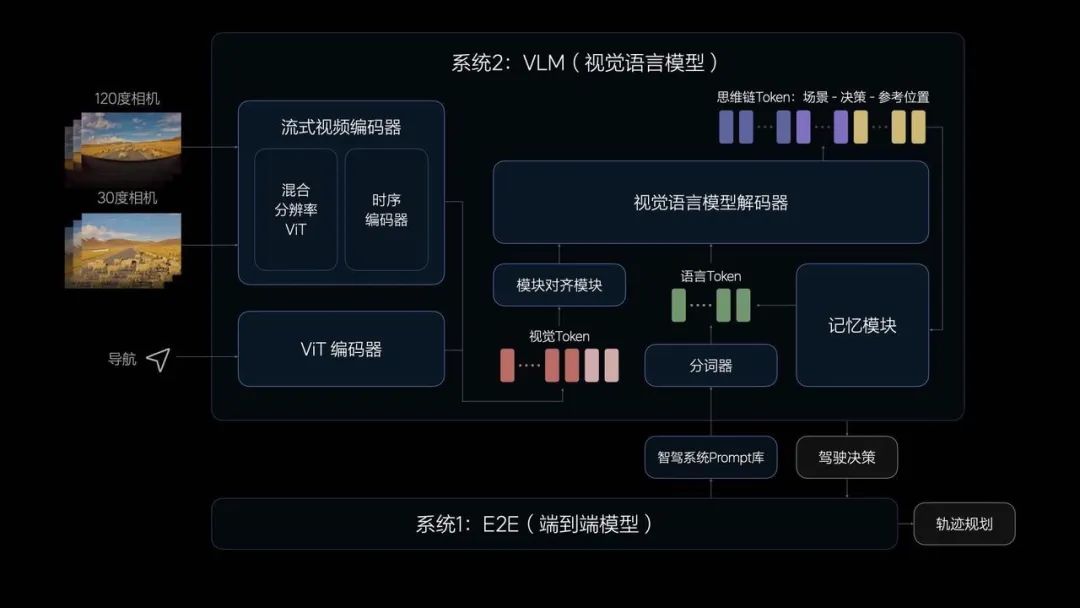
ChatGPT 在经过了众多语言和视频数据的训练之后,拥有了惊人的对世界的理解能力,理想汽车的 DriveVLM 正是利用了从非驾驶场景中获取的能力,迁移到自动驾驶场景中。
那么这种迁移是如何实现的?
这里有一个 Token 的概念,简单来说,神经网络理解世界都是将输入的信息进行压缩成一些数字,不论是视觉或者语言,所以虽然输入的信息不一致,但是对于神经网络的理解,都是一些数字,这些数字包含了所有需要的信息。
曾经有一本畅销书《天才在左,疯子在右》 里面提到一个故事,如果我们有足够高的制造工艺,将一本书完全编码成一个数字,然后将整个数字转换成距离,在一块石头的这个位置上刻上一个点,那么这个点就包含了这本书中的所有信息。
DriveVLM 的处理方式也是如此,语言和视频被处理成了相似的数字提供给神经网络进一步处理。
语言和视频最后的表现方式会基本接近,所以也就有了迁移的可能。
整个系统由两个子系统组成,一个是端到端网络负责快速响应,能力来自于常规驾驶任务数据,另一个是 VLM 负责思考,能力来自于语言和视频的数据迁移。
这个理论来源来自诺贝尔经济学奖《思考,快与慢》中对认知心理学的阐述,直觉决策和思维推理相互配合,成为人类世界认知、理解能力和做出决策的基础。
这也是在端到端自动驾驶领域,国内提出的第一套全新的路径。
很难想象理想团队在找到这条路之前赌了多少不一样的方向,也很难想象去将一个没有人验证过的系统做到基本可以量产上车付出了多少资源。
那么对于一个全新的系统,理想汽车 AD 团队是怎么训练并且量产的,换句话说,理想汽车 AD 团队是怎么验证这条路可行的?
端到端非常难以训练,这是业内共识。
一个巨大的网络,拥有巨大的参数量,但是监督却只有轨迹结果。
这相当于跟一个幼儿园小朋友说,现在的任务是研发火箭。
他会疑惑地问老师,那怎么做呢?
老师说:你可以先做,我可以告诉你做的对不对,但是答案只有是或者否。
这有可能吗?
当我们把时间维度拉长,假设有足够的时间和无限的精力,并且这个老师确实每次给出的答案都是正确的,那么这并不是不可以完成的任务。
因为谁也不能保证,从这个幼儿园里不会成长出一个马斯克,尤其是拥有绝对正确的指导下。
回到端到端自动驾驶,我们有了整个系统架构,就相当于有了一个幼儿园小朋友。
如何设计一个全知的指导任务?
那就要五星驾驶员。
理想汽车拥有目前新势力最大的智能量产车队,足以提供足够的数据,但是并不是每辆车的数据都可以被使用。
因为本质上端到端自动驾驶的训练就是模仿学习的概念,即从数据轨迹中学习驾驶任务。
那么驾驶员的驾驶习惯就至关重要了,毕竟谁也不想坐一个新手司机开的车,所以团队设计了一个司机评分系统,挑选出足够好的驾驶员,只选用这些驾驶员的数据。
这就相当于一个全知的指导任务,我们只需要等待足够好的结果出来。
那么会有足够的精力等待吗?其实也不需要等待,只要算力足够多,就可以用算力换时间。
理想汽车的算力储备高达「」 ,足以压缩时间,这也是为什么英伟达扶摇直上九万里的原因,本质上,现有的人工智能技术框架,是建立在对数据的获取、处理框架之上的,而处理数据就需要硬件。
同时要提醒读者一个概念,「端到端」只是一个解题方法或思路,端到端并不是答案,全球的人工智能科学家、工程师其实都在解一道数学应用题。
只是实现高阶的自动驾驶目前来看端到端具有很大的可行性和潜力,工程界依然不排除有其他方案可以比端到端更好用。
训练数据找到了,那么如何验证整个系统是可以完成任务的?
整个端到端自动驾驶去掉了模块化概念之后,整个测试和验证手段发生了极大的变化。这也是各大团队犹豫不决的原因,没有对应的验证手段,谁也不敢盲目切换。
因为原来模块化的算法,可以单独进行验证,例如感知模块可以验证出来的目标数据对不对,规划模块可以验证当输入目标级数据之后,出来的轨迹对不对。
而端到端的的系统,输入的只有传感器信息,但是输出直接到了轨迹信息。大部分团队的验证手段都失效了,因为不是按照端到端进行开发的。
验证手段的迭代和适配,难度其实并不比设计一个端到端算法简单。
Street Gaussain。
这是浙江大学与理想汽车的合作,如果说 DriveVLM 是一种全新的算法架构,那么 Street Gaussian 就是对应端到端的全新的验证方式。
这里引入了一个全新的概念,叫做:Gaussain Splatting(高斯泼溅)。
高斯泼溅是一个计算机图形学概念,它通过对每个像素应用一个高斯分布的权重,对相邻像素进行混合,从而产生柔和的模糊效果。
这可能不是很好理解,但是我们如果将整个世界都理解成透明度不一的一些点,我们用眼睛观看的时候,看到的每一个点,其实都是由周围各个点通过权重组成的。
由此可以用来做世界的重建,将图片中的信息保存在这些点中。

重建完有什么用?
答案是:可以用来做自动驾驶的验证,或者说可以用于端到端自动驾驶系统的验证。
我们都知道端到端系统被广为诟病的黑盒,在真正发出轨迹指令前,我们无法验证在里面发生了什么,这种未经验证的系统是无法实车测试的。
所以就对虚拟验证提出了更高的要求。
而一些常规的验证方法,例如纯虚拟的验证方案,例如基于虚幻引擎的验证手段,需要大量人力来构建场景,并且还要保证视觉效果,难度几乎不亚于 3A 大作。

而端到端系统又要求非常多样的场景,所以必须有一个基于真实数据,可以交互的场景验证方式出现。
Gaussain Splatting 就提供了一个非常好的 3D 重建手段,但是原生的 GaussainSplatting 缺陷较多,对动目标重建能力较弱,在此基础上理想汽车与浙江大学共同开发 Street Gaussian 将动态目标和静态目标进行分离,把新技术基本推向自己的量产验证技术栈。
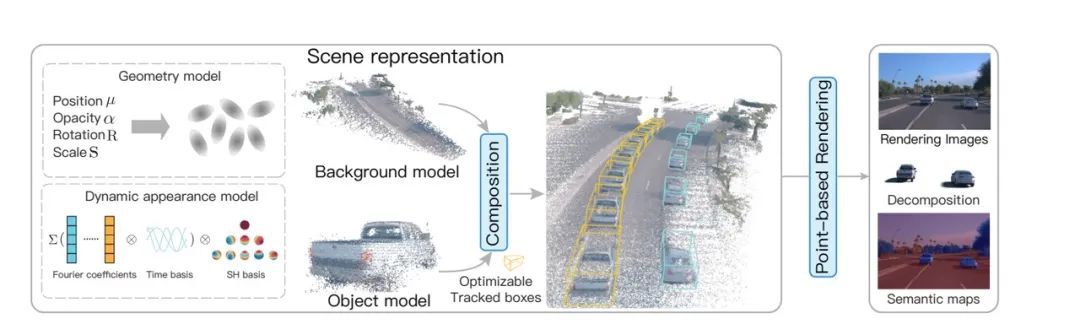
这也是一次豪赌,2023 年 NeRF(另一种基于神经网络的 3D 重建技术,推理速度较慢)还大行其道,Tesla 在 2022 年也宣布自己使用 NeRF 进行重建并且验证。
而 2024 年理想汽车就能将一个新的技术推向自己的量产技术栈,完成了整体切换,这种难度可想而知。
到此为止,从架构到数据再到验证,是一个完整清晰的端到端自动驾驶路径,而这也是唯一一个讲端到端如何做、怎么做,讲的清楚的团队。
「理想汽车这套架构如果顺利上车,那应该在架构上会领先至少 5 个月。」
在行业里「端到端 + 场景理解」,确实是 2025 年主要的工作方向,如果理想上车成功,它可能会跳过侠义端到端。
大家一直在做的其实是,理解神经网络,因为只有理解后,才能知道怎么做到更好。就好比人,我们都知道读书、看科普视频、听大佬演讲、做黄冈试卷,可以提升只是和做题能力。
这个本质就是数据喂养学习的过程,可是即使大家看的学习资料完全一样,但有人清华大学,有人青花职业技术学校。
在生命科学里,我们依然不能理解,为什么有小孩更聪明,是吃了鸡蛋,还是鹅蛋导致的。
到自动驾驶技术上则是,大家依然要用多模态的语言模型去增加场景理解能力,从而提升系统的可解释性。
当然,这是一个难度巨大的工程,恭喜理想汽车,他们做的非常好。
写在最后
我们可能都低估了理想汽车在端到端自动驾驶的投入,不论是架构,还是数据的挖掘,验证手段,都有了当年特斯拉 AI Day 的影子,每一个模块都有了足够的先进性。
而这种技术的先进性是国内团队不擅长的。
国内团队擅长的,是在一个已经验证好的路线上做到工程极致。
但是在还没有形成技术路线共识的时候,赌技术的发展,才有机会真正技术领先。
在发布会最后是理想汽车关于端到端自动驾驶的相关论文总结,每个方向都是顶级会议的重磅论文。
也就是说,在做量产的过程中,理想汽车也获得了学术界的肯定。
而仔细看论文的发表时间:
这种顶级论文的发表至少是一个季度的工作,我们几乎可以往前推演到 2023 年 9 月,整个理想汽车团队就对此有了非常巨大的投入。

那时候众多车企在开城的定义上争论不休,在谁是城区辅助驾驶第一梯队的口水战中分身乏术。
谁也没有想到,同样在这场比赛中的理想汽车已经悄悄转身,笃定的走向自己认为更有希望的一条路。
而那时候,这条路上国内没有同行者。
在今天的夏季发布会上,这些论文研究已经成了一个个重要筹码。
在走向端到端无人之境的路口,理想汽车已经设下了他的赌局,押注整个自动驾驶团队的投入和众多高校前沿团队的支持。
像黄金时代的港片《赌神》里周润发严肃地说:ALL IN。
添加微信,找到我们

更多阅读
 我们研究了特斯拉、毫末「自动驾驶算法」的秘密
我们研究了特斯拉、毫末「自动驾驶算法」的秘密
 2022,车载高规激光雷达量产元年
2022,车载高规激光雷达量产元年
